Visualisation et compréhension des réseaux de neurones convolutionnels
Les réseaux de neurones convolutionnels permettent d’effectuer diverses tâches de traitement d’images, comme de la reconnaissance d’images ou la détection d’objets. (Cf article sur le fonctionnement des réseaux de neurones ici)
Dans la suite de cet article, nous nous pencherons sur le cas réseaux de neurones convolutionnels pour la classification d’images afin de garder une trame simplifiée et cohérente. Lors de l’entraînement d’un réseau de neurones, on juge la qualité des résultats à l’aide de certaines métriques. Des images sont fournies en entrée et une mesure de la capacité de l’algorithme à réaliser correctement une tâche (classification par exemple) est calculée en sortie. On s'attend à ce que la valeur de la fonction de coût (loss) diminue au cours de l’entraînement et qu’au contraire, celle de la précision, du recall et de l’accuracy augmente. Le problème avec ces métriques est qu’elles ne nous donnent aucune information sur la manière dont le réseau de neurone a traité l’image pour aboutir à ce résultat. L’intérieur du réseau de neurones est souvent considéré comme une boîte noire complexe dont les résultats sont peu interprétables.
Cette complexité est dû, entre autres, à la profondeur d’un réseau de neurones, définie comme le nombre de couches convolutionelles qui constituent le réseau, là où plusieurs millions de paramètres sont optimisés pour prédire un résultat : la classe la plus probable par exemple.
Un réseau de neurones entraîné est donc constitué de plusieurs millions de paramètres utilisés lors d’opérations mathématiques sur une image d’entrée (ce qui reste assez abstrait de notre point de vue). On peut considérer l’ensemble de ces paramètres comme sa « représentation mathématique de la réalité ». Pour mieux comprendre ce qu’il se passe dans cette boîte noire, on voudrait “jeter un oeil à l’intérieur”.

Figure 1 : Exemples de résultats de classification d’un de neurones convolutionnel
Cela soulève plusieurs interrogations :
- Comment mes images sont analysées et traitées par le réseau de neurone ?
- Mon réseau de neurones est-il capable de saisir toutes les informations importantes d’une image, utiles à sa classification ?
- Quelles zones de l’image mon réseau de neurone “regarde” ?
- Quelle est la « représentation de la réalité » du réseau de neurones ?
Nous allons voir différentes méthodes qui permettent de rendre ces boîtes noires plus transparentes, en ayant un retour visuel du système.
Quels intérêts à déchiffrer un réseau de neurones ?
Essayer de comprendre ce qu’il se passe dans un réseau de neurones permet, d’une part, au data scientist de mieux entraîner son modèle. En effet, on parle souvent d’« intuition » lorsque le data scientist est amené à choisir la complexité de son modèle et à entraîner son réseau de neurones. De manière plus concrète, une bonne compréhension du problème et une bonne connaissance de l’état de l’art permettent au data scientist de mieux construire son réseau de neurones lors de la phase de modélisation.
Plus le fonctionnement du modèle sera transparent, plus il sera interprétable et donc plus le data scientist sera à même de prendre les bonnes décisions afin d’améliorer ses résultats. Ainsi dans le cadre du traitement d’image, il est intéressant d’avoir un feedback visuel en plus des métriques habituellement utilisées (loss, accuracy etc). Ce dernier aide à mieux comprendre comment les images sont traitées par le réseau de neurones.
D’autre part, l’interprétabilité bénéficie aussi au client et à l’utilisateur final du produit (cf article sur l’interprétabilité des systèmes de Data Science ici et article sur la confiance des utilisateurs dans un système d’IA ici).
Les retours visuels peuvent être complémentaires des résultats statistiques (courbes de précision, accuracy etc) lors de la présentation des performances du modèle au client, favorisant ainsi sa confiance dans la solution apportée.
Penchons-nous sur les méthodes de visualisation.
Visualisation des erreurs
Une première étape simple consiste à visualiser les images mal classées. En effet, les images mal classées suivent parfois une certaine « logique visuelle ». Par exemple, on peut imaginer dans le cadre d’un réseau de neurones qui classifie des images de chiens et de chats, que le modèles fait souvent des mauvaises prédictions sur les images de chats lorsque la photo est sombre. Une solution serait alors d’ajouter manuellement des images de chats où la luminosité est faible, si cela est simple, ou bien de jouer sur de l’augmentation de données en modifiant l’exposition d’une image lors de l’entraînement.
Regarder les images mal classées permet donc au data scientist de se faire une première idée des faiblesses de son modèle. On peut avertir le client du type d’image (s’il y en a) qui trompent souvent le système, en attendant de pouvoir améliorer les résultats (récolter plus de données, réentrainer ...).
Les conclusions qui peuvent être tirées suite à l’analyse des images mal classées sont des premiers éléments de compréhensions. Cependant, il faut vérifier après réentraînement du modèle que la rectification appliquée améliore les résultats du modèle.
Cette procédure de vérification devient difficilement exploitable lorsque le nombre de classes augmente et que les confusions entre les classes sont de plus en plus nombreuses.
Visualisation des embeddings
Dans les dernières couches d’un réseau de neurones convolutionnel, on retrouve souvent des couches entièrement connectées (perceptron multicouches). On peut alors utiliser l’une de ces couches pour extraire des features (vecteur de taille N) pour chaque image. Ces features correspondent à la représentation de l’image dans un espace à N dimension, propre au réseau de neurones. Ce sont des embeddings. L’étape suivante est de visualiser la projection de ces images dans un espace réduits à 2 ou 3 dimensions. Les images d’une même classe seraient à priori « proche » dans cet espace.
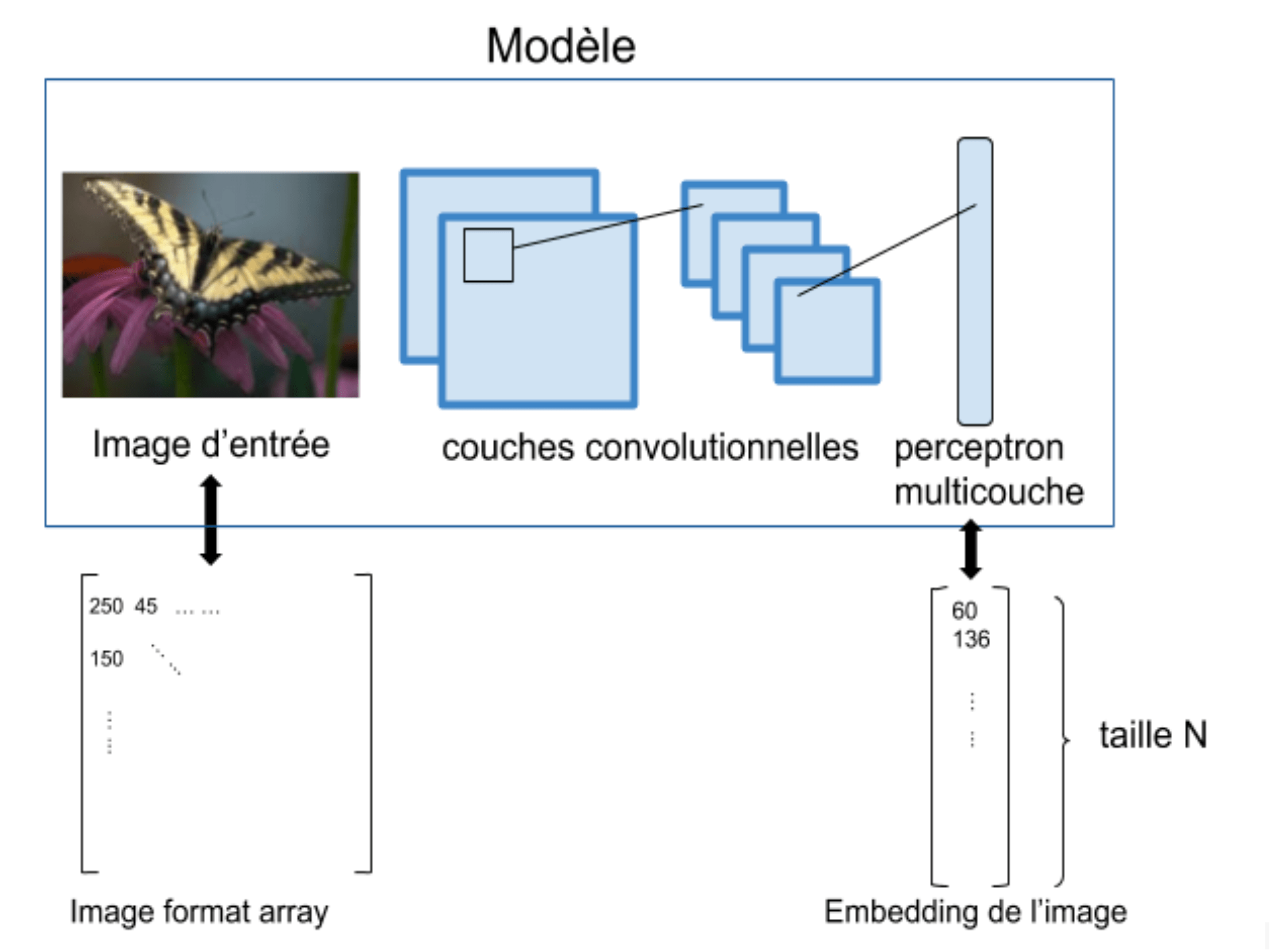
Figure 2 : Embedding d’images
On peut récupérer l’ensemble des embeddings de nos données de tests, c’est à dire faire passer toutes nos images dans le réseau de neurones puis récupérer les valeurs dans l’une des couches perceptron. Ensuite, il faut réduire la dimension de l’embedding, initialement de taille N, à une taille visualisable, c’est à dire en 2 ou 3 dimensions.
Tensorboard est un outils de monitoring développé avec Tensorflow. Parmi les nombreuses options que nous offre cet outil, on a la possibilité de visualiser nos images projetées dans un espace à 2 ou 3 dimensions à partir de leur embedding.
Les images ci-dessous correspondent à la projection en 3D du dataset Mnist (images manuscrites de chiffre allant de 0 à 9)

Figure 3 : exemples du dataset mnist
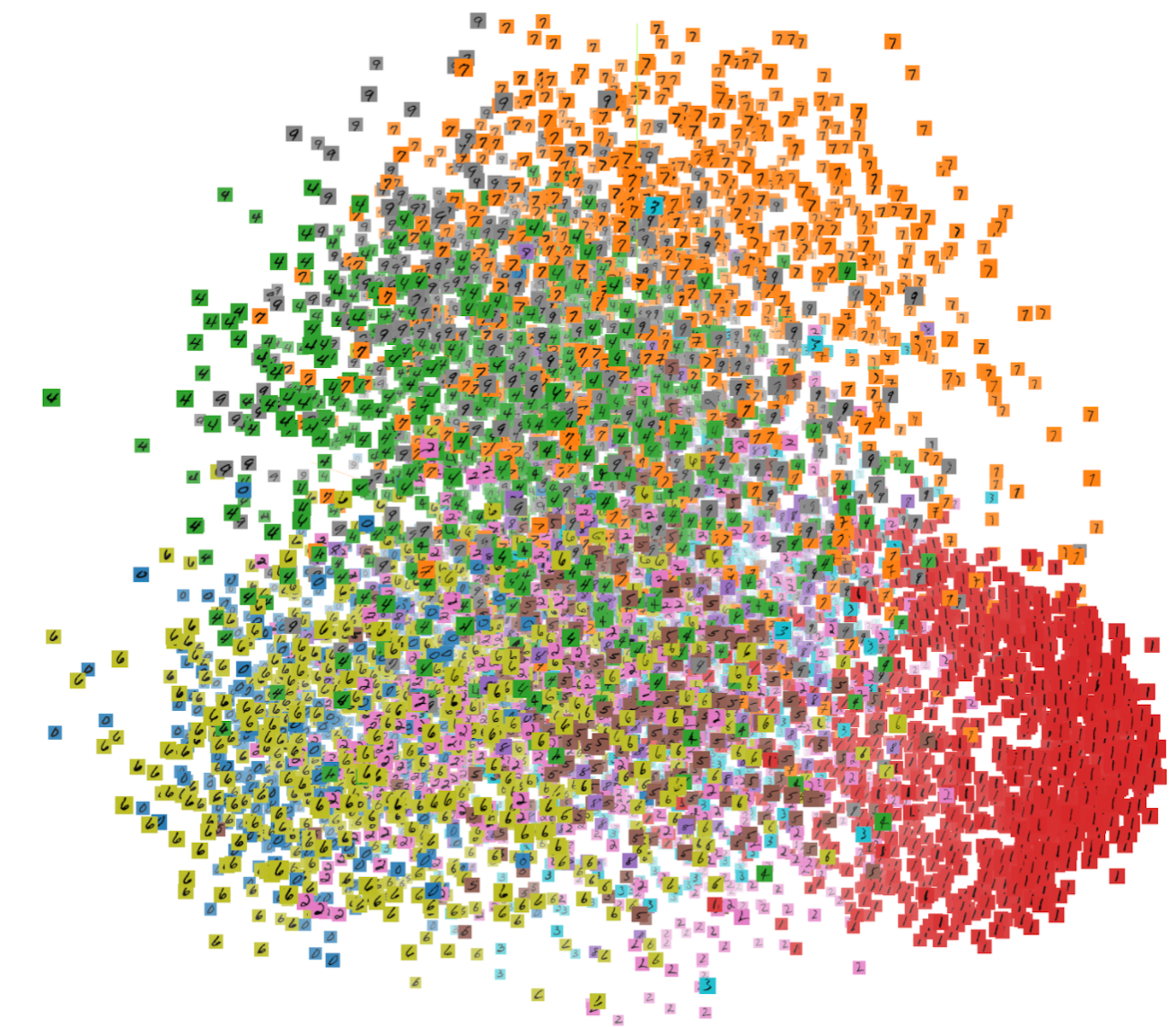
Figure 4 : Projection 3D du dataset Mnist coloré par label
On voit que les « 1 » (en rouge) forment un regroupement à droite sur l’image, alors que les « 7 » forment un regroupement en haut de l’image. Il s’agit d’une représentation des images dans un espace réduit, l’une de ses “représentations mathématique de la réalité”
Tensorboard nous permet de choisir l’algorithme à exécuter pour réduire les dimensions.
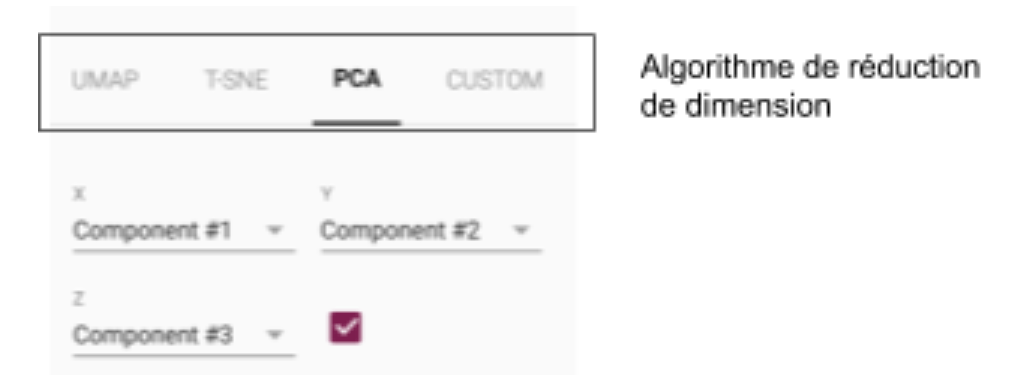
Figure 5 : Choix d’algorithme sur tensorboard
On peut vérifier que 2 classes occupent probablement une même région de cet espace lorsque le résultat de leur prédiction est souvent confondu. Attention toutefois à ne pas sur-interpréter : 2 classes d’images qui se superposent dans cet espace ne signifie pas qu’elles sont souvent confondues lors de la prédiction.
Visualisation des pattern appris par filtres
Une couche convolutionnelle est généralement composée de plusieurs filtres. Un filtre est une matrice dont les valeurs sont optimisés lors de la phase d'entraînement du réseau de neurones. Ce sont eux qui sont chargés d’extraire des patterns d’une image. Chaque filtre est responsable de l’extraction d’un type de pattern: il peut s’agir de couleurs et de formes pour les filtres des premières couches, et des patterns plus complexes dans les couches inférieures. On peut alors visualiser une image correspondant au pattern qui est appris par un filtre. Il s’agit de l’image qui maximise le plus l’activation d’un filtre donné.
Pour aller plus loin : on applique l’algorithme du gradient descent sur une image d’entrée sans information (image grise avec du bruit) sur plusieurs itérations afin de maximiser l’activation d’un filtre spécifique.
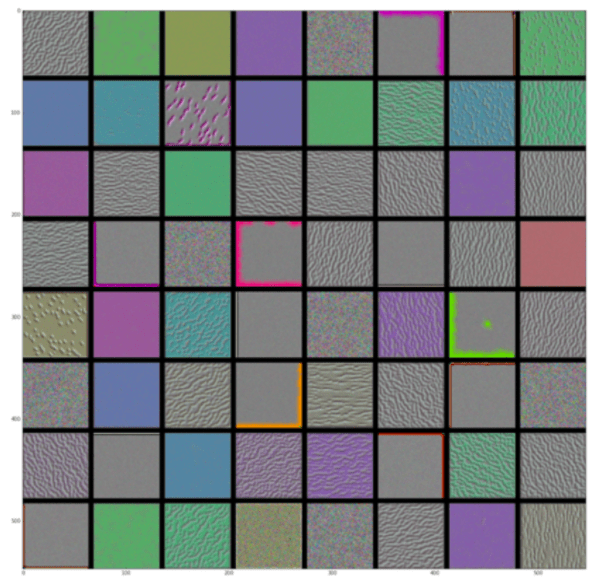
Figure 6 : Pattern des 64 filtres de la première couche convolutionnelle de VGG16
On voit par exemple que certains filtres reconnaissent des couleurs alors que d’autres reconnaissent des motifs granuleux. Toutefois, la visualisation des patterns des filtres apporte peu d’informations sur les performances du modèle, il est plus intéressant de voir comment les images sont transformées à travers le réseau de neurones.
Visualisation des features maps
Les features maps, ou activation maps, sont le résultat de la transformation de l’image d’entrée après application des filtres. On peut ainsi visualiser les transformations successives des images à travers le réseau de neurones, afin d’avoir une première idée du sens de chaque couche convolutionnelle.
Prenons l’exemple d’un réseau convolutionnel qui a appris à reconnaître des papillons (il s’agit de l’architecture VGG16 entraîné sur ImageNet) et intéressons-nous aux transformations opérées sur l’image.

Figure 7.1 : Papillon
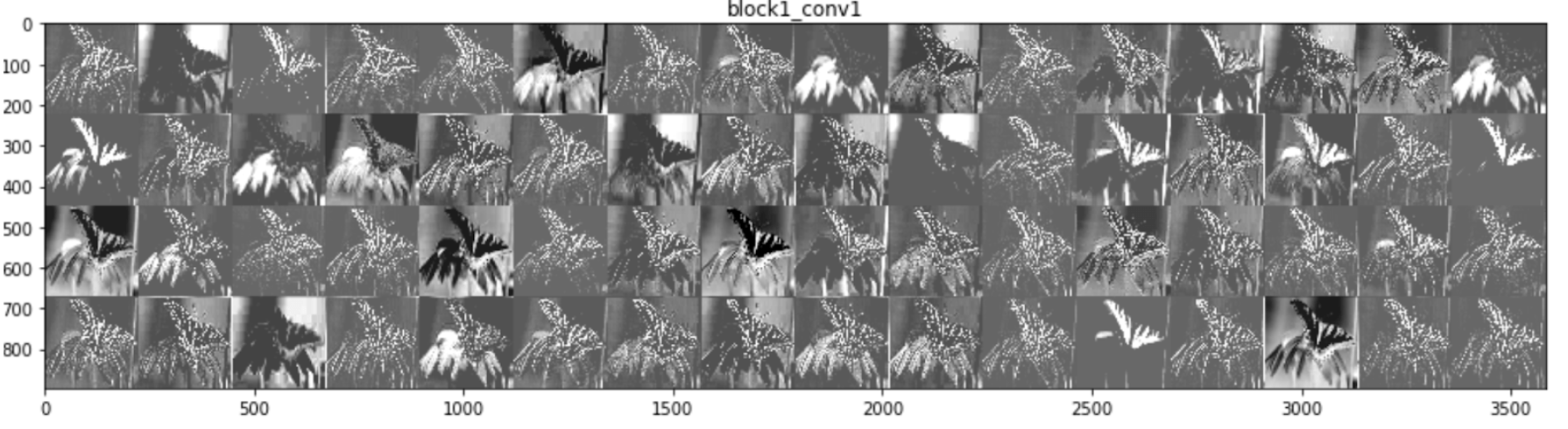
Figure 7.2 : Features maps à la sortie de la couche convolutionnelle 1
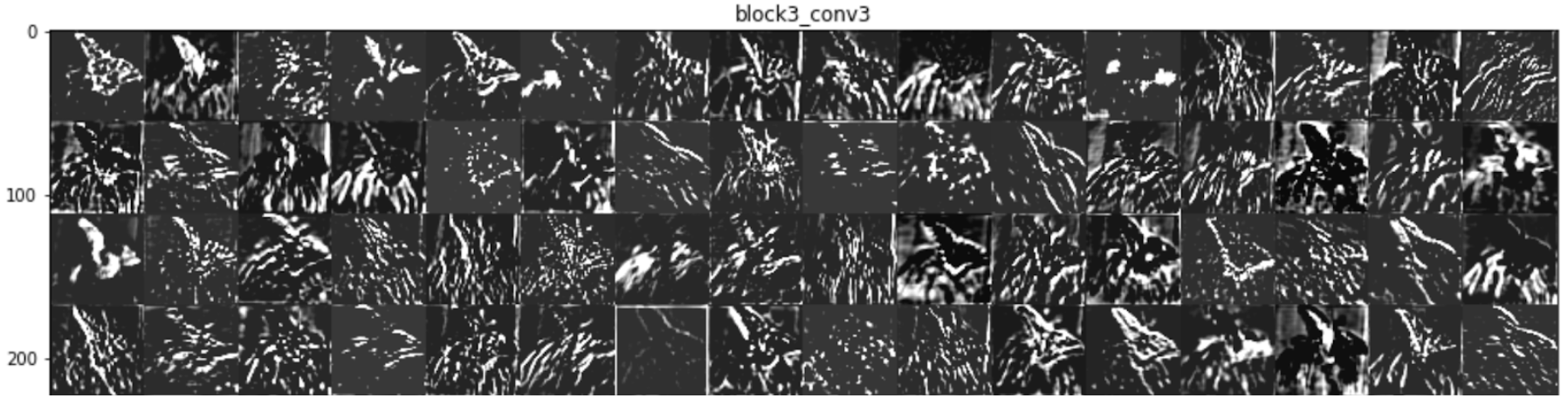
Figure 7.3 : Features maps à la sortie de la couche convolutionnelle 3
NB: chaque carré d’image correspond à la transformation de l’image d’entrée par l’un des filtres de la couche convolutionnelle en question.
On peut constater :
- la forme du papillon est facilement identifiable dans les premières couches
- certains filtres mettent en valeur la forme des ailes, d’autres, les rayures noires sur les ailes du papillon
- la forme des pétales est aussi une information retenue
- plus la couche convolutionnelle est profonde dans l’architecture du réseau de neurone, plus l’image d’entrée transformée devient abstraite
Ainsi, nous pouvons obtenir des éléments de compréhension de l’intérieur d’un réseau de neurones convolutionnel en visualisant :
- les filtres d’un réseau de neurones, c’est à dire les valeurs apprises par le réseau de neurone, utilisées pour effectuer des opérations mathématiques (convolutions) sur l’image
- les features maps, qui sont le résultat de la transformation de l’image par les filtres, qui nous montrent comment sont perçues les images par le réseau de neurones
Un autre aspect intéressant est de visualiser, sur l’image originale, la zone d’intérêt qui permet au modèle de prédire la classe.
Visualisation de heatmap
Lorsque qu’un algorithme prédit une classe, on aimerait savoir les éléments de l’image qui lui ont permis d’effectuer cette prédiction. Dans le cas où la prédiction est correcte, on peut vérifier que le modèle utilise les bonnes régions de l’image, et non pas des éléments du décor pour déterminer la classe. Dans le cas où la prédiction est mauvaise, on aimerait connaître les éléments de l’image qui ont conduit à ce résultat.
Masque / occlusion
Une première méthode consiste à déplacer un carré noir (le masque) qui viendra cacher une partie de l’image, et à prédire la classe de chacune des images modifiées (cf figure 8). L’idée est de constater que la probabilité de reconnaître l’objet diminue lorsqu’une partie de l'objet est cachée.

Figure 8 : Déplacement du masque sur l’image
D’après les résultats de l’algorithme, la probabilité qu’il s’agisse d’un papillon est plus forte lorsque le masque ne recouvre pas le papillon. On déplacera ce masque sur toute la longueur et largeur de l’image pour obtenir la heatmap, correspondant à la probabilité qu’il s’agisse d’un papillon, pour chaque position du masque.
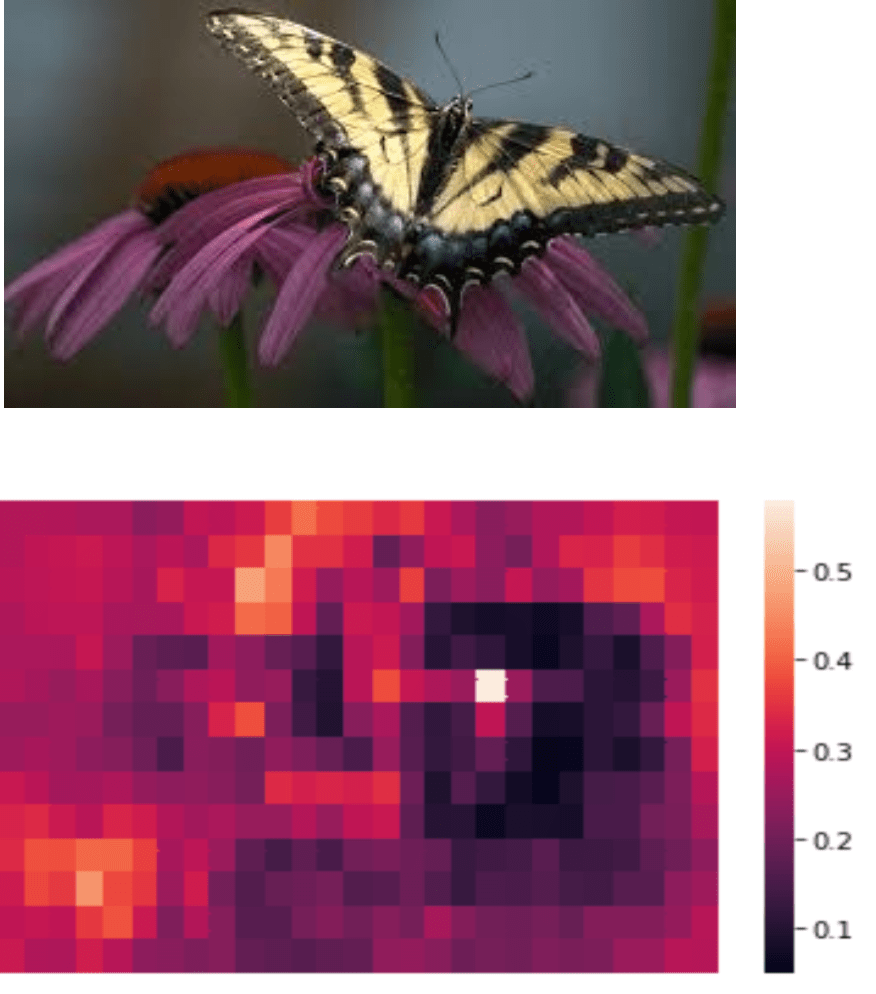
Figure 9 : Heatmap de probabilité
La figure 9 est la heatmap obtenue et l’axe indique la probabilité que l’image soit un papillon. On remarque que cette probabilité diminue lorsque le masque est situé dans la zone supérieure droite de l’image. Le modèle reconnaît donc le papillon grâce à la bonne partie de l’image.
Cette méthode est assez facile à coder. De plus, elle est assez intuitive à comprendre pour quelqu’un qui ne connaît pas le fonctionnement d’un réseau de neurones et peut donc être expliquée à un client non technique.
La heatmap est plus ou moins pixelisée en fonction des paramètres utilisés. L’algorithme suivant permet d’afficher des heatmap tout en remédiant à ce problème de pixels.
Grad-cam
L’algorithme Grad-cam permet d’identifier la zone d’une image responsable de la prédiction d’une catégorie donnée. Le mécanisme est un peu plus complexe que pour la méthode d’occlusion. Chaque heatmap s’obtient par rapport à une classe choisie : c’est à dire qu’on demande à l’algorithme d’identifier les zones d’intérêt de l’image qui participent le plus à la prédiction du score de la classe choisie.
Pour aller plus loin : en réalité, pour obtenir la heatmap par rapport à une classe c, on calcule le gradient du score de la classe c par rapport aux features maps d’une couche convolutionnelle, et on redimensionne cette carte de gradient à la taille de l’image d’origine. Cette heatmap dépend de la classe cible et de la couche convolutionnelle regardée (lire le papier ici pour plus d’information).
Pour l’image ci-dessous, la classe dont la probabilité est la plus élevée est l’ananas, à 98%. On voit qu’il y a effectivement un ananas, mais également des bananes à droite. Sur la heatmap, plus la zone est jaune, plus elle est importante pour la prédiction. La heatmap nous indique que le réseau de neurones « regarde » au bon endroit de l’image pour effectuer sa prédiction d’ananas.

Figure 10.1 : Heatmap de la classe ananas
Notre algorithme considère que l’image correspond à des bananes avec 5% de certitude. En regardant la heatmap qui fait prédire la classe “banane”, on vérifie qu’il s’agit bien de la zone où est située la banane qui est activée.

Figure 10.2 : Heatmap de la classe banane
Cette méthode est utilisable pour toutes les architectures avec des couches convolutionnelles.
Enfin, une dernière méthode, appelée Guided backpropagation, nous permet de voir voir plus précisément quels pixels de l’image ont un impact dans la prédiction de la classe.
Guided-backpropagation
L’idée reste la même, on cherche la zone de l’image que le réseau de neurones considère comme importante afin de prédire sa classe. Toutefois, le résultat n’est pas une heatmap mais une image retenant les pixels importants de l’image d’entrée.
Cette méthode s’appuie sur une modification du calcul du gradient lors de la phase de backpropagation (cf ici pour aller plus loin).
Pour la prédiction d’un chat dans l’image ci-dessous, on obtient avec l’algorithme Guided-backpropagation la figure suivant.

Figure 11 : Guided-backpropagation (image issue de
https://medium.com/@mohamedchetoui/grad-cam-gradient-weighted-class-activation-mapping-ffd72742243a)
Cette méthode a l’avantage de souligner les zones d’intérêt par de fins détails sur l’image d’origine. Ici, on peut reconnaître les formes de la tête, des yeux, des oreilles, des pattes etc. Le fond de l’image n’apparait pas.
Conclusion
Dans cet article, nous avons vu qu’il est possible de visualiser le fonctionnement d’un réseau de neurones de plusieurs manières :
- en projetant les images dans un espace visualisable
- en affichant le pattern appris par un filtre
- en regardant comment les images sont transformées dans chaque couche
- en repérant les zones importantes pour la classification.
Malgré la complexité d’un modèle convolutionnel, il est possible de le rendre plus transparent. J’espère que ces outils vous convaincront que les boîtes noires que sont les réseaux de neurones convolutionnels ne sont pas si noires que ça.