WIP de 1, une histoire de WIP limits qui finit bien
Au début de notre projet, nous avions des WIP limits (Limitation du Work In Progress/Process). Elles sont vite devenues gênantes, et nous les avons supprimées. Mais un jour nous avons eu une douleur qui nous a décidés à réinstaurer des WIP limits ; et pas n'importe lesquelles : des limites de 1. Dès l'itération suivante, nous avons très significativement amélioré notre productivité.
Avoir des WIP limits ne se justifie que si elles répondent à une douleur partagée. Sinon, c'est du Kanban by the book et ça n'a pas de sens. Lorsque ces limites sont portées par l'équipe entière, les résultats sont remarquables.
Qu’est-ce qu’une WIP limit ?
Les WIP limits sont une composante de Kanban. Kanban est un framework d’amélioration continue issu de la pensée Lean. Il vise à équilibrer capacité et demande dans un système complexe**[1]**. Kanban propose notamment de visualiser son flux de travail, souvent sous la forme d’un tableau où chaque colonne est une étape d’un processus - de production de software dans notre cas. Sur ce tableau se déplacent de gauche à droite des tickets figurant un incrément de code (un apport de valeur (User Story - US), une correction (Bug), une tâche technique, etc.).
Exemple de flux :
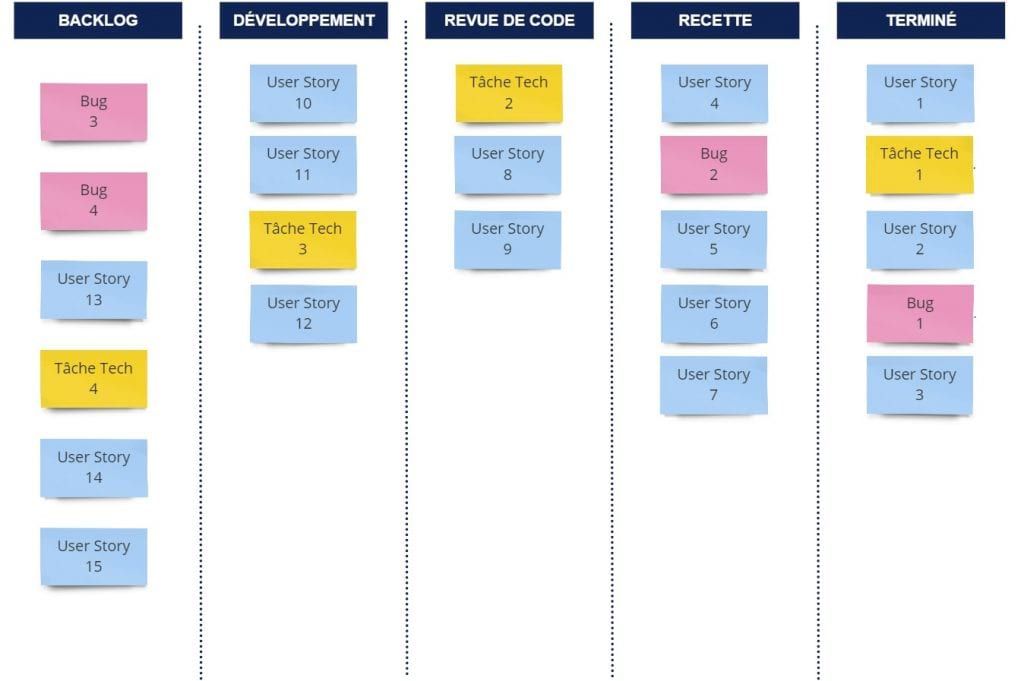
Kanban repose fondamentalement sur l’optimisation du système (plutôt que sur l’optimisation des ressources). Et dans cette logique, un des principes de Kanban est de limiter le travail en cours. Une implémentation possible est de borner pour chaque étape (chaque colonne), le nombre d’activités (de tickets) en cours. Ceci afin de favoriser la concentration des énergies et de limiter le temps passé sur chacune des tâches. On peut résumer cette idée par cette injonction désormais célèbre “Stop starting, start finishing![2]”. La WIP limit est la matérialisation de ce nombre maximum de tickets autorisés dans une colonne.
Exemple de flux avec des WIP limits :
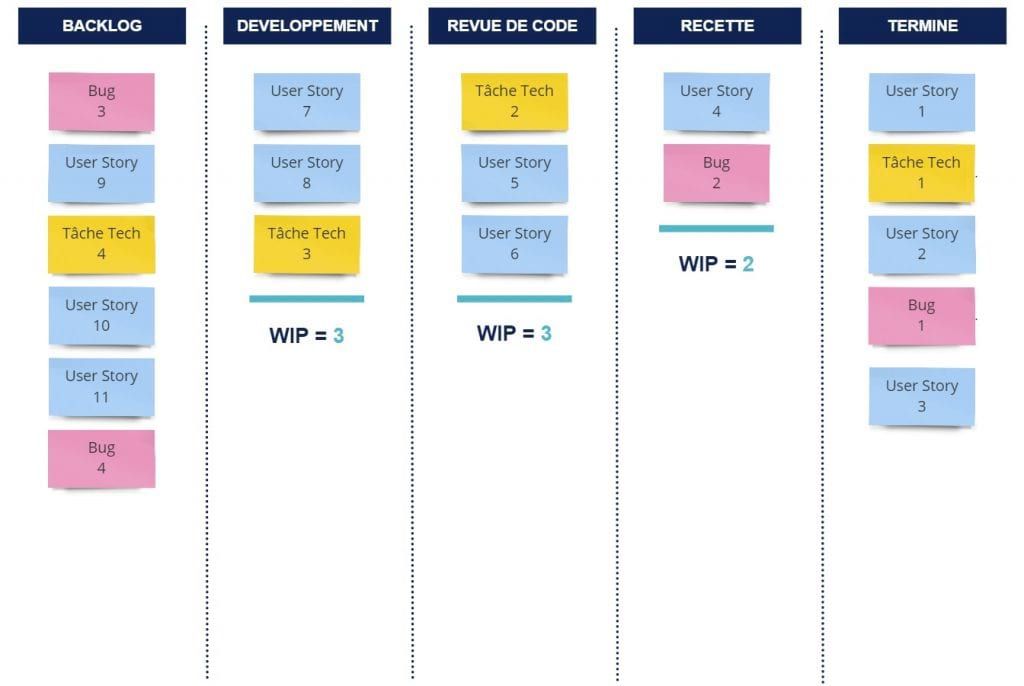
Pourquoi la WIP de 1 ?
Le contexte
Nous développons un applicatif aux règles métiers très spécifiques. Notre core-team est composée de 7 Développeurs et 2 Product Owners (PO ; 1 PO client et 1 CoPO / Delivery Manager). Un temps, un Ops a fait partie l’équipe pour mettre en place l’usine de développement qui, entre autres, automatise nos déploiements. Nous faisons du feature flipping et nous utilisons GitHub Flow.
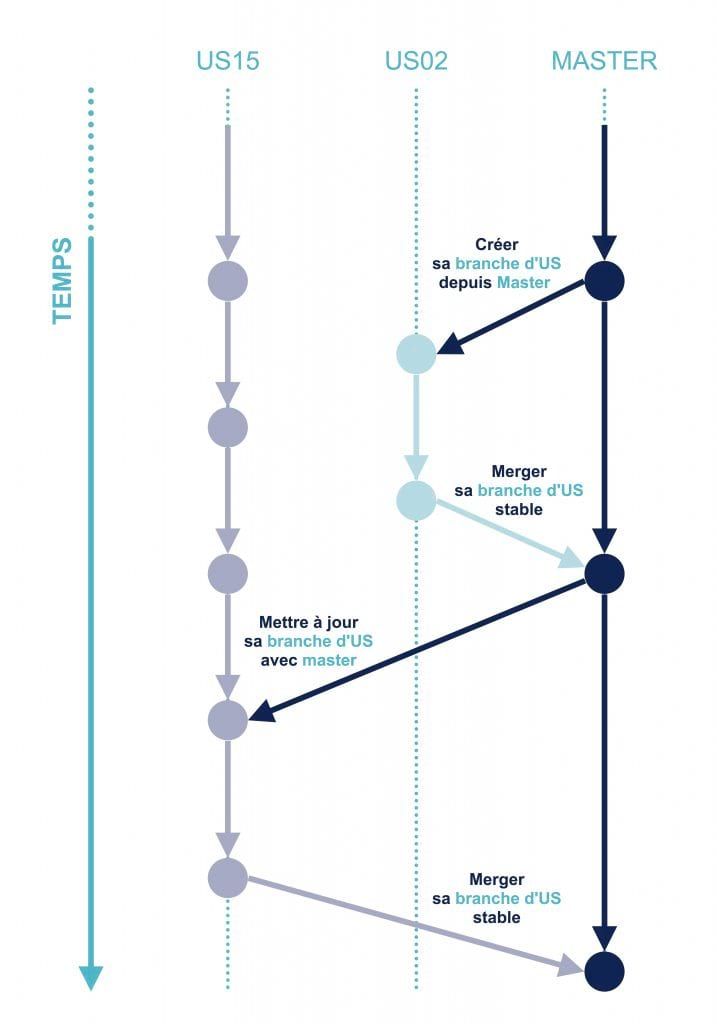
Ce qui signifie que le code développé pour chaque ticket doit être mergé**[3]** sur master**[4]** pour être testé sur l'environnement de recette ; puis le même build (la même version de l'application) est déployé sur les environnements de pré-production et de production.
Avant la MEP (Mise En Production)
Au début de notre projet, nous avons construit notre workflow (flux de travail) en fixant des WIP limits par activités, en appliquant une limite cumulative pour les colonnes En cours et Terminé de chaque activité. La quantité maximale s'applique donc à l'addition du nombre de tickets se trouvant dans les deux colonnes concernées. Nous avons fixé ces limites en appliquant la règle du nombre de personnes disponibles pour cette activité + 1, en ayant en tête qu’il s’agissait de valeurs par défaut que nous aurions à adapter aux réalités de notre projet.
Notre flux initial :
Nous avons mis une petite semaine avant de faire sauter notre première limite, et les autres ont suivi (ce qui est aussi une manière de les adapter aux réalités de notre projet…). Ces limites s'opposaient à nous sans raison ni justification, c'étaient elles les douleurs, on les a supprimées l'une après l'autre, et ça a duré des mois comme ça.
Nous n'étions pas en production (nous n'avions pas d’utilisateurs, notre service n'était pas ouvert). Nous n'avions donc aucune urgence à faire des MEP et peu importait le temps que nous mettions à déployer sur l'environnement de production.
Après la MEP, la douleur
Puis on a ouvert le service, nous avons eu des clients : nous étions passés en production pour de vrai (et pas juste sur un environnement qui s'appelait Production). Et là, la douleur est apparue. La question de déployer dès que possible nos développements en production est devenue cruciale. Et nous ne faisions pas autant de MEP que nous l’aurions souhaité, en tout cas pas autant que nous le permettait notre super usine de développement automatisée. Des développements prêts ne pouvaient être déployés car master comportait en permanence du code indésirable (par code indésirable, j'entends du code mergé qui n'a pas été testé ou qui a été testé et nécessite des corrections) : le temps de mettre un ticket OK, d'autres étaient mergés sur master, qu'il fallait tester et éventuellement corriger. Ça n'en finissait plus, nous avions toujours une bonne raison de ne pas mettre en prod.
Le remède
Une fois la douleur partagée en rétrospective**[5]**, nous avons réfléchi collectivement à une solution nous permettant d’améliorer cette situation, de livrer le plus vite possible en production les développements terminés. Ce devait être d'autant plus simple que les opérations de déploiement en tant que telles sont automatisées et rendues anodines par notre usine de développement (ce qui est un préalable). Nous en sommes arrivés à cette conclusion : pour livrer rapidement, il nous faut livrer unitairement. Pour livrer unitairement, il nous faut recetter unitairement. Pour recetter unitairement, il nous faut merger unitairement. Et nous avons rendu opérationnelle cette logique.
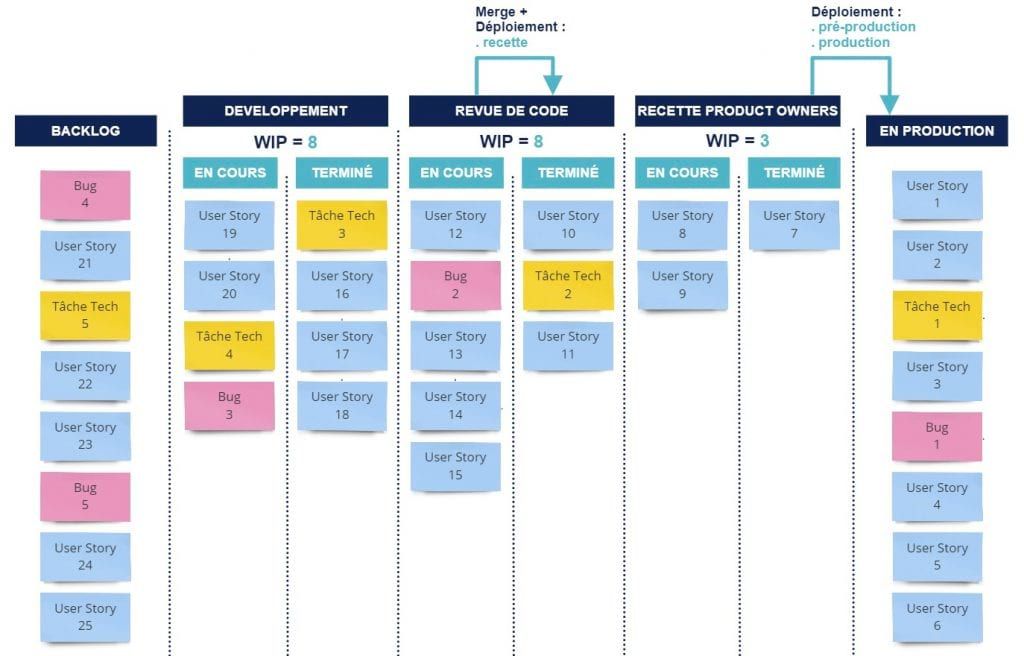
Concrètement, l’équipe a décidé de passer la WIP limit de la colonne Recette PO en cours à 1 et de déplacer le merge au passage de la colonne Revue de code terminée à Recette PO en cours. Les merges seront désormais faits à la demande des PO, au moment où le ticket est pris pour recette ; ce qui peut nécessiter de temps à autre un rebase**[6]** supplémentaire après la fin de la revue de code, mais l'équipe accepte ce prix. Nous avons également fait du déploiement en préproduction (sur lequel les PO ont la main) une DOD**[7]** du passage à Recette PO terminée. En poussant la réflexion, nous avons fait remonter le principe de WIP de 1 à l'étape de Revue de code en cours et à sa queue qui est l'étape de Dev terminé. Les tickets ne peuvent donc sortir du développement (Dev en cours) qu'un par un. Ce qui crée une tension : si je viens de finir un ticket et que personne n'a pris la revue de code du ticket qui le précédait, je suis coincé et donc dans l'obligation de faire cette revue pour pouvoir faire bouger mon ticket terminé. En remontant encore, nous avons fixé la WIP limit du Dev en cours à : (nombre de développeurs -1). Ce qui nous assure de toujours avoir un développeur disponible pour faire une revue de code, corriger une anomalie détectée en recette, se mettre en pair programming avec un autre membre de l’équipe ou en mob programming si la situation le permet ou le nécessite.
Nous pouvions d’autant plus nous offrir le luxe de la radicalité d’une WIP limit à 1 que nous sommes relativement isolés de contraintes externes. Nous avons peu d'adhérences avec des systèmes externes, et donc peu de risques d’avoir des tickets bloqués après la colonne Dev en cours pour une raison que nous ne maîtrisons pas.
Notre flux modifié :
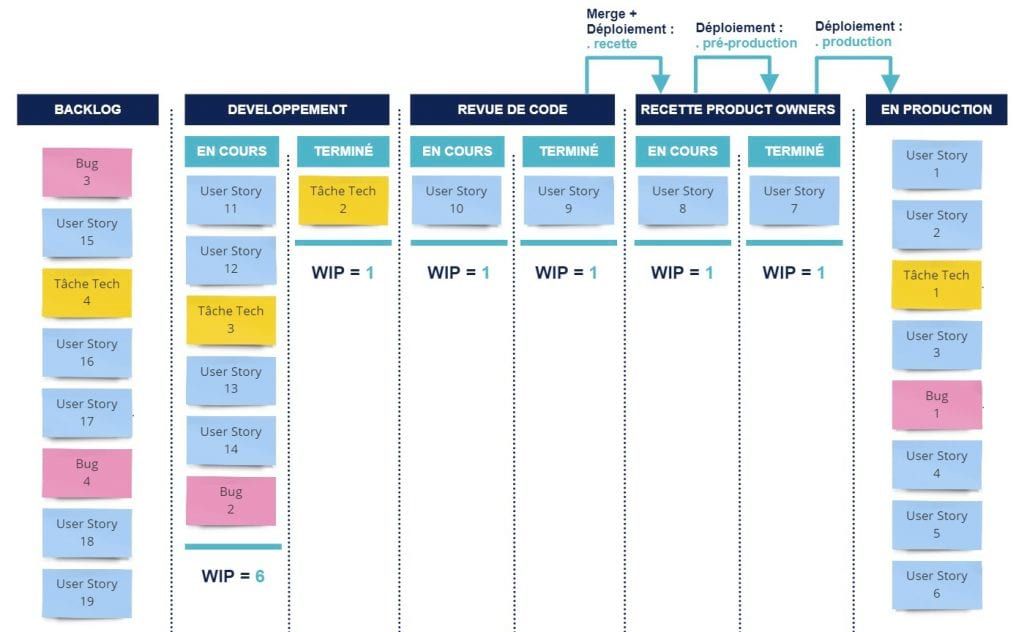
Pour quels résultats ?
Ces modifications nous ont permis d’atteindre notre objectif initial de manière spectaculaire : dès l’itération suivante, nous avons multiplié par 3 notre nombre de MEP.
Nous avons désormais les douleurs que nous avons choisies. C’est-à-dire, un flux ralenti, voire bouché, aussitôt qu'un ticket passe trop de temps en Revue de code ou en Recette PO. Et, nous l’escomptions, la réaction à cette douleur va naturellement dans le sens de la solidarité : les personnes impactées par le bouchon viennent aider à le résorber (à faire passer le ticket douloureux) en se rendant disponibles pour du pair ou du mob programming. De même, lorsque deux tickets pourraient sortir plus ou moins en même temps de Dév en cours, deux développeurs deviennent disponibles pour des revues de code. Comme il n’y a qu'un seul emplacement dans la colonne Revue de code en cours, ces deux tickets ne peuvent être revus en parallèle par chacun des développeurs disponibles. Ils sont donc revus successivement et en pair.
Les bénéfices
Du point de vue du produit, ces modifications de WIP limits et de DOD ont eu des effets qui ont dépassé notre objectif initial. Non seulement nous avons augmenté la fréquence de nos MEP, mais nous avons également multiplié par 3 le nombre de tickets livrés par itération. C’est à dire que nous livrons plus d’US par itération et que nous avons diminué significativement notre stock de bugs. Nous livrons donc plus de valeur, de manière plus régulière, et avons augmenté la qualité du produit.
Pour ce qui concerne l’équipe, tout ceci facilite la propriété collective du code et du flux, la montée en compétence des nouveaux, encourage la courtoisie dans les merges, rend plus immédiat le traitement des retours de revue de code et limite les ajustements détectés en Recette PO (le comportement est discuté et éventuellement amélioré lors des revues en pair).
Cette expérience nous a montré la puissance de la limitation de l’encours ; son impact sur l’efficacité d’une organisation.
La contrainte, lorsqu’elle est décidée et plébiscitée par une équipe, devient un levier remarquable pour canaliser l’énergie là où elle crée le plus de valeur.
__________________________ [1] Cf. framework Cynefin ↩ [2] Stop Starting, Start Finishing! Arne Roock and Claudia Leschik. (USA: Lean-Kanban University, 2012). ISBN 978-0985305161 ↩ [3] Merger : action d’incorporer le code nouvellement développé dans la base de code commune du projet (master). ↩ [4] Master : base de code commune dans laquelle le code correspondant à chaque ticket développé doit être incorporé (mergé). ↩ [5] Rétrospective : Rituel agile consistant à une introspection collective permettant notamment d’identifier des pistes d’amélioration continue. ↩ [6] Rebase : Action de récupérer la base de code commune (master) à jour avant d’y incorporer de nouveaux développements (de merger). Si du code a été ajouté à la base commune (master) entre le début de mes développements et leur fin, un rebase me permet de m’assurer que mes développements s'incorporeront correctement dans la base de code à jour. ↩ [7] DOD - Definition Of Done : Ensemble des conditions devant être remplies pour qu’un ticket passe d’une colonne à l’autre. ↩