Vision d’OCTO sur le Service Mesh : radiographique du Service Mesh
Cette année les Services Mesh sont de toutes les conférences : istio, linkerd, kubeflix, zuul? ... Dans un premier article nous avons positionné le Service Mesh et ses enjeux dans l’écosystème des microservices. Nous allons désormais en proposer une radiographie.
Notre définition du Service Mesh est la suivante : Le Service Mesh désigne une plateforme chargée d’assurer la sécurité, le routage et la traçabilité des communications entre applications microservices déployées de façon dynamique dans des conteneurs.
Différentes solutions ont émergé pour répondre à ces besoins :
- au niveau de l’infrastructure, les plateformes d’orchestration de conteneurs telles que Kubernetes s’étendent avec des solutions comme Istio pour fournir une plateforme d’infrastructure
- au niveau de l’API, des solutions comme Kong s’étendent pour être plus dynamiques et gagner en traçabilité
- au niveau logiciel, des frameworks logiciels comme HAPI ou Spring fournissent plugin et librairies qui fournissent des fonctionnalités très proches
Multiplier les solutions n’est, à notre avis, pas la bonne approche. Mais ces différentes solutions sont-elles toutes équivalentes ? Nous souhaitons vous apporter ici un éclairage pour comparer les fonctionnalités de ces implémentations. Cela vous permettra de choisir ou composer la meilleure solution de Service Mesh en fonction de votre besoin et de votre existant.
Dans le premier article nous avons listé deux enjeux fondamentaux pour les applications actuelles : modularité et évolutivité. Nous allons ici donner un cadre aux fonctionnalités nécessaires pour répondre à ces enjeux. Pour cela nous avons utilisé les patterns des 12-factor apps mais pas uniquement pour caractériser ces fonctionnalités indépendamment de leur implémentation.
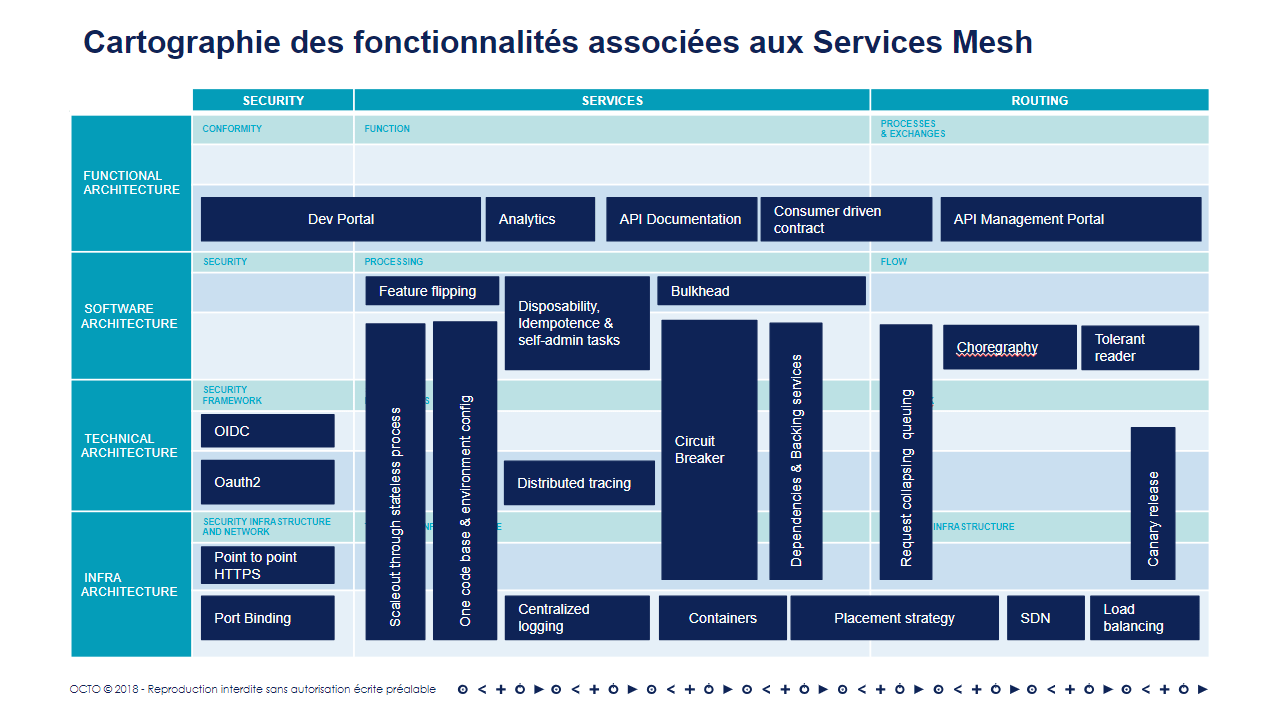
Nous avons positionné ces différents patterns selon 2 axes :
- Le niveau de spécificité technique de chacun de ces patterns avec quatre niveaux : fonctionnel, applicatif, technique et d'infrastructure
- Le type de problématique adressée : services, routage/intégration et de façon transverse la sécurité
Nous citerons ici quelques solutions dans un but d’illustration, sans que cela se veuille exhaustif des fonctionnalités pour chacune de ces solutions. Nous aborderons la question de la couverture fonctionnelle de ces solutions dans les articles suivants.
Sécurité

Si nous considérons un micro-service exposant une API, la sécurisation peut s’appuyer sur les éléments suivants :
- Portail développeur : il permet au développeur de s’enregistrer auprès de l’API et d’obtenir toutes les informations pour réaliser son premier appel de façon authentifiée.
- OAuth2 : propage les droits d’un utilisateur (l’ensemble de ses autorisations) entre plusieurs applications
- OIDC : Open ID Connect permet d’étendre les fonctionnalités d’OAuth2 avec une capacité d’authentification
- Point to Point HTTPS : HTTP sur TLS ou plus simplement HTTPS sécurise les connections. Fréquemment la protection TLS s’arrêtait au niveau d’un reverse proxy central. Désormais on peut viser de sécuriser non plus uniquement jusqu’à l’entrée du cluster, mais jusqu’à l’entrée de chaque conteneur
- Port Binding : ségrègue le trafic jusqu’au niveau conteneur : chaque conteneur ne voyant que le trafic qui lui est destiné
Linkerd et Istio proposent par exemple une fonctionnalité de TLS jusqu’au conteneur final de façon transparente pour les applicatifs. Istio peut fournir une fonctionnalité d’habilitation de type RBAC, mais va déléguer toute la partie authentification. A l’inverse un outil de type Kong sera plus outillé pour s’intégrer avec une infrastructure OAuth2 et OIDC.
Services
Dans un écosystème digital, on souhaite des services modulaires, évolutifs. Le déploiement est automatisé voir continu. Une application peut être découpée en un grand nombre de microservices. Le data driven development se met progressivement en place avec la collecte de métriques à grande échelle. Les besoins sont également tirés par les possibilités des différentes plateformes. Voici un ensemble non exhaustif mais le plus représentatif possible de l’état de l’art des différents microservices :
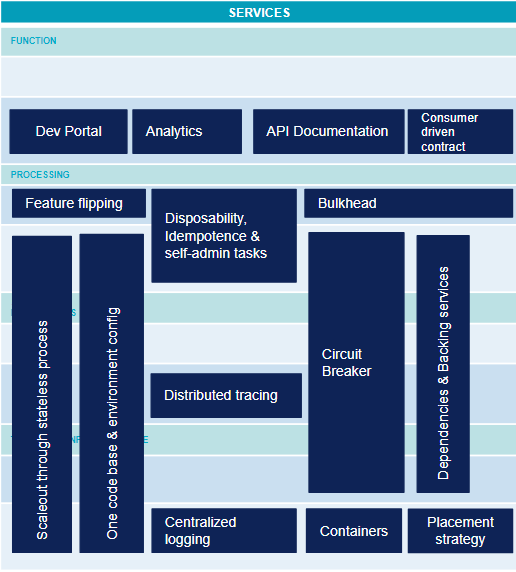
- Feature flipping : le déploiement continu de nouvelles fonctionnalités n’est pas toujours souhaité par les utilisateurs qui peuvent avoir besoin de délais avant la mise à disposition. De la formation peut être nécessaire ou simplement de la promotion doit être faite sur la nouvelle fonctionnalité. Le Feature Flipping permet d’activer ou de désactiver une fonctionnalité. Cela permet de décorréler mise en production et déploiement ce qui est fondamental pour permettre le déploiement continu.
- API Documentation : capacité à fournir toutes les informations sur l’API de façon à ce que son utilisation soit intuitive pour un développeur client.
- Dev Portal et Analytics : l’identification des utilisateurs est un prérequis pour pouvoir collecter des statistiques. Ces métriques peuvent aller du SEO du portail de développement de l’API à du drill down de temps de réponse des méthodes dans le cadre du management de la performance.
- Centralized logging : dans un contexte de conteneurs éphémères, les logs doivent être extraits et corrélés les uns aux autres pour fournir une vision globale de l’application qui permet le pilotage et le diagnostic d’erreur.
- Distributed tracing : au delà des logs, la traçabilité des échanges entre les différents microservices est une fonctionnalité essentielle pour pouvoir comprendre le routage et diagnostiquer d’éventuels problèmes de latence.
- One codebase & environment config : afin de pouvoir suivre la version d’une application de bout en bout, l’ensemble de ces éléments doivent être versionnés : d’une part une code base qui restera identique entre les environnements, et d’autre part une configuration d’environnement gérée par une solution d’infrastructure as code (orchestrateur de conteneurs ou autre). Cette configuration sera également versionnée et servira au déploiement sur chaque environnement.
- Disposability, idempotence & self-admin tasks : capacité à prendre en charge toutes les tâches d’arrêt et de démarrage (ex. initialisation des données, dédoublonnage des messages déjà traités) par le microservice lui-même. C’est une caractéristique essentielle d’une application pour qu’elle fonctionne sur une plateforme dynamique comme un orchestrateur de conteneurs. En effet, à tout moment l’instance peut être détruite ou recréée. Le microservice doit être en mesure de se configurer pour être prêt à traiter des requêtes.
- Bulkhead : à l’image des caissons étanches de la coque d’un bateau, capacité d’une application à continuer à répondre en mode dégradé en cas d’erreur grave sur l’un ses composants ou l’une de ses dépendances.
- Circuit breaker : à l’image du disjoncteur, proxy implémentant une machine à état qui désactivera les appels à une dépendance en cas d’erreurs trop nombreuses. Ce pattern permet de ne pas surcharger un microservice suite à un problème dans un autre microservice en aval.
- Container : packaging d’un processus qui isole à l’exécution le filesystem et les ressources informatiques de ce processus. Docker est le type de conteneur le plus connu. Un conteneur permet de normaliser le déploiement. Les orchestrateurs de conteneurs peuvent ainsi traiter tous les microservices de façon industrialisée.
- Scaleout through stateless process : capacité à répartir le traitement sur plusieurs processus qui ne partagent aucun état. C’est une caractéristique essentielle de l’application pour qu’elle soit scalable et qu’elle sache tirer parti de la capacité d’une infrastructure à la demande comme un cloud ou un orchestrateur de conteneurs.
- Placement strategy : fonctionnalité au cœur des orchestrateurs de conteneurs qui permet d’exécuter un conteneur sur le nœud physique le plus approprié en fonction d’un certain nombre de contraintes.
Istio et Linkerd vont ainsi fournir des fonctionnalités avancées de tracing distribué. Mais elles devront se reposer sur d’autres outils pour la centralisation des métriques ou l’identification. Certaines fonctionnalités applicatives comme le Circuit Breaker peuvent également être prises en charge par ces outils. Mais pour un comportement totalement transparent pour l’utilisateur par exemple, ces outils génériques seront toujours limités. Une stratégie de gracefull degradation élégante ne pourra par exemple pas être implémentée par un outil générique agnostique du métier.
Communication - routage
Plus la granularité de la modularisation devient fine, plus la complexité se déplace sur la communication entre ces différents microservices. Les fonctionnalités suivantes deviennent progressivement indispensables pour gérer cette complexité.
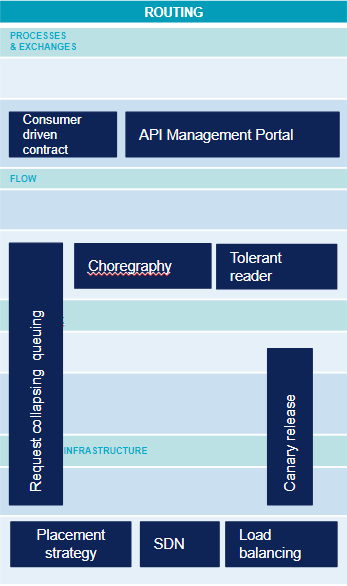
- Consumer Driven Contact (CDC) : Si l’on reprend la définition de Sam Newman dans “Building Microservices” : “Avec le Consummer Driven Contract, nous définissons les attentes d’un consommateur sur un service [...]. Ses attentes sont capturées sous la forme de tests, qui sont ensuite exécutés sur le service producteur. En cible, ces CDCs doivent être exécutés dans l’intégration continue du service, de façon à s’assurer que celui-ci ne soit jamais déployé s’il ne respecte pas l’un de ces contrats.”
- API Management Portal : Ce prolongement du portail développeur permet de configurer les API, de paramétrer le routage des requêtes. Il peut également gérer la documentation de l’API.
- Tolerant Reader : Le principe est de veiller à ce que le consommateur d’un quelconque système externe soit tolérant à l’évolution du schéma de données qui lui est fourni en lecture. Cela consiste à prévoir des solutions palliatives en cas de valeur non prévue, de valeur absence ou encore ne respectant pas le format attendu. Les navigateurs web par exemple sont relativement tolérants par rapport à des écarts par rapport à la norme HTML.
- Choregraphy : l’approche traditionnelle de la SOA consiste à avoir un composant central (souvent un ESB) pour orchestrer l’ensemble des échanges entre services. L’approche par choregraphy consiste à déléguer cette responsabilité aux différents microservices et ainsi à la décentraliser.
- Request Collapsing & Request Queuing : capacité à temporiser ou à regrouper plusieurs requêtes pour ne réaliser qu’une requête physique vers le service cible. Ce pattern permet d’optimiser le routage en terme de scalabilité.
- Canary Release : capacité à mettre en production une nouvelle version de l’application sur un sous-ensemble de clients choisis. Cela permet de valider la nouvelle version avant de la déployer largement. Voir l’article d’OCTO sur le Zero Downtime Deployment.
- Load balancing : capacité à rediriger un flux réseau vers plusieurs composants de façon transparente pour l’appelant. Cela permet de répartir la charge ou de pallier la défaillance de l’un des composants.
- Software Defined Network : environnement réseau totalement virtuel où la partie routage proprement dite (data plan) est séparée de la partie plan de routage (control plan) qui définit les règles de routage de façon globale.
Istio et Linkerd vont avoir ici des fonctionnalités très avancées en termes de routage dynamique et de management de trafic. Ils sont également très bien intégrés aux fonctionnalités de SDN des orchestrateurs de conteneurs. Leur positionnement différenciant repose justement sur une architecture similaire au SDN (data plan dans un conteneur accolé au conteneur applicatif comme un side-car est accolé à une moto). Le Service Mesh applique ce concept au routage applicatif. Leur choix d’avoir une approche transparente vis-à-vis des applications va nécessairement les limiter sur la partie API et applicative. Des solutions d’API management seront très bien outillées pour la gestion des API et le load balancing, mais elles nécessiteront plus de mise au point pour suivre la topologie dynamique d’un orchestrateur de conteneurs.
A travers ce cadre, nous avons pu mettre en évidence que le Service Mesh fournit des fonctionnalités très utiles pour répondre aux enjeux de modularité et d’évolutivité. Mais cet outil peut ne pas être suffisant ou au contraire ne pas être nécessaire dans votre contexte. Comme tout outil, il est indispensable d’identifier son besoin au préalable. Le choisir car il est sur toutes les lèvres aujourd’hui ne fera qu’ajouter de la dette technique à votre architecture. Tordre un outil pour répondre à un nouveau besoin pour lequel il n’a pas été conçu aura le même type de conséquence néfaste. Nous espérons que ce cadre vous aidera à mieux faire votre choix en connaissance de cause.