You Only Look Once - un réseau de neurones pour la détection d'objets
Nous, les humains, avons un système visuel rapide et précis, ce qui nous permet d'effectuer des tâches complexes comme la conduite avec peu de réflexion consciente. En effet, nous savons inconsciemment quels sont les objets que nous voyons, où ils se trouvent et comment ils interagissent.
Au cours des dernières années, des algorithmes rapides et précis se sont mis en place pour la reconnaissance d'objets dans une image. Plus de détails sur ces différents algorithmes dans la page wikipédia : https://fr.wikipedia.org/wiki/Reconnaissance_de_formes. La reconnaissance d'objets est un terme général pour décrire un ensemble de tâches de vision par ordinateur qui impliquent l'identification d'objets dans des photographies numériques. Il existe différents types de reconnaissance d’objets :
- La classification d'images consiste à prédire la classe d'un objet dans une image.
- Entrée : une image avec un seul objet.
- Sortie : une étiquette de classe.

- La localisation d'objets consiste à identifier l'emplacement d'un ou plusieurs objets dans une image et à dessiner un cadre de délimitation autour de leur étendue.
- Entrée : une image avec un ou plusieurs objets.
- Sortie : un ou plusieurs cadres de délimitation.

- La détection d'objets combine ces deux tâches et dessine un cadre de délimitation autour de chaque objet dans l'image et leur attribue une classe.
- Entrée : une image avec un ou plusieurs objets.
- Sortie : un ou plusieurs cadres de délimitation et une étiquette de classe pour chaque cadre de délimitation.

Dans cet article, nous allons tout d’abord survoler l’approche globale d’un des réseaux de neurones qui permet de faire de la détection d’objets sur des images, à savoir le réseau de neurones You Only Look Once plus communément appelé YOLO puis, nous allons entrer plus en profondeur sur son comportement ainsi que son architecture pour au final, voir à travers un cas particulier la détection d’objets se trouvant sur la route tels que les feux tricolores, les panneaux de direction, les piétons, etc en installant une caméra dans une voiture et en récupérant les images prises par cette dernière.
You Only Look Once - approche générale
Il s'agit d'une famille populaire de modèles de reconnaissance d'objets est appelée YOLO ou « You Only Look Once », décrite pour la première fois par Joseph Redmon et al. dans l'article de 2015 intitulé “You Only Look Once: Unified, Real-Time Object Detection.” (https://arxiv.org/abs/1506.02640). Ce modèle réalise une détection d’objets en temps réel : il traite les images à 30 images par seconde (IPS).

Le fonctionnement de YOLO
L'approche implique un réseau de neurones qui met bout-à-bout une multitude de neurones et qui prend une photo en entrée et prédit directement les cadres de délimitation, plus communément appelés "bounding box", et les étiquettes de classe pour chaque cadre de délimitation.
Le modèle fonctionne en divisant d'abord l'image d'entrée en une grille de cellules, où chaque cellule est responsable de la prédiction d'un cadre de délimitation. Une prédiction de classe est également basée sur chaque cellule.
Par exemple, une image peut être divisée en une grille 7 × 7 et imaginons que chaque cellule de la grille peut prédire 2 cadres de délimitation, ce qui donne 98 prédictions de cadres de délimitation proposées. La carte des probabilités de classe et les cadres de délimitation avec confiance sont ensuite combinés en un ensemble final de cadres de délimitation et d'étiquettes de classe. L'image ci-dessous résume les deux sorties du modèle.
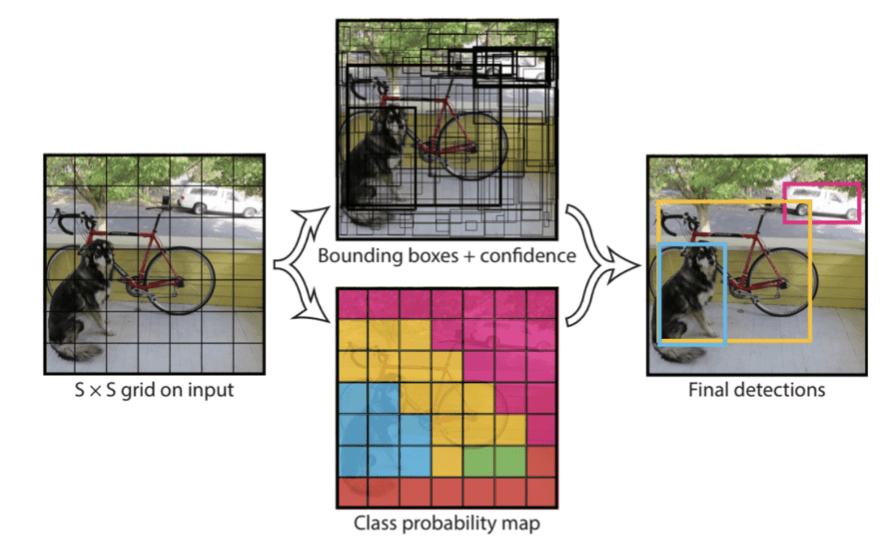
Exemple de la prédiction faite par YOLO
Plus en profondeur
Dans un premier temps, comme dit dans l’introduction, YOLO applique une grille sur l’image qui ne sert pas à segmenter l’image, pour analyser séparément chaque portion, comme le ferait un R-CNN. En effet, Le R-CNN est une architecture de détection d'objets qui commence par extraire des régions intéressantes de l’image, puis utilise ces régions comme données d’entrée pour un CNN. Cette séparation en régions permet de détecter plusieurs objets de plusieurs classes différentes dans une même image. Pour plus de détails sur le fonctionnement du R-CNN, se référer à la page towards data science : https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e.

Au contraire, avec YOLO, les carrés de la grille sont utilisés pour générer un certain nombre d’anchor boxes. Ces anchor boxes sont un des concepts les plus difficiles à saisir lors de l'apprentissage des réseaux de neurones convolutifs pour la détection d'objets. C'est également l'un des paramètres les plus importants que vous pouvez régler pour améliorer les performances de votre ensemble de données. En fait, si les anchor boxes ne sont pas réglés correctement, votre réseau de neurones ne saura jamais que certains objets petits, grands ou irréguliers existent et n'aura jamais la chance de les détecter.
Une anchor box est une boîte englobante (un rectangle sur l’image) définie d'une certaine hauteur et largeur (voir l’image ci-dessous en bleu). En effet, L'utilisation d’anchor boxes permet à un réseau de détecter plusieurs objets, des objets d'échelles différentes et des objets qui se chevauchent.

La première étape, tout naturellement, est de se débarrasser de toutes les anchor boxes qui ont une faible probabilité qu'un objet soit détecté. Cela peut être fait en construisant un masque booléen (tf.boolean_mask dans tensorflow), et en ne gardant que les cases qui ont une probabilité supérieure à un certain seuil. Cette étape élimine les détections anormales d'objets.
Cependant, même après un tel filtrage, on se retrouve avec de nombreuses anchor boxes pour chaque objet détecté. Mais nous n'avons besoin que d'une seule boîte. Cette-ci est calculée à l'aide de la suppression non max https://leonardoaraujosantos.gitbook.io/artificial-inteligence/machine_learning/deep_learning/single-shot-detectors/yolo#:~:text=Maxima%20Suppression%20(nms)-,During%20prediction,-time%20(after%20training
La suppression non max fonctionne comme suit :
- On supprime les anchor boxes ayant une probabilité inférieure à un certain seuil, 0.6 par exemple;
- on sélectionne l’anchor box avec la probabilité de détection la plus élevée;
- on supprime les anchor boxes qui intersectent l’anchor box sélectionnée en 2) ayant un IoU supérieur à un certain seuil, 0.5 généralement. En clair, on supprime les anchor boxes trop proches les unes des autres dans cette étape car elles labelisent le même objet;
- on répète 2) et 3).
Dans l’étape 3, la suppression non max utilise un concept appelé « Intersection over Union » ou IoU. Il prend en entrée deux anchor boxes et, comme son nom l'indique, il calcule le rapport de l'intersection et de l'union des deux.
Pour mieux comprendre comment est calculé cet indice, zoomons sur l’image et concentrons-nous sur les anchor boxes vert et jaune :

IoU
L’IoU est calculé en divisant l’intersection des 2 anchor boxes par leur union. En d’autres termes, la formule revient à diviser la partie rouge par la partie bleue.
En général, on considère que :
- Si IoU > 0.5 entre 2 anchor boxes, cela signifie qu’elles labellisent le même objet.
Après l’exécution de l’algorithme, l’image finale est la suivante. Là, nous pouvons remarquer que l’IoU permet de réduire la sélection d’anchor boxes en passant d’une vingtaine d’anchor boxes à seulement 2 qui caractérisent ici 2 objets, à savoir, la voiture et la personne :

Détection finale d’objets grâce à YOLO
Sur cet exemple, cela paraît simple : la grille est petite, il y a peu d’anchor boxes... Mais en pratique, cela ressemble plutôt à l’image ci-dessous. Dans cette suite d'images, nous remarquons que l’image a été découpée en plusieurs carrés (image 1) qui permettent de générer plusieurs anchor boxes (image 2). L’IoU est ensuite calculé pour regrouper les anchor boxes qui détectent le même objet (nous pouvons le voir à travers les groupes de couleurs sur l’image3). Puis finalement, grâce à l’algorithme de Non-Max Suppression, nous passons de milliers d’anchor boxes à seulement 2 pour détecter un chien et un vélo (image4) :

Architecture de YOLO
Après avoir étudié le comportement général du réseau de neurones YOLO, nous allons maintenant nous intéresser à son architecture. YOLO se compose d'un total de 24 couches convolutives suivies de 2 couches entièrement connectées. Les couches sont séparées par leur fonctionnalité de la manière suivante :
- Les 20 premières couches convolutives sont pré-entraînées sur l'ensemble de données de classification ImageNet 1000-class.
- Les couches comprennent des couches de réduction 1x1 et des couches convolutives 3x3.
- Les 4 dernières couches convolutives suivies de 2 couches entièrement connectées sont ajoutées pour entraîner le réseau à la détection d'objets avec notre base de données.
- La couche finale prédit les probabilités de classe et les cadres de délimitation.
→ C'est une technique classique d'entraînement par transfert (transfer learning). On prend un modèle déjà entraîné sur une tâche assez générique et on le spécialise sur une tâche d'intérêt en re entraînant uniquement les dernières couches du réseau avec des données spécifiques à cette tâche. (Pour en savoir plus : https://en.wikipedia.org/wiki/Transfer_learning)
→ L'entrée est une image de 448 x 448 et la sortie est la prédiction de classe de l'objet enfermé dans la boîte englobante.
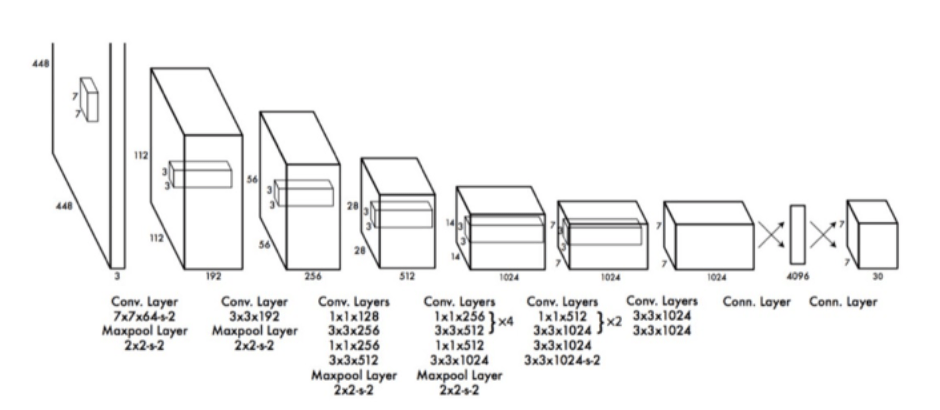
L’architecture de YOLO
Et dans la pratique, ça donne quoi ?
Cas particulier : voitures autonomes
Il est temps maintenant de mettre en pratique les notions abordées dans les parties précédentes à travers un cas particulier, à savoir le cas des voitures autonomes. En effet, pour qu’une voiture puisse circuler sans conducteur, plusieurs points doivent être mis en place tels que l’accélération, le freinage, la direction de la voiture, etc. Dans notre cas, nous allons nous focaliser uniquement sur la détection de certains objets sur la route à savoir : 
Notre but est d’intégrer une caméra dans une voiture afin que cette caméra détecte ces objets se trouvant sur la route.
Création de la base de données
Pour atteindre ce but, nous commençons par installer une caméra dans une voiture en déplacement en agglomération. Nous filmons la route du côté passager de la voiture un jour d’été (dans ce cas pratique, les différentes conditions météorologiques n’ont pas été prises en compte) pendant 2 minutes 30. Puis, au moyen d’un script, nous récupérons une image pour chaque seconde de vidéo, soit au total 150 images. Ci-dessous une image parmi les 150 de notre base de données :

Exemple d’une image de la base de données
Labellisation
Une fois cette base de données créée, nous labellisons ces images grâce à un projet open source nommé “YOLO Annotation Tool”, particulièrement adapté pour une utilisation des données sur YOLO (https://github.com/ManzarIMalik/YOLO-Annotation-Tool).
Cette labellisation consiste, pour chaque image du jeu de données, à tracer des rectangles autour des objets que l’on souhaite reconnaître, en précisant pour chaque rectangle la classe de l’objet qu’il désigne (feu rouge, voiture, piétons...). Comme on peut le voir dans l’image ci-dessous, nous avons tracé les 3 rectangles roses en leur assignant la classe de voiture puis les 2 rectangles bleus représentant les feux rouges.
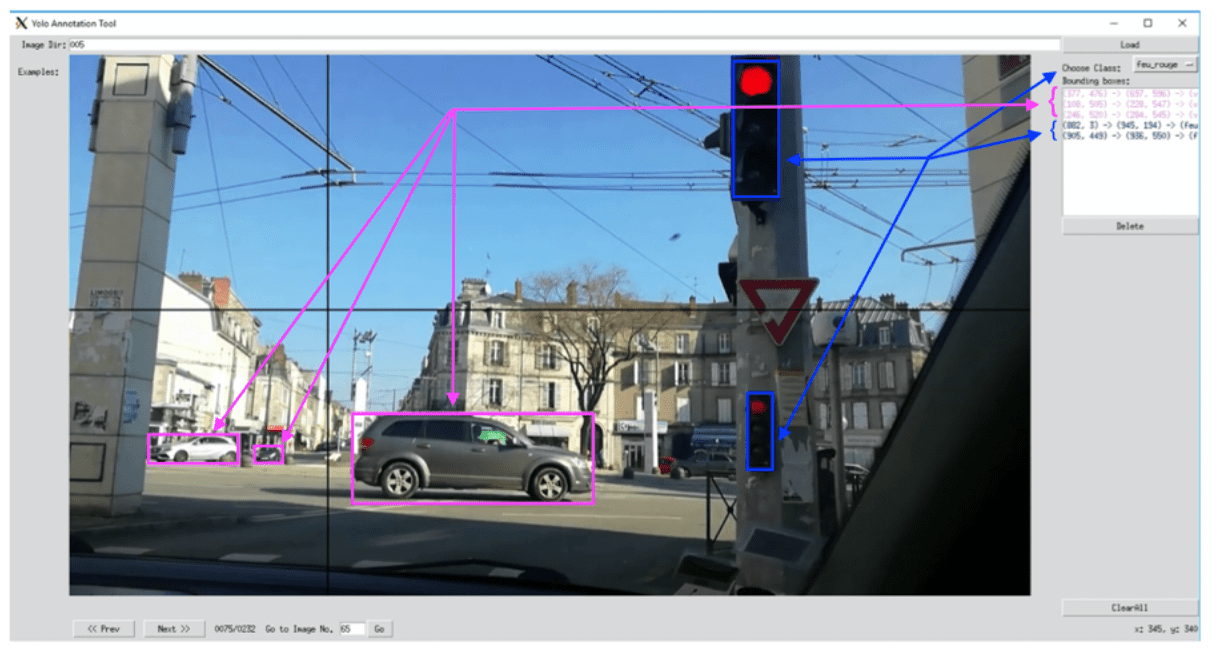
YOLO Annotation Tool : Exemple de labellisation
Cela va produire pour chaque image un fichier texte contenant les informations de classe et de position sur l’image de chaque objet labellisé. Puis, nous utilisons ce fichier texte pour ré entraîner les 4 dernières couches du réseau à la détection d'objets avec notre base de données.
Exécution de l’algorithme
Pendant l'entraînement des dernières couches du réseau de neurones YOLO avec notre base de données, voici ce que l’on voit :

Sorties pendant l'entraînement de YOLO
- 5981 : nombre d’itérations,
- Avg loss : l’erreur moyenne → On s’attend à ce qu’elle soit la plus petite possible et on se sert de cela pour décider quand arrêter l’entraînement ;
- Rate : taux d’apprentissage utilisé pour mettre à jour les poids ;
- Image : le nombre d’images total pour l’entraînement ;
- Loaded : le temps pour changer les images ;
- Region Avg IoU : l’Intersection over Union ;
- Class : la moyenne des probabilités des vrais positifs. Si on prend l’exemple de la troisième ligne 94,00 % des objets détectés dans cette sous-division appartiennent à leurs classes correctes ;
- Obj : la probabilité que la boîte contienne un objet ; Dans cet exemple, l’entraînement est à 57.96 % confiant que les boîtes englobantes contiennent un objet;
- No Obj : même chose que précédemment mais pour les endroits où il n’y a pas d’objet, donc on s’attend à des valeurs basses ;
- Avg Recall : parmi les objets à détecter, le nombre d’objets qu’il a réellement détectés;
- Count : le nombre total d’objets détectés dans cette subdivision.
Une fois le réseau entraîné, voici le résultat sur une image donnée :

Résultat après entrainement de YOLO sur une image donnée
On remarque que le réseau a bien détecté les trois panneaux de direction et les deux voitures.
Conclusion
YOLO est un réseau de neurones qui traite toute l’image d’un seul coup d’où le nom “You Only Look Once”, ce qui va lui permettre de faire de la détection en temps réel sur des vidéos. Rappelons qu'il traite les images à 30 images par seconde (IPS). Cette détection en temps réel est un véritable atout notamment pour des cas d’usage bien précis comme l’exemple vu de la voiture autonome ou encore de la réalité augmentée.
En effet, après avoir installé une caméra dans une voiture en déplacement et après avoir récupéré les images prise par la caméra, YOLO nous a permis de faire de la détection d’objets sur la route tels que les feux tricolores, les panneaux de direction, les piétons ainsi que les voitures.
Toutefois, YOLO n’est pas le seul modèle existant capable de faire de la détection. Il en existe plusieurs autres tels que R-CNN, fast R-CNN, faster R-CNN...
Mais ce qui rend YOLO différent de ces derniers est sa vitesse d’exécution. En effet, les différents modèles du type "R-CNN" vont définir, pour chaque image en entrée (selon des méthodes spécifiques aux différentes versions de R-CNN), un ensemble de régions susceptibles de contenir un objet recherché. Le réseau de neurones va analyser chacune de ces régions séparément et déterminer si elles contiennent un objet ou non, et si oui, la classe correspondante. Pour chaque image passée en entrée, le réseau va donc devoir définir et analyser une multitude de régions, ce qui prend du temps.