Une gestion d’incidents méthodique : transformer chaque dysfonctionnement en opportunité pour améliorer son système
Depuis plus de 2 ans, notre équipe de 6 Ops/SRE est responsable de l'infrastructure hébergeant un système critique qui doit être disponible 24h/24, 7j/7. Comme tout système informatique, cette plateforme a été, et sera confrontée à des incidents.
Dans cet article, nous allons vous partager ce que nous avons mis en place pour gérer au mieux les incidents : nos pratiques, nos outils et nos apprentissages.
Anatomie d'un incident
Commençons par une définition : Un incident survient quand le système se retrouve dans un état qui demande une intervention immédiate et que les utilisateurs de ce système sont ou vont être impactés.
On peut décomposer les différentes étapes d’un incident comme suit :
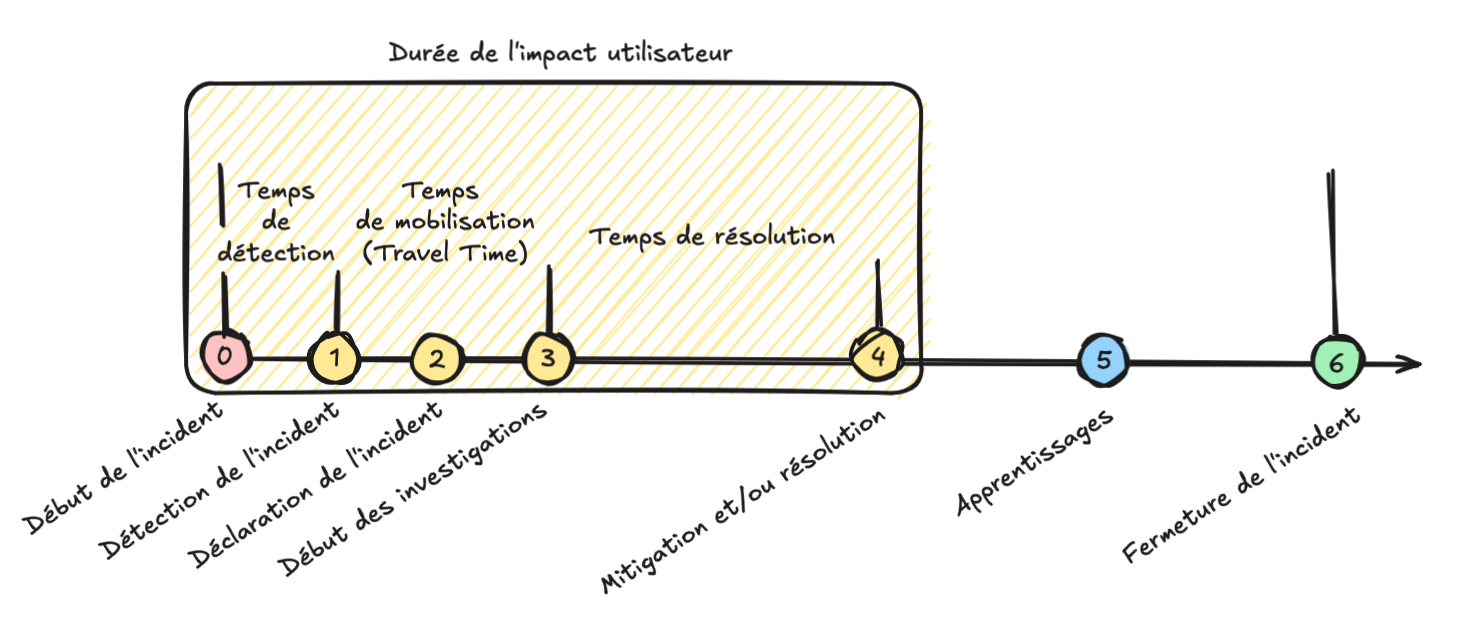
Pour minimiser l'impact d’un incident, nous cherchons à améliorer :
- Notre temps de détection : détecter les incidents le plus tôt possible, idéalement avant qu'ils impactent les utilisateurs
- Notre temps de mobilisation : le "temps de trajet" que l’on met entre le moment où nous sommes appelés pour intervenir et le moment où nous commençons effectivement à intervenir
À travers notre système de gestion d’incident, nous souhaitons atteindre 2 objectifs :
- Le premier, tactique et court terme : minimiser l'impact des incidents pour les utilisateurs
- Le second, stratégique et long terme : éviter que cet incident ou d'autres incidents du même type ne se reproduisent
Dans le cadre de cet article, nous nous concentrerons particulièrement sur les étapes 2 à 6 d’un incident. Pour chacune de ces étapes, nous avons mis en place - au fur et à mesure - des règles qui nous ont permis d’améliorer notre gestion des incidents.
Étape 1 - Détection de l’incident
Il existe énormément de littérature sur les outils et techniques pour détecter efficacement une anomalie sur un système technique. Globalement, notre système se compose :
- de monitoring via une stack Prometheus/Grafana, principalement utilisée par les équipes “Infra”
- de logging et de tracing via une stack EFK (Elastic - Fluentbit - Kibana), principalement utilisée par les équipes de développement
- d’alertes basées sur nos outils de monitoring/logging/tracing qui remontent dans Slack, visibles et utilisées par tous
Cet outillage permet de détecter la majorité des incidents bloquants (la plateforme ne fonctionne pas du tout). En revanche, il nous arrive régulièrement de nous baser sur des remontées utilisateurs pour d’autres problèmes moins binaires (erreurs de données, problèmes de performances côté “front”, incidents localisés chez un client en particulier, etc.). Pour ce genre de cas, nous avons mis en place des canaux Slack dédiés avec nos utilisateurs qui sont monitorés par les équipes d’exploitation.
Étape 2 - Déclaration de l’incident : optimiser son "temps de trajet"
Le "temps de trajet" c'est le temps que met l’équipe d’investigation à "arriver sur la scène", c’est une analogie avec le temps que mettent les services d’urgence entre la prise d’un appel et leur arrivée sur un sinistre. Dans le cas d'un incident, c'est le temps entre la remontée d'un incident et le début des investigations. Nous avons cherché à rendre ce temps de trajet le plus court possible en rendant la déclaration et la mobilisation d’un incident les plus simples et les plus rapides possible.
Rendre la déclaration d'un incident la plus simple et rapide possible
Nous utilisons Slack comme outil de communication principal. Sur Slack, nous avons un canal #production dédié aux échanges avec nos utilisateurs. C’est ici que nous annonçons nos opérations de maintenance et que sont partagés les éventuels problèmes.
Nous considérons que n’importe qui doit pouvoir déclarer un incident. Par conséquent, nous avons rendu le processus aussi simple que possible : il suffit d’ajouter l'emoji :incident: à un message sur le canal #production. Un workflow automatique Slack est alors exécuté, ce workflow :
- Demande de définir un titre à l’incident
- Crée automatiquement un nouveau canal dédié au format #date-heure-titre-de-l-incident
- Invite une liste de personnes pré-définies dans le canal (nous avons dans cette liste les différents stakeholders, les référents fonctionnels, les experts techniques…)
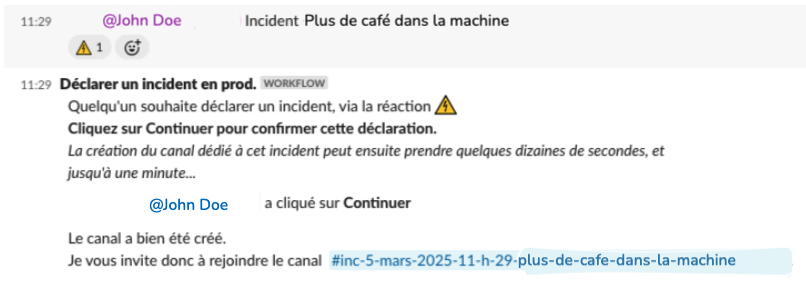
Dans ce nouveau canal, un template de document est déjà présent dans un canevas. Ce canevas contient déjà l’ensemble des rubriques pour consigner toutes les informations nécessaires aux différentes étapes de traitement de l’incident :
- Une première section “résumé/organisation” pour avoir une vue rapide de l’incident et pour distribuer les rôles
- Une section “chronologie” pour consigner toutes les actions/informations durant la gestion de l’incident
- Plusieurs sections qui serviront lors des étapes de restitution et d’apprentissage

Rendre la mobilisation des intervenants la plus simple et rapide possible
Maintenant que nous avons simplifié la déclaration d’incident, il faut réussir à réunir rapidement les bonnes équipes pour intervenir.
Nous avons parlé plus haut d’un canal slack #production unique qui centralise toutes les informations liées à la production. En plus de ce canal, nous avons également :
- En physique, une salle de visio conférence dédiée au “cockpit” (ainsi qu’une petite salle de débord en cas de besoin)
- En distanciel, un lien visio unique, disponible 24h/24 et accessible facilement depuis les marques pages de notre canal slack #production
Afin de pouvoir assurer un support aux utilisateurs 24/7, nous avons mis en place deux systèmes sensiblement différents en heures ouvrées (HO) et en dehors des heures ouvrées (HNO).
Pendant les Heures Ouvrées (HO)
Chaque jour, dans chaque équipe (Dev, Ops, Data, etc.), un référent est responsable du “support” (dans d’autres organisations, on parle de “gilet jaune” ou de “sheriff”). Cette personne a la charge, pour la journée, de garder un oeil sur le canal #production et d’intervenir rapidement si un incident est déclaré. La fréquence de rotation du référent est propre à chaque équipe. Dans l’équipe Ops, nous avons choisi d’avoir un binôme de support qui tourne à chaque sprint de 2 semaines.
- La liste des référents est mise à jour chaque matin et partagée dans un canevas du canal #production.
- Pour les équipes : cela permet de définir clairement, dès le début de la journée, qui est chargé d’intervenir sur un incident si nécessaire. Plus de question à se poser ou d’arbitrage entre une réunion “importante” ou un incident : la priorité pour la personne de support pour cette journée, c’est de répondre aux incidents.
- Pour le reste de l’organisation : cela permet de savoir qui peut être dérangé si on a une question à propos d’une application en particulier.
En cas de déclaration d’incident sur le canal #production, par défaut :
- Toutes les personnes “de support” se connectent sur le canal de visio cockpit depuis là où elles travaillent ou se rendent en salle “cockpit”.
- Les différents référents peuvent sortir de l’incident après avoir validé qu’ils n’étaient pas utiles à sa résolution (on peut parfois avoir besoin d’une personne, non pas pour son expertise technique, mais pour tenir un autre rôle plus logistique : prendre des notes (scribe), assurer la communication, etc.).
Pendant les Heures Non Ouvrées (HNO)
Notre dispositif d'astreinte s'articule autour de deux niveaux d'intervention, tous deux composés de membres issus des équipes techniques.
Le premier niveau regroupe des référents transverses, joignables directement par téléphone par nos utilisateurs. Ils possèdent une bonne connaissance fonctionnelle et technique du système, comprennent la criticité des différentes briques et connaissent les moyens de contournement possibles. Leur rôle est d'évaluer la situation et de décider s'il est nécessaire de déclencher un dispositif de réponse à incident plus conséquent.
Le second niveau est composé d'experts techniques, mobilisés uniquement en cas d'incident confirmé. À ce jour, seule l'équipe Infra assure une astreinte de second niveau en 24/7. Ces experts interviennent pour résoudre techniquement l'incident une fois qu'il a été déclaré par le premier niveau.
Si les référents de premier niveau décident qu'un incident doit être déclaré :
- Ils créent l'incident via le canal #production
- Ils contactent par téléphone les experts de second niveau nécessaires
- Tout le monde se connecte sur la visio "cockpit"
- Le reste du déroulement est similaire à ce qui se passe en heures ouvrées
Peu importe que ce soit en HO ou en HNO, voici quelques règles générales que nous nous sommes fixés concernant la déclaration d’incident :
- Mieux vaut déclarer un incident trop tôt que trop tard : en cas de suspicion, c’est OK de déclencher une mobilisation. Dans le doute, on peut également demander un second avis ou solliciter nos référents utilisateurs pour voir s’ils détectent quelque chose sur le terrain
- Déclencher un incident en heures ouvrées interrompt une bonne dizaine de personnes et a donc un impact sur le delivery, il faut savoir garder un certain équilibre
- Dans tous les cas, on ne remet pas en cause la nature de l’incident pendant sa déclaration : si on juge que ce n’était pas vraiment une bonne raison pour mobiliser toute une équipe de réponse, on pourra en discuter plus tard lors de la phase 6 d’apprentissage
Étapes 3 et 4 - Mitigation/Résolution : s’organiser pour des investigations efficaces
L’importance d’avoir des rôles prédéfinis
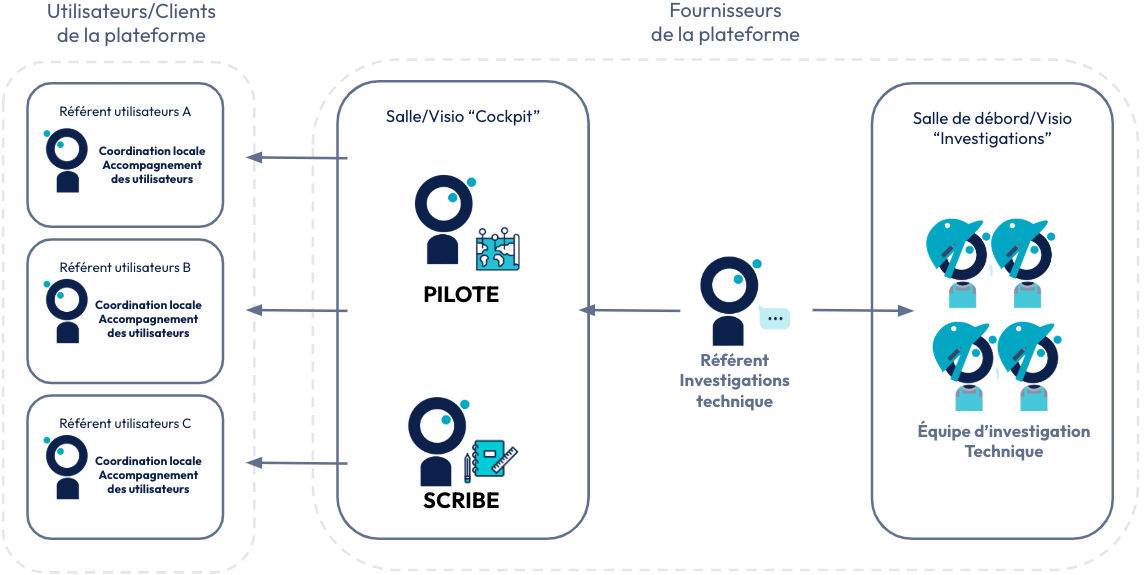
Comme vous avez pu le voir dans le canevas partagé plus haut, nous avons deux rôles définis pour chaque incident.
Le pilote
Le pilote est le responsable de l'incident. Il coordonne l'ensemble de la réponse et assure plusieurs missions clés :
Coordination et animation :
- Orchestrer les différents acteurs mobilisés sur l'incident
- Animer les discussions : distribuer la parole, s'assurer que les messages et échanges sont bien compris par tous
- Organiser le(s) groupe(s) de travail et coordonner les interventions
Communication et suivi :
- Centraliser toutes les communications : toute question, demande d'intervention ou proposition d'aide passe par lui
- Maintenir à jour le statut de l'incident et répondre aux questions
- Assurer l'interface publique de l'incident (dans certaines organisations où la communication externe est plus complexe, ce rôle peut être délégué à une personne dédiée)
En heures ouvrées, c'est généralement un responsable de direction (produit, technique ou data) qui prend ce rôle de Pilote, s'il est disponible. Dans notre contexte, le rôle d’interface avec les référents utilisateurs est sensible et il est intéressant d’avoir quelqu’un faisant figure d’autorité.
En heures non ouvrées, c’est généralement la personne d’astreinte de premier niveau qui prend ce rôle.
Sur des incidents complexes et transverses qui nécessitent des investigations horizontales sur plusieurs applications ou verticales sur plusieurs couches de la stack, nous découpons le rôle de pilote en deux : il reste un pilote principal de l’incident en charge de la coordination des différents acteurs, et nous désignons un pilote technique chargé d’animer les investigations et actions sur la plateforme.
Le scribe
Le scribe est en charge de noter (avec horodatage) dans le canevas l’ensemble des informations qui sont partagées dans les discussions :
- Les erreurs remontées
- Les actions qui ont été prises
- Les pistes envisagées
- Les personnes qui sont montées/sorties de l’incident
- Le statut et les impacts pour les différents utilisateurs
- Les décisions prises
Ces informations sont très utiles pour toute personne qui arrive au milieu de l’incident. Simplement en lisant la chronologie dans le canevas, elle doit être capable de comprendre à peu près où en est l’incident.
Ces informations seront encore plus utiles lors de la phase d’apprentissage quand il s’agira de revenir sur les différents éléments de l’incident pour en tirer des axes d’amélioration.
N’importe qui peut prendre le rôle de scribe. Il arrive souvent que ce soit quelqu’un qui n'ait pas de compétences particulières sur l’incident qui prenne ce rôle car il n'aura pas besoin d'intervenir dans l'investigation et sera consacré à la prise de note.
Bien que le scribe soit le principal responsable de la tenue du chronogramme, n’importe qui peut et doit compléter ou corriger ce qui est écrit.
Créer un sous groupe d’investigation si nécessaire
Nous pouvons rapidement avoir beaucoup de monde sur la visio d’un incident et chacun a souvent des besoins différents :
- Les référents de nos utilisateurs ont notamment besoin de savoir :
- S'ils doivent enclencher leurs procédures de backup
- Basculer sur leur “mode secours”
- Ce qu’ils doivent communiquer à leurs équipes
- Les experts techniques ont besoin d’informations plus spécifiques sur le système, par exemple :
- Quelle brique est impactée ?
- Comment est-elle impactée ?
- Est-ce que l’on peut isoler certains comportements, certains chemins réseaux en particulier ?
Nous nous donnons donc le droit de séparer les équipes et ainsi les discussions en plusieurs groupes de travail :
- Soit en présentiel à l'aide d'une salle juste à côté du cockpit
- Soit à distance sur un lien visio dédié
Si un groupe part en investigation, il décide en accord avec le pilote de l’incident comment ils vont communiquer leur avancement : soit le pilote vient prendre des nouvelles toutes les N minutes soit une personne du groupe d’investigation est désignée pour faire le pont entre les deux visios et apporter de la visibilité à tous sur l’avancement des investigations.
Partager et centraliser toutes les informations
Toutes les informations liées à l’incident doivent être partagées dans le canal slack dédié. Soit dans le canevas dans la section dédiée, soit en vrac dans la conversation du canal.
Chaque participant est invité à partager toute information qu’il peut découvrir ou sur laquelle il travaille : captures d’écran du produit ou d’outils de monitoring/observabilité, liens vers de la documentation, résultats d’investigations, etc.
Nous encourageons le partage d’informations, même incertaines. Un simple message descriptif avec une capture d’écran suffit. Il n’est pas nécessaire de chercher à ordonner ou filtrer l’information à priori.
L’objectif est de centraliser un maximum d’informations en temps réel, pour assurer un partage uniforme entre les intervenants et pour faciliter leur exploitation lors de l’analyse post-incident.
Éviter les loups solitaires
Nous évitons à tout prix le “loup solitaire” qui investigue et lance des actions dans son coin. Nous cherchons systématiquement à créer des binômes/équipes d’investigations et à partager toutes les informations et actions prises.
Nous évitons les actions simultanées et désordonnées sur la production (actions que l’on ne sera pas capable de tracer et d’expliquer). Toute action sur la production doit d’abord être partagée avec le pilote et le reste du groupe d’investigation.
Nous cherchons également à créer une dynamique d’apprentissage. Si une personne est assez à l’aise dans les investigations, il est important qu’elle embarque avec elle des personnes qui le sont moins pour pouvoir partager ses connaissances sur la plateforme, sur ses outils et méthodes d’investigations, etc.
Comme pour une équipe de foot sur le terrain, la tactique et la stratégie ont été discuté en avance : chacun a sa place définie dans l’équipe. Des imprévus peuvent arriver et il faudra alors compenser durant la partie mais globalement chacun a son rôle et il est important que chacun sache ce qu’il doit et ne doit pas faire.
Étape 5. Apprentissages : Améliorer ses systèmes grâce aux incidents
Nous aspirons à construire un système anti-fragile : un système qui se renforce à chaque panne ou incident. Chaque incident est une opportunité pour prendre des décisions/actions et en apprendre davantage sur le fonctionnement de notre système :
| Notre système technique | Notre système social/organisationnel |
|---|---|
| - Pourquoi avons-nous ce dysfonctionnement au niveau de l’infrastructure ? - Pourquoi avons-nous ce problème entre ces deux applications ? - Pourquoi notre monitoring n’a-t-il pas détecté cette panne ? - Pourquoi n’avons-nous pas remarqué ce comportement sur nos plateformes ante-prod ? - … | - Pourquoi n’avons-nous pas réussi à mobiliser les bons experts rapidement ? - Pourquoi n’avons-nous pas réussi à communiquer efficacement ? - Pourquoi seule Mathilde était-elle capable de se connecter sur la machine qui nous bloquait ? - Pourquoi seul Arnaud a-t-il été capable de débugger l’incident ? - Pourquoi personne n’a-t-il communiqué aux utilisateurs que la situation était désormais résolue ? - … |
Ainsi, nous sommes partis du principe qu’un incident n’est pas “terminé” lorsqu’il est résolu. Il n'est terminé que lorsque nous l’avons étudié pour en tirer des axes d’amélioration.
Le rituel de post-mortem : un point de revue et d’apprentissage collectif
Pour éviter d’avoir à coordonner des agendas souvent surchargés, nous avons décidé de bloquer un rituel “post-mortem” hebdomadaire d’une heure. Ce rituel est ouvert à tout le monde : chacun peut venir soit pour participer et apporter quelque chose à la discussion, soit pour écouter afin d'apprendre et de comprendre ce qu'il s'est passé.
La liste des incidents qui sont traités est partagée avant chaque rituel pour que chacun sache s'il doit ou souhaite participer.
Le rituel est organisé comme suit :
- Pour chaque incident, et durant la séance, nous prenons 10/15 minutes pour que chacun puisse relire dans son coin le canevas de l’incident et y ajouter soit des compléments, soit des questions (les canevas Slack permettent d’être annotés par des commentaires)
- Nous partons du principe que, s’il n’y a pas de commentaire, c’est que tout le monde est en phase et a compris ce qui est écrit
- Chaque commentaire (question, remarque, désaccord, etc.) est analysé et discuté entre les personnes présentes pour améliorer le document
- Ces discussions nous permettent de valider collectivement les sections “Root Cause”, “Mitigations/Correction” et “Retours d’expérience”
- Enfin, pour chaque action, nous identifions une équipe responsable
Ce rituel public nous permet d’apprendre, en équipe, à partir de chaque incident.
Exemple de la section “Retour d’expérience” d’un de nos post-mortem :

Étape 6. Fermeture et archivage de l'incident
Un incident est clos si :
- Il n’y a plus d’impact pour les utilisateurs. Évidemment !
- Il a été analysé par un groupe d’experts en revue de post-mortem
- Les actions qui sont ressorties de l’analyse ont chacune une équipe responsable.
Toutes les actions de post-mortem sont ensuite suivies et mises à jour dans un unique tableau qui ressemble à ça :
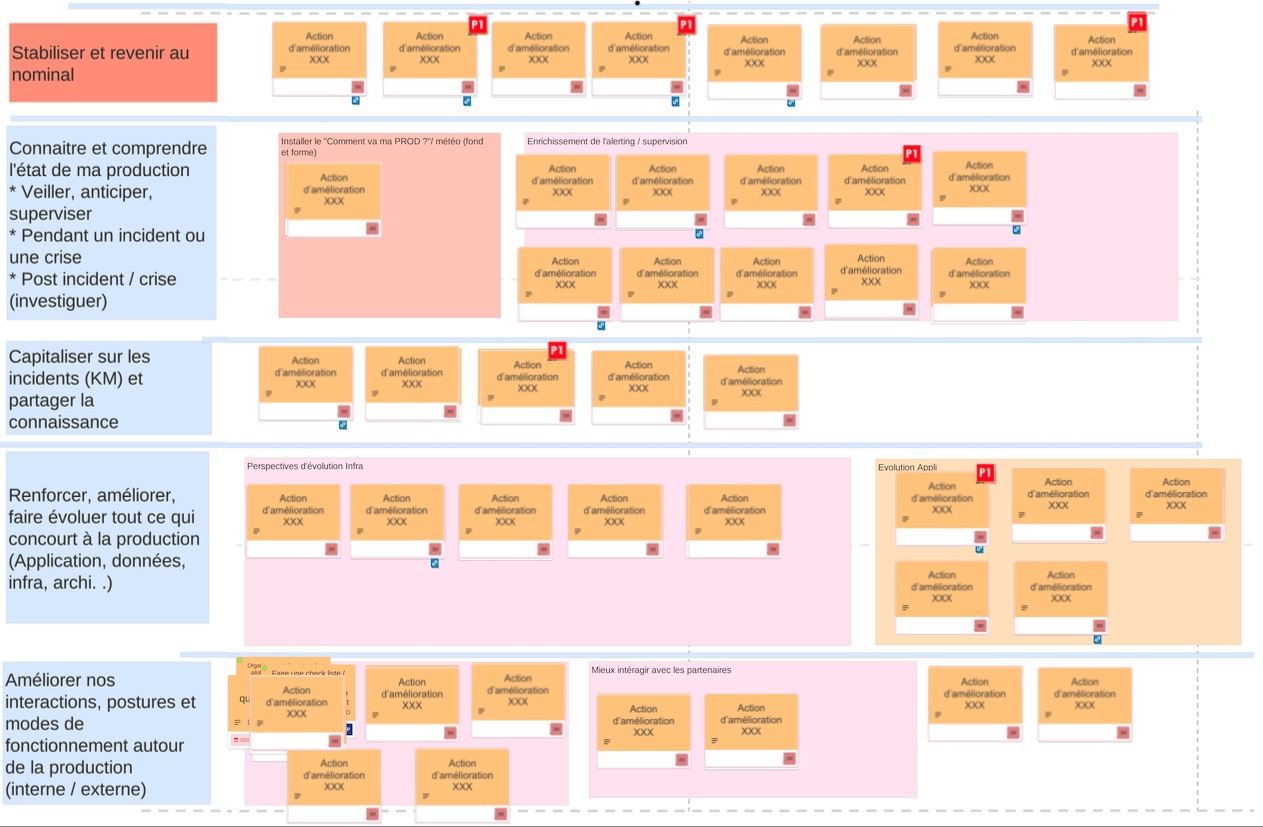
Chaque ticket dans ce tableau est revu régulièrement avec l’équipe responsable. On vérifie si le sujet a été pris en charge, traité, ou abandonné (l’architecture a changé, notre compréhension du problème a évolué, etc.)
Ce management visuel permet de détecter assez rapidement si nous ajoutons plus de tickets que nous en traitons, signe que nous avons un problème de priorisation des tâches d’amélioration dans nos backlogs.
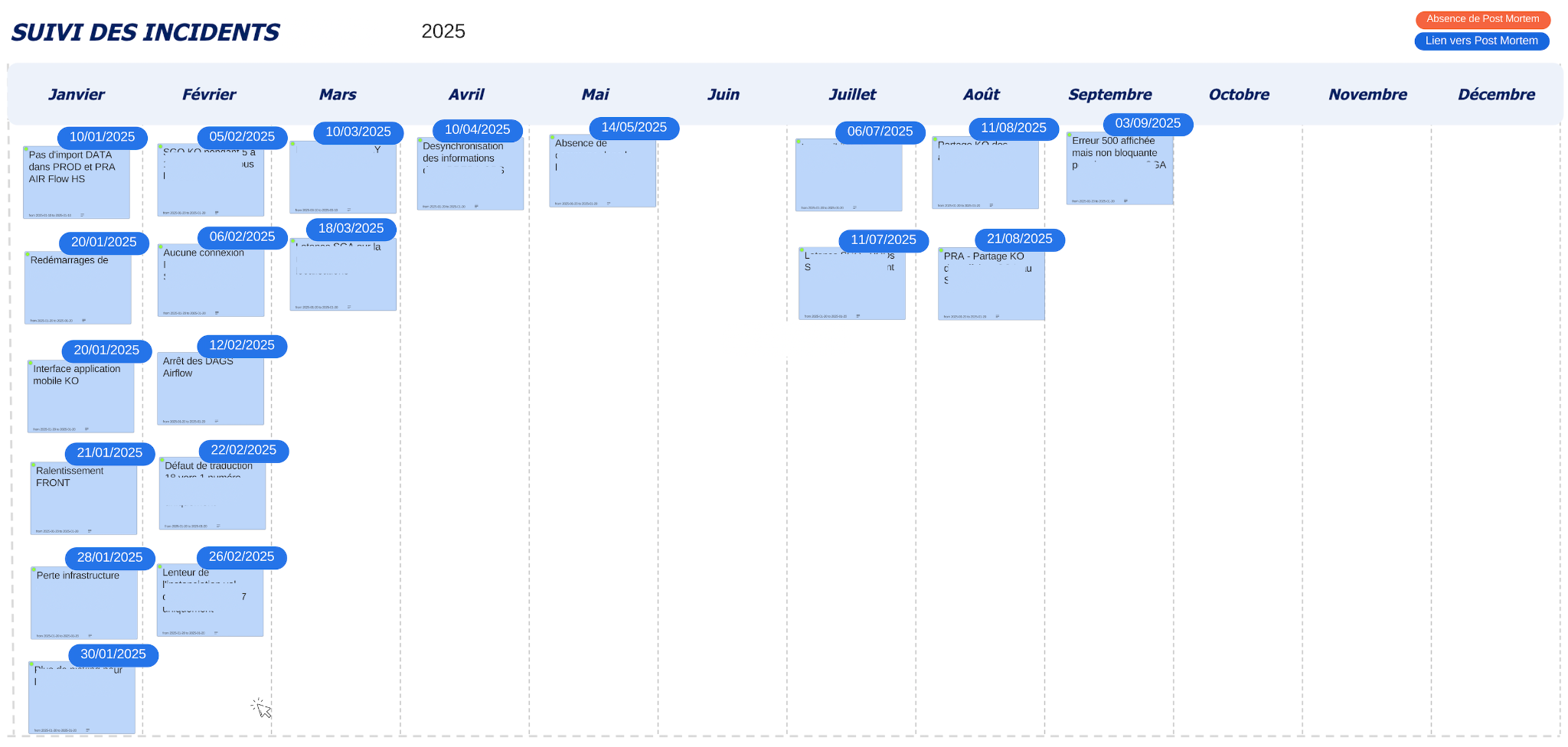
Les documents de post-mortem sont ensuite archivés au format pdf et une timeline des incidents est partagée avec nos utilisateurs. Chaque carte a en lien le pdf du document de post-mortem pour pouvoir revenir sur un incident en particulier.
Observations et enseignements après deux ans de gestion d’incidents
Cette approche de gestion d’incidents a eu des répercussions bien au-delà des incidents eux-mêmes.
Chaque incident réunit des profils variés – dev, ops, data, produit/métier – qui doivent coopérer efficacement. Ces moments de crise développent nos compétences transverses : les dev comprennent mieux l'infrastructure, les ops approfondissent leur compréhension des problématiques applicatives, et l'ensemble de l'équipe progresse en communication et coordination.
Nos rituels de post-mortem sont devenus des temps d’apprentissage, technique et organisationnel, qui enrichissent notre compréhension du système.
Les incidents nourrissent notre amélioration continue : ils alimentent nos backlogs, guident nos choix d’architecture et orientent nos priorités de développement. Ils ne sont plus des accidents de parcours ou des évènements venant gêner notre progression mais nous servent pour guider l'évolution de notre plateforme.
Nous visons l'antifragilité : construire un système – technique et social – qui devient plus fort à chaque panne. Chaque incident nous rend plus robustes, plus réactifs et, paradoxalement, plus sereins.