Vers un auto-hébergement des modèles VLM/LLM : étude empirique sur une infrastructure entrée de gamme, défis et recommandations
Résumé
L’inférence de grands modèles de langage (LLM) et de vision (VLM) auto-hébergés en production posent des défis majeurs de dimensionnement. Ceci est particulièrement vrai lorsque l’infrastructure repose sur du matériel d’entrée de gamme. Dans cet article, nous proposons et évaluons une architecture pour servir l’inférence d’un LLM de 14 milliards de paramètres et un VLM de 7 milliards, déployées sur des GPU NVIDIA T4. Ce choix d’infrastructure vise à explorer les limites de ce type de matériel et à concentrer l’effort d’optimisation sur les paramètres du serveur d'inférence et de l’orchestrateur de requêtes. Sur 19 expérimentations totalisant 7310 requêtes, le système affiche un taux de réussite global de 91% et une résilience remarquable : aucun arrêt brutal, aucun dépassement de mémoire (Out-of-Memory), même lors des montées en charge soudaine. Les résultats présentées dans notre article permettent de dimensionner une infrastructure de production en fonction de l’accord sur le niveau de service visé (Service Level Objective - SLO), mais posent aussi la question stratégique de l'arbitrage entre performance, coût et expérience utilisateur dans un contexte où les attentes en matière de réactivité des LLMs continuent d'augmenter.
Introduction et état de l’art
En 2022, OpenAI dévoile au monde son interface ChatGPT qui démocratise l’utilisation des modèles de langage entraînés sur de larges corpus de texte (Large Langage Model, LLM), les sortant ainsi à jamais des laboratoires de recherche [21,20,23]. Depuis, et poussé par l’adoption populaire de ces modèles, d’autres acteurs comme Google, Anthropic, Deepseek, ou encore Mistral ont rejoint la course. Les modèles sont devenus de plus en plus performant [1,2], plus léger à entraîner et plus rapide sur l’inférence [3].
Cherchant d’autres sources de revenus que les souscriptions à leurs interfaces de chat, les fournisseurs de solutions IA, ont vite donné accès à des interfaces de programmation d’application (API), permettant d’envoyer des requêtes sous forme de prompt et recevoir le résultat directement au sein de son application. La monétisation de ce service se calcule en nombre de tokens [4] donnés en entrée, et le nombre de tokens en sortie. Par exemple pour leur dernier modèle Opus 4.6, Anthropic vous facture par millions de jetons : 5$/MTokens en entrée et 25$/MTokens en sortie. Open AI, vous facture 1.75$/MTokens en entrée et 14$/MTokens en sortie pour GPT-5.2. Vous pouvez trouver une comparaison complète des autres modèles ici [5].
L’utilisation des APIs qui exposent des LLMs, s’est vite révélée limitée par leur manque d’accès à l'exécution de fonctions ou de commandes d’autres outils externes. L’ensemble des acteurs se sont vite attelés à la tâche pour développer une surcouche dans leur API permettant de faire des appels à des fonctions (functions tooling), et donc à exécuter du code. Google Search a publié ReAct (Reason Act, ou raisonnement action) fin 2022 [6], considéré comme le paradigme qui a lancé le développement et l’amélioration des appels de fonctions à exécuter.
Plus tard, fin 2024, Anthropic propose le Model Context Protocol (MCP) [7], et en le mettant en open source, elle développe un standard permettant à chacun de proposer un serveur MCP qui expose des fonctions pouvant être appelées par des clients LLMs. Le MCP rend les appels de fonctions agnostiques du fournisseur IA [8]. Ces deux évolutions majeures donnent la possibilité aux modèles de faire de la recherche, de la planification et de mettre en action un plan. Ajoutons à cela une automatisation d'exécution et nous avons l’(r)évolution de l’utilisation des agents/bots appelée communément agentic IA. Nous définissons l’agentic comme une structuration d’un ensemble d’appels à des APIs par un LLM ou VLM pour exécuter un plan d’action.
![Chronologie des différentes annonces et publications cités [6,7,13] tout au long de notre article, elle retrace les événements marquants qui ont changé notre façon de travailler avec et d’utiliser les modèles de langages.](/vers-un-auto-hebergement-des-modeles-vlmllm-etude-empirique-sur-une-infrastructure-entree-de-gamme-defis-et-recommandations/image1.webp)
Figure 1.1. Chronologie des différentes annonces et publications cités [6,7,13] tout au long de notre article, elle retrace les événements marquants qui ont changé notre façon de travailler avec et d’utiliser les modèles de langages.
Ces dernières évolutions ont percé le plafond de verre des modèles de langage et les ont libérés de leur boîte qui les limitait à de “simples” interface de chat dans un navigateur web. Maintenant, ils peuvent être une partie intégrante d’un programme informatique, d’un système d’information d’une entreprise, ou encore d’un programme qui automatise une partie d’un processus métier. Et même si plusieurs débats existent [9,10], sur l’utilisation de ces outils pour l’amélioration de la productivité, nous observons que la course est lancée, et que tout le monde court. On ne voit pas la ligne d’arrivée, mais il ne faut pas rester sur la ligne de départ.
Si l'adoption ne fait parfois pas de doute, les questions sur la sécurité des données et l’utilisation d’APIs de fournisseurs externes restent fondamentales. Cela s’avère encore plus important, si l’entreprise est en train d’intégrer ces APIs dans son système d’information, et a ouvert son utilisation à l’ensemble de ses employées. Des secteurs, comme la finance, la banque, la santé, la défense doivent répondre à des exigences de conformités qui se durcissent à travers le monde :
- RGPD en Europe : interdiction de transfert des données personnelles hors UE sans garanties appropriées.
- HDS (Hébergement de données de santé) en France : certification obligatoire pour les données médicales.
- SecNumCloud : qualification ANSSI pour les infrastructures cloud hébergeant données sensibles.
- Secteur financier : PCI-DSS, LCB-FT imposent traçabilité complète des traitements.
Indépendamment du secteur, et du contexte réglementaire, posez-vous ces questions : lorsque j’envoie mes données à travers une API, où transite ma requête ? Par quel data center ? Quelle juridiction ? Qui y accède ? Administrateur du fournisseur de cloud, administrateurs de l’API, sous-traitants ? Est-ce qu’elle est utilisée pour entraîner des modèles ? Quelle est la durée de rétention des logs, du cache) ? Pour toutes structures, il y a un besoin de traçabilité de la donnée, d’une conformité par rapport à des prérequis de sécurité, et d’une maîtrise de la durée de rétention avec une suppression garantie des données sensibles.
Héberger soit même des modèles avec des poids ouvert (open weight) et exposer sa propre API en interne est une possibilité de réponse à ces problématiques. De plus, ce qui était réservé aux GAFAM (Google, Amazon, Facebook, Apple, Microsoft), il y a 2 ans devient accessible à des équipes de DevOps, MLOps, ML Engineer qui sont averties et à l’état de l’art. La preuve, Anthropic, startup puis challenger il y a deux ans, est devenue un incontournable dans les discussions voire même leader sur certains aspects, notamment en modèle spécialisé dans l'assistance de code [11]. Sans parler des “Six Little Dragons” de Hangzhou, ou de Alibaba et ses modèles Qwen qui participent activement à cette course en avant.
Cela dit, entreprendre soit même l’hébergement des modèles et de(s) API pour les exposer, ne veut pas forcément dire acheter des GPUs et des machines (ce que nous allons voir dans la suite de l’article). Cela peut être nécessaire dans certains cas d’usage (e.g. données du secteur défense, données du secteur de la santé, données à protéger dans le cadre du secret industriel, etc.), mais ce n’est pas forcément la règle. Une approche hybride est conseillée, du bare metal quand vous avez des données sensibles et que vous devez laisser allumer les GPU 24/24 et du cloud pour avoir des ressources et des services sur demande. Le cloud restera toujours pertinent, car il vous permet de rester à la pointe de la technologie mais aussi vous décharger des aspects maintenance et opérations d’une partie de votre parc informatique.
Méthodologie et outils
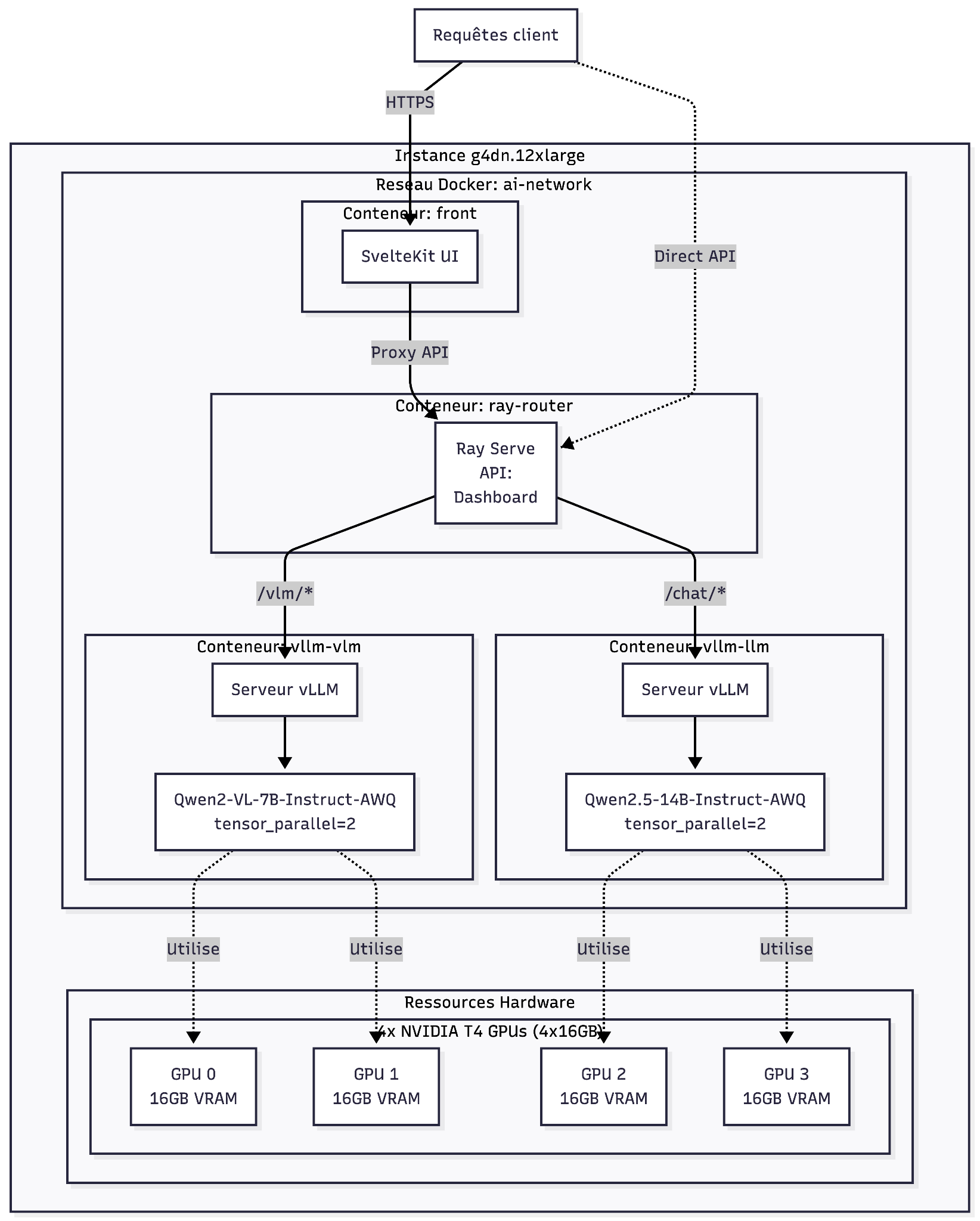
Figure 1.2. Architecture avec deux services d’inférence vLLM déployé sur une instance avec 4 GPUs NVIDIA T4. Le modèle de vision (Qwen2-VL-7B) utilise les GPUs 0-1 et le modèle de langage (Qwen2.5-14B) utilise les GPU 2-3. Ray serve orchestre le routage des requêtes depuis un frontend svelte via une API unifié sur un port défini.
Dans la suite de cet article, nous vous présentons une architecture et son étude empirique pour évaluer sa performance. Nous avons déployé cette architecture et mené nos expérimentations sur quatre GPUs NVIDIA T4 (voir Table 1.1), servant simultanément un LLM 14B (Qwen 2.5-14B-Instruct-AWQ) et un VLM multimodal 7B (Qwen2-VL-7B-Instruct-AWQ). Cette architecture utilise Ray Serve comme routeur pour distribuer les requêtes vers le bon modèle selon le endpoint appelé. Elle contient trois conteneurs docker :
- vLLM-VLM, serveur vLLM dédié au Qwen-VL-32B;
- vLLM-LLM, serveur vLLM dédié au Qwen-14B-Chat;
- Ray Server pour une redirection vers les endpoint /vlm et /chat. Ces différents composants sont schématisés dans la figure 1.1.
Nous avons choisi de travailler avec des serveurs vLLM comme moteur principal pour l’inférence. Ce choix est principalement motivé par notre souhait d’orienter nos expérimentations sur les accès concurrentiels aux ressources des GPUs. Un domaine où les vLLM excellent [12], grâce au mécanisme de PagedAttention, introduit dans le papier fondateur de vLLM en 2023 [13]. Inspiré du mécanisme de pagination implémenté pour la gestion de la mémoire vive, PagedAttention permet d'optimiser l’utilisation de la mémoire cache clé/valeur (KV cache) et de réduire considérablement la perte de mémoire causée par la fragmentation et la redondance des poids du modèles à travers la mémoire. Au lieu d’allouer le KV cache de manière contigüe en mémoire GPU, Paged Attention le découpe en pages de 16 Tokens allouées de manière non-contigüe.
![Gauche : Schéma [13] de la disposition mémoire lors du serving d'un LLM de 13 milliards de paramètres sur NVIDIA A100. Les paramètres du modèle (en gris) persistent en permanence dans la mémoire GPU tout au long du serving. La mémoire dédiée au KV cache (en rouge) est allouée et désallouée à chaque requête de serving individuellement. Une petite quantité de mémoire (en jaune) est utilisée de manière éphémère pour les activations.Droite : vLLM lisse la courbe de croissance rapide de la mémoire KVcache observée dans les systèmes existants, permettant ainsi une augmentation notable du débit global (throughput) [13].](/vers-un-auto-hebergement-des-modeles-vlmllm-etude-empirique-sur-une-infrastructure-entree-de-gamme-defis-et-recommandations/image3.webp)
Figure 1.3. Gauche : Schéma [13] de la disposition mémoire lors du serving d'un LLM de 13 milliards de paramètres sur NVIDIA A100. Les paramètres du modèle (en gris) persistent en permanence dans la mémoire GPU tout au long du serving. La mémoire dédiée au KV cache (en rouge) est allouée et désallouée à chaque requête de serving individuellement. Une petite quantité de mémoire (en jaune) est utilisée de manière éphémère pour les activations. Droite : vLLM lisse la courbe de croissance rapide de la mémoire KVcache observée dans les systèmes existants, permettant ainsi une augmentation notable du débit global (throughput) [13].
D’autres serveurs d’inférence ont été considérés [12] : llama.cpp, Ollama ou encore SGlang [14] (qui a introduit le concept de RadixAttention pour la réutilisation du KV cache). Nous n’avons pas trouvé d’études comparatives entre vLLM et SGLang. Cet article aurait pu aussi être fait avec SGLang, car lui aussi gère bien les accès concurrentiels. Une expérimentation poussée mériterait d’être faite afin de comparer les deux serveurs.
Cela dit, nous trouvons dans l’état de l’art [15] une étude comparative sur un MacStudio avec une puce M2 Ultra (192Go). L’article compare les serveurs d’inférence MLX, MLC-LLM, llama.cpp, Ollama et PyTorch MPS. Les résultats démontrent que le MLX, un framework open source développé par Apple, sort un meilleur throughput, ceci est logique vu que les expérimentations ont été faites sur des puces M2.
Nous avons choisi d’isoler chaque service dans un conteneur indépendant pour de nombreuses raisons dont celles-çi :
- avoir une isolation complète des modèles (e.g. un crash d’un serveur vLLM n'affecte pas l’autre)
- avoir la capacité de redéployer un modèle sans une mise hors service de l’autre
- être en capacité d’augmenter les ressources du VLM et du LLM indépendamment.
| GPU | Architecture | CUDA Cores | FP32/16 (TFLOPS) | Mémoire | Bande passante | TDP |
|---|---|---|---|---|---|---|
| T4 | Turing (2018) | 2 560 | 8.1/65 | 16 GB GDDR6 | 320 GB/s | 70W |
| A100 | Ampere (2020) | 6 912 | 19.5/312 | 40/80GB HBM2e | 1 555 GB/s | 260W |
| A10 | Ampere (2021) | 9 216 | 31.2/250 | 24GB GDDR6 | 600 GB/s | 150W |
| RTX 4090 | Ada Lovelace (2022) | 16 384 | 82.6/82.6 | 24GBGDDR6X | 1 008 GB/s | 450W |
| L40S | Ada Lovelace (2023) | 18 176 | 91.6/366 | 48GB GDDR6 | 864 GB/s | 350W |
Table 1.1. Comparaison des GPUs NVIDIA qu’on retrouve dans les datacenters, le CUDA core est l'unité de calcul parallèle propre à NVIDIA, TerraFlops et FP (Floating point) sont des métriques pour mesure la puissance de calcul mathématique, le FP32-bit consacrant plus de bit au calcul est nécessaire pour la précision, FP16-bit est nécessaire pour la performance. Afin d’exploiter ces Terraflops, la mémoire permet de stocker les paramètres du modèles, ainsi que les gradients, et les activations intermédiaires pour la backpropagation. La bande passante mémoire c’est ce qui permet d’alimenter continuellement les unités de calcul avec les poids du modèle à partir de la mémoire (particulièrement important pour l’inférence [18]). Sources : [17],[19],[20].
La table 1.1, permet de positionner notre choix parmi les autres types de GPUs présents dans les datacenters, à part la RTX 4090 qui est destinée originellement au gaming. Il démontre également que les meilleurs GPUs sont les L40S ou les A100 pour l’inférence du fait de leur bande passante et leur FP16-bit respectivement à 366 et 312 (voir explication FP32 et FP16 dans la description de la table 1.1).
Les GPUs T4 se positionnent dans un segment entrée/milieu de gamme de ce que l’on peut trouver dans les datacenters. Ils sont optimisés pour l’inférence et l’efficacité énergétique, avec une faible consommation de 70W sous la charge maximale théorique appelée aussi TDP (Thermal Design Power). Le choix de ce type de GPU est motivé par notre souhait de mener nos expérimentations avec une contrainte sur la mémoire et les capacités du calcul du hardware, afin de prêter notre attention sur la configuration des outils d’orchestration (Ray Serve) et d’inférence choisie (vLLM).
Nous décrivons par la suite, les éléments essentiels de la configuration des serveurs vLLM déployés sur notre infrastructure. Nous avons alloué pour les deux serveurs 70% de la VRAM avec le paramètre –gpu-memory-utilization 0.70, laissant 30% de marge de sécurité pour éviter les OOM lors des pics de charge et gérer les buffers du driver GPU.
Nous avons restreint la longueur maximale de contexte que le moteur va supporter par requête, c'est-à-dire le nombre maximal de tokens prompt + génération pour une séquence donnée [24]. Nous avons mis le paramètre —-max-model-len à 8192 pour le vlm et à 4096 pour le llm. Les deux serveurs avaient accès chacun à deux GPUs en même temps —-tensor-parallel-size 2. Ces valeurs ont été obtenues de façon empirique après avoir lancé les premières itérations des scénarios décrits dans la table 1.2.
Expérimentations
L’objectif des expérimentations que nous avons menées est de mettre sous une situation de stress notre architecture (figure 1.1) ainsi que la configuration hardware sur laquelle elle est déployée. À noter que même si les résultats montrent clairement que le VLM est plus performant que le LLM en throughput et sur l'ensemble des autres métriques, cela n’a pas d’intérêt pour cet article. Vous pouvez trouver une comparaison de l’efficience des modèles dans des ressources comme [1] ou encore [2]. Cette supériorité est expliquée par le fait que le VLM est plus petit que le LLM et dispose d’autant de ressources que le LLM. De plus, nous tenons à préciser que ce benchmark a été effectué en se connectant à l'instance depuis nos environnements locaux. Nous n'excluons pas que certains résultats en soient impactés. Cette démarche est assumée et permet de simuler une latence dite "normale" liée à l'utilisation des LLMs dans notre vie courante.
| # | Nom du scénario | Description |
|---|---|---|
| 1 | Warm up | Préchauffer les modèles, initialiser les caches et stabiliser les performances avant les vrais benchmarks. |
| 2 | Progressive test | Augmenter la charge de 1 à 50 utilisateurs en 10 min pour identifier un potentiel point de saturation. |
| 3 | Stress test | Stimuler le système avec le maintien de 50 utilisateurs pendant 5 minutes. |
| 4 | Endurance test | Évaluer la stabilité sur une longue durée avec une charge modérée (30 min avec 10 utilisateurs simultanés). |
| 5 | Prompt length impact test | Mesurer l'impact de la longueur du prompt sur la latence. |
| 6 | Generation length impact test | Quantifier le temps de décodage en fonction du nombre de tokens générés (court, moyen, long). |
| 7 | Spike test | Évaluer la résilience face à des variations brutales de charge (ex : passer de 1 à 30 utilisateurs) et mesurer le temps de récupération. |
| 8 | Image resolution impact test | Mesurer le surcoût de traitement induit par des images haute résolution (512x512, 1024x1024 et sans image) - spécifique au VLM. |
| 9 | Tensor parallel comparison | Comparer les performances entre différentes configurations hardware (TP=1 vs TP=2) et valider les choix d'architecture. |
| 10 | Router overhead test | Isoler et mesurer la latence ajoutée par la couche de routage Ray Serve par rapport à un accès direct aux moteurs vLLM. |
| 11 | Conversation KV cache test | Simuler une conversation multi-tours pour vérifier l'efficacité du KV Cache et son impact sur la réduction de latence. |
Table 1.2. Noms et descriptions des scénarios de tests mis en place pour mettre à l’épreuve l’architecture proposée dans la figure 1.2.
| Type | Nom | Description |
|---|---|---|
| Latence | Time to First Token (TTFT) | Temps écoulé entre l'envoi de la requête et la réception du premier token généré. |
| Time per Output Token (TPOT) | Temps moyen nécessaire pour générer chaque token de sortie après le premier. | |
| End-to-End Latency | Temps total entre l'envoi de la requête et la réception complète de la réponse. | |
| Queue Time | Temps d'attente de la requête dans la file avant son traitement. | |
| Prefill Time | Temps nécessaire pour traiter le prompt d'entrée et calculer le KV cache initial. | |
| Decode Time | Temps total nécessaire pour générer tous les tokens de sortie. | |
| Throughput | Tokens/sec par requête | Nombre de tokens générés par seconde pour une requête individuelle. |
| Tokens/sec total | Nombre total de tokens générés par seconde par le système (toutes requêtes confondues). | |
| Requêtes/sec | Nombre de requêtes traitées par le système par seconde. | |
| Fiabilité | Success Rate | Pourcentage de requêtes complétées avec succès. |
| Error Rate | Pourcentage de requêtes ayant échoué avec une erreur. | |
| Timeout Rate | Pourcentage de requêtes ayant dépassé le délai d'attente maximum. | |
| Retry Count | Nombre moyen de tentatives nécessaires avant la réussite d'une requête. | |
| Qualité (conversations) | Cache Hit Rate | Pourcentage de tokens du contexte retrouvés dans le cache KV. |
| Cache Improvement % | Gain de performance (réduction de latence) grâce au cache. | |
| Turn-to-Turn Latency Ratio | Ratio entre la latence du premier tour et celle des tours suivants dans une conversation. | |
| Context Growth Impact | Impact de l'augmentation de la taille du contexte sur la latence au fil de la conversation. |
Table 1.3. Ensemble des métriques suivies et collectées lors des scénarios d’expérimentation décrits dans la table 1.2.
Résultats
Nous décrivons par la suite, les résultats obtenus en analysant les métriques issues de nos 19 expérimentations totalisant 7310 requêtes. Nous ne rapportons ici qu’un ensemble de métriques choisies pour éclairer nos propos et la synthèse finale de l’article, vous pouvez retrouver l’analyse complète attachée à ce notebook marimo.
Une des métriques importantes pour l’adoption d’un produit est la latence en l’occurrence. Au vu des standards mis par les fournisseurs d’interface de chat (e.g. Open, Anthropic, Mistral, etc..), Il est raisonnable de penser que pour une conversation avec un LLM, celle-ci doit se situer autour des 2 secondes. Si elle dépasse les 5 secondes, cela impacterait l’expérience utilisateur [25].
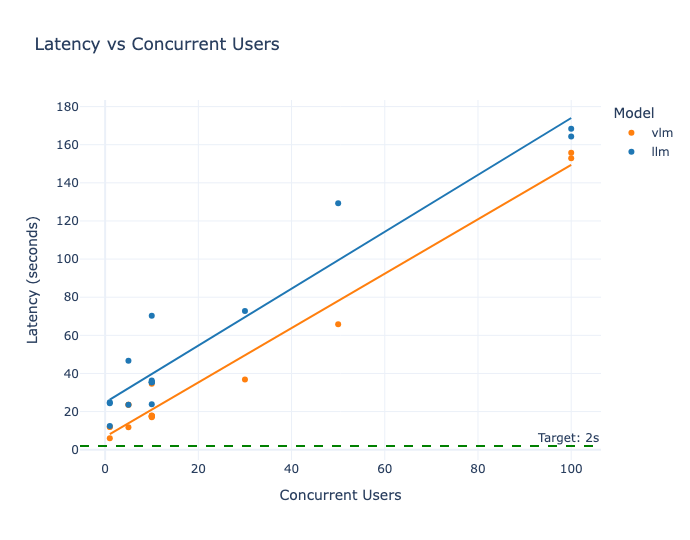 | 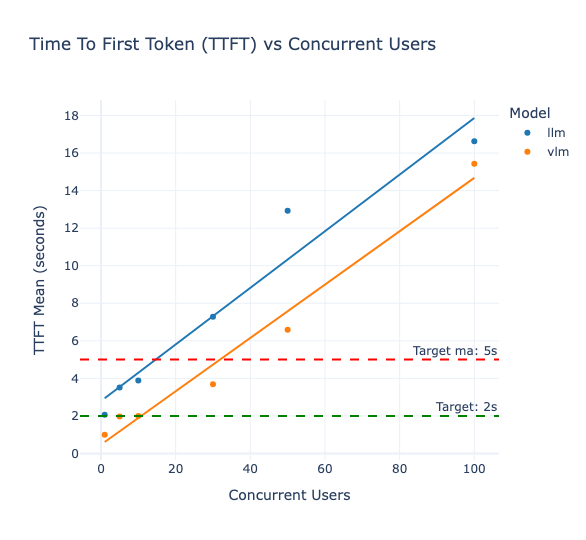 |
|---|---|
| (a) Latence en fonction du nombre d’utilisateurs concurrents. | (b) Time To First Token (TTFT) en fonction du nombre d’utilisateurs concurrents. |
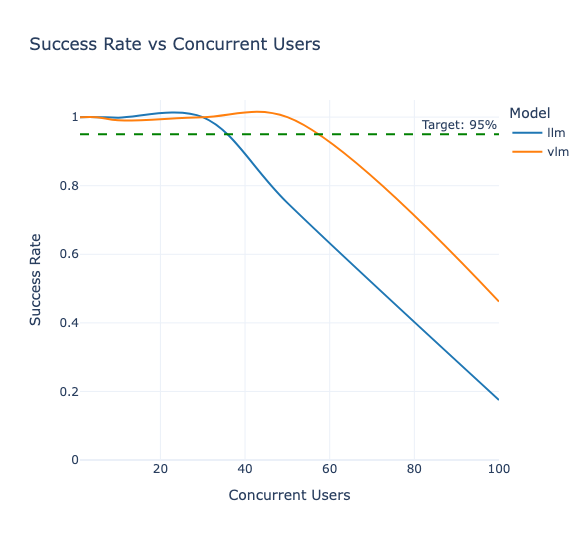 | 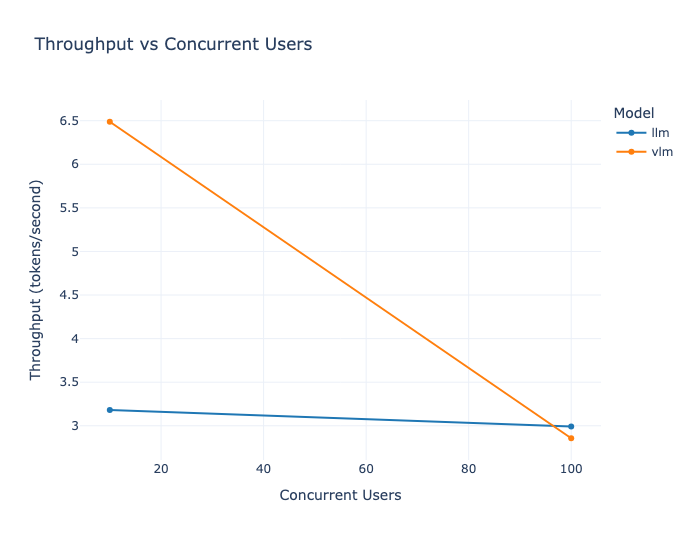 |
| (c) Le taux de réussite des requêtes envoyées aux LLMs en fonction du nombre d'utilisateurs concurrents. | (d) Throughput (tokens/seconde) par scénario. |
Figure 2.1. Les figures décrites ici représentent la valeur de différentes métriques calculées par rapport à l'augmentation du nombre d'utilisateurs concurrents pour ressource GPU.
La figure 2.1.a met en évidence deux résultats significatifs. Premièrement, dès 5 utilisateurs simultanés, la latence des deux modèles augmentent de manière significative : elle atteint 11 secondes pour le VLM et dépasse 30 secondes pour le LLM). Cet écart est cohérent avec la différence de taille et de consommation en ressources entre les deux modèles, le LLM étant le plus gourmand des deux (le LLM en FP16 nécessite à lui seul 28GB de VRAM rien que pour les poids). Sur les GPUs T4 utilisés pour cette expérimentation, il est difficile d’envisager plus de 10 utilisateurs simultanés : la latence du VLM est multipliée par 2,5 entre 1 et 10 utilisateurs, passant de 8 à 21 secondes.
Deuxièmement, à mesure que le nombre d'utilisateurs concurrents croît, l'écart de latence entre le LLM et le VLM tend à se réduire.. Le VLM, en tant que modèle multimodal, supporte un coût computationnel lié à la complexité de son architecture et de ses paramètres. Un coût qui se manifeste de manière particulièrement prononcée en situation d’accès concurrent, comme le confirment nos expérimentations.
Une seconde métrique pertinente pour évaluer les performances des LLMs en contexte conversationnel est le délai moyen avant le premier jeton généré (ou Time To First Token, TTFT), présentée dans le tableau 1.3. Ce second graphique corrobore les observations formulées à partir de la figure 2.1 et confirme l'hypothèse avancée précédemment : au-delà de 10 utilisateurs simultanés, l’expérience de l’usage se dégrade au point de compromettre l'adoption du produit. Entre 1 et 10 utilisateurs le TTFT du LLM passe de 2,6 à 4 secondes : un intervalle qui reste en deçà du seuil des 5 secondes généralement considéré comme acceptable pour une interaction conversationnelle [25]. Au-delà de ce palier de 10 utilisateurs, une montée en milieu gamme vers des GPUs A10G, ou L4 serait recommandée afin de disposer de la puissance de calcul nécessaire au maintien d’une latence compatible et d’un usage fluide.
La figure 2.1.c nous montre les limites de notre architecture. Celle-ci n'est pas prévu pour passer à l’échelle et commence à souffrir dès que l'on atteint les 50 utilisateurs simultanés. Le LLM affiche un taux de réussite de 75% lors du stress test à 50 utilisateurs concurrents, tandis que le VLM maintient 100% de succès. Cette différence s'explique par la taille supérieure du LLM (14B vs 7B) et sa consommation mémoire plus importante. Les erreurs observées sont principalement des timeouts, le système saturant en mémoire GPU. À noter que pour tous les autres scénarios (jusqu'à 30 utilisateurs concurrents), les deux modèles affichent 100% de success rate.
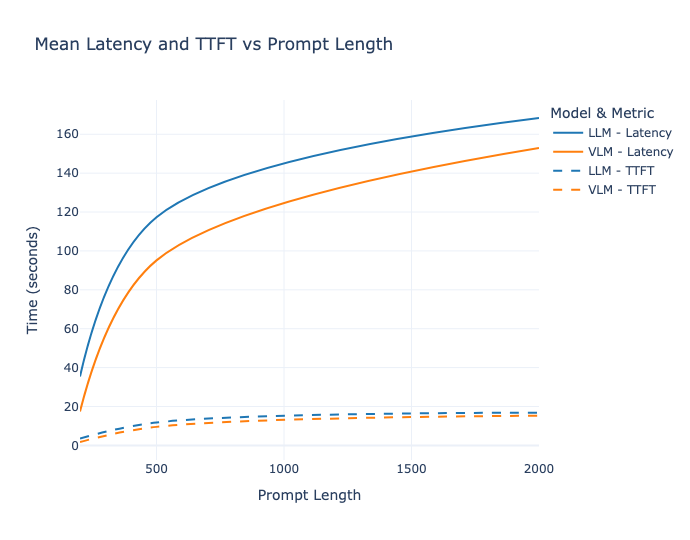
Figure 2.5. Impact de la longueur du prompt sur la latence et le TTFT moyen.
Le prompt_length_test permet d'évaluer l'impact de la longueur du contexte d'entrée. Nous avons comparé des prompts de 200 tokens (warmup standard) avec des prompts de 2000 tokens.
Pour le VLM, l'impact est important : 17,3 secondes de latence moyenne avec un prompt de 200 tokens, 152,9 secondes avec un prompt de 2000 tokens (~ x9), soit un facteur de presque 9. Le TTFT est lui aussi impacté passant de 1,7 à 15,3 secondes (x9), soit un facteur d’exactement 9. On observe le même comportement pour le LLM, avec une latence moyenne passant de 35,4 à 168,3 secondes (x5) (facteur de presque 5), et un TTFT de 3,5 à 16,8 secondes (x5)(facteur de presque 5).
Au vu des résultats, nous notons que l'augmentation de la latence n'est pas linéaire : passer de 200 à 2000 tokens (x10) multiplie la latence par environ 9x pour le VLM et 4x pour le LLM. Cette non-linéarité s'explique par la nature du prefill : le modèle doit traiter l'ensemble du prompt pour construire le KV cache initial, et le coût effectif de ce traitement tend à croître de façon plus que proportionnelle à la longueur du prompt, sous l’effet cumulé des opérations d’attention, du scheduling et des contraintes mémoire. En outre, des prompts plus longs sollicitent davantage la mémoire GPU (accès au KV cache, pression sur la bande passante), ce qui peut introduire des ralentissement additionnels.
 |  |
|---|---|
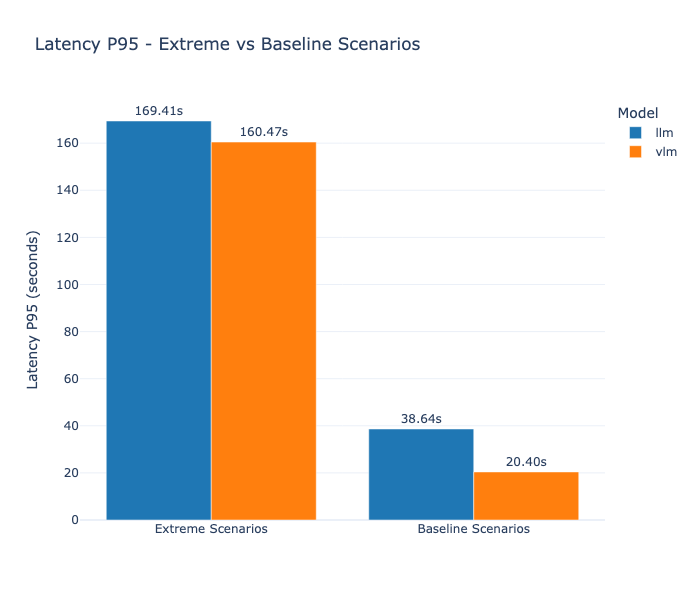
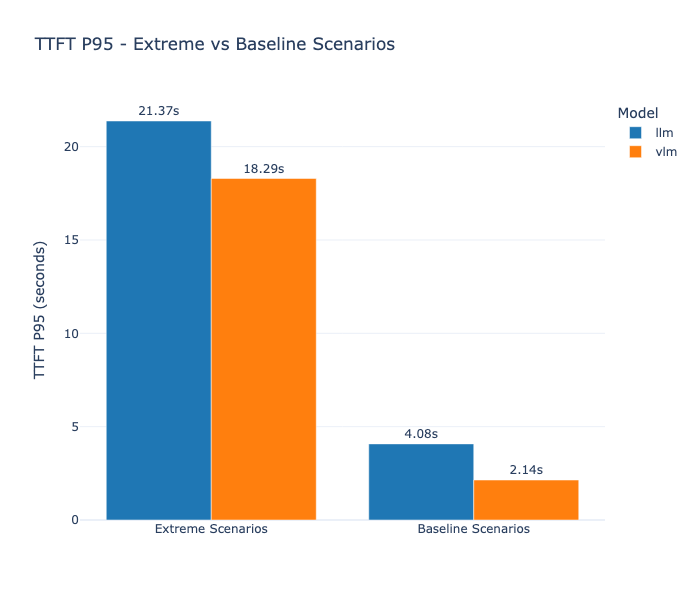
| Figure 2.6. Comparaison entre les spike tests et les autres pour la latence P95 | Figure 2.7. Comparaison entre les spike tests et les autres pour le TTFT P95 |
Les spike tests simulent des scénarios critiques : une montée brutale de la charge, par exemple, un passage instantané de 1 à 30 utilisateurs concurrents.
Les résultats confirment la résilience de l'architecture Ray + vLLM : les deux modèles survivent avec 100% de success rate, aucun arrêt brutal, aucun dépassement de mémoire. Cependant, les latences explosent : pour le LLM, la latence P95 (soit le temps après lequel 95% des requêtes se sont terminées) atteint 169,41 secondes, pour le VLM elle grimpe à 160,47 secondes. Le TTFT suit la même tendance : 21,37 secondes P95 pour le LLM, 18,29 secondes pour le VLM.
Ces latences sont évidemment inacceptables pour une expérience utilisateur fluide, mais l'absence de crash est un point positif. Le système entre en mode dégradé : les requêtes s'accumulent dans la queue (vLLM implémente une file d'attente FIFO), et chaque utilisateur reçoit sa réponse avec un délai important mais reçoit bien une réponse.
Ce résultat valide deux points : d’abord, l'architecture ne comporte pas de bug critique qui causerait un crash sous charge. Ensuite, les GPUs T4 sont inadaptés pour absorber des pics de charge au-delà de 10-15 utilisateurs. Pour un système en production, il faudrait soit re-dimensionner le hardware pour le pic (ce qui coûte cher), soit implémenter un système de limitation des taux en entrée (rate limiting) pour refuser les requêtes excédentaires plutôt que de les laisser s'accumuler dans la queue.
Synthèse et recommandations
Sur 19 expérimentations totalisant 7310 requêtes, le système affiche un taux de réussite global de 91% et une résilience remarquable : aucun arrêt brutal, aucun dépassement de mémoire (Out-of-Memory), même lors des montées en charge soudaine (les différents spike tests voir table 1.3) à 50 utilisateurs ou du stress test à 100 utilisateurs. L’architecture figure 1.2 démontre ainsi qu’elle est capable d’absorber des charges importantes sans défaillance matérielle, ni logicielle, y compris sur du matériel d’entrée-moyenne gamme.
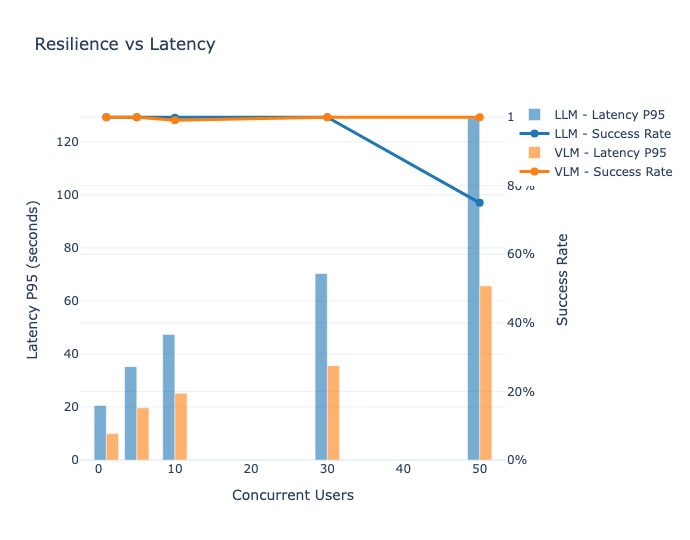
Figure 2.8. Mise en perspective entre la latence qui augmente et le sucess rate qui reste globalement stable ce qui permet d’illustrer la résilience de l’architecture.
Le plafond d'usage se situe à 10 utilisateurs simultanés sur GPU T4 : au-delà, la latence dépasse 20 secondes pour le VLM et 40 secondes pour le LLM (figure 2.1 a), et à 50 utilisateurs le LLM tombe à 75% de success rate (figure 2.1 c). L'impact de la longueur du prompt n'est pas linéaire : multiplier par 10 le nombre de tokens d'entrée augmente la latence de 4 à 9 fois selon le modèle (figure 2.5). Le regroupement dynamique de requêtes (dynamic batching) de vLLM permet de maintenir un débit global (throughput) total stable même sous forte charge. Le dynamic batching est un mécanisme qui consiste à rassembler automatiquement plusieurs requêtes entrantes en un seul lot de calcul afin de maximiser l’occupation du GPU, cela permet donc d’obtenir une résilience de l’architecture mais au prix de latences individuelles qui explosent comme le montre la figure 2.8.
Le passage à 20 ou 50 utilisateurs concurrents nécessite soit un upgrade hardware vertical vers des GPUs mid-range (A10G, L4), soit un scale horizontal avec plusieurs répliques derrière un distributeur de charge (load balancer), comme nginx. La diffusion progressive des réponses (communément appelée streaming) peut améliorer la latence perçue sans changer l'infrastructure. Limiter la longueur maximale des prompts et des générations selon le cas d'usage réduit mécaniquement la charge mémoire. L'implémentation d'un mécanisme de limitation du débit (ou rate limiting) en amont éviterait l'accumulation de requêtes dans la file d’attente lors de pics de charge, au prix d'un refus explicite plutôt qu'une dégradation progressive.
Les résultats présentées dans notre article permettent de dimensionner une infrastructure de production en fonction de l’accord sur le niveau de service visé (Service Level Agreement - SLA), mais posent aussi la question stratégique de l'arbitrage entre performance, coût et expérience utilisateur dans un contexte où les attentes en matière de réactivité des LLMs continuent d'augmenter.
Conclusion et perspectives
Les serveurs d’inférence deviennent de plus en plus accessibles et permettent de déployer soi-même une infrastructure permettant de servir l’inférence des modèles de langage et de vision à plusieurs utilisateurs, tout en gardant la maîtrise de ces données. Lors de notre expérimentation, nous avons volontairement monté une infrastructure contraignante avec des GPUs T4. Le choix de ce type de GPU est motivé par notre souhait de mener nos expérimentations avec une contrainte sur la mémoire et les capacités du calcul du hardware, afin de prêter notre attention sur la configuration des outils d’orchestration (Ray Serve) et d’inférence choisie (vLLM). L’architecture démontre qu’elle est capable d’absorber des charges importantes sans défaillance matérielle, ni logicielle, y compris sur du matériel d’entrée-moyenne gamme.
Sur 19 expérimentations totalisant 7310 requêtes, le système affiche un taux de réussite global de 91% et une résilience remarquable : aucun arrêt brutal, aucun dépassement de mémoire (Out-of-Memory), même lors des montées en charge soudaine. Des latences dans le temps de réponse ont été observées à partir de 10 utilisateurs, un passage à l’échelle horizontal avec plus de GPU ou verticale en augmentant la capacité de calcul des GPU résoudra ce problème.
Ceci démontre que l'auto hébergement des LLMs est de plus en plus abordable. Cela dit, les modèles qui sont disponibles sont en poids ouverts et ne mettent pas à disposition le corpus de texte ainsi que le code qui a permis de les entraîner. Aussi, ils n’ont pas encore atteint les performances des modèles commerciaux comme Opus 4.5 ou dernièrement Opus 4.6, même si la tendance est en train de s’inverser avec la sortie de GLM5 qui s’approche des performances d’Opus 4.5 [26]. Nos perspectives seront donc orientées vers le déploiement et la mise en service de ces modèles pour outiller les développeurs, par exemple avec des assistants de code auto-hébergé, et évaluer leur pertinence par rapport aux modèles commerciaux.
Bibliographie
[1] LiveBench, “AI Leaderboard.” [En ligne]. Disponible sur : https://livebench.ai/#/.
[2] OpenRouter, “AI Rankings.” [En ligne]. Disponible sur : https://openrouter.ai/rankings.
[3] Hugging Face, “Blog: Mixture of Experts.” [En ligne]. Disponible sur : https://huggingface.co/blog/moe.
[4] OpenAI, “Tokenizer.” [En ligne]. Disponible sur : https://platform.openai.com/tokenizer.
[5] Artificial Analysis, “Model Comparison.” [En ligne]. Disponible sur : https://artificialanalysis.ai/models/.
[6] Google Cloud, “Vertex AI: Function Calling.” [En ligne]. Disponible sur : https://docs.cloud.google.com/vertex-ai/generative-ai/docs/multimodal/function-calling.
[7] Anthropic, “News: Model Context Protocol.” [En ligne]. Disponible sur : https://www.anthropic.com/news/model-context-protocol.
[8] OCTO Technology, “Comprendre le Model Context Protocol (MCP).” [En ligne]. Disponible sur : https://blog.octo.com/comprendre-le-model-context-protocol-(mcp)--connecter-les-llms-a-vos-donnees-et-outils.
[9] Khatua, Arpandeep, Hao Zhu, Peter Tran, Arya Prabhudesai, Frederic Sadrieh, Johann K. Lieberwirth, Xinkai Yu et al. "CooperBench: Why Coding Agents Cannot be Your Teammates Yet." arXiv preprint arXiv:2601.13295 (2026).
[10] M. Alderson, “Two Kinds of AI Users Are Emerging.” [En ligne]. Disponible sur : https://martinalderson.com/posts/two-kinds-of-ai-users-are-emerging/..
[11] Robbes, Romain, Théo Matricon, Thomas Degueule, Andre Hora, and Stefano Zacchiroli. "Agentic Much? Adoption of Coding Agents on GitHub." arXiv preprint arXiv:2601.18341 (2026).
[12] Pan, James, and Guoliang Li. "A Survey of LLM Inference Systems." arXiv preprint arXiv:2506.21901 (2025).
[13] Kwon, Woosuk, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. "Efficient memory management for large language model serving with pagedattention." In Proceedings of the 29th symposium on operating systems principles, pp. 611-626. 2023.
[14] Zheng, Lianmin, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao et al. "Sglang: Efficient execution of structured language model programs." Advances in neural information processing systems 37 (2024): 62557-62583.
[15] Rajesh, Varun, Om Jodhpurkar, Pooja Anbuselvan, Mantinder Singh, Ashok Jallepali, Shantanu Godbole, Pradeep Kumar Sharma, and Hritvik Shrivastava. "Production-Grade Local LLM Inference on Apple Silicon: A Comparative Study of MLX, MLC-LLM, Ollama, llama. cpp, and PyTorch MPS." arXiv preprint arXiv:2511.05502 (2025).
[16] Apple Open Source, “MLX Framework.” [En ligne]. Disponible sur : https://opensource.apple.com/projects/mlx/. [Accès : 9 Fev 2026].
[17] Server Parts, “Nvidia T4 vs A100 GPU Comparison.” [En ligne]. Disponible sur : https://www.server-parts.eu/post/nvidia-t4-vs-a100-gpu-comparison-ai-deep-learning-data-centers. .
[18] Apxml, “Memory Compute Bottlenecks Inference.” [En ligne]. Disponible sur : https://apxml.com/courses/llm-compression-acceleration/chapter-1-foundations-llm-efficiency-challenges/memory-compute-bottlenecks-inference.
[19] Ori, “Nvidia L40S GPU Comprehensive Overview.” [En ligne]. Disponible sur : https://www.ori.co/blog/nvidia-l40s-gpu-comprehensive-overview.
[20] Nvidia, “Data Center: A10 GPU.” [En ligne]. Disponible sur : https://www.nvidia.com/fr-fr/data-center/products/a10-gpu/.
[21] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019, June). Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) (pp. 4171-4186).
[22] VASWANI, Ashish, SHAZEER, Noam, PARMAR, Niki, et al. Attention is all you need. Advances in neural information processing systems, 2017, vol. 30
[23] Radford, A., & Narasimhan, K. (2018). Improving Language Understanding by Generative Pre-Training.
[24] vLLM engine arguments [En ligne]. Disponible sur : https://docs.vllm.ai/en/stable/configuration/engine_args/
[25] Maslych, M., Katebi, M., Lee, C., Hmaiti, Y., Ghasemaghaei, A., Pumarada, C., ... & LaViola Jr, J. J. (2025, July). Mitigating response delays in free-form conversations with LLM-powered intelligent virtual agents. In Proceedings of the 7th ACM Conference on Conversational User Interfaces (pp. 1-15)
[26] Claude Opus 4.5 vs GLM5 [En ligne]. Disponible sur : https://llm-stats.com/models/compare/claude-opus-4-5-20251101-vs-glm-5