Utiliser Hadoop pour le calcul de la Value At Risk Partie 1
Après avoir introduit la Value At Risk dans mon premier article, je l'ai implémentée en utilisant GridGain dans mon second article. J'ai conclu dans ce dernier que les performances relativement bonnes obtenues étaient liées aux optimisations réalisées. L'une d'elles était basée sur l'hypothèse que les résultats intermédiaires - les prix issus de chaque tirage - pouvaient être oubliés. Cependant, ce n'est pas toujours le cas. Conserver les paramètres de génération et les prix des calls pour chaque tirage peut être très utile pour le métier afin de pouvoir analyser l'influence des différents paramètres. De telles données sont souvent traitées par des outils de Business Intelligence. Le calcul de la VAR n'est peut être pas le meilleur exemple pour illustrer ce besoin métier mais je vais le réutiliser car il a déjà été introduit dans un précédent artcile. L'objectif de cette série d'articles sera de calculer la Value At Risk et de conserver tous les résultats, de façon à pouvoir les analyser.
- Dans la première partie, je décrirai comment conserver ces données aussi bien avec GridGain qu'avec Hadoop
- Dans les trois parties suivantes, je décrirai en détail les implémentations avec Hadoop. Ces parties fournissent des exemples de code très utiles mais peuvent être ignorées au besoin en première lecture
- Dans la cinquième partie, je montrerai comment utiliser Hadoop pour réutiliser de l'analyser décisionnelle sur ces données
- Et dans la dernière partie, je donnerai quelques chiffres de performances et sur les possibilités d'amélioration
Dans ces articles, certaines portions de code ont été supprimées lorsqu'aucune évolution n'avait eu lieu depuis le dernier article. Ces portions ont été remplacées par des commentaires (//Unchanged...).
Evolution de l'implémentation courante
La façon la plus simple de répondre au besoin est de modifier l'implémentation courante. J'ai créé pour cela une classe Result qui porte les paramètres et le prix pour chaque tirage. Elle implémente Serializable de façon à pouvoir être stockée sur le disque et Comparable de façon à pouvoir être triée de la même façon que les prix.
public class Result implements Serializable, Comparable<result> {
private final Parameters parameters;
private final double price;
//Constructor, getters, compareTo(), equals(), hashCode(), toString() implementations...
}
computeVar() signature is modified accordingly.
public SortedSet<result> computeVar(...) throws MathException {
//Unchanged...
for (int i = 0; i < drawsNb; i++) {
//Unchanged....
final Result result = new Result(new Parameters(optionPricer.getParameters()),price);
// For each draw, put the price in the sorted set
smallerPrices.add(result);
if(configuration.isCombineAllowed()) {
//Unchanged...
}
}
return smallerPrices;
}
Enfin, les résultats sont écrits sur le disque en appelant FilePersistenceManager.writeToDisk() qui délègue simplement à un ObjectOutputStream branché sur le disque.
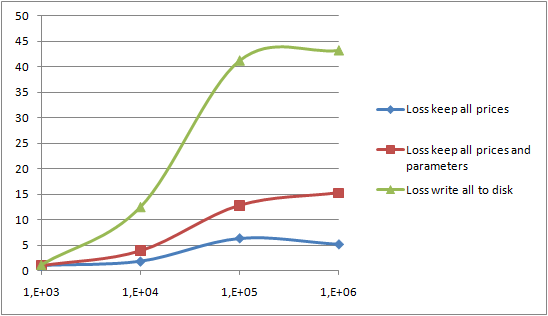
Quelques mesures, réalisées sur le même portable que pour le précédent article, montre comme nous pouvions nous y attendre, des impacts de performance :
- La consommation mémoire de la Heap s'est accrue car une collection d'objets
Resultest plus grosse qu'une collection de simplesdouble. En fait, sur mon architecture 32 bits, je n'ai pas été capable de générer plus de 1000000 de résultats. - Ecrire les données sur le disque conduit à un très fort taux d'entrées/sorties. Ecrire un fichier de 1000000 de résultats avec la sérialisation Java conduit à un fichier de 61 MB. Mon disque dur était saturé avec un débit continu de 7 MB/s.
Le graphique suivant montre la perte liée au stockage des résultats intermédiaires comme définie ci-dessous, à travers les différents scénarios.
, Ces scénarios sont définis comme indiqués ci-dessous.
- optimisation "combine" (implémentation de référence) : seuls 10% des tirages sont renvoyés à la fonction cliente. Voir le premier article pour plus d'explications
- Sans optimisation : tous les prix résultants des tirages sont envoyés au client
- Tous les résultats : à la fois les prix et les paramètres utilisés pour calculer ces prix sont envoyés au client
- Ecriture sur le disque: les résultats sont stockés sur le disque en utilisant la sérialisation Java
Le choix d'Hadoop
Présentation d'Hadoop
Hadoop, est un projet Apache qui se définit lui-même comme un projet open-source pour du calcul distribué, scalable et fiable (an open-source software for reliable, scalable, distributed computing). Selon Wikipedia il permet de travailler avec des milliers de noeuds et des petabytes de données. En bref, il s'agit d'un outil employé par Yahoo pour traiter de très gros volumes de données. Son architecture a été inspirée par Google MapReduce and Distributed File System. Je ne le décrirai pas plus avant. Je vous renverrai vers cet article pour de plus amples informations.
Pourquoi choisir Hadoop?
J'ai décidé d'implémenter ce calcul de VAR avec Hadoop pour 3 raisons :
- Une telle architecture a prouvé son efficacité sur les tâches informatiques les plus lourdes comme l'indexation du web.
- Hadoop est basé sur le pattern map/reduce qui est la base de mon implémentation de la VAR
- L'émergence d'un nouveau paradigme, appelé "NoSQL trace la route pour de nouvelles architectures et cet article était une occasion d'explorer cette voie aujourd'hui.
Plus spécifiquement, les architectures "NoSQL" sont bien adaptées aux traitements décisionnels. Aussi, j'ai voulu voir s'il était possible de combiner les deux fonctions dans un seul outil. Un des avantages serait de limiter la quantité de données transportées d'un outil à un autre. Pour ce faire, j'ai utilisé Hadoop pour le map/reduce et pour l'analyse avec Hive. Hive est une sorte de petit system de datawarehouse conçu au dessus de Hadoop. En pratique, il fournit un petit DSL très proche du SQL, qui est transcrit en actions de map/reduce. Je vous renvoie à cet article pour plus de détails sur l'installation de Hive.
Implémentations de Hadoop et de Hive
Hadoop et Hive sont des systèmes basés sur la manipulation de fichier (en conservant en tête qu'ils sont basés sur un système de fichiers distribué). Hadoop consiste donc en un système de fichier distribué (Distributed File System) - qui permet de partager le code et les données entre noeuds (les machines) -, et d'un ensemble de travaux (jobs), divisés en tâches map et reduce coordonnées par le framework Hadoop. Ainsi, Hadoop fournit nativement :
- Un système de stockage distribué et un mécanisme pour partitionner la donnée : chaque fichier est stocké sous la forme d'un ensemble de blocs distribués à travers les machines physiques, éventuellement avec de la réplication. La vision du développeur reste celle d'un système de fichier, Hadoop se chargeant de la complexité de la distribution.
- Un mécanisme de coordination des travaux avec affinité locale. De façon à améliorer drastiquement les performances pour un grand volume de données, les tâches sont exécutées sur le noeud où se trouvent les données impactées.
Hadoop traite des fichiers. Pour mon besoin je lui ai fourni en entrée le fichier suivant.
1;252;120.0;120.0;0.05;0.2;0.15;1000;0.99;250
1;252;120.0;120.0;0.05;0.2;0.15;1000;0.99;250
1;252;120.0;120.0;0.05;0.2;0.15;1000;0.99;250
1;252;120.0;120.0;0.05;0.2;0.15;1000;0.99;250
Chaque ligne signifie: Calcule 250 tirages du prix du call avec les paramètres suivants (t=252 days, s0=120€, k=120€, r=0.05%, sigma=0.2, historicalVolatility=0.15) pour ce scenario 1. L'objectif est de calculer la VAR à 1% (0.99) sur 1000 tirages. Je vous renvoie à mon précédent article pour plus d'explications sur ces paramètres. L'implémentation sur Hadoop est décrite ci-dessous. La numérotation correspond aux étiquettes sur le schéma et fait référence à l'ordre chronologique: 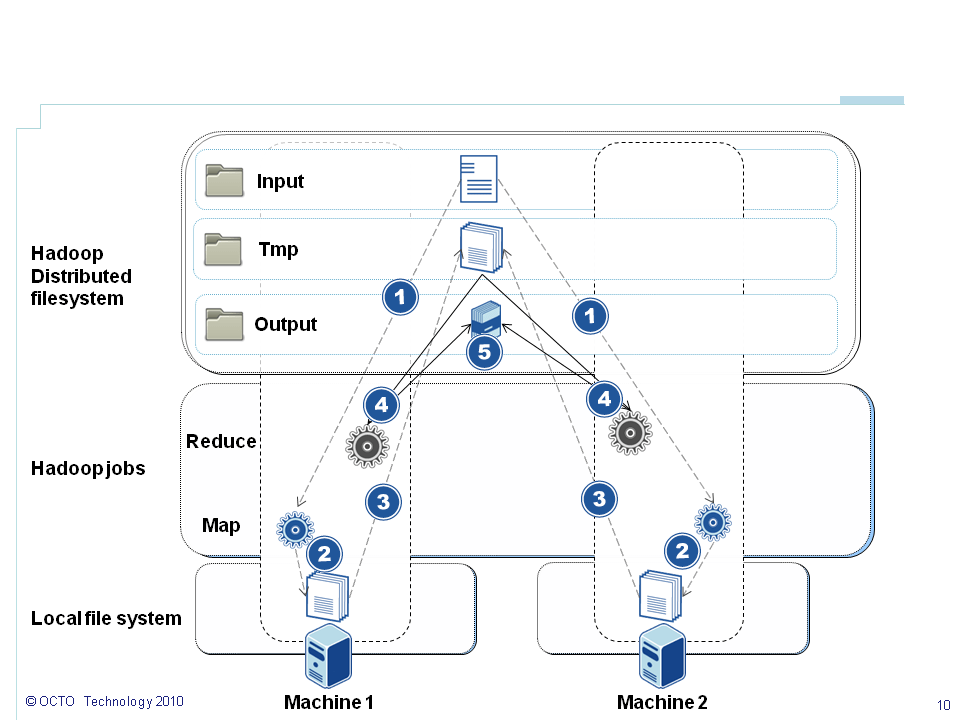
- 1. J'ai choisi de partitionner les données ligne par ligne (utilisation du
NLineInputFormat, décrite dans un prochain article de cette série), ce qui signifie que chaque ligne sera envoyée à un créneau de tâchemap - 2. 250 tirages sont réalisés au sein de la phase
mapet les prix sont calculés. Les résultats sont stockés temporairement dans le système de fichier local. Le format de sortie sera clé-valeur comme décrit ci-après - 3. Les résultats sont pré-triés par clé et partagés à travers le système de fichiers
- 4. Les résultats sont envoyés à la tâche
reduce. Pour les besoins de la première implémentation, je n'ai pas utilisé de code dans la partiereducecomme nous le verrons dans le prochain article 5. Les résultats sont partagés sur le système de fichiers distribué
Ainsi, l'implémentation avec GridGain a montré que stocker les résultats sur le disque a un impact sur les performances. Hadoop est un outil différent. Il est moins optimisé pour les tâches de calcul intensif mais fournit un framework efficace pour distribuer le traitement de gros volumes de données. Son implémentation du pattern map/reduce est assez différente de celle de GridGain et nécessite un certain nombre d'adaptations pour calculer la VAR. Nous discuterons en détail, dans le prochain article de cette série, l'implémentation du calcul de la VAR. Les trois parties qui suivront se concentreront sur du code et des détails d'implémentation. Les personnes les moins intéressées par la technique pourront reprendre la série au niveau de la partie 4 où j'introduirai l'analyse des données intermédiaires.