Living documentation, parce que la doc, ça peut être fun !
Living documentation, parce que la doc, ça peut être fun !
Remerciement aux relecteurs, et les octos qui ont pratiqué l’exercice du Perfection Game en interne pour aider à l’améliorer : Sofía Calcagno, Julien Tellier, Thamazgha Smail, Sébastien Gahat, Abdenour Keddar.
Dans un projet informatique, le rapport du développeur à la documentation est souvent difficile.
Au delà du “comment”, la question même d’en faire ne va pas toujours de soi :
- Le développeur peu attentif ou de mauvaise foi pourrait déclarer que le manifeste agile encourage à ne pas en faire :
We value […] working software over comprehensive documentation,
- Les puristes d’Xtreme Programming n’en disent pas moins :
- Le literate programming, un paradigme de documentation défini par Donald Knuth, encourage à mêler indépendamment code et prose pour court-circuiter le débat, mais l’a-t-on déjà vu en production ailleurs que chez IBM ?
Les occasions de rédiger de la documentation ne manquent pas, dans un projet informatique :
- De la documentation à destination de personnes qui vont nous remplacer après notre départ d’un projet,
- De la documentation à produire en anticipation de l’onboarding d’un nouveau collègue qui rejoint le projet au prochain sprint,
- De la documentation à destination d’utilisateurs, pour les aider à se servir d’un outil ou d’un produit (ex: une FAQ, de la documentation OpenAPI statique ou exécutable…)
Si la rédaction de documentation est souvent perçue comme un exercice frustrant, un paradigme de documentation, sous-côté mais néanmoins efficace, a été théorisé ces dernières années par Cyrille Martraire : la Living Documentation.
Je vous propose dans cet article de définir ce dernier, d’illustrer comment l’appliquer dans nos projets informatiques, et pourquoi pas se défaire de l’image de “corvée” qu’on associe habituellement à l’activité de documentation.
Pour faciliter la navigation dans cet article, voici un sommaire pour se rendre rapidement aux différentes parties :
- Living documentation, parce que la doc, ça peut être fun !
- La documentation peut prendre la forme d’une discussion ️
- La documentation morte
- La documentation peut être générée, au lieu de la rédiger ⚙️
- Documenter des usages en CLI
- Documenter des règles de gestion métier
- Documenter des concepts métiers, dans un contexte opérationnel
- Documenter un schéma de base de données
- Documenter un data contract, dans un contexte data/analytique
- Documenter une API REST
- Documenter une API de communication par messages asynchrones
- Documenter un diagramme d’architecture
- Conclusion
La documentation peut prendre la forme d’une discussion 🗣️
Avant de rentrer dans des considérations d’outillage, commençons par une définition.
Dans le livre Living Documentation, la documentation est définie comme :
🧠 The process of transferring valuable knowledge to other people now and also to people in the future.
C’est donc un processus qui consiste à transférer des connaissances :
- d’un individu à un autre,
- pour autrui ou pour soi-même,
- pour maintenant ou pour plus tard.
Cette définition est intéressante en ceci qu’elle permet de distinguer le problème (transférer de la connaissance), de potentielles solutions (prendre sa plus belle plume pour rédiger un document avec de la connaissance dedans par exemple).
D’autres solutions que la rédaction d’un document existent pour répondre à ce problème : Alistair Cockburn en présente quelques-unes, hiérarchisées selon leur efficacité dans le graphe ci-après. Il met notamment la discussion entre deux individus équipés d’un support de dessin ou de modélisation à disposition (et idéalement colocalisés) dans le haut du panier.
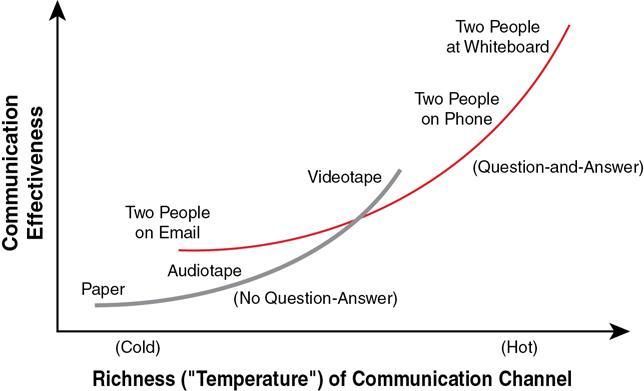
Richness of communication channel - Alistair Cockburn
Dans nos projets informatiques, une discussion pour transmettre de la connaissance peut prendre plusieurs formes :
- discuter et dessiner au tableau blanc, physique ou numérique (comme Excalidraw),
- pratiquer le pair/mob-programming/software teaming,
- pratiquer la revue de code,
- échanger via des Issues ou Discussions/Forums comme proposées par Github ou Gitlab
- Faire un event-storming.
Néanmoins, on reconnaîtra que ces discussions sont souvent plus efficaces à tenir quand il est possible de s’appuyer … sur des documents ou des diagrammes qui existent déjà !
Les discussions en tête-à-tête et la culture orale passent aussi difficilement à l’échelle.
Mais sommes-nous condamnés à rédiger cette documentation, au crayon ou au clavier ?
🎃 La documentation morte 👻
Décrire le concept de documentation vivante me paraît souvent plus efficace en définissant d’abord son opposé.
De la documentation morte, c’est de la documentation considérée comme obsolète à partir du moment où le crayon qui a servi à la rédiger est posé.
De la documentation vivante, c’est donc de la documentation qui sait rester utile, pertinente dans le temps et qui évolue au rythme des sujets sur lesquels elle porte.
Voici des exemples afin d’illustrer ces concepts de documentation morte et documentation vivante.
De la documentation métier morte 👔 👻
Sur un projet dans le domaine de l’assurance, nous avons implémenté la règle de gestion rétractation à l’initiative de l’assuré.
Voici à droite l’implémentation de cette règle, et à gauche un extrait du wiki d’entreprise rédigé par des membres de l’équipe pour documenter cette règle de gestion.
Ici, nous avons deux sources d’informations (le code d’une part, et le wiki d’entreprise d’autre part) qui portent sur le même objet (la règle de gestion rétractation à l’initiative de l’assuré).
In fine, nous considérons le code comme la source de vérité car c’est ce qui est exécuté en production.

De la documentation (à gauche) qui porte sur des règles de gestion
modélisées dans du code (à droite), code qui pourrait se suffire à lui-même
Rédiger manuellement un document pour expliquer des concepts modélisés dans du code, c’est prendre le risque de produire un document :
- incomplet (par rapport au code),
- ou avec des informations obsolètes, si ce document n’évolue pas au même rythme que le code,
- ou avec des informations erronées si ce document diverge du code.
Quelques semaines plus tard, les experts métier font évoluer la règle : ils décident d’accorder 1 jour de réflexion supplémentaire aux assurés.
Si le code est simple à modifier pour modéliser ce changement, l’équipe ne pense pas à modifier le wiki d’entreprise.
C’est à l’arrivée d’un nouveau membre dans l’équipe, 7 mois plus tard, qui prend le temps de lire le wiki et le code pour comprendre le contexte, qu’il se rend compte de cette désynchronisation.
Cela crée de la méfiance envers la documentation dans l’équipe : si ce chiffre est faux depuis des mois, quid du reste du document ?

De la documentation obsolète (à gauche) car elle n’a pas évoluée en même temps que le code (à droite), code qui fait foi car il tourne en production
De la documentation technique morte ⌨️ 💀
Voici un second et dernier exemple de documentation morte, qui porte sur de la documentation technique cette fois.
Toujours dans la même équipe, ce nouveau membre fraîchement arrivé en tant que développeur décide de préparer son poste de travail pour pouvoir commencer à travailler. Il clone le repo de code que ses collègues lui partagent, et va naturellement ouvrir le fichier README.md à la racine du projet. À la lecture, il comprend qu’il s’agit d’un projet en Python :
## Getting started
You should install pyenv, then run in your terminal:
> PYTHON_VERSION=3.10.12;
> pipx install poetry;
> pyenv install ${PYTHON_VERSION};
> pyenv local ${PYTHON_VERSION};
> poetry install;
Après avoir exécuté ces commandes avec succès, il décide de lancer les tests unitaires. Il voit à l’arborescence de code qu’il y a des tests, dans un dossier tests/, mais le fichier README.md ne mentionne ni tests ni commande pour lancer les tests.
Armé de courage, et parce qu’il n’a rien à perdre, il tente de les lancer avec la commande suivante :
> pytest tests/;
Les tests se lancent bien ! Mais il y a des erreurs :
200 passed, 29 errors in 75.24s (0:01:15)
Après avoir demandé de l’aide à l’équipe et investigué pendant 1 heure, l’équipe se rend compte que la version de Python renseignée dans le README est erronée.
Si le projet avait bien démarré en 3.10.12 il y a 1 an, ce projet est passé à la version 3.11.5 il y a 2 mois, et c’est une mise à jour majeure qui s’accompagne de breaking changes (d’où les tests en échecs).
Ce fichier README.md contient donc de la documentation morte. Par contamination, on pourrait même considérer l’ensemble de ce fichier README.md comme de la documentation morte : si la version de Python spécifiée n’est pas bonne, qu’en est-il de la valeur de vérité du reste du README ?
Attention au lecteur hâtif à ne pas se méprendre en retenant simplement qu’avoir un fichier README.md dans son projet est une mauvaise pratique ! Ce n’est pas le fichier qui pose problème, mais la manière dont il a été construit.
Un enjeu de Living Documentation consiste à produire ce que son auteur décrit comme un evergreen document, un document qui sait résister à l’épreuve du temps, au travers de techniques comme :
- Rester haut-niveau dans ce qu’on décrit, mettre l’effort de rédaction sur des éléments pérennes comme des invariants métier, dans le cas d’une documentation sur le fonctionnement d’un produit par exemple,
- S’il faut rentrer dans des détails, privilégier la ready-made documentation (des documents de référence, sur étagère, réutilisables) quand cela est possible.
- Par exemple, si on fait de la Clean Architecture sur son projet et qu’on veut documenter cela : mettre un pointeur vers un document de référence qui décrit ce que c’est (et qui le fera sans doute mieux que nous) plutôt que de le décrire soi-même,
- Générer automatiquement des documents à partir de sources de vérité (comme le code) au lieu de les rédiger soi-même.
Attardons-nous d’ailleurs sur ce dernier item essentiel pour produire des documents vivants.
La documentation peut être générée, au lieu de la rédiger ⚙️
Si ce début d’article a réussi à vous intriguer sur le concept de Living Documentation, je vous invite à lire le livre éponyme, nécessairement plus détaillé, plus précis, et qui donne de nombreux exemples de documents vivants et de documents morts.
Afin d’apporter un différenciant avec cet article, des exemples de construction de documents vivants, certains inspirés du livre et d’autres absents de celui-ci, seront présentés dans cette partie.
Il s’agit d’exemples tirés de projets réels, et qui ont su rester vivants au sens où nous avons vérifié qu’ils sont toujours présents et toujours utilisés par des équipes après le départ des personnes qui les ont initiés.
Documenter des usages en CLI
La plupart des projets que j’ai traversés documentent la manière de configurer leur poste de développement et certains usages au travers d’un fichier README.md, contenant souvent une partie intitulée Getting started, qui peut ressembler à ceci :
## Getting started
- you can install dependencies with `poetry install`
- we also have dev dependencies that you can install with `poetry install --only dev`
- you can run the tests with `poetry run pytest tests/`
- if tests are green, you can try to run the app locally with `DB_PASSWORD=toto poetry run uvicorn src.coolcover_company_app.main:app --reload`
Comme ces usages évoluent souvent avec le temps, je privilégie la pratique du makefile auto-documenté pour documenter de tels usages.
Afin de goûter ma propre soupe, voici de la ready-made documentation sur ce concept, ici dans cet article de François Zaninotto pour Marmelab : https://marmelab.com/blog/2016/02/29/auto-documented-makefile.html.
En une phrase, je résumerai cette pratique ainsi : se servir d’un makefile comme d’un contrat d’interface exécutable, à destination d’un utilisateur qui découvre un repo de code et se demande comment il peut interagir avec celui-ci.
Un makefile auto-documenté propose en point d’entrée principal une commande help pour décrire ses usages, et qui peut ressembler à ceci :
.DEFAULT_GOAL: help
# 🛟 to display this prompts. This will list all available targets with their documentation
help:
echo "📍🗺️ You are in $(shell basename $(CURDIR))/"
echo "❓ Use \`make <target>' where <target> is one of 👇"
grep -E '^\.PHONY: [a-zA-Z0-9_-]+ .*?##' $(MAKEFILE_LIST) | \
awk 'BEGIN {FS = "(: |##)"}; {printf "\033[36m%-30s\033[0m %s\n", $2, $3}' | sort
echo "Tips 💡"
echo " - use tab for auto-completion"
echo " - use the dry run option '-n' to show what make is attempting to do. example: make -n help"
.PHONY: install-dependencies ## ⬇️ to download all python dependencies
install-dependencies:
poetry install
…
En exécutant make help, ou simplement make ici, on obtient un document vivant qui décrit les usages principaux d’une équipe sur sa base de code :
❯ make
📍🗺️ You are in src/
❓ Use `make <target>' where <target> is one of 👇
install-dependencies ⬇️ to download all python dependencies
install-dev-dependencies ⬇️ to download code dev dependencies
python-format 🪮✨ to format the code following our team standards
python-lint 🪮 to lint the code and check if it is homogeneous and pretty and follow our team standards
security-lint 🚔 to run security checks on Python code
start ▶️ to start the api
test ✅ to run all tests

Capture d’écran de la sortie console, quand on exécute make help dans le terminal
Cette sortie console, une fois redirigée dans un fichier (texte ou image), peut être alors considérée comme un evergreen document : un document qui se base sur une source de vérité (le Makefile) utilisé par l’équipe quotidiennement.
Les avantages de cette pratique :
- les usages, processus et commandes d’intérêts ne sont pas simplement rédigés, ils sont exécutables :
- si l’équipe se sert du makefile et qu’une commande ne marche plus, cela finira par se voir
- en bons scouts (BSR), la commande obsolète finira par être corrigée dans un temps raisonnable. Si elle n’est pas corrigée, c’est peut-être le signe qu’elle n’est plus utilisée ou utile et qu’il ne faudrait plus la documenter.
- la documentation des usages est au plus proche du code, elle est générée à partir du code et peut évoluer quand le code évolue,
- la réduction de la charge mentale : plus besoin de retenir des commandes par coeur ou de fouiller dans son historique de commandes pour les retrouver,
- l’expérience développeur (DX) : l’utilitaire make est disponible nativement sur les plateformes Linux/MacOS.
- Cela demande ainsi moins d’étapes préliminaires d’installation avant de pouvoir exécuter la première commande quand on prend en main un repo ou pour s’en servir dans un pipeline CI/CD (en comparaison à des scripts NPM qui demandent d’installer préalablement NodeJS et NPM, par exemple).
- On réduit ainsi le time to first use.
Voici un template de Makefile auto-documenté simple, si vous voulez vous essayer à cette pratique chez vous : https://gist.github.com/Mehdi-H/0e1a47fb0243f6d6a4aa7108a3cbacfe.
Vous trouverez aussi dans cet autre repo un exemple de Makefile auto-documenté, avec une commande help exécutable en local pour :
- Afficher en console les usages de ce repo,
- Capturer automatiquement dans une image cette documentation des usages afin de rendre le fichier README.md vivant (avec l’utilitaire Freeze).
Documenter des règles de gestion métier
S’il peut être tentant de prendre sa plume pour rédiger le fonctionnement d’un processus métier ou des règles de gestion dans un outil de documentation d’entreprise à la Confluence, on prend alors le risque de documenter ce que le système devrait faire et non pas ce que le système fait actuellement.
Idéalement, on aimerait que ces deux situations se superposent (le système fait ce qu’il devrait faire), mais comment faire confiance à une telle documentation si la documentation est en avance de phase sur l’implémentation ou si l’implémentation diverge de la documentation ?
Pour éviter la désynchronisation entre la documentation de règles de gestion métier et leur implémentation, le livre Living Documentation conseille, entre autres, de s’orienter vers de la documentation exécutable. La pratique du makefile auto-documenté évoquée plus haut est une forme de documentation exécutable. Pour documenter des règles de gestion métier, on peut plutôt regarder du côté de la méthodologie BDD : Behavior-Driven Development.
Pour rester succinct, car la littérature sur cette approche de développement est pléthorique, celle-ci consiste en des discussions entre sachants métier (SME), développeurs et testeurs traversant trois étapes clefs :
- La découverte,
- La formulation,
- Enfin, l’automatisation.
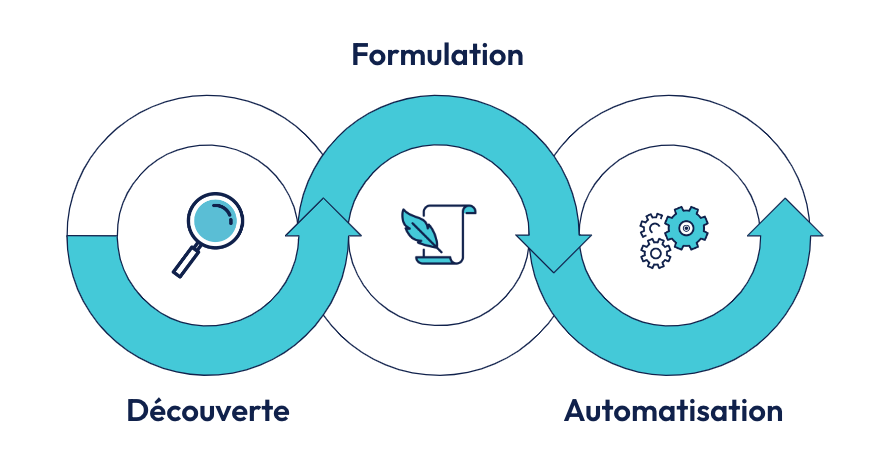
Il devient ainsi possible, en phase de formulation, de documenter des comportements attendus du système en langage naturel avec un certain formalisme (comme le Gherkin), puis en phase d’automatisation de lier ces comportements rédigés en langage naturel à des tests automatisés avec du code.
Les outils de tests BDD proposent généralement de produire des rapports consultables par des populations non-techniques, à partir de ces spécifications Gherkin et de l’exécution des tests automatisés.
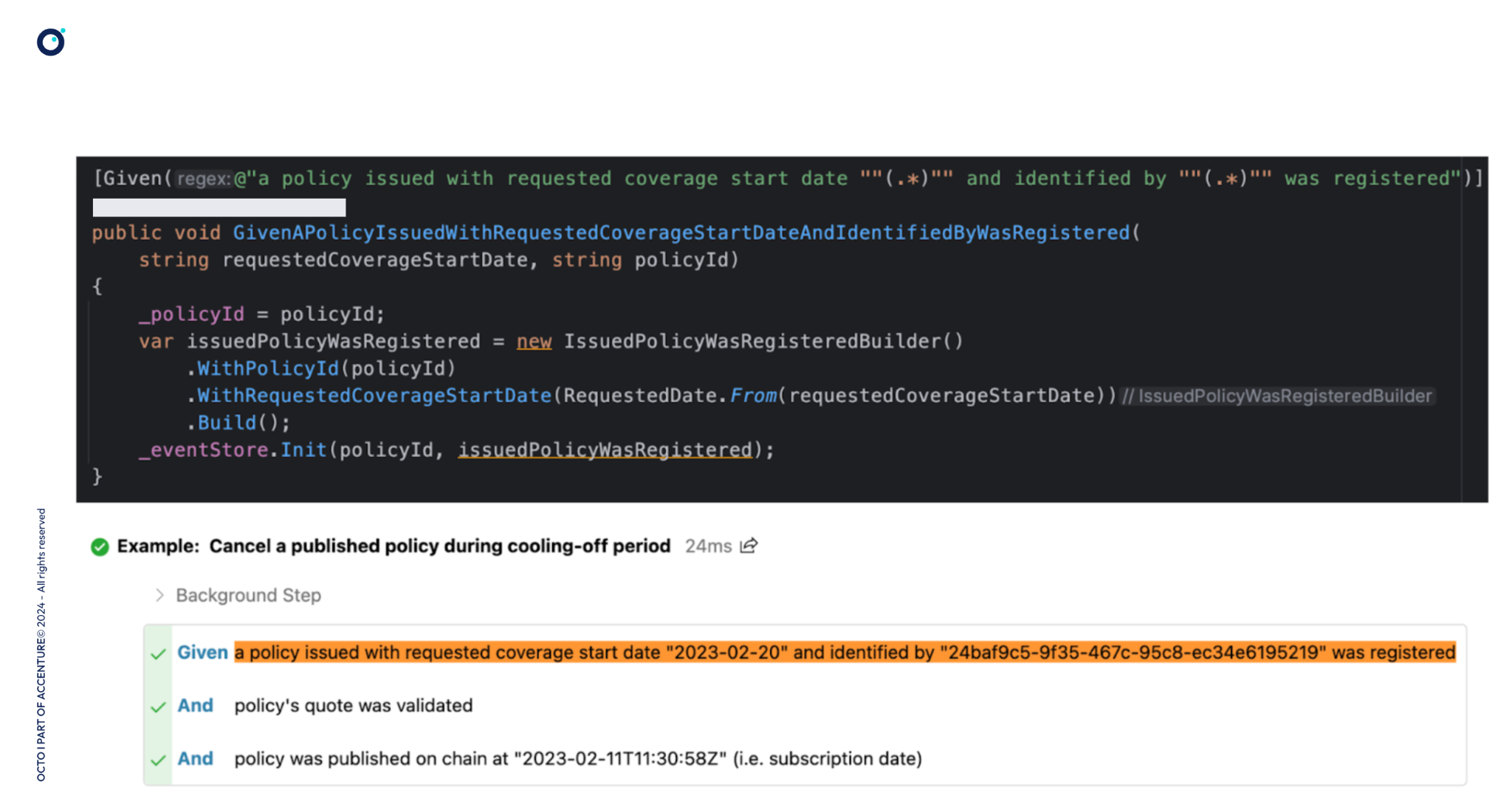
En haut, une interface de développement (IDE),
et en-dessous son rapport HTML correspondant, généré à partir du code
Ces rapports sont des documents vivants et ont les avantages suivants :
- En couplant leur génération à une étape de build dans un pipeline d’intégration continue, il est possible de les générer automatiquement, à la demande, et de les lier à une version (un tag ou commit) précise du code,
- Au-délà de décrire ce que le système est censé faire, de tels rapports documentent aussi la capacité du système à respecter ces comportements attendus (si les tests passent ou non),

Les scenarii précédés d’une ✅décrivent des comportements respectés par le code,
ceux précédés d’une coche grise ne sont pas encore supportés,
❌ signifierait que le code échoue à respecter le comportement attendu pour une règle de gestion donnée
- Si l'équipe de développement intègre le BDD à ses pratiques en accompagnant le développement de fonctionnalités avec la rédaction de scenarii, la documentation peut évoluer au même rythme que le code, juste à temps.
Documenter des concepts métiers, dans un contexte opérationnel 📖
Dans Domain-Driven Design: Tackling Complexity in the Heart of Software, Eric Evans décrit le concept d’ubiquitous langage : un langage partagé par l’équipe de réalisation d’un logiciel (développeurs et sachants métier) leur permettant de discuter de concepts d’intérêt en évitant les ambiguïtés.
S’il peut être intéressant de documenter les concepts et termes qui composent ce vocabulaire commun dans une feuille Excel ou un tableau Markdown à mesure que le projet avance, un problème de multiplication des sources de vérité peut là aussi apparaître : faut-il se fier à cette documentation rédigée manuellement ou bien aux objets modélisés dans le code ?
Que faire quand le ticket JIRA rédigé par le PO parle d’Underwriter quand le code, à jour, parle de Policyholder. Parle-t-on de la même chose ?
Une solution évoquée dans Living Documentation pour couper la poire en deux est la knowledge augmentation : une technique qui consiste à rédiger la documentation de ces termes (ou d’autres éléments de connaissance) au plus proche du code, par le biais, par exemple, d’annotations sur des classes.
Dans la phrase précédente, le terme annotation est utilisé de manière générique et est à adapter selon votre langage de programmation favoris : annotations Java, décorateurs Python, attributs C#… ou simplement des commentaires s’il n’existe pas d’équivalent idiomatique aux annotations dans un langage de programmation (en bash, par exemple).
Voici un exemple de termes documentés par annotation dans un module Python :
@Glossary
class CatActivity:
"""The set of the main activities of a cat"""
pass
@Glossary
class Sleeping(CatActivity):
"""The cat is sleeping with its two eyes closed"""
pass
@Glossary
class Eating(CatActivity):
"""The cat is eating, or very close to the dish"""
pass
@Glossary
class Chasing(CatActivity):
"""The cat is actively chasing, eyes wide open"""
pass
@Glossary
class Event:
"""Anything that can happen that matters to the cat"""
pass
Voici des exemples de fichiers de documentation markdown et Excel générés automatiquement à partir du code annoté ci-avant :

Cette documentation par annotations a les avantages suivants :
- La documentation de concepts métier porte sur les concepts essentiels : ceux qui existent dans le code (sous forme de classe souvent, mais pas nécessairement, comme on peut le constater dans l’ouvrage Domain Modelling Made Functional de Scott Wlaschin).
- Si un concept est suffisamment clef dans un processus métier pour devoir le documenter dans un wiki mais qu’il n’est pas modélisé dans le code, peut-être a-t-on raté une opportunité de conception ?
- La documentation est au plus proche du code : elle a plus de chance d’évoluer en même temps que le code car elle est sur le chemin du critique du développeur et elle peut être captée par des outils de refactoring en cas de renommage d'une classe par exemple,
- Pour devenir accessible à des populations non-techniques, la documentation par annotations dans le code peut être exportée hors du code pour être projetée dans des fichiers Excel, des fichiers Markdown, des pages Confluence, des bases de données Notion ou autre Wiki doté d’une API ...
- La manipulation de texte avec sed, awk, grep ou bien d’autres outils tels que la réflexion ou la modélisation AST peuvent aider à y parvenir.
Documenter un schéma de base de données 🧫
Il est souvent utile de pouvoir consulter le schéma de sa base de données : pour pouvoir le faire évoluer ou simplement faire un état des lieux.
On peut tenter de construire soi-même un diagramme qui représente le schéma de base de données : avec un diagramme entités-relations si cela s’y prête, que l’on pourrait construire sur la base de notre compréhension du système ou en le rétro-documentant à partir du code. C’est un diagramme qu’on peut dessiner sur une feuille pour l’afficher au mur sur son plateau projet. On peut aussi modéliser ce diagramme avec du code (avec des librairies comme MermaidJS par exemple). Dans les deux cas, cela nécessite une certaine discipline pour le maintenir à jour quand le code évolue.
Pour avoir accès aux informations nécessaires pour produire un tel diagramme, le plus rapide reste certainement de se connecter à ladite base de données en SSH pour y exécuter des commandes et ainsi lister les tables, relations et autres contraintes.
Cette option, manuelle, peut nécessiter quelques acrobaties réseaux rarement documentées (connexions à un VPN, à un bastion, multiples rebonds, allowlisting de l’IP de son poste sur les machines idoines, …). C’est aussi une option contraire au principe d’infrastructure immutable : en se connectant manuellement à la base de données pour exécuter des commandes ou débugger, on prend le risque de perturber l’état de la machine qui l’héberge.
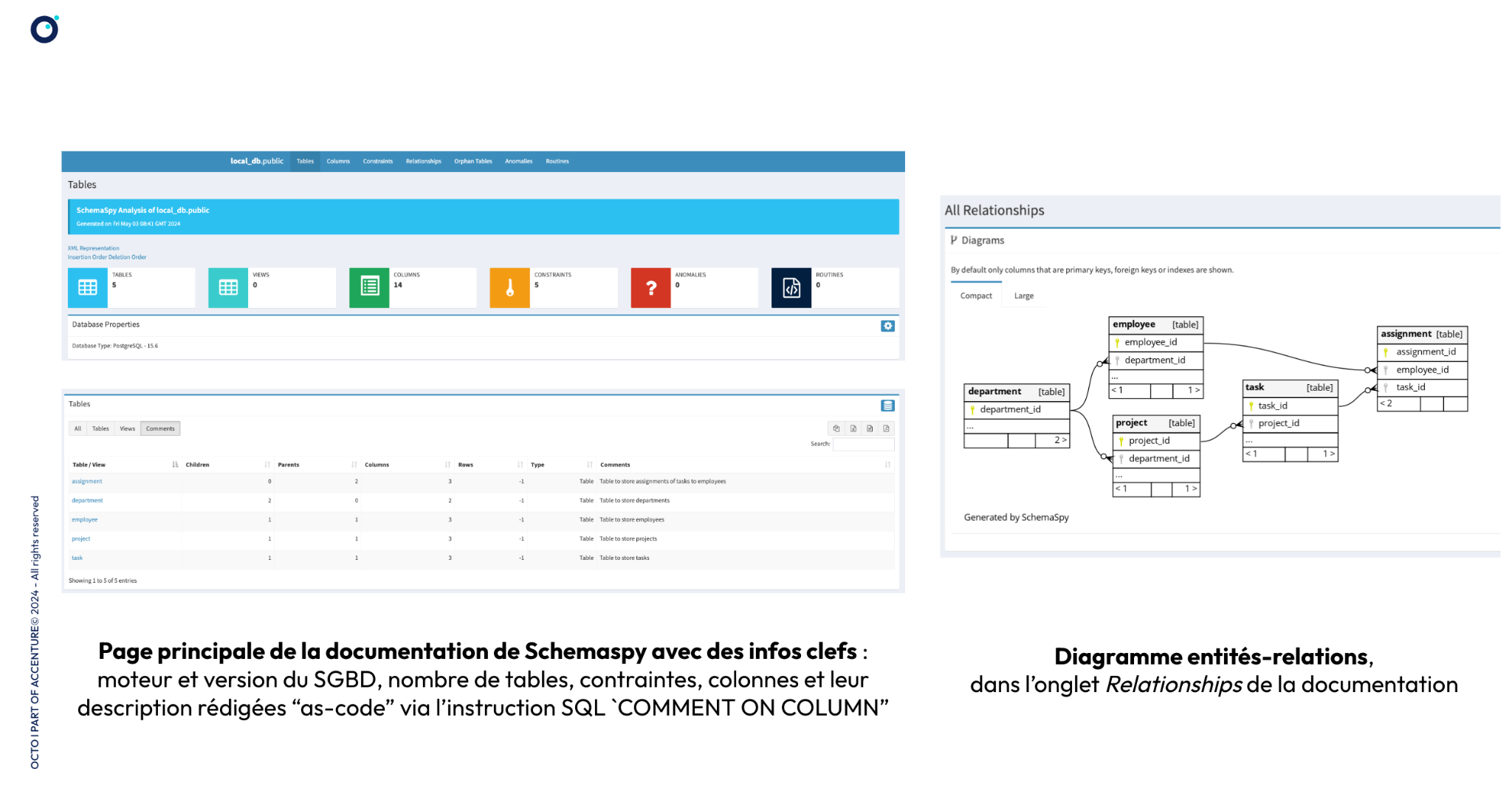
Pour générer une telle documentation automatiquement, ma préférence est de générer des diagrammes de relations à partir de l’état même de la base de données, avec un outil tel que SchemaSpy. C’est un outil qui peut s’utiliser en CLI (binaire Java ou conteneur docker) : l’outil se connecte automatiquement à la base de données pour produire une documentation sous la forme d’un site HTML statique.
Embarqué dans un pipeline CI/CD, on peut alors s’assurer de produire une documentation vivante de la base de données, qui évolue au même rythme que le code. Au choix, le pipeline peut construire une base de données éphémère (avec un conteneur par exemple) à partir de laquelle on peut générer la documentation des tables, ou bien il peut directement se connecter à une base de données déjà déployée dans un environnement de référence avec un schéma à jour (la production ou un environnement iso-production).
Vous trouverez dans ce repo publique un exemple de Makefile auto-documenté, exécutable en local pour
- Monter une base de données PostgreSQL éphémère, accompagné d’un schéma relationnel décrit par un script SQL
- Générer de la documentation sur cette base de données avec Schemaspy
- Détruire la base de données
Voici le rendu auquel vous pouvez vous attendre, à des fins d’illustrations :
Documenter un data contract, dans un contexte data/analytique 📈
Dans la littérature Data Mesh, le terme data contract désigne un contrat d’interface, les modalités d’un échange de données entre deux parties prenantes : structure de la donnée, format attendu ou exposé, définitions de termes, contraintes sur les champs (chaine de caractères, entier compris entre 0 et 12, énumération…) …
Une manière de produire de la documentation de data contract automatiquement, qui peut évoluer en même temps que ces éléments énumérés ci-dessus, peut reposer sur un assemblage de quelques outils open-source. Je me suis récemment essayé à la combinaison qui suit :
- Pydantic, une librairie de modélisation et de validation de données en Python, permettant aussi de convertir simplement une classe au format JSON Schema,
- le standard JSON Schema (un standard pour décrire de la donnée à échanger, en JSON),
- la librairie json-schema-for-humans, qui peut convertir un document JSON Schema en document HTML statique.
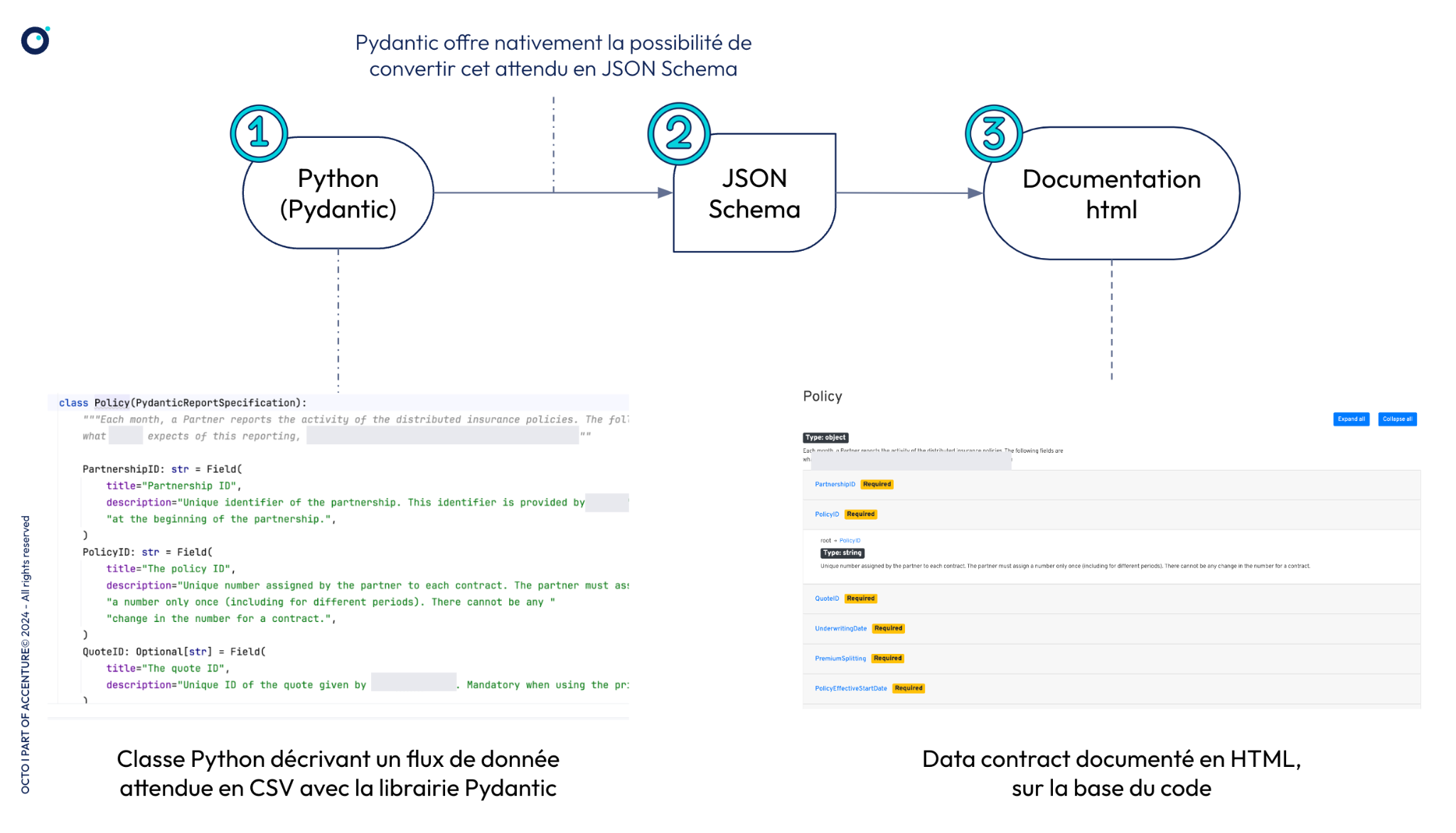
Production d’une documentation de data contract automatique à partir de code
Intégrées à un pipeline CI/CD, la génération et la publication d’un tel document peuvent être réalisées à chaque évolution des contraintes sur la donnée exprimées dans le code afin de le garder vivant.
Vous trouverez dans ce repo un exemple de Makefile auto-documenté, exécutable en local pour produire simplement une documentation json-schema-for-humans à partir d’une classe Python.
Documenter une API REST
Cette partie se veut assez courte car un standard existe dans le paysage web depuis plus d’une décennie maintenant pour documenter un contrat d’interface entre un client et un serveur sur le médium web HTTP : la spécification OpenAPI (auparavant Swagger), en version 3.1.0 à ce jour.
De nombreuses intégrations existent afin de générer et servir une définition OpenAPI à partir du code de contrôleur rédigé par un développeur.
Parmis les avantages à générer une documentation d’API web à partir de classes rédigées, on on notera que :
- La documentation est générée de façon standardisée, en JSON ou en YAML, selon la spécification OpenAPI, mais aussi (et surtout) en HTML pour être consultée par des humains,
- La documentation des usages (routes et codes HTTP) et des objets avec leurs contraintes (types, caractère obligatoire ou optionnel…) et leur définition, est générée à partir du code, donc elle évolue en même temps que le code pour éviter la désynchronisation,
- La définition des objets (champs summary et description de la spécification OpenAPI) est souvent renseignable en décorant les classes via des commentaires XML dans le code.
- Une fois servie, la documentation peut être exécutée pour vérifier/recetter les comportements du système,
- La documentation générée à partir du code peut être “augmentée” en la complétant avec du contenu dans des fichiers Markdown pour l’accompagner d’un guide d’utilisation, par exemple.
Documenter une API de communication par messages asynchrones 📨
Si le standard OpenAPI est adapté pour documenter une interaction synchrone, il l’est moins pour documenter des interactions asynchrones.
Pour ce genre d’interactions basées sur des messages ou des événements, il convient de les documenter via le standard émergent AsyncAPI. Celui-ci a le bon goût de chercher à produire une expérience de conception et d’usage similaire à celle fournie par le standard OpenAPI : spécification rédigeable en JSON ou YAML, rendu de la documentation en HTML, génération d’artéfacts de documentation à partir du code…
Ce standard, porté par la communauté open-source*,* dispose lui aussi de nombreuses intégrations, probablement dans votre langage de programmation favori, afin de générer la documentation à partir du code, telles que Saunter en .NET.
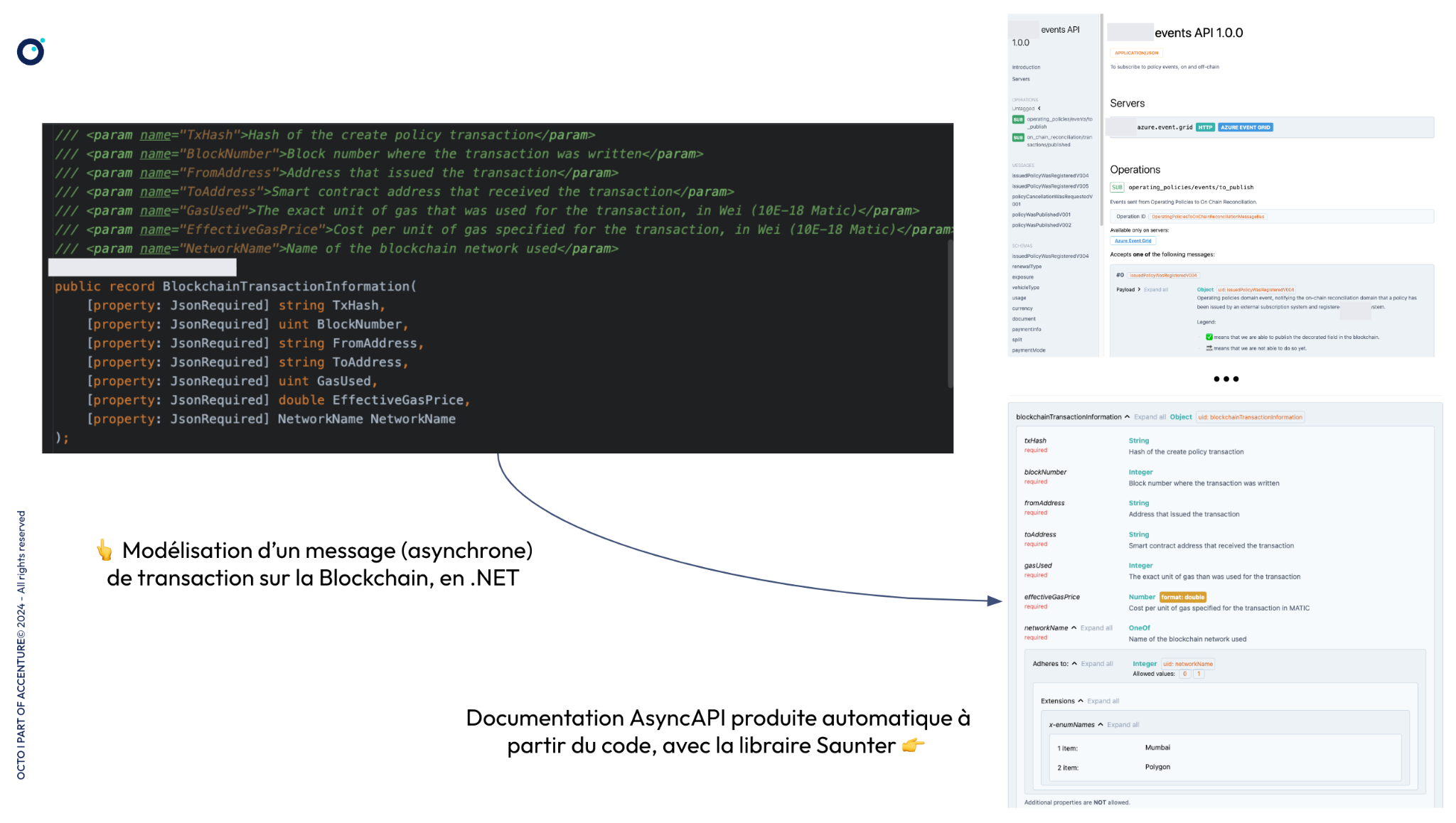
A gauche, un message modélisé sous la forme d’un objet .NET.
A droite, de la documentation AsyncAPI sur les différents canaux asynchrones et messages générée automatiquement à partir du code
Documenter un diagramme d’architecture 📐
En usant à nouveau de ready-made documentation, je vous réfère à un autre article sur le blog OCTO, rédigé par votre serviteur, qui traite de génération de diagrammes d’architecture à partir de code.
J’y explique comment la proximité entre code applicatif et code de diagrammes peut permettre d’activer une démarche de Living Documentation et augmenter la probabilité de voir le code et les diagrammes qui le documente évoluer au même rythme.
Conclusion
S’il peut souvent être tentant de prendre sa plus belle plume pour rédiger de la documentation, nous avons vu dans cet article que des alternatives existent :
- La discussion, souvent négligée, est une approche efficace pour transmettre de la connaissance;
- La génération de documents à partir de sources de vérité (comme le code) est un bon moyen aussi de mettre toutes les chances de notre côté pour produire de la documentation evergreen, pérenne.
Pour conclure, j’ajouterai simplement que la documentation peut aussi être rédigée quand on ne peut pas la générer. Il y a en effet des éléments qui ne peuvent pas être inférés à partir du code. Les décisions d’architecture (ADR) en sont un bon exemple : ces documents permettent de capturer le contexte de l’équipe et de l’organisation dans laquelle elle évolue au moment de prendre une décision d’architecture. Si le code applicatif ou le code d’infrastructure peut servir à rétro-documenter la décision prise, on y trouvera difficilement les éléments de contexte qui ont aidé à prendre la décision comme l’effectif de l’équipe, ses compétences à date, ce qu’elle a déjà expérimenté ou non, les standards et règles de gouvernance de l’entreprise à suivre, etc.
Les exemples présents dans cet article ne sont pas exhaustifs, je vous invite à trouver vos propres façons de faire de la Living Documentation, de surcroît dans cette ère d’intelligence artificielle générative !
N’hésitez pas à me contacter pour me partager vos façons de faire et vos découvertes !