Mesurer le ressenti des internautes : clé d’un numérique responsable
Dans la série “mesurer pour nous aider à développer des services numériques plus responsables pour l'environnement”, quantifier le ressenti de l'internaute surfant sur les pages d'un portail web est un axe d’amélioration potentiel. Nous allons donc voir ci-dessous quel serait l'intérêt d'une telle méthode, pourquoi, comment et quand mesurer ?
Les experts qui analysent l'impact environnemental du numérique (NEGAOCTET, THE SHIFT PROJECT, GreenIT.fr …) sont unanimes sur le poids prédominant et grandissant que font subir des terminaux sur notre planète. L’un des objectifs de l’éco-conception est alors de limiter le phénomène d’obsolescence perçue en s’assurant que l’attention portée à l’expérience utilisateur soit suffisante afin que cela ne soit pas une tentation supplémentaire pour l’internaute de changer de machines prématurément.
Le but de cet article est donc de questionner la manière d’évaluer côté front-end, le plus objectivement et réaliste possible, le ressenti de l’internaute, c’est-à-dire la qualité de l’expérience utilisateur.
Il est complémentaire à la mesure de l’Ecoindex. Puisque ce besoin avait déjà été identifié, il y a un an, dans l’article « Sous le capot de la mesure Ecoindex ! » dans le chapitre “Attention à la perception de l’internaute lambda” et sa conclusion.
Le plan de l’article est :
Que sont les “(Core) Web Vitals” ?
Exemple de chargement du portail Web
En pratique, comment faire les mesures en direct et simplement ?
Que faire avec cette mesure ?
Automatisation de la mesure
Conclusion sur les (Core) Web Vitals
Attention à ne pas se tromper d’objectif…
Remerciements
Informations pour aller plus loin
Que sont les “(Core) Web Vitals” ?
Les Web Vitals (également connus sous le nom de “Core Web Vitals”) mis en avant par Google peuvent aider à objectiver l'expérience utilisateur d’une page Web et à identifier les possibilités d'amélioration avec des indicateurs chiffrés.
Ce sont 3 indicateurs :
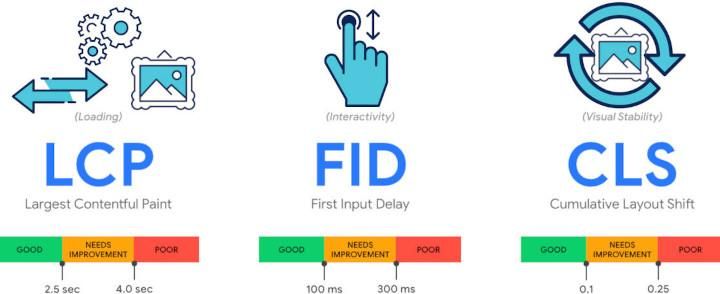
Largest Contentful Paint (LCP) : mesure les performances de chargement. Il mesure les performances de chargement de l'élément le plus visible sur l'écran de l'internaute. Pour offrir une bonne expérience utilisateur, le LCP doit se produire dans les 2,5 secondes qui suivent le début du chargement de la page.
First Input Delay (FID) : mesure l'interactivité. C’est plus précisément le temps avant que le site permette la prise en compte de la première interaction initiée par l'utilisateur. Pour offrir une bonne expérience utilisateur, les pages doivent avoir un délai de première entrée de 100 millisecondes (ms) ou moins.
Cumulative Layout Shift (CLS) : mesure la stabilité visuelle. Pour offrir une bonne expérience utilisateur, les pages doivent avoir un CLS de 0,1 ou moins.
Le calcul du CLS se base sur la taille de la part de l’écran qui s’est déplacé (aussi appelé “fraction d’impact”) et la distance du déplacement du mouvement inattendu (aussi appelé “fraction de distance”) au sein du navigateur pendant le chargement de la page. La formule exacte est : CLS = <Fraction d’impact> * <Fraction de distance> (plus de détails et illustrations ici).
Il faut avoir un score proche de zéro pour être considéré comme bon. Par exemple, nous avons tous été surpris un jour par un décalage désagréable dans une page web dû à l’apparition inopinée d’une image dont la taille n’avait pas été préalablement correctement définie.
Voilà un exemple concret en vidéo de ce genre de désagréments. Dans cet exemple, quelqu'un décide de cliquer sur “No, go back” pour modifier sa commande alors qu’au même moment l’affiche se décale pour insérer un nouvel élément. Ce qui a pour désagréable effet de valider involontairement la commande.
Cet article ne rentrera pas sur tous les détails et subtilités de l'implémentation de ces trois mesures, elles sont décrites notamment sur leur site web.dev (cités dans la section précédente décrivant les trois indicateurs). Certaines autres références complémentaires se trouvent à la fin de cet article dans la section « pour aller plus loin ».
Exemple de chargement du portail Web
Entrons dans le concret avec un exemple de chargement d’un portail Web afin d'illustrer les différentes mesures pour mieux les comprendre.
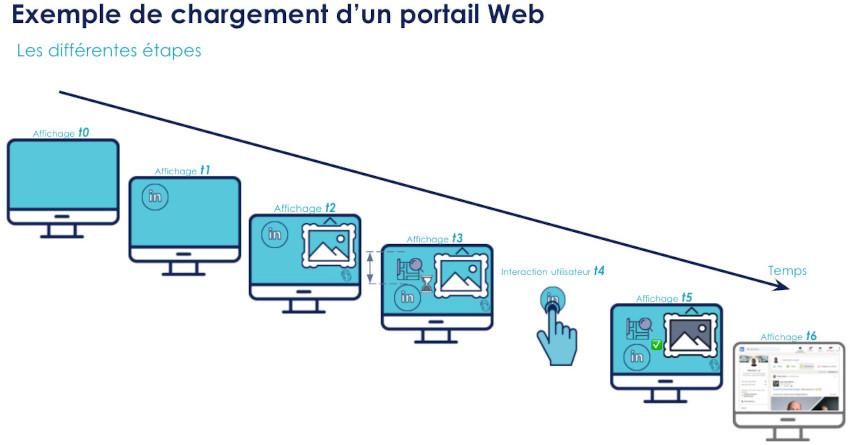
Supposons que :
Au temps t0 : tout début du chargement du portail web.
Puis chargement de différentes requêtes avec les ressources (CSS, JavaScript, images…), sollicitant des analyses et des traitements sur l'activité principale les processus du navigateur internet.
t1 : affichage des premiers éléments avec un bouton LinkedIn. t1 - t0 donne donc la mesure du FCP (First Content Paint).
Puis chargement d’autres éléments…
t2 : chargement du plus grand élément de la page (c'est-à-dire une image de montagne). t2 - t0 donne donc notre LCP (Largest Content Paint)
t3 : imaginons que la suite est l’affiche d’une carte géographique juste au-dessus du bouton LinkedIn sans avoir préalablement défini une hauteur et une largeur et que cela entraîne un décalage dans cette colonne déplaçant vers le bas le bouton LinkedIn. S’il est le décalage le plus significatif, il permettra donc de calculer le CLS (Cumulative Layout Shift).
t4 : supposons maintenant que l'utilisateur essaie de cliquer sur le bouton LinkedIn alors que le processus principal du navigateur internet est déjà occupé (par exemple à traiter un code JavaScript fraîchement chargé), le traitement du clic est donc retardé à plus tard.
t5 : moment où le navigateur respire enfin après avoir presque terminé de traiter cette page dans son ensemble. Cela permet donc de dépiler les tâches en attente de traitement et donc dans notre cas la demande d'affichage de la page Linkedin. Dans ces circonstances l'utilisateur ne verra très certainement pas l'écran de cette étape, mais plutôt le résultat du traitement de cette nouvelle tâche (c'est-à-dire l'affichage de la page LinkedIn).
t6 : fin de l'affichage de la page LinkedIn et donc de l'activité du processus principal du navigateur internet suivi d’une période de faible d'activité (c’est-à-dire permettant à la page de répondre aux interactions de l'utilisateur dans un délai de 50 ms). Nous avons donc la mesure du TTI (Time to Interactive). Dans notre cas TTI = t6-t0.
t7 : reprise de l'activité avec du processus principal du navigateur internet par une autre tâche (de plus de 50 ms).
En pratique, comment faire les mesures en direct et simplement ?
Avec les navigateurs internet basés sur Chromium (Google Chrome ou Brave), les DevTools permettent d’afficher en direct une fenêtre en haut à droite du navigateur.

Voici les étapes pour afficher cette fenêtre
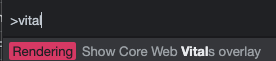
Activez la fenêtre des DevTools Chromium en appuyant, par exemple, sur <F12>
Appuyer sur <Ctrl> (ou <⌘> sur Mac) + <Shift> + <p>
puis taper “vitals” (les trois premières lettres devraient suffire)
puis cliquez sur « Show Core Vitals overlay »
- Afin d‘avoir des mesures reproductibles et stables, Il est souvent préférable de choisir un type de réseau qui reflète utilisateur lambda. Pour cela, allez dans l’onglet <Network>, activez <Disable cache> et spécifiez une vitesse connexion (<3G Fast> par exemple, ou plus lent suivant l’usage moyen pressenti du service numérique)
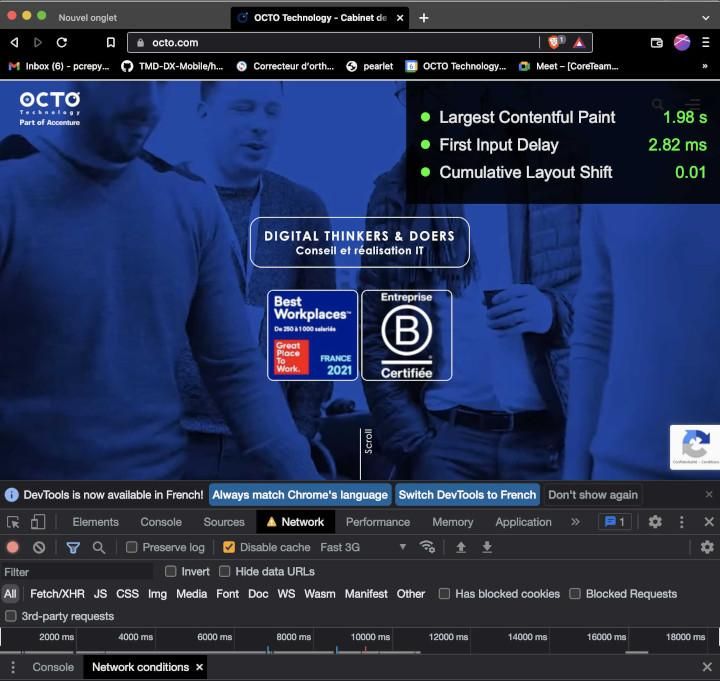
Suivant les cas, il sera peut-être nécessaire de cliquer sur le portail, afin d'avoir le FID (First Input Delay).
Il est toutefois préférable d’utiliser un profil vierge dédié à la mesure. Si vous n'en avez pas, il est conseillé d’en créer un à cet effet.
Que faire avec cette mesure ?
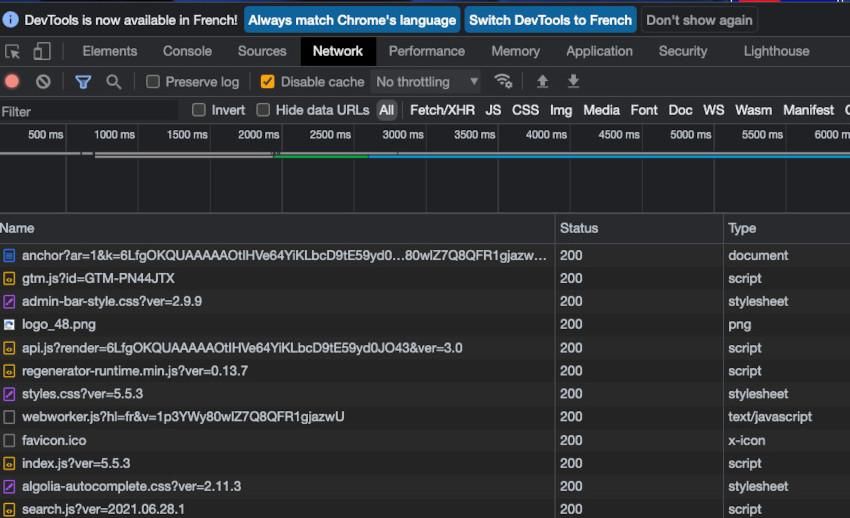
De manière générale, les conseils d’audit Lighthouse peuvent bien aider à trouver des pistes d’améliorations si nécessaire. Si les indicateurs Largest Contentful Paint (LCP) ou First Input Delay (FID) ne sont pas corrects, il est souvent bien utile de passer du temps dans les outils de développement “Network”. Il est disponible sur Mozilla / Moniteur Réseau ou sur Inspect Network Activity In Chrome DevTools.
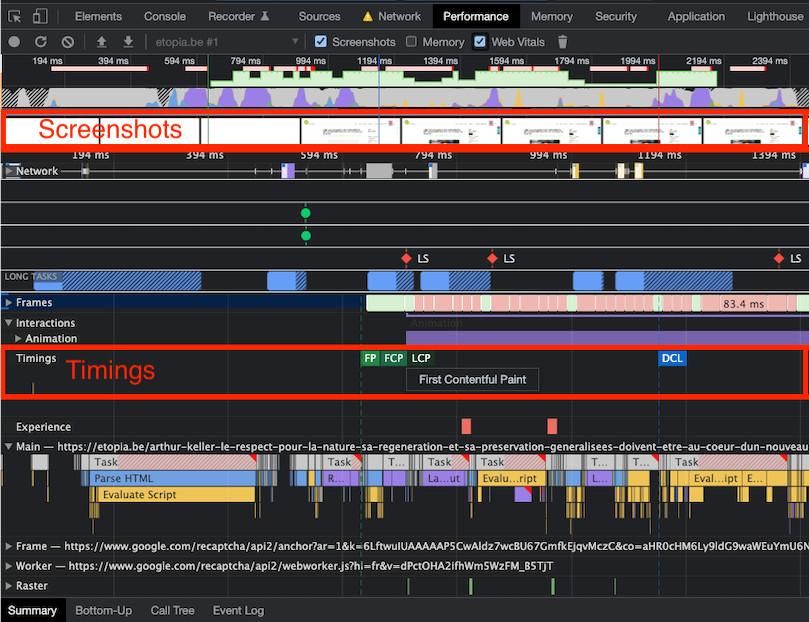
Le FID peut être anormalement allongé dans le cas où le navigateur Internet est trop occupé à analyser et à exécuter de grosses quantités de JavaScript. Dans ce cas, le traitement du JavaScript peut monopoliser trop de ressources (d’autant plus sur des terminaux vieillissants, non mis à jour, ou avec des ressources limitées !), il ne peut donc rien faire d’autre durant cette période. Les longs FID se produisent généralement entre First Contentful Paint (FCP) et Time To Interactive (TTI), car la page affiche une partie de son contenu, mais n'est pas encore interactive durablement. Un exemple typique est un problème de développement avec des fonctions synchrones bloquantes niveau JavaScript. Si le Cumulative Layout Shift (CLS) pose un problème. Une façon de tester est de ralentir la connexion, par exemple en “3G Fast” (voire plus lent), puis de recharger la page (en “dézoomant” au besoin le rendu de la page pour en avoir une vue globale). Une analyse plus détaillée peut être effectuée avec les devTools. En effet, les informations (encadrées en rouge dans l’image ci-dessous) de “Screenshots” et les “Timings” de Chrome DevTools / Performance features reference sont utiles :
Automatisation de la mesure
À l'exception du First Input Delay (FID) les deux autres mesures peuvent être obtenues directement de manière automatique, par exemple au travers de l'outil Lighthouse (via en version CLI - C'est-à-dire ligne de commande - afin d'être intégré dans une usine de développement).
En effet le FID ne peut pas être simulé dans un environnement de test classique car il nécessite une réelle interaction avec l’utilisateur pour mesurer le délai de réponse.
Une astuce, souvent utilisée dans ce cas, consiste à mesurer le Total Blocking Time (TBT). Certes ce n’est pas pareil, mais généralement, une amélioration du TBT contribue à optimiser le FID. Voyons pourquoi et dans quelle mesure.
Le Total Blocking Time (TBT) est la mesure du temps de blocage total. C'est-à-dire le temps total entre le First Contentful Paint (FCP) et le Time to Interactive (TTI) pendant lequel le processus principal du navigateur internet a été bloqué suffisamment longtemps pour empêcher la réactivité des entrées.
Ce processus / thread principal est considéré comme "bloqué" chaque fois qu'il y a une tâche longue - une tâche qui s'exécute sur le thread principal pendant plus de 50 ms. Nous disons que le fil principal est "bloqué" parce que le navigateur ne peut pas interrompre une tâche en cours. Ainsi, si un utilisateur tente d’interagir avec la page au milieu d'une longue tâche, le navigateur doit attendre que la tâche se termine avant de pouvoir répondre.
Si la tâche est suffisamment longue (plus de 50 ms, par exemple), il est probable que l'utilisateur remarquera le retard et percevra la page comme étant lente ou problématique.
Le temps de blocage d'une longue tâche donnée est sa durée au-delà de 50 ms. Et le temps de blocage total d'une page est la somme du temps de blocage de chaque tâche longue qui se produit entre le FCP et le TTI.
Reprenons l’exemple précédent et calculons-en le TBT. Il s'agit de calculer l’ensemble des tâches du thread principal d’une durée supérieure à 50 ms entre t1 (notre First Contentful Paint - FCP) et t6 (notre Time to Interactive - TTI) :
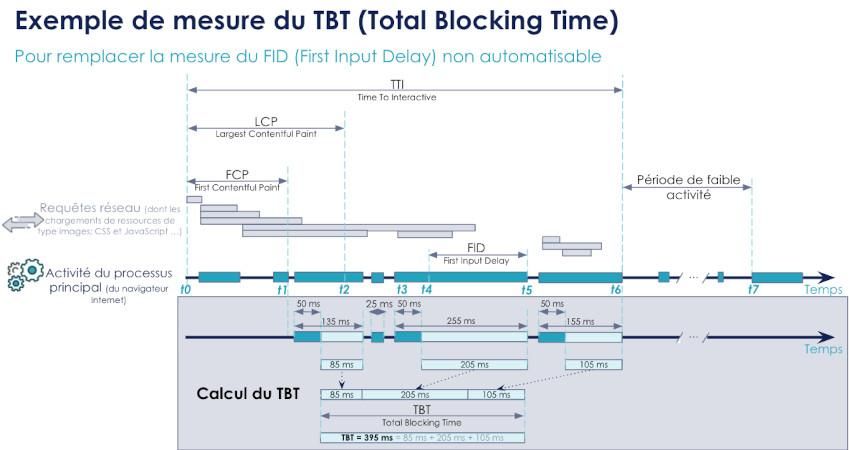
Sur ce schéma “chronogramme,” seul le cadre gris intitulé “Calcul du TBT” est nouveau. (Le reste est une copie du chronogramme précédent.)
Dans notre cas, nous avons donc bien un TBT englobant notre FID. Ceci est d'autant plus vrai que durant une mesure automatique il n’y aura pas d'intervention utilisateur et donc ici le TBT aurait été plus rapide de 105 ms puisque la tâche qui se termine en t6 n'existera pas (elle est induite par l’appui sur le bouton LinkedIn).
Chercher à diminuer le TBT revient donc à réduire les temps de blocage trop longs du processus principal et donc devrait aller dans le sens d’une diminution du FID et donc d’améliorer l'interactivité de la page.
En pratique, comme écrit sur web.dev/tbt/#what-is-a-good-tbt-score : ”Pour offrir une bonne expérience utilisateur, les sites doivent s'efforcer d'avoir un temps de blocage total inférieur à 200 ms lorsqu'ils sont testés sur un matériel moyen”.
Profitons ici pour rappeler que les mesures varient en fonction du type et des performances de la machine et du réseau. Il convient donc de faire bien attention à ces paramètres lorsque l'on fera ces mesures (automatique dans l'usine de développement notamment).
Nous avons les moyens de suivre l'évolution de manière continue au sein d'une usine développement pour contrôler l'évolution de ces scores tout au long des jalons d'un projet d'un service numérique.
Le sujet de l'automatisation de la mesure et un gros sujet à part entière sur lesquels nous travaillons déjà, il se peut que cela fasse l'objet d'autres articles de blog…
Au-delà des usines de développement (CI/CD), notons qu’il y existe le Chrome User Experience Report (CrUX) qui est un ensemble de données public contenant des données de performances réelles sur l'expérience utilisateur Chrome.
Conclusion sur les (Core) Web Vitals
Nous avons bien de quoi objectiver le ressenti d’un internaute.
Il ne reste plus qu’à y porter attention, et à suivre ces 3 valeurs, que cela soit de manière instantanée au cours d’une session de développement et/ou automatiquement via une usine de développement au moment de chaque démonstration à la fin de Sprint.
Le TBT peut remplacer le FID dans une usine de développement. Le FID sera réservé à la mesure en direct durant les nouveaux développements par exemple.
À rebours pour un audit d’un portail déjà existant ces 2 mesures couplées se sont déjà révélées bien utiles pour orienter nos recherches et trouver des “quick wins”.
En effet, c'est un bon complément à Ecoindex, puisque cette mesure prend en compte également les architectures logicielles utilisant du JavaScript notamment dans le cadre des Single Page Application.
Voici par exemple ce que l'on peut faire autour de l'analyse d'un parcours utilisateur (l'unité fonctionnelle) ici composé de 4 URLs.
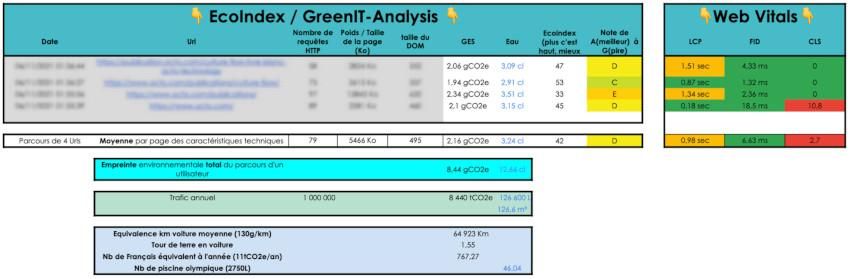
Du côté de l'Ecoindex et des mesures Web Vitals, nous pouvons calculer les moyennes. Dans l’exemple ci-dessus, on observe que le ressenti de l’internaute est perfectible sur le chargement des pages et n’est pas acceptable au sujet de la stabilité de la quatrième page.
Pour finir, voici un graphique issu du http archive.org / Core Web Vitals / Technology Report. Il montre le pourcentage de portail avec un “bon score Core Web Vitals” suivant les technologies utilisées. Attention cependant à ce que ces chiffres disent et ne disent pas, mais ce n'est pas l'objet de cet article :
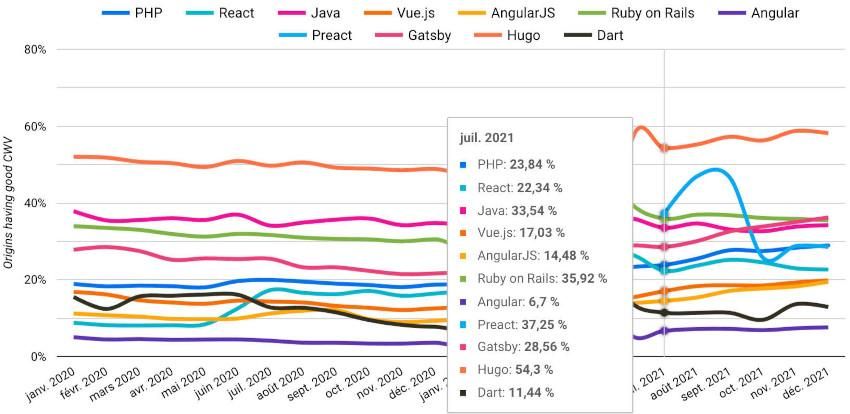
De manière globale, on peut tout de même remarquer que les scores perfectibles des (Core) Web Vitals laissent une belle marge de progression. Nous avons donc collectivement encore du pain sur la planche pour aider les internautes à conserver leurs terminaux (ordinateurs et smartphones) plus longtemps. Le but des concepteurs responsables étant d’éviter la tentation de l’obsolescence perçue qui s’exprime parfois par « ma machine rame, je vais donc en acheter une nouvelle… »
Attention à ne pas se tromper d’objectif…
En guise de réflexion sur ce fléau moderne nommé inflagiciel, citons deux sommités en informatique qu’il est bon de se rappeler quand on pense à développer un service numérique quel qu’il soit :
- Frederick Brooks qui a introduit en 1962 au sein d’IBM la notion d'architecture informatique en le définissant comme suit : "L'architecture informatique, comme toute autre architecture, est l'art de déterminer les besoins de l'utilisateur d'une structure, puis de la concevoir pour répondre à ces besoins aussi efficacement que possible dans le cadre de contraintes économiques et technologiques.”
L’essentiel est bien là. 60 ans plus tard nous pourrions ajouter contraintes environnementales et acceptabilité sociale !
- et A Plea for Lean Software Feb-1995 qui explique dans le paragraphe « Causes for "fat software" » que : "La pression du temps est probablement la principale raison de l'émergence des logiciels volumineux…". Ce qui l’a amené à la loi (empirique) de Wirth : “Les programmes ralentissent plus vite que le matériel n’accélère”.
Autrement dit aujourd’hui et bien au-delà des mesures de performance, le but n’est pas de simplement optimiser pour pouvoir en faire plus, mais bien de prendre le temps de réfléchir dès le début lors de l’expression des besoins utilisateurs et de la phase de conception afin de s’assurer de ne surtout pas développer des fonctionnalités et services n'étant pas vraiment utiles à l'utilisateur final… Le but premier étant de judicieusement mieux développer moins de choses pour avoir au final à utiliser le moins possible de machines nécessitant le moins de ressources pour répondre uniquement à l’essentiel des besoins des utilisateurs finaux. Tout cela pour préserver les ressources limitées et critiques que sont nos joujoux électroniques modernes (dont le prix ne reflète d’ailleurs souvent pas vraiment la réalité écologique).
Informations pour aller plus loin
Autres articles autour des (Core) Web Vitals :
fasterize.com / Core Web Vitals Google : qu’est-ce que le Largest Contentful Paint (LCP)
fasterize.com / Core Web Vitals Google : qu’est-ce que le First Input Delay (FID)
fasterize.com / Core Web Vitals Google : qu’est-ce que le Cumulative Layout Shift (CLS)
fasterize.com / Qu’est-ce que le Time To Interactive et comment l’améliorer
codeur.com / Core Web Vitals : Comment améliorer le First Input Delay ?
codeur.com / 7 outils Google pour mesurer les Web Vitals de votre site
eficiens.com / C’est quoi Signaux Web essentiels / Core Web Vitals ? Nos experts en parlent
Autres informations :
Video de 15 minutes / Event loop et asynchronisme en JavaScript (Benjamin Cavy)
Blog OCTO / Analyser les performances de rendu de son interface avec du profiling
Les formations sur le numérique responsable d’OCTO Technology