Streamlit, PyVista et Ipyvolume : Créez une Visualisation 3D Interactive
Le premier article présentait notre cas de représentation de structures cristallines, ainsi que les librairies impliquées dans les visualisations 3D : PyVista et Ipyvolume. Il est maintenant temps de mettre cela en musique dans une application plus “professionnelle”, au moyen de Streamlit.
L’application Streamlit
Streamlit était un candidat naturel pour cette application : très simple à prendre en main, adapté à la data science exploratoire, c’est un juste milieu entre les notebooks et les applications industrielles qui sont très robustes et flexibles mais ont un coût d’entrée supérieur. Pour un prototype à vocation didactique comme celui-ci, nous n’avons pas besoin de sécurité, de scalabilité ou de monitoring ; cela nous permet de garder le code facile à lire. Vous trouverez d’ailleurs une introduction à Streamlit dans cet autre article du blog.
Pour nous, tout le code de l’interface, y compris celui faisant appel à Ipyvolume, se trouve dans un fichier : viz/app.py. Les réglages sont déportés dans la sidebar, tandis que la partie principale de la page affiche les visualisations. Voici la maquette :

Pour lancer l’application depuis la ligne de commande, il faut utiliser cet appel, où samples/ est le répertoire avec les fichiers .xyz :
crystalz$ python -m streamlit.cli run crystalz/viz/app.py -- --xyz-dir samples/
La commande “canonique” est streamlit run ..., mais bizarrement elle ne permet pas d’importer des modules applicatifs qui ne sont pas dans les packages parents. Or dans notre cas, l’application est dans un module parmi d’autres, elle a besoin de “remonter” l’arborescence des packages pour importer des modules cousins. Vous trouverez la discussion qui nous a sauvé la vie à cette adresse.
D’un point de vue programmation, le déroulement de la boucle Streamlit est le suivant :
run_app(): enregistrer et récupérer les paramètres réglés par l’utilisateur (fichier.xyz<br>, couleurs, taille du cube, résolution, méthode de calcul du potentiel)render_structure(): afficher la structure cristalline avec PyVistarender_voxels(): afficher le potentiel avec Ipyvolume
Streamlit + PyVista + Ipyvolume
C’est dans les fonctions render_XXX() que se trouvent les intégrations avec PyVista et Ipyvolume, et cela mérite de s’y attarder un peu. Il faut savoir que ces librairies sont, avant tout, destinées à s’exécuter dans un notebook de type Jupyter. Les objets qu’elles manipulent sous le capot sont des widgets IPython : Jupyter sait quoi en faire, mais pas Streamlit ! Pour les afficher, nous devons les “sérialiser” sous forme de code HTML et embarquer le code généré dans la page.
La génération du code HTML est assez simple, elle revient à créer l’extrait de code HTML correspondant aux widgets. Le tout est de savoir exactement ce qui répond au contrat des widgets dans les objets manipulés par les librairies. Un petit tour dans leur code source donne la puce à l’oreille :
import ipywidgets.embed as wembed
# Créer une nouvelle figure
ipv.figure()
# Créer et paramétrer des graphiques dans la figure (exemple avec Ipyvolume)
ipv.volshow(...)
# Récupérer l'HTML !
# Il contient les ressources annexes type code javascript, les widgets de contrôle
# (ex. curseurs de réglage de la fonction de transfert), etc.
# Pour PyVista, remplacer ipv.gcc() par l'objet scene renvoyé par plotter.show()
html = wembed.embed_snippet(ipv.gcc())
html = f'{html}'
C’est le bon moment pour expliquer pourquoi ce système marche de manière aussi simple, et quelles sont ses limites. Streamlit ne sait bien sûr pas gérer les widgets du monde IPython. Il possède la notion de composant HTML, rudimentaire, via l’appel streamlit.components.html(). Ce type de composant est entièrement géré par le navigateur : l’HTML est embarqué dans une <iframe> et n’a pas moyen simple de communiquer avec le reste de l’application. De fait, les widgets PyVista et Ipyvolume doivent être autonomes. C’est le cas parce que, tels qu’ils sont conçus, ils viennent avec un état qui est embarqué dans le code HTML qui les représente. L’état en l’occurrence c’est les données, les géométries à afficher, leurs matériaux (couleurs et éclairage), etc. Chaque <iframe> porte tout cela, avec les codes Javascript qui permettent à l’utilisateur de manipuler les vues 3D sans interagir avec le serveur. Elles sont aussi étanches, elles ne risquent pas d’interférer entre elles en tirant par exemple des versions incompatibles de dépendances Javascript. Beaucoup d’avantages donc.
Le revers de la médaille, c’est qu’il n’est pas simple de s’abonner, côté Python, à des actions que l’utilisateur ferait sur les vues 3D pour déclencher du code serveur, ou même d’asservir deux représentations entre elles dans le navigateur. Le code HTML produit par les widgets contient des ID aléatoires que nous ne pouvons pas récupérer et réutiliser pour lier la sauce. Inversement, les modifications apportées aux paramètres Streamlit vont relancer la construction des graphiques de zéro, état par défaut et enrobage HTML + Javascript compris (essayez de faire tourner les figures et de changer un paramètre innocent, comme la résolution des voxels : les cubes reviennent à leur position initiale).
Dans notre cas, simple, tout ceci ce n’est pas un gros problème, même si l’ergonomie pourrait en être améliorée.
On peut résumer toute cette discussion par le schéma ci-dessous :
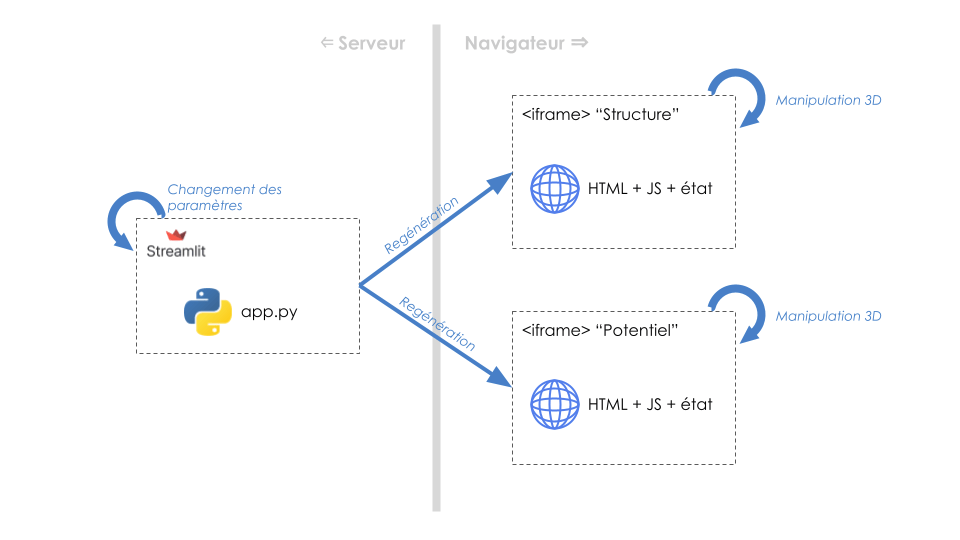
Gestion de l’état serveur et performances
Streamlit possède sa propre notion d’état (à ne pas confondre avec celui des widgets décrit plus haut), soit par le biais de sessions, soit pour les besoins simples par le biais du cache (annotation @st.cache). Dans l’application, nous avons utilisé le cache pour optimiser deux fonctions : le calcul de la fonction de transfert monochrome pour Ipyvolume, et l’énumération des fichiers .xyz présents dans le répertoire passé en paramètre de l’application. Ce n’est pas très coûteux, mais nous n’avons pas envie d’appeler le système à chaque fois que l’utilisateur bouge un curseur, alors que la liste ne va vraisemblablement pas changer.
On pourrait se dire que le cache serait bien plus utile là où l’application passe du temps : dans le calcul du potentiel, qui fait intervenir quelques calculs matriciels sur un tableau à 3 dimensions. L’ennui c’est ledit tableau est gros (plusieurs dizaines de milliers à plusieurs millions d’éléments selon la résolution), qu’il prend par conséquent de la place, et que le cache va accumuler ces tableaux en mémoire à chaque fois qu’un paramètre change, que ce soit la résolution, la taille du cube ou le fichier .xyz à représenter. Notre application est à vocation exploratoire, il est peu probable que l’utilisateur passe ses journées à regarder les quelques mêmes graphiques en boucle. En fait, pour optimiser ce temps de calcul, et massivement, il faudrait suivre d’autres pistes. En voici quelques-unes, plus ou moins subtiles, avec de gros gains probables à la clef :
- générer toutes les combinaisons possibles d’avance, en parallèle bien sûr, et stocker les tableaux NumPy sur disque…
- utiliser plus intelligiment la vectorisation de NumPy, qui évite les boucles et les changements de contexte Python / C
- réécrire le calcul en Cython – on peut utiliser NumPy depuis le code Cython pour ne pas réinventer la roue
- utiliser des librairies de vectorisation “automagique” comme Numba
A titre d’exemple vécu, la traduction de ce genre de code en Cython peut faire gagner un ou deux ordres de grandeur au temps de calcul…
L’écosystème de visualisation 3D
Jusqu’ici, nous avons expliqué nos choix d’implémentation par les besoins particuliers de notre application, en retenant des librairies qui “font le job”. On a notamment justifié l’utilisation de deux librairies différentes pour ces visualisations. En fait, il y a un autre critère qui nous a guidés : la facilité. Les alternatives ne manquent pas, plus riches mais aussi plus complexes, et adaptées à la création d’applications robustes. Il y a même trop d’alternatives.
Sans prétendre à l’exhaustivité, une petite cartographie des librairies de visualisation 3D dans le navigateur peut aider à y voir plus clair.
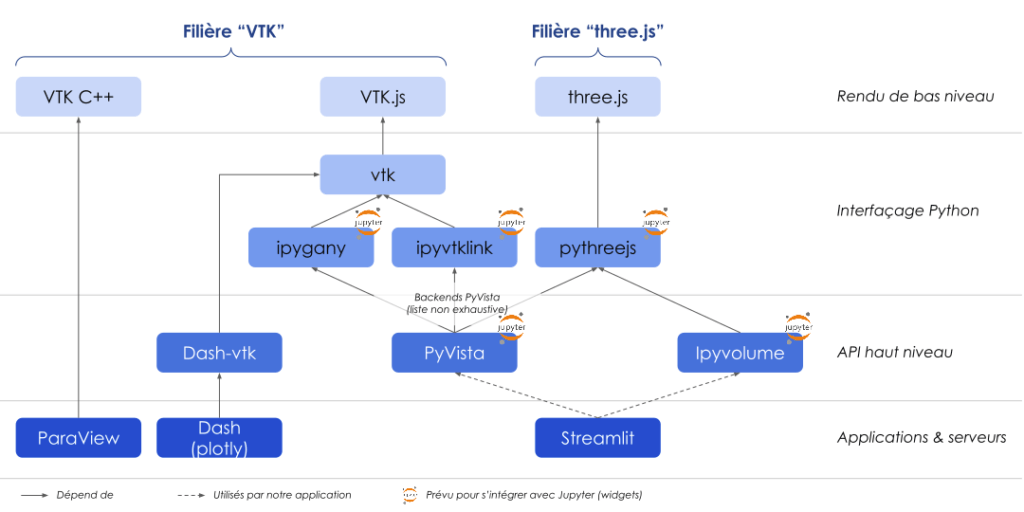
Ce qu’il faut en retenir :
- l’écosystème est diablement compliqué !
- deux librairies se retrouvent au niveau le plus élémentaire, pour le navigateur du moins : VTK.js, et three.js. Elles sont toutes deux très riches, mais pour en tirer parti, encore faut-il que les surcouches que l’on emploie côté Python exposent cette richesse – si possible avec une API de haut niveau, adaptée à l’usage visé (réalité virtuelle, data, …). Pour les applications de données, il faut par exemple que la communication frontend/backend, la (dé)sérialisation des tableaux NumPy, etc., soient transparentes, et que le développeur se préoccupe moins de géométrie pure que de la mise en forme de ses données numériques
- à partir des premières couches Python, beaucoup de librairies sont conçues pour fonctionner avec Jupyter, qui semble donc la plateforme de référence pour les applications de données à base de 3D interactive. Les deux exceptions, Dash et ParaView (un environnement de visualisation scientifique, client lourd, scriptable en Python), sont d’ailleurs des plateformes à part entière
Pour l’anecdote, voici ce que nous avons testé dans le cadre de cet article.
Dash, de Plotly, et son extension dash-vtk : ils couvrent nos deux besoins de visualisation, sans poser de problèmes d’intégration puisque Dash est une plateforme de développement complète (il prend la place de Streamlit). Cependant dash-vtk se révèle difficile à prendre en main faute de masquer suffisamment la complexité de VTK. La documentation en ligne suppose une familiarité avec ce dernier, ce qu’en toute modestie, nous ne possédons pas. Pour le coup, VTK est destiné à couvrir tout le spectre de la réalité virtuelle, pas la visualisation de données, et il n’a pas été conçu pour s’interfacer avec l’écosystème data de Python. Avec plus de temps et d’effort, ce serait sans doute la meilleure solution pour une application complète.
L’utilisation d’Ipyvolume de bout en bout : le rendu précis de la structure cristalline s’est avéré compliqué, faute de disposer d’une primitive pour les sphères. Il y a bien un scatter plot en 3D, mais le rayon des marqueurs (nos sphères) ne peut pas être contrôlé finement en coordonnées absolues. Nos atomes en auraient été déformés.
L’utilisation de PyVista de bout en bout : nous nous sommes heurtés à l’impossibilité de faire un rendu volumétrique (le potentiel). La plupart des backends (pythreejs, ipygany,…) ne savent pas “gérer” les volumes. Plus exactement, les adaptateurs de PyVista, qui traduisent les objets de la scène en primitives comprises par les backends, ne connaissent que les maillages. Un seul backend semble honorer les volumes, ipyvtklink ; malheureusement il ne marche pas en dehors d’un environnement Jupyter (au lieu de “sérialiser” une scène autonome pour VTK.js, il génère des images à la volée et les envoie par les canaux de communication client/serveur de Jupyter).
Pour finir, c’est aussi la simplicité qui nous a fait faire le choix de Streamlit comme serveur d’applications. Flask ou Django, par exemple, auraient été plus appropriés pour de la production. Cela n’aurait sans doute pas changé grand-chose pour l’intégration avec PyVista et Ipyvolume, qui étaient la cible principale de cet exercice.
Conclusion
Avec ce petit exemple, nous voyons qu’une visualisation 3D interactive, de nature scientifique, est à portée de main. Si elle est adaptée à un usage modéré, il y a du travail pour aller un cran plus loin en direction d’une application complète. Insistons sur le fait que nous avons fait le choix de la simplicité pour créer rapidement ce prototype, et non d’un développement complet qui serait plus robuste. En décortiquant les composants de l’application, et leurs capacités d’intégration, nous avons tout de même une meilleure idée des choix qu’il faudrait faire,et de l’effort à fournir pour redévelopper l’application dans un contexte plus industriel.
Notre application est finalement bien sympathique, et l’intégration de Ipython avec Streamlit a été sans douleur. Si l’ergonomie est rudimentaire, les visualisations sont efficaces, les manipulations 3D à la souris plutôt intuitives. Après tout, nous voulions construire une application d’exploration, n’est-ce pas ?
Si vous avez manqué la première partie, nous vous invitons à la lire ici : Visualisation scientifique 3D avec Streamlit, PyVista et Ipyvolume (partie 1)