Une équipe plateforme qui délivre ! - Compte-rendu du talk de François-Xavier VENDE à la Duck Conf 2021
5 réponses à 5 questions qui se sont posées pour une équipe plateforme lors de la création from scratch d’un SI.
Contexte
La création du SI de www.aladin.farm, une plateforme B2B de vente de biens et de services par les coopératives pour les agriculteurs.
François-Xavier est l'ancien lead de l'équipe SRE chargée de la mise en place de la plateforme. Il est maintenant le CTO de la Digital Factory d'Invivo.
Question 1 : comment construire un socle utile pour les développeurs en le faisant émerger progressivement ?
En suivant l'objectif de créer un socle avec du sens :
- Pour servir les développeurs
- Pour servir le fonctionnel
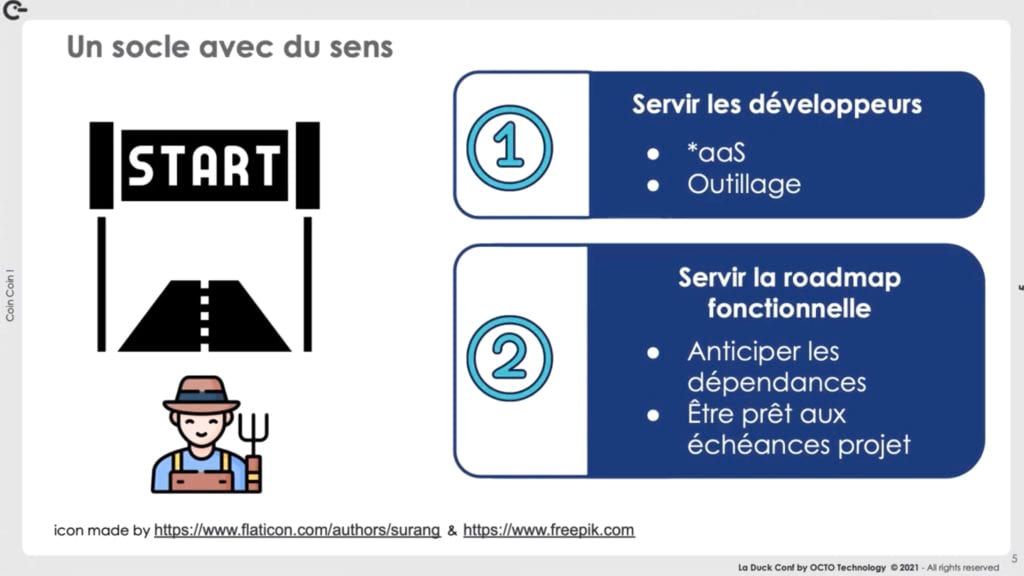
Pour servir les développeurs, l’équipe SRE applique le pattern “as a service” (ex. pour commander un certificat, cela ne se fait pas via un service de ticketing classique, avec beaucoup de perte de temps, mais via un service à la demande qui permet aux développeurs de commander le certificat et de gérer son renouvellement facilement). Un outillage complémentaire pour faciliter la prise en main et l'utilisation du service par les développeurs est par ailleurs fourni (ex. un snippet de code).
Pour servir la roadmap fonctionnelle : l’équipe SRE s'assure que les ressources pour exposer un service (ex. serveur, BDD, etc.) soient toujours disponibles en temps et en heure pour que les développeurs puissent présenter les fonctionnalités.
Pour cela, les dépendances ont dû être anticipées et cela n'a pas toujours été facile (Ex : Azure n'était pas immédiatement disponible au début pour des raisons contractuelles).
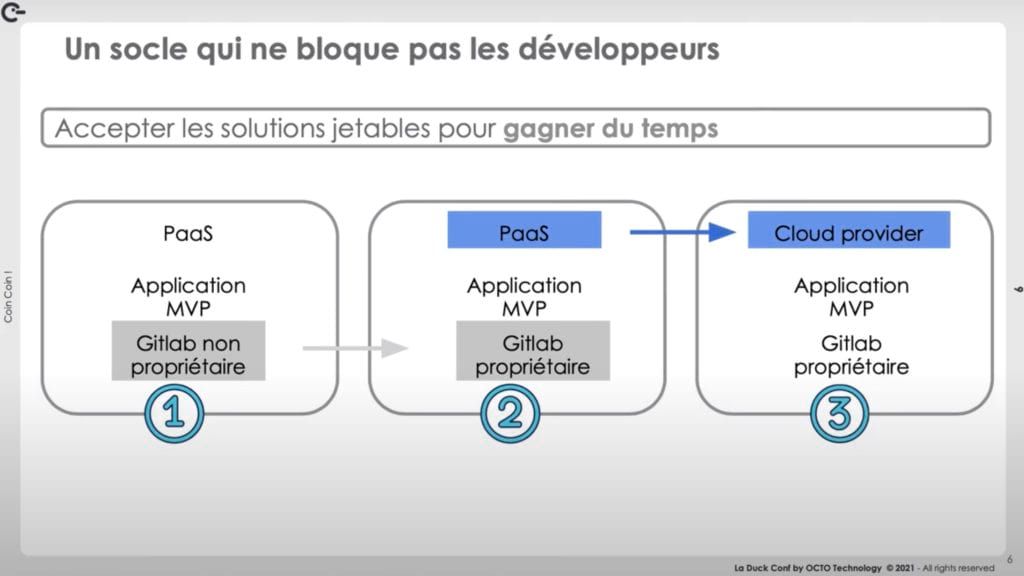
L'équipe a donc accepté de faire du jetable pour ne pas bloquer les développeurs. Dans ce cadre, le Cloud apporte une flexibilité qui permet de faire du “à la demande” pendant un certain temps, sans investissement sur la durée et sans que cela coûte plus cher.
Heroku, une solution PaaS, a été utilisée pour héberger les applications puis progressivement, une migration vers la cible Azure a été faite.
Attention à ce que la solution intermédiaire ne coûte pas plus cher que la solution cible : il faut bien prévoir la trajectoire.
Le parti pris a été de construire progressivement le socle. Par exemple, au démarrage, pas de monitoring exhaustif mais plutôt une solution simple basée sur un outil SaaS (Status Cake) qui ne faisait que pinger les applicatifs pour vérifier leurs disponibilités. Cela suffisait dans un premier temps pour répondre au besoin exprimé par le métier à ce moment-là : un SLO de 99%.
La solution de monitoring a été ensuite enrichie avec des logs, de l'alerting et différentes métriques en fonction des problèmes de production rencontrés, pour pouvoir les investiguer et les résoudre.

Question 2 : Comment réussir à délivrer vite tout en industrialisant ?
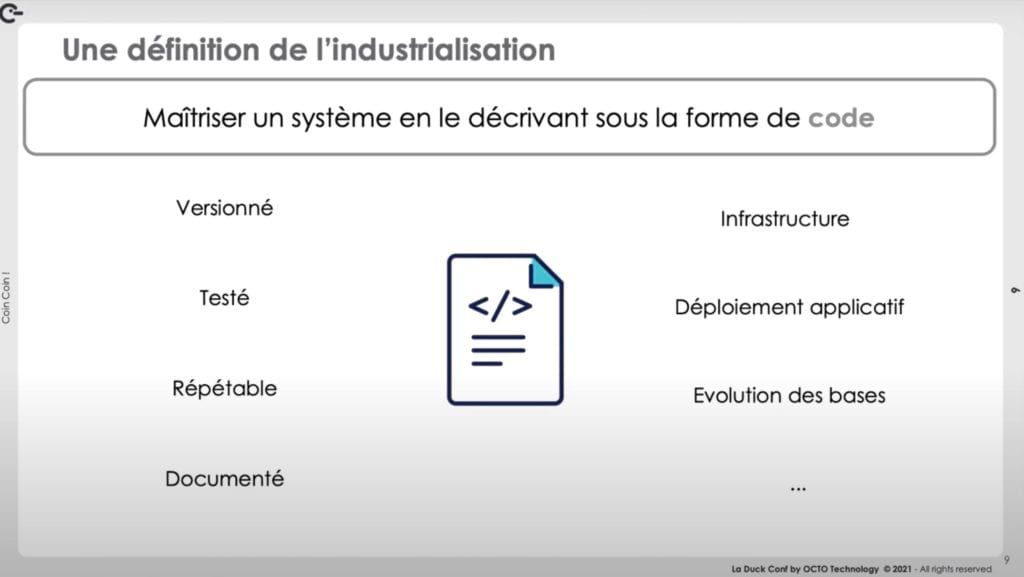
Industrialiser, c'est maîtriser un système en le décrivant sous la forme de code.
Un système, cela signifie tout ce qui est nécessaire pour que le SI soit fonctionnel, à savoir l'infrastructure, l’application, les évolutions de base et les déploiements applicatifs. Cela permet d'être en maîtrise car le code est versionné, documenté, testé et répétable. Le SI est donc reconstructible de 0 si cela est nécessaire.
Le problème de l’industrialisation, c'est que cela prend énormément de temps. Du coup, comment prioriser ce qui est industrialisé ?
Pour cela, il faut réfléchir à la priorisation. L’équipe SRE a opté pour le faire de la même façon que pour prioriser du fonctionnel, en rapprochant le coût à la valeur. Coût : le temps à mettre en œuvre pour l'industrialisation. Valeur : le temps qui est gagné de manière répétitive car l'industrialisation supprime cette tâche.
Ex. :
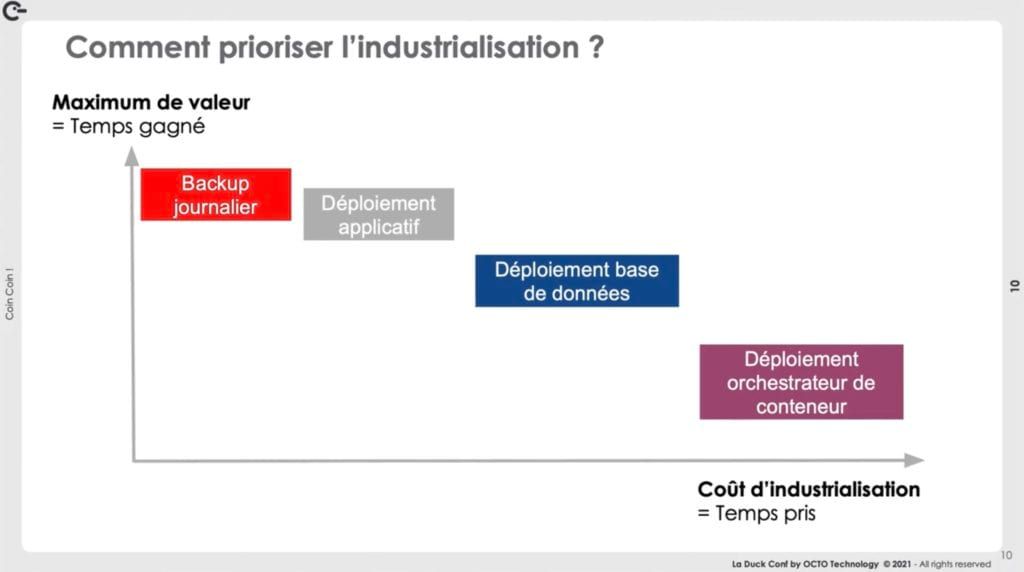
L'orchestrateur a ici un coût élevé. Il est donc acceptable, dans un premier temps, d'utiliser la console du cloud provider en effectuant les actions à la souris. Cela crée de la dette car, même si les actions sont correctement documentées, ce n'est pas réellement fiable : errare humanum est. Seule condition sine qua non : s'accorder avec le métier à priori pour avoir du temps, par la suite, afin de résorber cette dette.
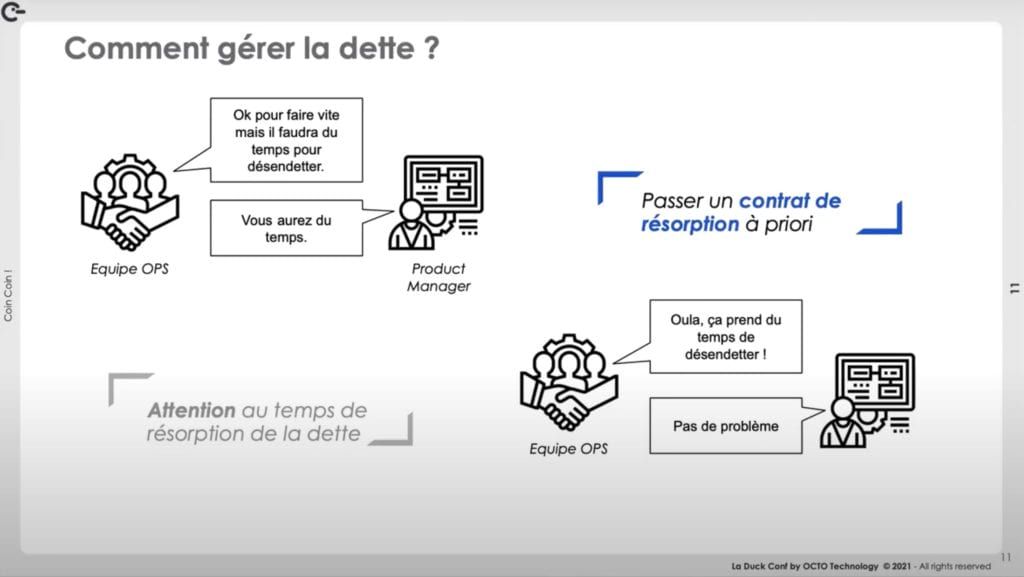
Cela a permis d'accompagner le besoin fonctionnel et par la suite le métier a accepté de donner le temps nécessaire à l'équipe pour la corriger
Question 3 : Comment continuer à délivrer sans être perturbé par la production et ainsi décélérer ?
Pour cela, les applications ont été construites dès le début en pensant au run, avec la mise en place d’un certain nombre d'éléments et de patterns :
- Build once, run everywhere pour avoir un comportement répétable.
- Des éléments de logs, de healthcheck, des métriques, de la sécurité applicative.
Cela a été fait, bien sûr, de façon itérative. Par exemple, le healthcheck du début ne répondait que OK/KO, puis la vérification de connexion à la BDD a été ajoutée, puis la validation d'autres API nécessaires au fonctionnement du service, etc. Conseil : il ne faut pas attendre pour mettre en œuvre ces points, il faut les initier puis les enrichir.
L'autre secret c'est la démultiplication de l'effort du run : ce n'est pas à l'équipe SRE de tout faire, c'est aussi aux équipes de développeurs de s'impliquer dans le run. Pour cela les équipes de développement ont été accompagnées afin de les aider à s'approprier les outils qui sont ouverts et de les responsabiliser sur les tâches à effectuer. Cela a permis de passer de 1 à 7 équipes sans être débordé par les demandes.
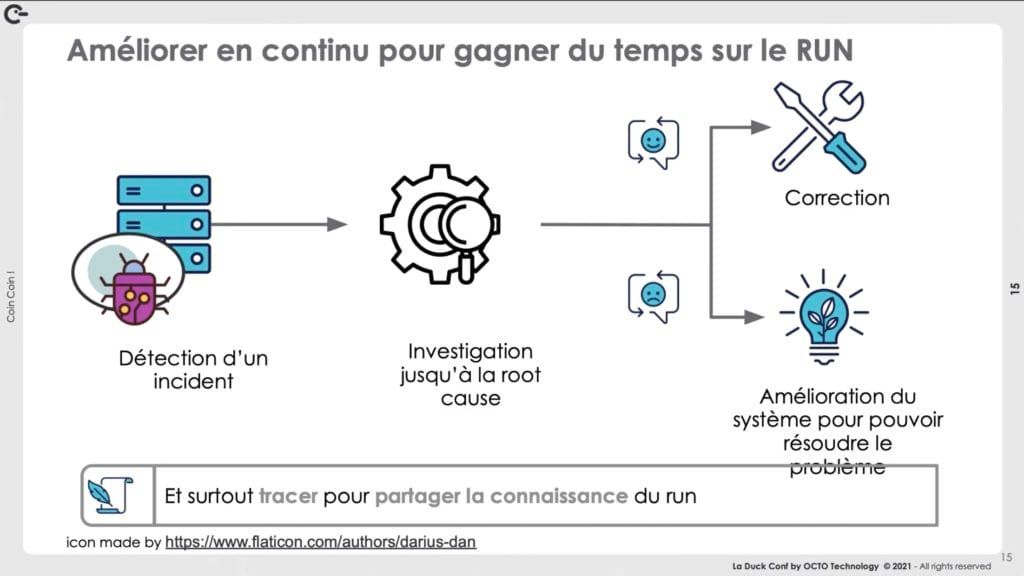
Enfin, il y a forcément des problématiques en production. La posture adoptée a été de ne pas les laisser traîner et de mettre en place une démarche d'amélioration continue sur le run avec, à chaque bug, un processus clairement défini :
- un post-mortem documenté et partagé aux équipes ;
- une démarche qui consiste soit à résoudre la problématique (si la cause est trouvée), soit à mettre en place les éléments qui permettront d'en déterminer la cause la prochaine fois que le problème surviendra.
Question 4 : Comment anticiper les besoins et embarquer dans les choix ?
Pour embarquer les équipes dans les décisions à prendre, une démarche de choix collectif a été mise en œuvre avec un processus appliqué de manière systémique qui consiste à "partir du besoin" et "avoir une matrice de choix" vis-à-vis de ce besoin. Le besoin est collecté en impliquant toutes les parties prenantes (les développeurs, les OPS et les décideurs) :
- pour que les contraintes de run et de déploiement soit prises en compte ;
- pour que les développeurs s'approprient les solutions ;
- pour que les décideurs soient contents d'un point de vue budgétaire.
Par exemple, le choix de la solution d’API Management (Kong) a été fait de cette façon. C'était la solution qui correspondait le mieux au contexte. La démarche a été garante de cette adéquation et de la bonne adoption.
Pour anticiper le besoin, il est important de structurer la roadmap technique par rapport à la roadmap fonctionnelle (les besoins du build) et d'anticiper systématiquement.
Dans la roadmap fonctionnelle, il y a les chantiers fonctionnels mais aussi les chantiers liés aux évolutions de l'organisation (quand on augmente le nombre d'équipes par exemple).
Au-delà du besoin fonctionnel, il y a le besoin du run qui est tiré des exigences du métier (disponibilité, résilience de la plateforme,...)
Question 5 : comment pérenniser les pratiques et les choix qui s'imposent ?
Cette problématique a été adressée en 2 temps : en local au sein de l'équipe SRE puis au global.
En local, elle est traitée sur 4 axes :
Le code et la conception : tout le monde doit être aligné grâce à du travail en mob et en pair programming. Ex : toutes les semaines, des séances de mob au sein de l'équipe SRE permettent de traiter un sujet collectivement : mob programming pour développer sur un sujet compliqué, mob design pour concevoir la solution à une problématique et mob hacking pour résoudre un problème complexe. C’est via ce mob que l’équipe SRE a défini ses pratiques et standards de développement, qui ont été documentés et donc pérennisés avec le collectif.
Le support est toujours réalisé en mode tournant : toutes les personnes de l'équipe sont capables de traiter les demandes de support.
La priorisation orientée par le CTO est effectuée avec et par l'équipe afin que les objectifs soient partagés et que rien ne soit oublié dans les tâches à effectuer.
Le modèle permet de s'assurer du bus factor (si quelqu'un passe sous un bus...) en partageant le plus possible dans l'équipe.
Au global, c'est beaucoup de partage : l'onboarding, le share show (événement ritualisé toutes les 2 semaines pour partager sur un sujet), l'OPS champion comme point de relai dans les équipes.
Le take away en 5 points
- Toujours partir du besoin pour construire quelque chose qui a du sens et répondre aux enjeux.
- Embarquer les équipes dès le cadrage pour faire en sorte que tous les acteurs soient bien alignés et gagner en efficience.
- Accepter les solutions intermédiaires, ne pas bloquer les développements, de façon à toujours être dans une logique de time to market, délivrer de nouvelles fonctionnalités et pouvoir observer si les solutions répondent ou non aux attentes des utilisateurs.
- Sécuriser le run au plus tôt et toujours anticiper pour que le passage en production soit un non-sujet
- Être dans une démarche d'amélioration continue, ne pas viser la cible, commencer petit et progressivement, faire de mieux en mieux pour finalement répondre pleinement aux besoins de manière adéquate.