Une architecture d'application Flex maintenable
Le framework Flex permet d'écrire très rapidement des IHM fonctionnelles, notamment grâce au langage MXML. Celui-ci permet effectivement de décrire l'interface avec peu de lignes de code.
Seulement, voilà, une fois l'étape du POC passée, les fichiers MXML s'accumulent, le code ActionScript s'insinue petit à petit dans le code MXML pour implémenter les handlers d'événements, les appels de services, la logique métier. Après quelques temps, il devient de plus en plus difficile de savoir d'où viennent les données affichées (ie. quel code a mis à jour la donnée ?), d'où provient un appel de service (surtout d'où proviennent les valeurs des arguments de cet appel).
Dans cet article, nous verrons quelques bonnes pratiques permettant d'assurer la maintenabilité d'une application Flex.
Séparation des responsabilités
La première étape consiste à séparer les responsabilités du code de l'application. En effet, lorsqu'une même méthode doit collecter les données (ex : dans un formulaire), les préparer pour l'appel d'un service distant, appeler le service et mettre à jour la vue, il devient difficile de la tester ou de retrouver l'origine d'un bug.
Commençons par le modèle de données qui gagnera à se retrouver dans des classes séparées. En effet, il sera alors plus facile d'identifier les données à mettre à jour. Par exemple, lorsque le résultat d'un appel de service arrive, les données reçues seront placée dans ce modèle. Plus besoin de se poser la question de savoir si toutes les données ont été mises à jour, elles sont uniques et regroupées dans ces classes de modèle. On créera, par exemple, un modèle par vue (au sens fonctionnel de l'application).
Ensuite, les appels de services méritent eux aussi d'être encapsulés dans des classes dédiées afin de ne pas écrire 3 fois le même code technique et de les écrire de 3 façons différentes. Il deviendra alors simple d'ajouter des fonctionnalités communes aux appels de services (ex : authentification, gestion des exceptions, ...) et de les remplacer par des mocks dans les tests.
On retrouve ainsi quelques-unes des recommandations du pattern MVC et de ses cousins (MVVM, MVP, ...), c'est toujours bon de se les remémorer de temps à autre. En Flex, il existe un certain nombre de frameworks comme Cairngorm, PureMVC ou encore Mate (et bien d'autres) qui vous permettront de mettre en place cette séparation des responsabilités et ainsi d'améliorer la maintenabilité (en même temps que la testabilité) de votre application. Il ne faut cependant pas obligatoirement sélectionner l'un de ces frameworks tant que quelques règles d'organisation du code ont été définies et partagées par tous les développeurs du projet. Ces frameworks ne sont qu'un moyen d'appliquer ces règles.
Circulation des données
La seconde étape consiste à définir "un sens de circulation" des données dans l'application afin de faciliter le debuggage de celle-ci (ie. mieux comprendre d'où viennent les données et où vont les données) et de favoriser la réutilisation et testabilité des composants Flex écrits.
La partie "vue" d'une application Flex se définie par un arbre de composants (MXML et ActionScript) :
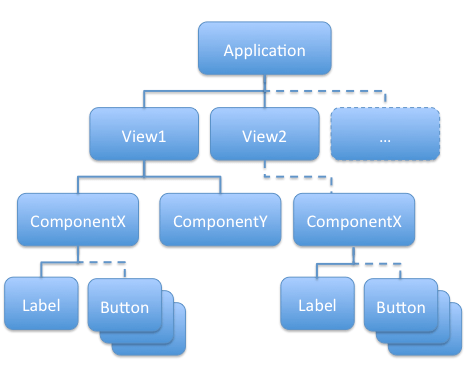
Les nœuds de l'arbre étant des composants conteneurs (*Box, Canvas, List, ...) contenant d'autres composants plus primitifs (Label, Button, ...) ou d'autres conteneurs. Avec une séparation entre le modèle et les appels de services et la vue, il reste que n'importe quel composant peut se binder sur le modèle de données et peut effectuer un appel de service. Ce composant n'est alors plus réutilisable dans un autre contexte : il dépend des données sur lesquelles il est bindé et ne peut plus être utilisé pour en afficher d'autres. Pour lever cette limite, il faut que les données sur lesquelles il se binde lui soit injectées. De même pour les appels de services, pour que le composant puisse être utilisé dans un autre contexte (qui nécessite l'appel d'un autre service ou qui ne nécessiterait pas d'appel du tout), il faut supprimer la dépendance vers cet appel de service (ie. le composant ne devrait même pas "savoir" qu'un appel est effectué lorsqu'un événement intervient).
La solution à ces 2 problèmes de dépendance est de repousser le problème au composant parent :). Ce composant parent pourra alors, soit déporter à nouveau le problème à son parent (en ajoutant des informations au passage si besoin), soit être lui-même dépendant du modèle et du service. En fait, à partir d'un certain seuil dans la hiérarchie de composants (en la remontant), il n'est plus vraiment envisageable de parler réutilisation (cela peut être le composant racine) et avoir des dépendances n'est plus vraiment problématique.
On obtient alors une circulation des données qui ressemble à ceci :
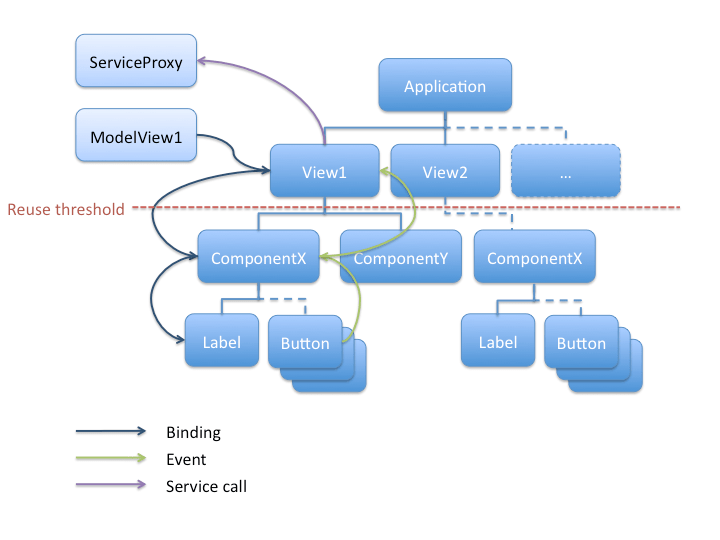
Les données redescendent la hiérarchie via le binding (ie. un composant binde ses attributs aux attributs des composants qu'il contient) :
Dans View1.mxml :
<Componentx title="{modelView1.viewTitle}" />
Dans ComponentX.mxml :
<mx:Label text="{title}" />
Et elles remontent par l'intermédiaire d'événements envoyés par les composants les plus bas dans la hiérarchie. Ces événements sont retransmis (avec du code ou avec la fonctionnalité de bubbling qui leur permet de remonter automatiquement la hiérarchie de composants) ou transformés en événement de plus haut niveau par le composant parent.
Dans ComponentX.mxml :
<mx:Button click="dispatchEvent(new AddItemEvent(this.item))" />
Dans View1.mxml :
<Componentx addItem="serviceProxy.addItem(event.item)" />
Ce mode de fonctionnement revient en fait à définir une API claire des composants développés :
- Les attributs exposés reçoivent les données en entrée
- Les données ressortent via les événements envoyés par le composant
Au passage cela facilite ainsi la testabilité du composant.
Conclusion
Une fois ces 2 principes appliqués sur une application Flex, celle-ci devrait mieux résister à l'augmentation de la quantité de code et rester maintenable plus longtemps. Il faut cependant garder à l'esprit que ces principes ne seront probablement pas suffisant et de nouveaux devront être imaginés s'adaptant au contexte de chaque projet afin de favoriser la lecture du code de l'application dans sa globalité.