De l'observabilité technique à l'observabilité métier : quand vos logs racontent enfin une histoire claire
Remerciement aux octos qui ont pratiqué l’exercice du Perfection Game en interne pour aider à l’améliorer : Sofía Calcagno, Julien Tellier, Sébastien Gahat, Céline Gilet et à d’autres relecteurs qui m’ont fourni des feedbacks utiles : Julien Assemat, Lucie Quach, Julien Alexandre, Julien Tabary.
En tant que consultant, il m'est commun d'apporter de l'expertise ponctuelle dans des projets. J'interviens dans des projets dont je n'ai pas assisté à la genèse (et pour lesquels j'espère ne pas voir la fin non plus). Je prends le train en marche, et mon premier ressenti est souvent de faire face à une boîte noire.
Pour pallier mon déficit d'information, je peux alors me pencher sur des éléments de documentation (idéalement, vivants) produits par l'équipe responsable du système avant mon arrivée. Mais je constate en pratique qu'il n'y a rien de plus efficace pour comprendre un système que de l'observer pendant qu'il fonctionne : pouvoir appuyer sur un bouton et observer quels rouages de la machine tournent, ou ne tournent pas.
Récemment, une de ces casquettes d'expertise que j'ai eue à porter est celle d'expert en performance, pour aider un client à améliorer la latence de son système distribué. Avant mon intervention, on m'avait assuré que le système était observable, ce qui allait faciliter mon intervention.
Posons une définition de ce terme, tirée du livre Observability Engineering (Charity Majors, Liz Fong-Jones, George Miranda, 2022) :
💡 Observabilité
Un système logiciel est dit "observable" si les humains qui interagissent avec lui sont capables de comprendre ses états internes sans avoir besoin de livrer une nouvelle version de ce système.
Le piège de l'observabilité technique
(Note : dans ce qui suit, le terme “simulation” est un terme métier : une simulation est réalisée par des chercheurs R&D qui se servent de données issues de mesures expérimentales)
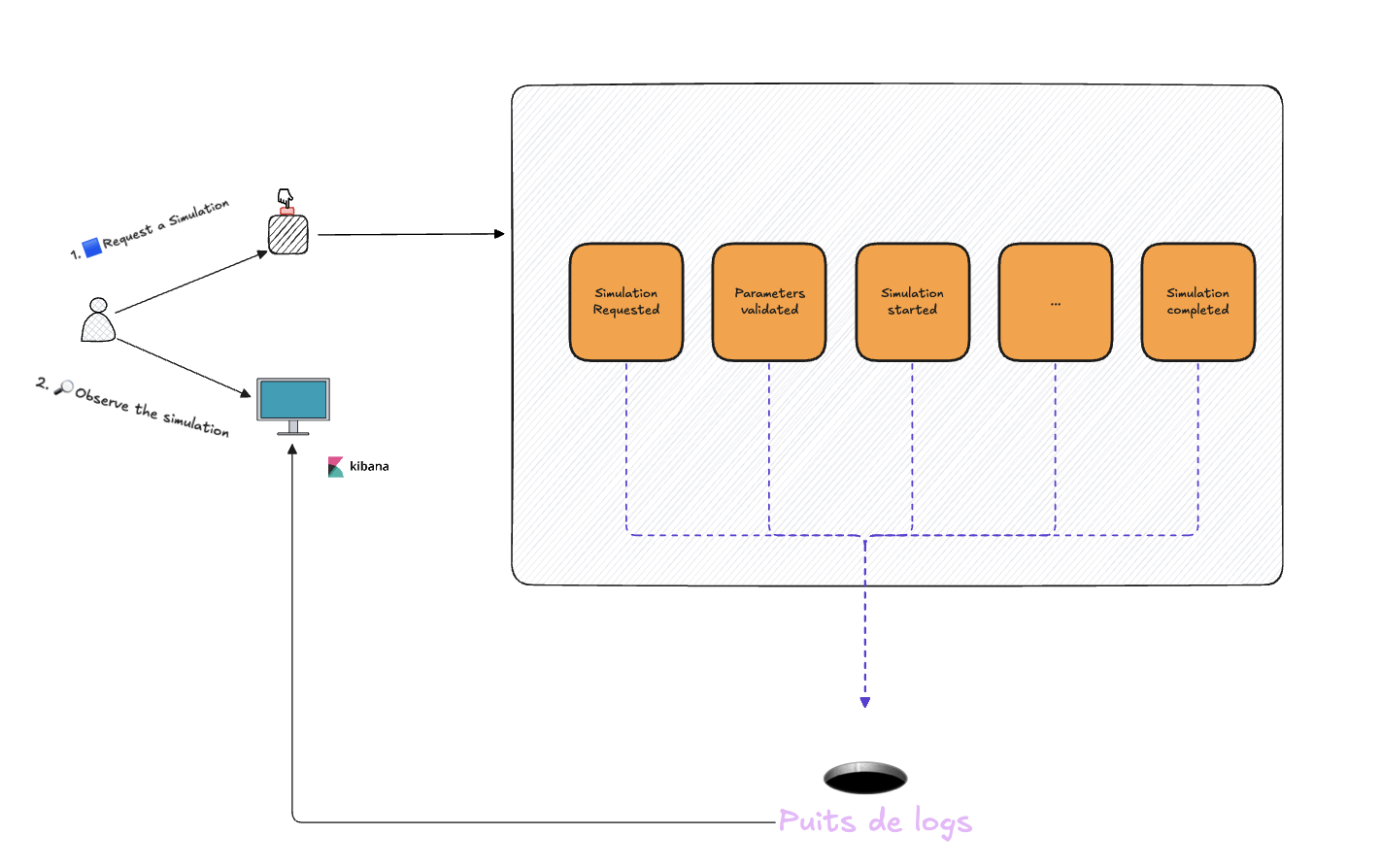
Lors de mon premier jour à interagir avec ce système, j'étais en mesure de le stresser : je pouvais lancer un ordre pour exécuter, via un endpoint HTTP, une simulation dite "lourde" (durée de traitement approximative de 13h).
Je me suis naturellement rendu dans la solution d'observabilité utilisée par l'équipe pour observer le système pendant cette simulation, et j'ai fait face à une situation à laquelle je ne m'attendais pas : les requêtes que je saisissais dans l'interface produisaient soit aucun log, soit trop de logs, et je ne comprenais pas ce que le système faisait.
L'équipe a configuré ses microservices de manière à remonter tout ce qu'elle pouvait dans son puits de logs : logs de requêtes HTTP, logs techniques des différents frameworks frontends et backends, logs des bases de données, logs systèmes des services sur les machines virtuelles, logs applicatifs rédigés par les développeurs dans le code, ... Tout était là, et en tant que nouvel arrivant sur le projet, je me sentais submergé.
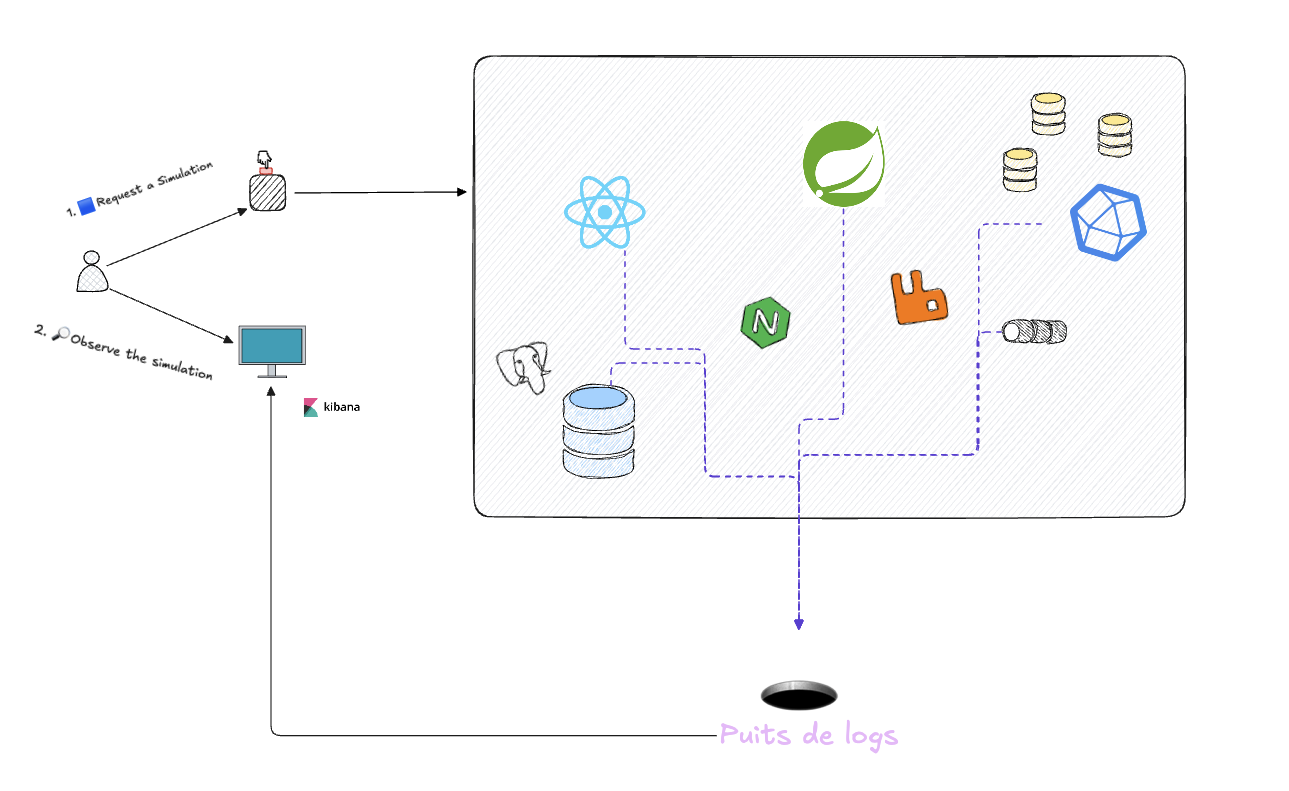
Pour les besoins de ma mission, j'étais intéressé par répondre à de simples questions, par exemple :
- quels sont les logs liés uniquement aux microservices que je veux auditer,
- quels sont les logs liés à la simulation que j'ai lancée
- comment trouver le log qui marque le top départ de ma simulation
- comment trouver le log qui marque la fin de ma simulation
- combien de temps à duré la simulation que j'ai lancée
- quelles sont les étapes de la simulation où le système passe trop de temps
Le système produisait des logs, il y en avait beaucoup, ils remontaient bien dans la solution d'observabilité (d'ailleurs, certains remontaient même en double 👯), mais pour autant je trouvais que la solution d'observabilité en l'état ne remplissait pas sa fonction car je ne trouvais pas réponse à mes questions, et l'équipe en charge du projet non plus, d'ailleurs. Paradoxalement, une observabilité trop détaillée a rendu le système moins observable.

Ce système est-il observable ?
⚠️ Le paradoxe du bruit
Des logs qui n’obéissent pas à une stratégie de logging claire créent du bruit et rendent le système métier moins observable. Dans ce cas, plus on ajoute d'observabilité, plus on ajoute de bruit et moins le système est observable.
L'eventstorming, pour retrouver du signal dans le bruit
Pour sortir du brouillard, j’ai proposé à l'équipe qui opère le système de réaliser un atelier eventstorming, dans sa forme la plus simple (le format "Big Picture") pour se focaliser sur le processus métier qui nous intéresse. L'objectif : identifier les événements métier réellement significatifs pour permettre au néophyte que j’étais de comprendre ce qu'il se passe.
En 1h30 d'atelier, avec le tech lead et un sachant métier, nous avons identifié les événements clés du processus de simulation. En voici une version épurée :
(Note : dans un eventstorming, les post-its oranges 🟧 désignent des événements importants qui se produisent dans le système étudié, les post-its bleus 🟦 désignent des commandes envoyées à ce système. L’enchaînement de post-its produit un narratif qui se lit temporellement de gauche à droite dans les schémas plus loin, ou de haut en bas dans l’énumération qui suit - voici un lien pour ceux qui souhaitent en savoir plus sur cet exercice de modélisation collaborative qu’on retrouve fréquemment dans la boîte à outils des pratiquants du Domain-Driven Design)
🟦 Request a Simulation - L'utilisateur (un chercheur R&D) ordonne une simulation (via une UI)
🟧 Simulation Requested - La demande de simulation est réceptionnée par l'API de calcul
🟧 Simulation Parameters Validated - Les paramètres sont vérifiés
🟧 Simulation Started - Le traitement, réalisé par un worker, commence effectivement
🟧 Data Loading Completed - Les données nécessaires à la simulation sont chargées
🟧 Computation Started - Le cœur du calcul démarre
🟧 Intermediate Result Computed - Résultat intermédiaire (répété N fois)
🟧 Intermediate Results Persisted - Les résultats intermédiaires sont sauvegardés (répété N fois)
🟧 Post-processing Computation ended - Des post-traitements sont appliqués sur les données produites par la simulation
🟧 Calculation Phase Completed - Le calcul est terminé (côté backend)
🟧 Simulation Completed - La simulation est terminée (le frontend peut être notifié)
A la fin de l'atelier, nous avions sous les yeux une trame d'événements, un narratif construit collectivement pour modéliser ce que le système est censé faire.

💡Remarque
Tout le monde dans la pièce était aligné avec le contenu sur le mur de post-its. Tout le monde, sauf le code : aucun de ces événements métier n'apparaissait clairement ni dans le code ni dans les logs de l'application.
L'équipe a par la suite décidé d'ajouter de nouveaux logs dans le code, en miroir de l'eventstorming.
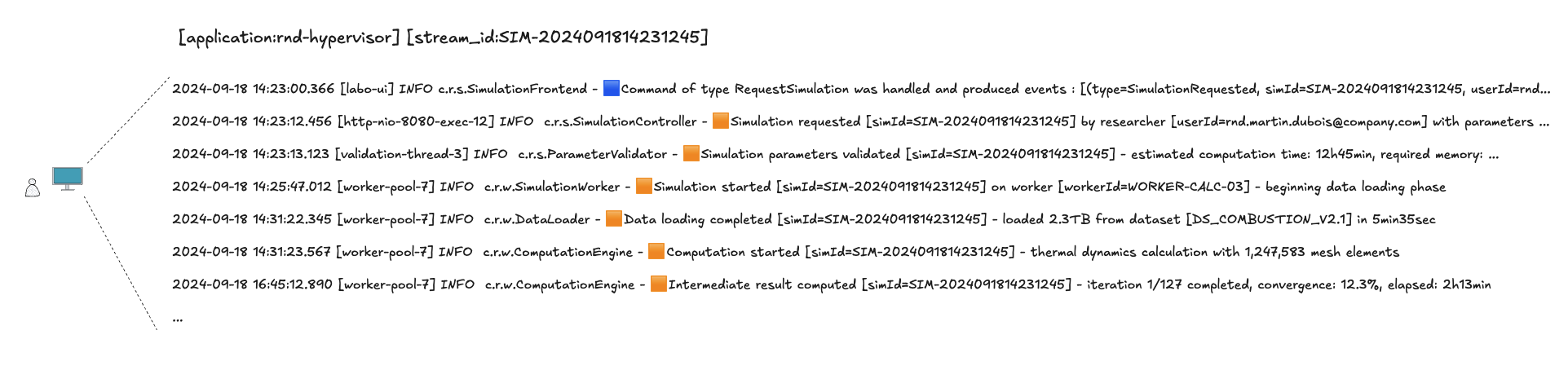
Les étapes de la simulation surgissent, en miroir de l'eventstorming
💡Remarque-bis
L’ajout de logs n’est pas toujours aisé dans tous les systèmes. L’eventstorming a mis en évidence ici que le flow de contrôle dans le code n'était pas exactement aligné sur le flow de l'eventstorming. Dans certaines situations, l’histoire racontée par le code peut en effet diverger, à tort, par rapport au modèle mental imaginé par les concepteurs du système. Ici, l’équipe a choisi dans un premier temps d’ajouter des logs pour marquer les début et fin des traitements qui composent la simulation. Une fois la simulation plus observable et la root cause des problèmes de performance identifiée, un refactoring a pu être priorisé pour ré-aligner le code avec la modélisation issue de l’eventstorming.
Quelques suggestions pour rendre votre observabilité plus impactante
Chez les clients chez qui j’interviens, l’observabilité est souvent soit absente, soit prise très au sérieux mais très centrée sur des aspects techniques. Les discussions tournent principalement autour des outils (quelle solution on achète ou déploie), et, selon moi, pas assez sur ce que je vais appeler ici l'observabilité métier.
💡 Observabilité métier
En complément de la définition de l'observabilité posée plus tôt : l'observabilité métier, c'est pouvoir observer les opérations métier réalisées par un système : comprendre ce que les utilisateurs essaient d'accomplir, pouvoir vérifier le respect (ou non) des invariants métier, pouvoir vérifier le bon respect de niveaux de service (SLA) métier.
L'obsession pour les métriques techniques peut nous faire perdre de vue ce qui compte vraiment. Voici quelques recettes que j'essaie d'appliquer dans mes projets pour rendre le métier plus observable, en concevant ma stratégie de logging autour de l'eventstorming.
Organiser sa stratégie de logging autour de l'eventstorming
- Être délibéré dans sa stratégie de logging : "on log tout, et on verra après" est une stratégie qui ne fonctionne que si les logs sont de bonne facture.
- Le livre Observability Engineering, évoqué plus tôt mentionne que des données d’observabilité utiles à capturer (soient-ils des logs ou des traces) prennent la forme d’ « arbitrary wide structured events » :
- des événements (🟧),
- structurés,
- et porteurs d’un contexte suffisamment riche pour pouvoir les exploiter.
- Le livre Observability Engineering, évoqué plus tôt mentionne que des données d’observabilité utiles à capturer (soient-ils des logs ou des traces) prennent la forme d’ « arbitrary wide structured events » :
- Faire des eventstormings, plein ! Je trouve que c'est un outil formidable pour révéler le "flux de valeur" métier et identifier les invariants métier critiques
- Un post-it orange = 1 point d'observation métier critique = 1 log dans le code. Si un événement important pour le métier apparaît dans nos discussions, pourquoi ne pas le faire non plus apparaître au moins dans un log ?
- 1 flux métier = 1 business correlation ID. Un identifiant pour marquer tous les événements liés à un usage, de bout en bout. On parle parfois de stream id dans la littérature sur l'event sourcing, par exemple pour le bon suivi de sagas métier.
- Ai-je besoin de faire de l'event sourcing pour mettre en œuvre tout ça ? Non. Je l'ai déjà appliqué dans des projets avec de la “simple” persistance d'état, sans event sourcing ni CDC. D’ailleurs, il n’y a même pas besoin de persistance opérationnelle pour discuter d’observabilité : il n’est pas nécessaire de commencer tous ses projets avec une base de données dès le premier jour.
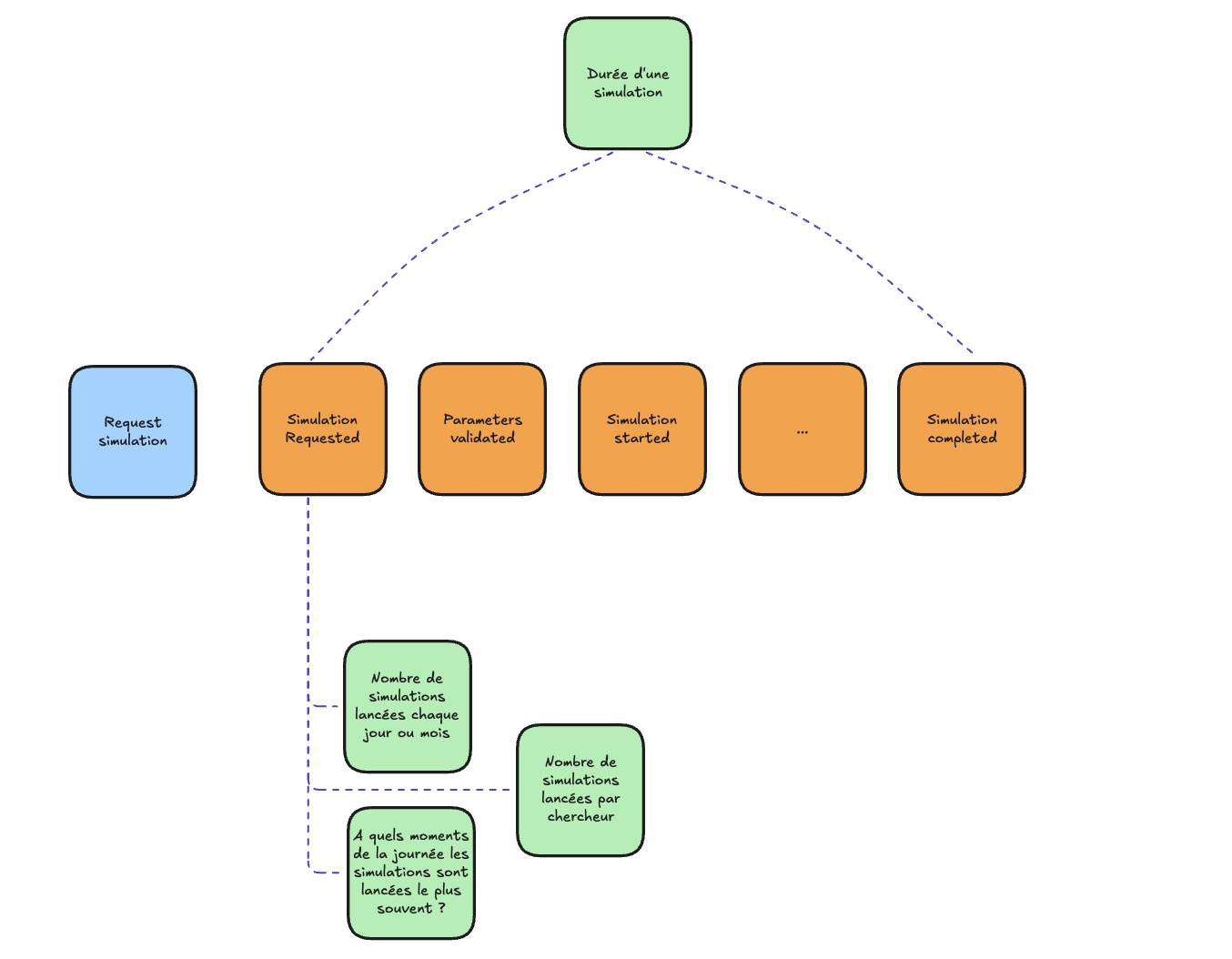
Un post-it orange = 1 point d'observation métier critique = 1 log dans le code
Travailler à la frontière entre observabilité et analytics
Orienter sa stratégie de logging de manière à ce que n'importe qui dans l'équipe, idéalement votre PO, puisse répondre à des questions essentielles sur le fonctionnement du système.
⚠️ Disclaimer
Il y a des limites à se servir d’outils d’observabilité pour prendre des décisions où le coût de l’erreur est élevé (ex: comptabilité, facturation, santé, …). Ces outils n’offrent généralement pas de garantie sur l’exactitude, la complétude ou la consistance des données qu’elles affichent. Des compromis sont faits pour favoriser la vitesse d’exécution ou limiter le coût de stockage de la donnée : donnée échantillonnée et donc incomplète, ou bien supprimée au bout d'un certain nombre de jours.
Exemples de questions sur le volet "produit"
- Combien de simulations sont lancées chaque jour ?
- Comptez le nombre de logs correspondant au post-it "🟦 Request a Simulation"
- Combien de simulations sont lancées chaque jour et se terminent avec succès ?
- Comptez le nombre de logs correspondant à "🟧 Simulation Completed"
- Ces 2 questions ne donnent pas le même résultat, pourquoi ?
- Listons les business correlation ID pour lesquels l'événement "🟧 Simulation Completed" n'a pas été loggué.
- Dans quelles situations est-ce que la validation des paramètres de simulation échoue ?
- Y a-t-il des opportunités à saisir pour améliorer l’interface de saisie de ces paramètres pour éviter ces situations et améliorer l’expérience ?
- Y a-t-il certains types de simulation qu’aucun chercheur ne fait jamais ?
- Serait-ce une bonne idée de supprimer la fonctionnalité permettant de réaliser ce type précis de simulation peu/pas utile ?
- …
Emergence de modèles de lecture (post-its verts) dérivés des événements pour mieux comprendre le rapport des utilisateurs au produit
Exemples de questions sur le volet "performance"
Je viens de lancer une simulation qui porte l'ID 7CDEFF5B-9CB5-45BB-B6DF-7E0DD6B06DBA et j’aimerais caractériser le comportement du système avant de chercher à réaliser de quelconques optimisations.
- Comment se passe cette simulation ?
- Je peux filtrer les logs pour ne visualiser que ceux où cet ID apparaît. Je peux faire l'hypothèse que le reste n'est pas important.
- Cette simulation a-t-elle démarré ?
- Je peux chercher si le log "🟦 Request a Simulation" est présent dans le sous-ensemble de logs précédent
- Cette simulation est-elle terminée ?
- Je peux chercher si le log "🟧 Simulation Completed" est présent dans le sous-ensemble de logs précédent
- La simulation est-elle toujours en cours ? Depuis quand ça tourne ?
- Combien de temps a pris la phase de chargement des données en début de simulation ?
- Combien de fois des résultats intermédiaires ont été persistés en base ?
- Où passons-nous le plus de temps ?
Je viens de réaliser un patch sur le code de la simulation : j’ai changé 1 ligne de code impliquée dans la sauvegarde des résultats intermédiaires en base de données. Je formule l’hypothèse (falsifiable) que ce patch va améliorer le temps de traitement. Je lance donc une nouvelle simulation qui porte l’ID 26C2399B-8845-485D-9B81-A420384B0366.
- Quelles données vont me permettre de valider ou réfuter cette hypothèse ?
- Comment se déroule cette nouvelle simulation ?
- Comment se déroule cette simulation au regard d’autres simulations lancées avec des paramètres comparables, toute chose étant égale par ailleurs™️ ?
- Combien de temps s’écoule entre deux sauvegardes successives de résultats intermédiaires ?
- Puis-je conclure que cette modification de code améliore les performances du système ?
- …
Exemples d’invariants métier sur la simulation, entendus à l’oral lors de discussions et lors de l’eventstorming
- Invariant : Une simulation ne peut pas se terminer avant d'avoir commencé sa phase de calcul
- Y a-t-il des simulations où le log "🟧 Simulation Completed" est présent, mais pas le log “🟧 Simulation Started” ?
- 🚨 Cet invariant est critique : une alerte doit être levée si cette situation se produit, le chercheur à l’origine de la simulation doit être notifié sur Teams pour investigation immédiate.
- Invariant : Une simulation lancée avec une précision “HIGH” ne peut pas se terminer en moins de 8h (selon le métier, c’est un signe que la simulation produit des résultats de mauvaise qualité)
- ⚠️ Cet invariant est important, mais il n’y a pas d’urgence : une alerte doit être levée si ces événements se produisent, le chercheur à l’origine de la simulation doit être notifié pour une revue des résultats dans les prochaines heures.
- Invariant : Les résultats d’une simulation ne peuvent être consultés que par le chercheur qui l’a lancé où les autres chercheurs de son département
- Nous n’avons pas couvert la consultation de résultats par les chercheurs dans notre eventstorming (c’est normal, ce n’était pas le sujet initial). Il va falloir modéliser ce parcours d’usage, ajouter les logs manquants pour observer cet invariant et livrer une nouvelle version plus observable du système !
- SLO : nous nous engageons à ce que 95% des simulations “MEDIUM” et inférieures produisent des résultats en moins de 8h ce mois-ci.
- L’heure de début de simulation (portée par “🟧 Simulation Started”) et l’heure de fin (portée par "🟧 Simulation Completed") peuvent nous donner la durée d’une simulation. Nous pouvons calculer les agrégations souhaitées (moyenne, médiane, percentiles, …) sur toutes les simulations observées.
Conclusion
Toutes ces questions (produit, performance, réglementaire, métier, ...) doivent pouvoir trouver une réponse si les événements importants sont logués.
Il est bien sûr possible de trouver réponse à ces questions sans faire tout cela. Mais pour prendre un autre exemple sans doute plus parlant, je trouve cela plus pratique de reconstituer un parcours d'achat ou le cycle de vie d'une police d'assurance en me basant sur des logs qui racontent une histoire métier explicite avec des termes signifiants, plutôt qu’en faisant de la rétro-ingénierie sur la signification de logs de requêtes HTTP.
🧩 Observer son système métier ne devrait pas être un escape game.
Si cet article vous a intéressé, je vous proposerai dans une seconde partie d’aborder des façons d’implémenter cette stratégie de logging en miroir de l’eventstorming, dans le code. On évoquera sans doute des mots bizarres mais importants tels que: pipes and filters, Middleware ou encore CommandBus 🤓.
Ressources
Pour les lecteurs qui souhaitent aller plus loin
- 📕 Observability Engineering (Charity Majors, Liz Fong-Jones, George Miranda, 2022)
- 🟧 Qu’est-ce que l’Eventstorming ? (Avanscoperta)
- 🧰 DDD starter modelling process (DDD crew)
- 🧰 Refcard sur le Domain-Driven Design (DDD) stratégique (OCTO)
- 📝 Observability Wide Events 101 (Boris Tane)
- 📘 SLO - Service-level Objectives (SRE Book, Google)
- 📝 SLI Compass: Fidelity and Granularity (Alex Ewerlöf)
- 📝 On Versioning Observabilities (1.0, 2.0, 3.0…10.0?!?) (Charity Majors)
- 📝 Live your best life with structured events (Charity Majors)
- 📝 Semantic/Synthetic Monitoring (Martinfowler.com)