Retour sur la conférence EventSourcing Live @ DDD Europe 2023
La semaine du 5 juin 2023 s’est tenue la conférence DDD Europe 2023 à Amsterdam, une conférence dédiée au domain-driven design et à la modélisation logicielle.
Nous sommes plusieurs Octos à avoir pu nous y rendre du 7 juin 2023 au 9 juin 2023 afin de couvrir une partie de cette édition 2023, notamment :
La conférence EventSourcing Live (le 7 juin 2023) : une "conférence dans la conférence" sur une journée dédiée à l’event sourcing, au CQRS et aux architectures event-driven,
Le workshop Domain Storytelling animé en parallèle par Stefan Hofer et Henning Schwentner, le 7 juin 2023,
Et enfin la conférence principale (les 8 juin 2023 et 9 juin 2023) : deux journées pour aborder des thèmes généralistes : conception logicielle, stratégie, architecture, via des talks et des hands-on labs (sessions de travail collaboratives au nombre de places limitées).
Nous vous proposons dans cet article de revenir sur la conférence EventSourcing Live du 7 juin 2023 qui proposait le programme suivant :
KISS, par Yves Reynhout
Event Sourcing in a Serverless World, par Alexei Zimarev
Beyond Aggregates: Advanced patterns for use with Event Sourced systems, par James Geall
Aggregates Composition: A new view on Aggregates, par Jérémie Chassaing
Zero-Downtime Projections Replay, par Robert Baelde
Event Driven Architecture & Governance in action, par Wim Debreuck
Event Sourcing in Action: Insights from Two Real-Life Projects, par Anita Kvamme
📸 Nous vous partageons ici notre compte-rendu et nos photos avec l'aimable autorisation de DDDEurope !
💡 Si les sujets de l’event sourcing ou du DDD vous sont inconnus, un lexique est disponible en fin d’article.
9h30 - KISS, par Yves Reynhout
Cette journée dédiée à l’event sourcing a débuté par le talk Keep It Simple, Straightforward d’Yves Reynhout.
Ce talk présente l’event sourcing comme une démarche pouvant être simple, ce qui ne coule pas de soi quand on sait que ce paradigme d’architecture a la réputation d’être complexe.
Il énumère justement les cas d’usage qui se prêtent à l’event sourcing :
Auditing capabilities
Traceability | Root cause analysis
Time travelling
For occasionally
connected systemsEnabling event-driven architecture
Observability
Analytics with business semantics
What-if analytics
Scalability
Easier bitemporal modeling
Good fit for digital twin architecture
Nous avons apprécié le contenu pédagogique de ce talk. Dès le début, Yves Reynhout nous a partagé plusieurs pointeurs pour apprendre l’event sourcing, notamment :
Un lien pour rejoindre un Discord réunissant la communauté DDD ;
Un repository Github centralisant des liens pédagogiques et des conversations autour de l’event sourcing.
Il a par ailleurs apporté des réponses claires à une dizaine de questions telles que :
Qu’est-ce que l’event sourcing ?
Quand en faire ?
Quel est le plus grand avantage de l’event sourcing ? (spoiler alert : les tests !)
Pourquoi en faire ? …
On retiendra notamment la réponse apportée à cette dernière question :
🎤 It depends […] but here is my personal motivation : to have a record of authoritative domain-specific facts that can be reinterpreted in a variety of ways, because reverse engineering the past can be next to impossible.
Enfin, une fois les slides ou le replay diffusés, on appréciera aussi revenir sur les schémas illustrant des mises en situation sur l’event sourcing, le CQRS, le pattern “breaking streams” ou le snapshotting.

Pattern read, decide, append
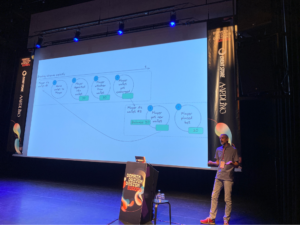
Le "breaking stream pattern"
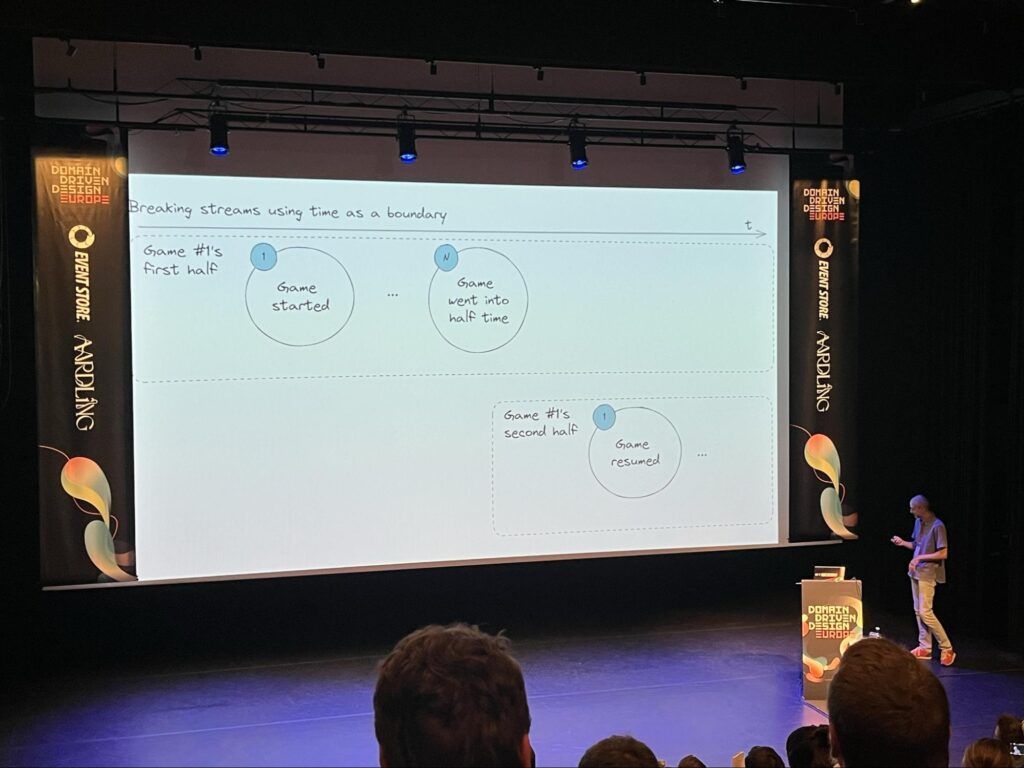
Event sourcing : le "breaking stream pattern" sur une dimension temporelle
💡 Quelques pointeurs relevés pendant cette présentation
Un repository Github centralisant des liens pédagogiques et des conversations autour de l’event sourcing
La chaîne Youtube Code Opinion
Le blog https://event-driven.io/en/ d’Oskar Dudycz, avec de nombreux articles qui portent sur le sujet des architectures event-driven
11h00 - Event Sourcing in a Serverless World, par Alexei Zimarev
L’hôte de cette conférence “EventSourcing Live”, Oskar Dudycz, annonçait en début de journée une volonté d’introduire plus de live coding et d’interactivité avec le public dans les talks.
Ce talk d’Alexey Zimarev porte sur un exemple d’implémentation d’architecture event-driven qui peut passer à l’échelle grâce à des services managés serverless.
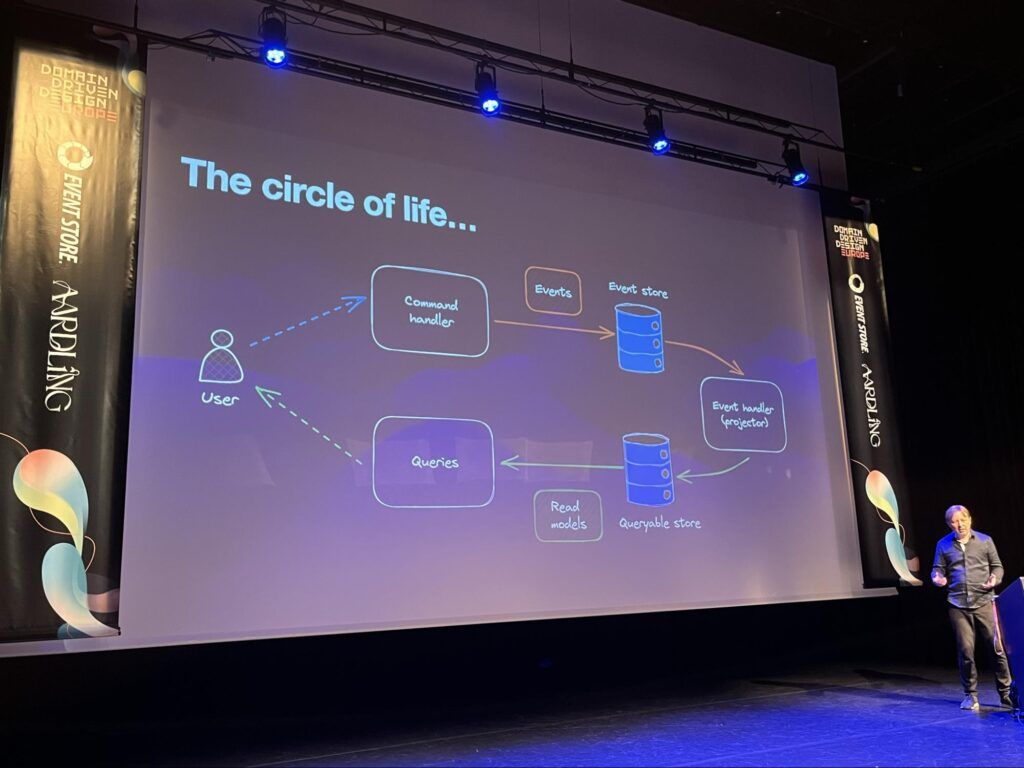
The circle of life - schéma simple d'une architecture event-driven
Ce fut le premier talk auquel nous avons assisté à proposer un format live coding, avec un bon équilibre et des aller-retours entre slides, code .NET, commandes dans le terminal et autres GUI (portail CloudRun GCP, interface OpenAPI Swagger, …).

Alexei Zimarev nous montre du code .NET pour une démo d'une architecture event-driven Serverless
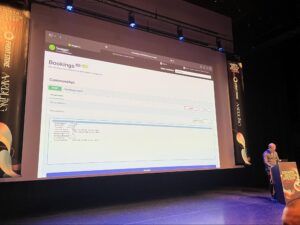
Le code .NET produit une documentation OpenAPI exécutable pour jouer des commandes et des queries
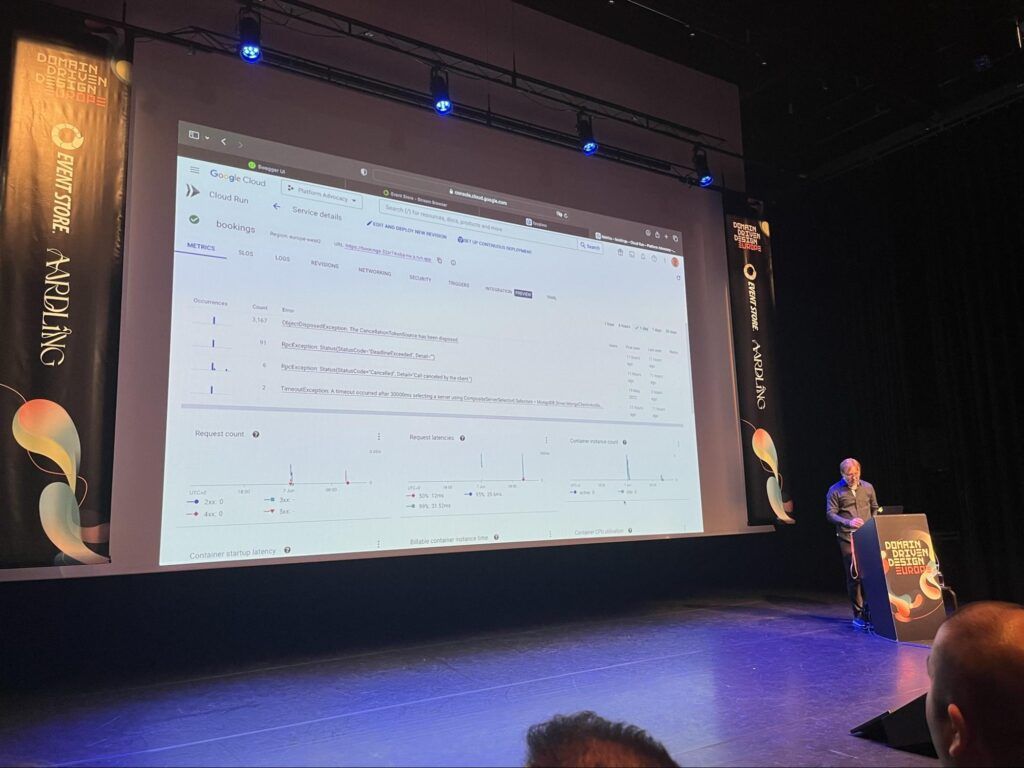
Les événements défilent dans GCP CloudRun à chaque commande traitées par le système
Pour terminer, en plus de la démo live, on retiendra de cette présentation quelques clés de lecture pour passer à l’échelle :
quels composants (command handlers, queries, event handlers, …) d’une architecture event-driven peuvent être découplés et lesquels peuvent ou non passer à l’échelle,
une liste comparative de services managés d’intérêt sur AWS, Azure et GCP pour faire du serverless,
et enfin quelques pièges à éviter en termes de partitionnement ou de stratégie d’élection de leader quand on manipule des systèmes distribués.
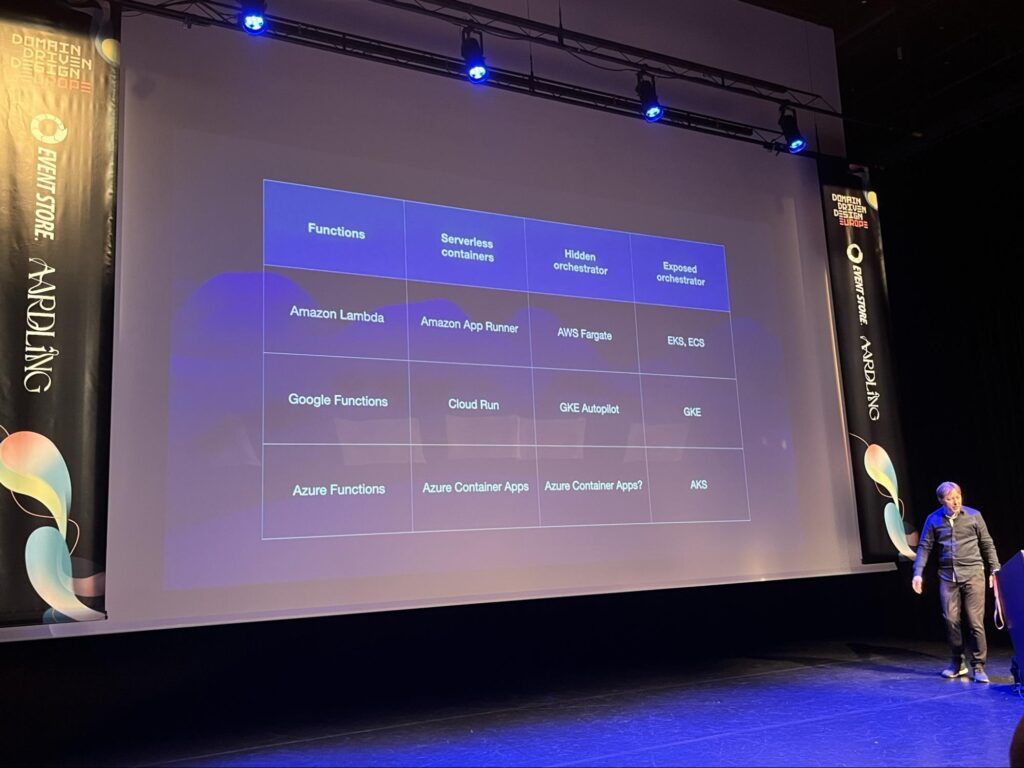
Tableau comparatif de fonctions serverless sur AWS, Azure et GCP (Kubernetes n'est jamais loin)
💡 Quelques pointeurs relevés pendant cette présentation
Eventuous, Un framework event sourcing en .NET développé par le speaker et utilisé lors de la présentation : https://eventuous.dev/
Le blog d’Alexei Zimarev : https://zimarev.com/
11h55 - Beyond Aggregates: Advanced patterns for use with Event Sourced systems, par James Geall

Ce talk de James Geall nous rappelle que l’event sourcing ne doit pas être un frein dans nos projets informatique mais un levier pour modéliser des problématiques métier.
Pour nous aider à faire cela, il présente le design pattern Process Manager initialement décrit dans le livre Enterprise Integration Patterns de Gregor Hohpe.

James Geall nous présente le pattern Process Manager
L’objectif de ce pattern est d’encapsuler et de centraliser dans un système la définition d’un processus métier complexe. Il aide à réduire la complexité de ces processus, décomposer des agrégats et détourer des zones de responsabilités.
James Geall nous met toutefois en garde, ce pattern est à utiliser avec parcimonie :
🎤 Nous pouvons être tentés de l’utiliser pour résoudre tous nos problèmes, mais c’est comme essayer de régler tous les problèmes avec un marteau, à la fin on a mal aux doigts 👍🔨.
Enfin, malgré le ton assez scolaire de la présentation et quelques confusions dans le code couleur des event stormings présentés, on a apprécié la pédagogie du speaker et les quelques exemples d’architectures dans lesquels il a éprouvé ce pattern.

😱 Trigger warning pour les pratiquants d'event storming :
les commandes sont en orange et les événements en vert 🟧 🟩 🟦


Le pattern process manager permet d'orchester des workflows relativement complexes
💡 Quelques pointeurs relevés pendant cette présentation
Le livre Enterprise Integration Patterns : https://www.enterpriseintegrationpatterns.com/books1.html
Le blog de Gregor Hohpe : https://architectelevator.com/
14h00 - Aggregates Composition: A new view on Aggregates, par Jérémie Chassaing
Ce talk de Jérémie Chassaing est le second et dernier talk de la journée à proposer du live coding, ici sur la thématique du design pattern Decider, un design pattern complémentaire au pattern Process Manager pour décomposer de la logique métier.

Le live coding de Jérémie Chassaing démarre !
Pour illustrer ce pattern, Jérémie Chassaing nous propose une expérience sans slide, uniquement à base de code F# exécuté en pas à pas dans son éditeur de code, avec quelques aller-retours dans son navigateur pour consulter les effets de bord du code exécuté dans une base de données "orientée événements" de son cru : eskv.
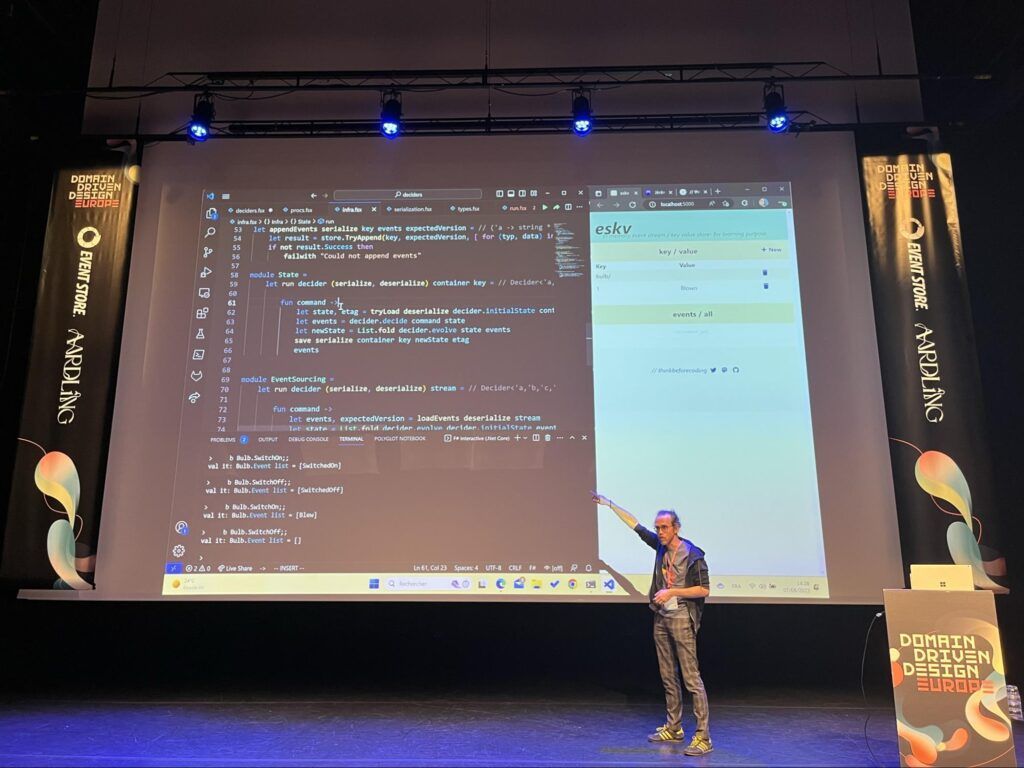
Le code F# est exécuté en pas à pas, des événements défilent dans la base eskv
Un Decider est ainsi défini par : une commande, un événement et un état actuel. Afin de pouvoir prendre des décisions, le Decider possède quelques méthodes :
“initialState” : pour connaître l’état initial,
“evolve” : pour définir un nouvel état,
“isTerminal” : pour exposer son avancement dans la prise de décision,
“decide” pour … décider ! Une décision est définie comme une commande appliquée à un état et produisant une collection d’événements.
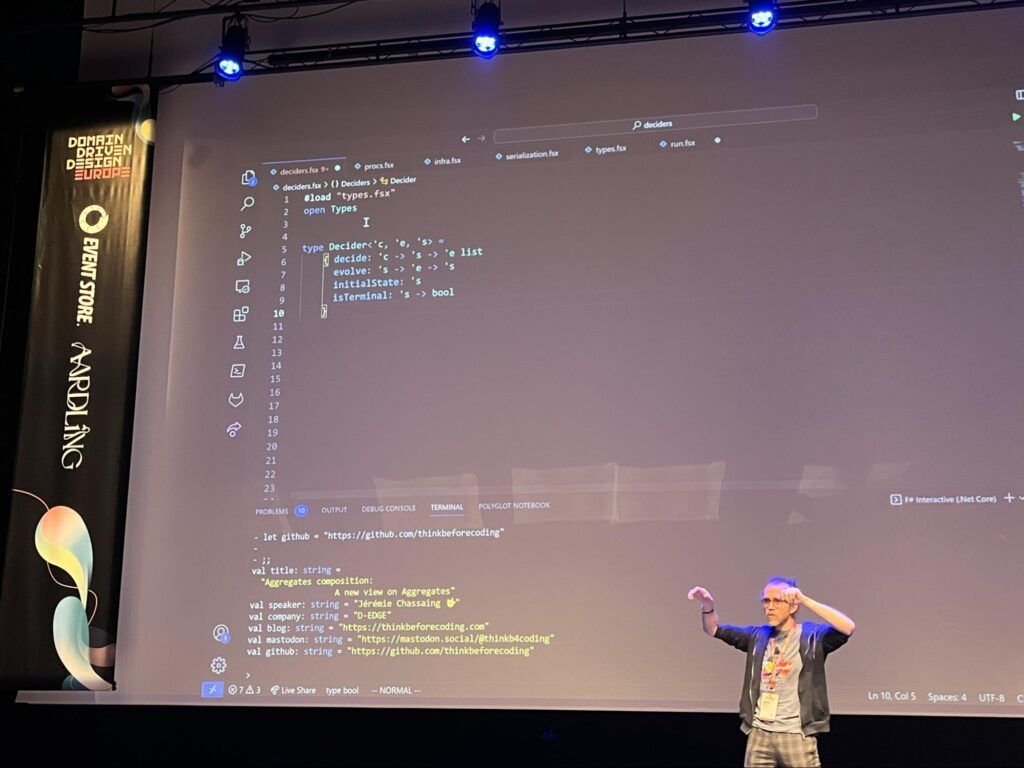
Un Decider, exprimé comme type F#
Pour illustrer le fonctionnement de ce Decider, le speaker introduit ensuite quelques nouveaux objets sur lesquels appliquer des décisions pour aboutir à des changements d’état, comme une ampoule 💡ou encore un chat 🐈.
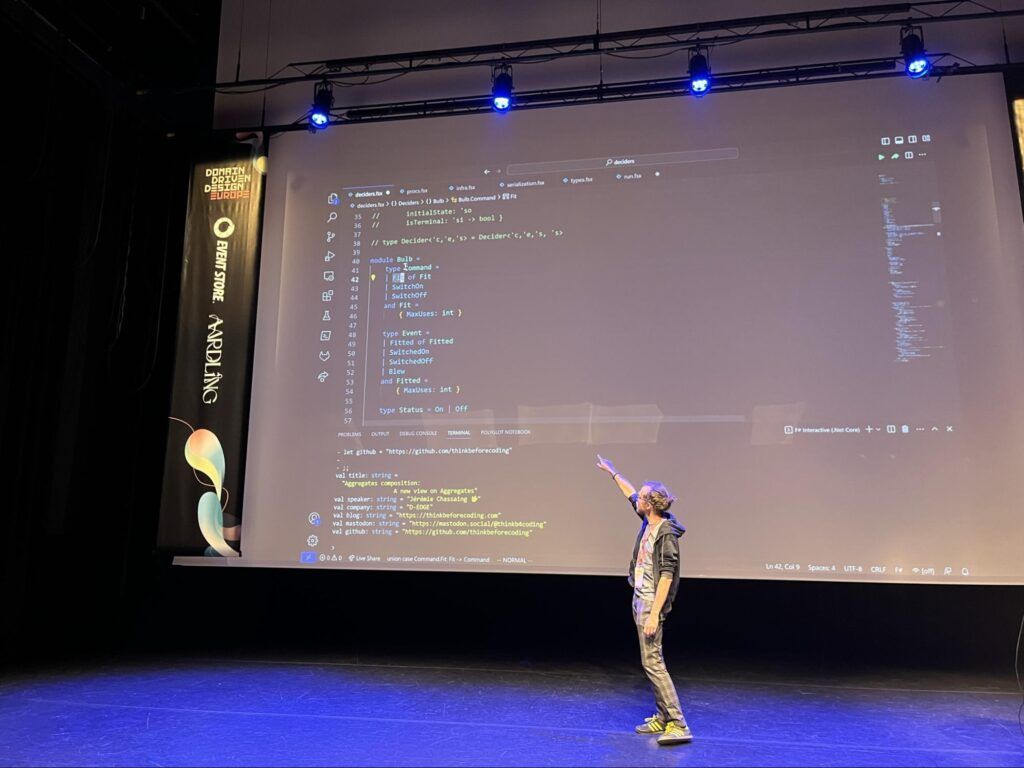
Des décisions, des ampoules 💡 et des chats 🐈
Si nous avons apprécié la prise de risque d’essayer un talk complètement tourné vers le live-coding, on regrettera quelques parti pris du speaker qui selon nous n’ont pas aidé à rendre le talk accessible aux néophytes.
Il est difficile de se concentrer sur le sujet du jour (le pattern Decider) quand la charge mentale du public est accaparée par des éléments que la plupart de l’audience découvrait en direct tels que le F# ou des patterns avancés de programmation fonctionnelle (ou simplement découvrir le concept de programmation fonctionnelle pour certains).
Si le F#, les monoïdes isomorphes, quelques termes tels que “Either”, “le folding left” ou la composition de fonctions ne vous effraient pas, n’hésitez pas à rejouer le code chez vous !
💡 Quelques pointeurs relevés pendant cette présentation
Le repo Github utilisé par Jérémie Chassaing pendant sa présentation : https://github.com/thinkbeforecoding/dddeu-2023-deciders
Son blog : https://thinkbeforecoding.com/
Son compte Mastodon : https://mastodon.social/@thinkb4coding
14h55 - Zero-Downtime Projections Replay, par Robert Baelde
Robert Baelde est venu nous partager son expérience sur l’event sourcing appliqué dans son entreprise dont il est le CTO. Il est fréquemment confronté à la problématique du rejeu de projections d’événements métier pour reconstruire l’état actuel du système depuis zéro (le replay dans la littérature).
Cette situation peut arriver quand une nouvelle projection est introduite dans le système, ou quand une projection existante voit son comportement modifié, ou pour des raisons de compliance (rejouer des événements pour supprimer des données sensibles pour des raisons RGPD, par exemple).
Robert Baelde nous sensibilise à plusieurs enjeux autour du rejeu :
Le temps de rejeu : comment concilier le rejeu et des objectifs de Zero Downtime Deployment ?
Les effets de bord de l’infrastructure, par exemple : comment s’assurer que les projections seront exécutées dans le bon ordre et pas plus d’une fois ?

Les deux principaux challenges du rejeu selon Robert Baelde
Là où les précédents talks de la journée se voulaient plus théoriques (ou avec des exemples qui tournent sur le poste local), on a bien apprécié ce retour d’expérience sur le terrain, avec quelques conseils pratiques au regard de ces enjeux : la pratique du partitionnement d’événements ou du snapshotting pour réduire le temps de rejeu, ou encore l’outbox pattern.
16h15 - Event Driven Architecture & Governance in action, par Wim Debreuck
Wim Debreuck nous a averti au début de son talk : il n’y aura pas de code dans cette présentation !
On se concentre ici sur des sujets plus abstraits de gouvernance sur la donnée d’entreprise, sur la manière de modéliser des événements (et les problèmes qui surviennent quand on néglige cet exercice), ou sur des réflexions telles que : comment le partitionnement de ma file de messages Kafka peut tirer des sujets de modélisation d’entreprise ?

Comment le nommage de topics kafka influe sur l'organisation de l'entreprise (et vice-versa)
On retiendra de ce talk un historique de l’évolution des architectures vers l’event-driven, ainsi que quelques conseils pour emprunter le chemin des architectures event-driven au travers d’un manifeste de gouvernance :
Définir des conventions de nommage de topics,
Valider les données en écriture via des schémas,
Définir des schémas de données avec des concepts clairs, compréhensibles par le métier,
Définir des politiques de rétention sur la donnée (pendant combien de temps ? quelle rétention pour quels événements ? une rétention infinie peut-elle poser problème ?),
Suivre l’operating model proposé par le speaker : design → publish → develop → deploy → operate → observe.

Evolution des architectures vers l'event-driven
Aller vers l'event-driven est un long chemin

Un operating model pour parcourir ce chemin
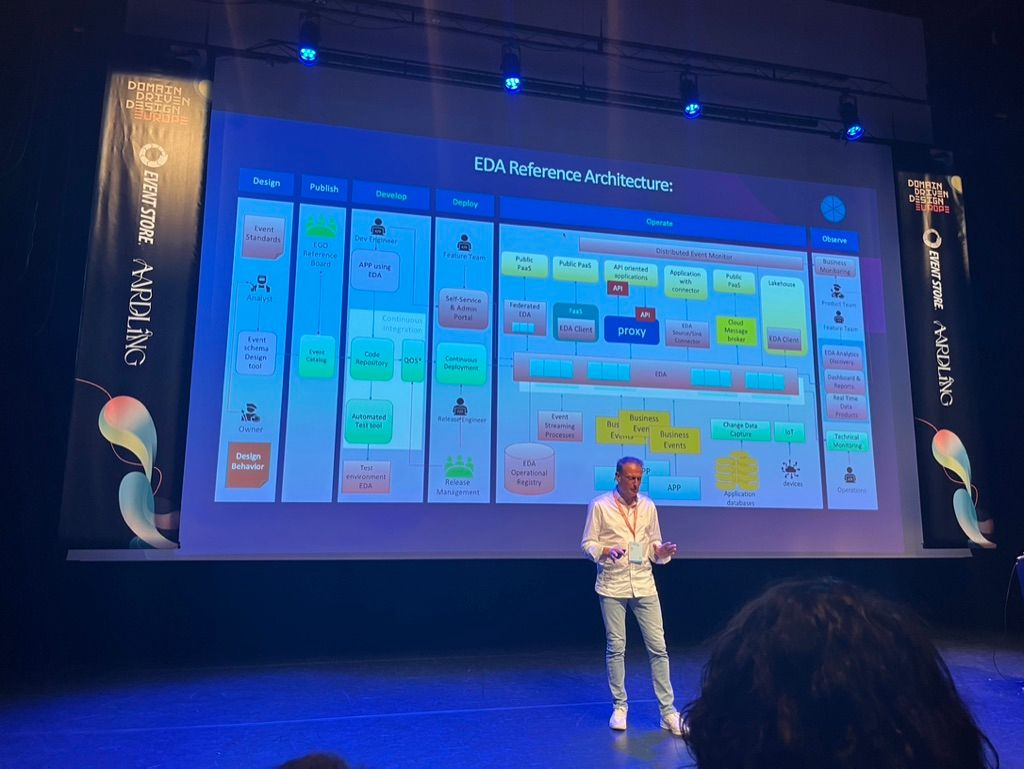
Plus de détails sur cet operating model EDA (Event-driven architecture)
17h10 - Event Sourcing in Action: Insights from Two Real-Life Projects, par Anita Kvamme
La journée s’est conclue par un talk d’Anita Kvamme qui nous a proposé un retour d’expérience sur l’application de patterns d’event sourcing dans son entreprise pendant ces dernières années.

Anita Kvamme sur scène pour le dernier talk de la conférence - Event Sourcing in Action
Quelques conseils que nous avons retenu de cette présentation
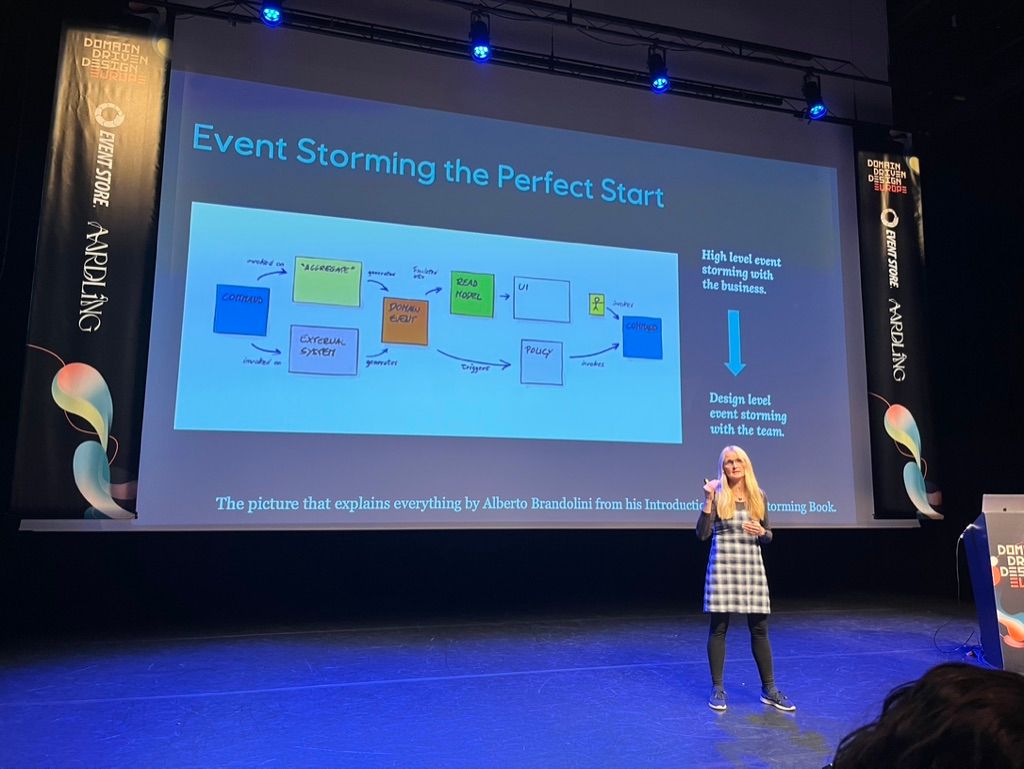
Démarrer le travail de modélisation avec un Event Storming

Quelques building blocks suffisent pour faire de l'event sourcing
S’appuyer sur quelques building blocks suffit quand on fait de l’event sourcing : des commands pour écrire, des queries pour lire, des reactors pour capturer des règles de gestion (when this happens, that happens) et un event-store pour capturer tous les faits métier d’intérêt.

Event sourcing et BDD se marient bien
L’approche BDD (Behavior-driven development) peut aider à rédiger des scénarii de tests qui exploitent efficacement ces building blocks :
Given cette liste d’événements,
When commande,
Then il se produit ce résultat/nouvel événement métier/effet de bord
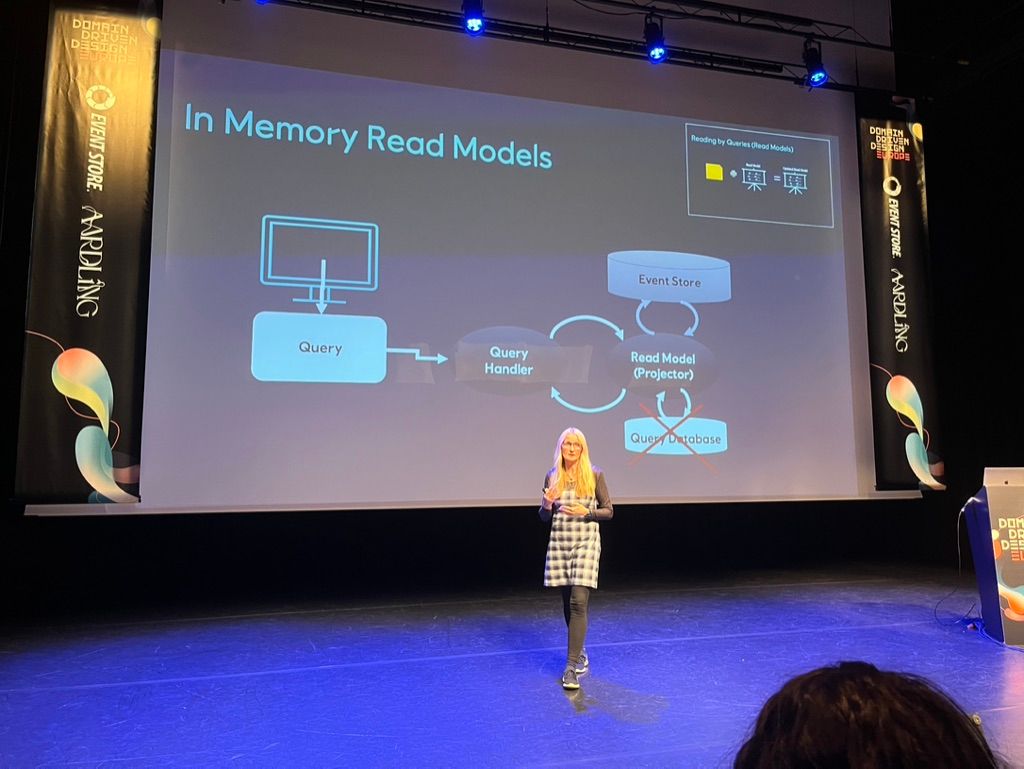
Il n'est pas toujours nécessaire de démarrer un projet avec un serveur de base de données
Il est tout à fait acceptable de démarrer un projet avec une base de données in-memory tant qu’un besoin de persistance n’est pas exprimé par les utilisateurs ou qu’on peut se permettre d’avoir un long cold start.
Anita Kvamme nous raconte avoir commencé par implémenter simplement un store éphémère en mémoire, puis découvert en production que le besoin de persistance n’était pas nécessaire sur son produit.
Il était acceptable de perdre de la donnée entre deux redémarrages de son application ainsi que d’avoir une première initialisation en mémoire assez longue, elle a donc choisi délibérément rester sur une implémentation in-memory de sa base de données d’états, économisant ainsi à son équipe de la charge de maintenance opérationnelle sur des serveurs de bases de données.
Pour finir sur ce talk, on appréciera enfin son énumération des pièges dans lesquels ne pas tomber : comment gérer les erreurs des reactors lors d’échanges asynchrones, comment interagir avec des systèmes qui ne sont pas idempotents, ne pas traiter de la même façon les événements internes à notre domaine et ceux qu’on intègre, …
Conclusion, à la fin de cette journée
Ce qu'on a aimé
La discussion sur des pratiques et patterns liés à l’event sourcing, avec les speakers et la communauté sur place,
Le côté très pratique apporté par les REX des speakers,
Le concept de "Conference Buddy". Si nous n'y étions pas allé en groupe, on l'aurait certainement essayé individuellement !
Ce qu’on aurait aimé voir
Plus de REX centrés sur quand faire ou non de l’event sourcing. Tous les speakers, sauf peut-être Yves Reynhout, sont partis du postulat que c’était la pratique la plus pertinente pour leur cas d’usage et n’ont pas pris le temps d’expliquer en quoi cela étant pertinent dans leur situation.
La plupart des talks ne précisait pas les pré-requis nécessaires pour les suivre, on a donc constaté en fin de journée que dans l’ensemble, cette journée s’adressait à une audience “entre deux” : des personnes qui ont quelques bases sur l’event sourcing sans être expertes.
Peut-être faudrait-il proposer des tracks parallèles la prochaine fois, avec des talks à destination des néophytes et d’autres pour les experts ?
On aurait apprécié voir un prérequis clair sur la programmation fonctionnelle sur le talk de Jérémie Chassaing pour pouvoir mieux l’apprécier en direct.
Enfin, la conférence principale qui a suivi cette première journée a ensuite proposé des thèmes plus généraux, plus variés, certains plus inspirants, notamment les keynotes d’ouverture (comme Systems thinking in large-scale modeling de Xin Yao) et de fermeture (Tidy First? A Daily Practice of Empirical Software Design par Kent Beck), ou encore les talks invitant des experts du monde académique, (comme Barry O’Reilly venu à nouveau nous parler du concept de résidualité, dans la continuité de l’édition de l’an dernier).
Lexique
L’event sourcing, mais qu’est-ce que c’est donc ?
Nous vous proposons un lexique avec les termes qu’il nous a paru nécessaire de connaître afin de pouvoir naviguer dans cette journée dédiée à l’event sourcing.
Domain-Driven Design (DDD)
Approche de développement logiciel cherchant à modéliser et construire un logiciel en partant des processus et des règles métier. En DDD, métier et technique collaborent de façon proche et construisent un langage commun pour construire et enrichir ce modèle. Ce concept a été introduit par le livre "Domain-Driven Design: Tackling Complexity in the Heart of Software" publié en 2003 par Eric Evans.
Pour aller plus loin :
Event sourcing
Un design pattern d’architecture, théorisé par Greg Young, dans lequel la source de vérité est modélisée sous la forme d’une collection d’événements immutables append-only : on y ajoute des événements, on ne les édite pas, on ne les supprime pas. Il devient alors possible de reconstruire tous les états du système uniquement à partir de cet historique d’événements.
Pour aller plus loin :
CQS
Command Query Separation
Principe différenciant de façon stricte les méthodes effectuant une commande de celles effectuant des requêtes, développé par Bertrand Meyer.
Pour aller plus loin :
- CommandQuerySeparation (Martin Fowler)
CQRS
Command Query Responsibility Segregation
Pattern d’architecture se basant sur le CQS, développé par Greg Young. Plus contraignant que le CQS, il consiste à séparer les modèles d’écriture de celui de lecture au sein d’une même application. Cela permet d’avoir un modèle optimisé pour l’écriture, et un ou plusieurs modèles pour la lecture, plus proches ainsi du cas d’usage qu’ils servent.
Pour aller plus loin :
Greg Young - CQRS and Event Sourcing - Code on the Beach 2014
CQRS, l'architecture aux deux visages (partie 1) - OCTO Talks !
CQRS à notre secours - Compte-rendu du talk de Florent Jaby à la Duck Conf 2021
CQRS (Martin Fowler)
Événement
Quelque chose d’important pour le métier qui a eu lieu dans le système.
Par exemple : “une entrée a été achetée”.
Commande
Une opération qui doit être effectuée dans le système.
Par exemple : “acheter une entrée”
Query
Une question qui est posée au système.
Par exemple : “combien d’entrées ont été vendues depuis le 07/06/2023 ?”
Reactor | Policy
Une policy (ou reactor) définit une réaction du système à un événement, capturée généralement avec la phrase “A chaque fois que [événement] alors [commande]”.
Par exemple :
Pay first policy : quand [une entrée est achetée] alors [demander son paiement]
Pay later policy : quand [une entrée est achetée] alors [envoyer un QR code par e-mail]
Pour aller plus loin :
- Introducing EventStorming (Alberto Brandolini)
Projection
Le processus qui permet de reconstituer l’état d’un système à partir d’une collection d’événements.
Pour aller plus loin :
Agrégat
Ensemble d’objets liés à une même thématique et ayant un cycle de vie commun. Comme Oskar Dudycz l’a défini lors de son hands-on “Slim down your aggregates” animé pendant la conférence principale, c’est comme une transaction : on agrège toutes les données qui ont besoin de changer en même temps.
Pour aller plus loin :
Behavior-driven Design (BDD)
Approche consistant à coupler la spécification et documentation du comportement attendu, du code et son test. Cette approche passe typiquement par l’écriture et la maintenance de tests fonctionnels écrits en langage naturel grâce à des frameworks comme Cucumber ou Specflow.