[MLOps] Une alternative au monitoring de distributions
Lorsque l’on s'apprête à mettre (ou lorsque l’on a mis) un système de data science en production, on souhaite s’assurer qu’il fonctionne comme prévu. Pour cela, il convient de monitorer ce système intelligent.
On peut s’intéresser à des problématiques opérationnelles classiques, telles que la consommation des ressources du système, mais aussi au bon fonctionnement d’un point de vue de la data science.
Pour adresser ce dernier point, la solution vers laquelle on tend généralement est le monitoring de diverses distributions calculées à partir des données en entrée du système, des données de sortie et des résultats intermédiaires.
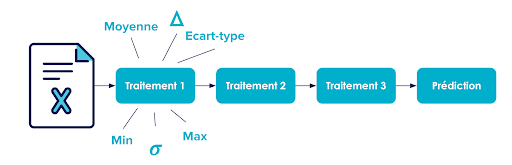
Prenons pour exemple la figure 1, qui illustre un pipeline de traitement classique sur des lignes de données lues dans un fichier. On pourrait calculer et suivre des métriques pour mesurer l'état de ce pipeline telles que:
- le delta entre le nombre de lignes traitées avec succès en sortie du traitement 1 par rapport aux nombres de lignes en entrée, pour savoir s'il y a des lignes traitées en erreur,
- la valeur moyenne de la variable X1 en entrée du traitement 1, par anticipation que des anomalies ne surviennent à cette étape à cause de la qualité de la donnée,
- la valeur moyenne de la variable X1 en sortie du traitement 1,
- d'autres statistiques descriptives potentiellement intéressantes (variances, écart-types, minimum, maximum, ...) en entrée et en sortie du traitement 1,
- Et enfin, pourquoi ne pas calculer ces mêmes mesures pour chaque traitement ?
Cette approche nous amène à calculer de nombreuses métriques, que l'on voudra visualiser dans autant de graphes qui viennent alors peupler des dashboards peu lisibles: la multiplicité des indicateurs, tel du bruit dans un signal, nous empêche de savoir si le système fonctionne comme prévu.
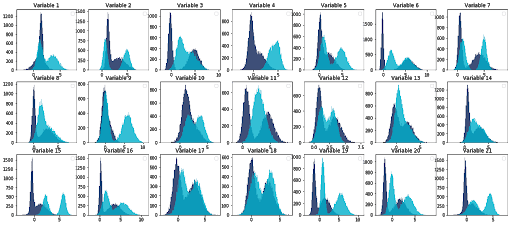
Convaincus que le suivi de distributions à tout va n’est pas la bonne stratégie de monitoring d’un système intelligent, nous avons construit une méthode pour identifier les métriques vraiment utiles à monitorer.
Cet article propose une description de cette méthode, et l’illustre avec un exemple fil rouge.
Un exemple fil rouge
Pour illustrer cet article, nous allons prendre l’exemple de la prédiction de crises d’épilepsie. Les crises d’épilepsie sont très handicapantes notamment car un patient ne sait pas quand elles vont arriver. Savoir quand aura lieu la prochaine crise permet aux patients de prévoir et réaliser des activités qu’ils n’auraient pas pu faire sereinement comme conduire, par exemple.
Pour parvenir à cette prédiction, le patient porte un certain nombre de capteurs sur lui qui permettent l’acquisition de son rythme cardiaque, sa respiration, son activité dermale (sudation, …). L’objectif est de lui fournir des alertes sur son téléphone lorsqu’une crise est imminente.
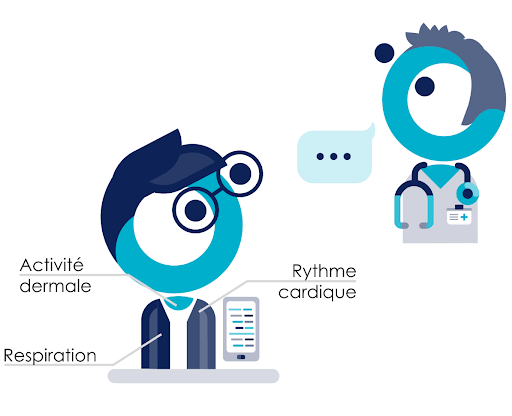
L’anticipation de motifs récurrents dans une série temporelle (dans ce cas les crises d'épilepsies) est une tâche classique dans le domaine de la data science. Pour ce projet, nous avons mis un place système embarquant un modèle de deep learning. C’est donc un système de data science (que nous appellerons aussi système intelligent par la suite).
Ce système étant en production, nous souhaitons nous assurer de son bon fonctionnement au fil du temps. En particulier, nous voulons nous assurer de la pertinence des prédictions faites par le système. Comme nous pouvons obtenir la vérité (crise ou non) que lorsque le patient va voir son médecin, nous souhaitons mettre en place des boucles de feedback plus rapides.
NDLR : Lorsque l’on parle de système de data science, on parle bien entendu du modèle, mais aussi de tout le pipeline. Il ne s’agit donc pas de surveiller uniquement une AUC ou une précision, mais le comportement du système intelligent dans sa globalité : ingestion de données, traitements divers sur la donnée, inférence, applications de règles métier aux prédictions, etc.
Étape 1 : Tracer le pipeline
La première étape de cette méthode est d’identifier les grandes étapes du pipeline de traitement.
NDLR : Toutes les étapes ne sont pas forcément automatisées.
Sur notre exemple fil rouge, le pipeline est représenté sur la figure 4.
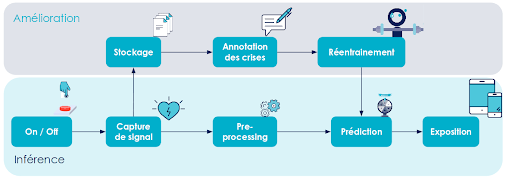
Lorsque le patient se réveille le matin,
- Il s’équipe de ses capteurs et allume le système (le On / Off),
- Le signal est capté et remonté vers son smartphone (la capture de signal),
- Un preprocessing nettoie les données,
- Une prédiction est réalisée,
- Une alerte est faite sur son téléphone en cas de crise imminente (l’exposition).
En parallèle, il y a une boucle de réentraînement pour améliorer les performances du modèle de machine learning :
- Les signaux captés sont stockés.
- Les crises passées sont annotées (par le patient, par son entourage ou par le personnel médical).
- De nouveaux modèles candidats sont entraînés et évalués.
- Lorsqu’un modèle est jugé pertinent, il est alors déployé en production à la place du modèle existant, moins performant.
Étape 2 : Identifier le non-déterminisme
Dans notre pipeline, il y a des comportements déterministes et des comportements non-déterministes. Le déterminisme s’entend ici par un comportement maîtrisé par le système (c-à-d : étant donné une situation, le résultat d’un traitement déterministe est anticipable).
La deuxième étape de la méthode que nous proposons consiste à identifier les sources de non-déterminisme dans le pipeline.
NDLR : En appliquant plusieurs fois cette méthode, nous nous sommes rendu compte qu’il n’y en a généralement pas beaucoup.
En appliquant cela à notre exemple fil rouge, on identifie 4 sources de non-déterminisme.
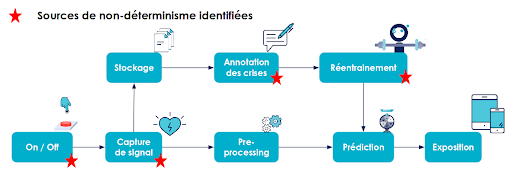
Figure 5 : Notre pipeline avec les étapes non-déterministes, apposées d’une étoile
Le On / Off est non déterministe, car il est à la main du patient. Comme cette opération n’est pas automatisée, rien ne garantit que le patient va le faire.
La prise de signal est non déterministe car elle dépend des constantes du patient, du bruit environnant, de la bonne position des capteurs...
L’annotation est non déterministe, car les patients peuvent rencontrer des problèmes d’amnésie suite aux crises et ne s’en souviennent pas toujours. L’entourage et les médecins peuvent aider à les annoter.
Le réentraînement est non déterministe, car il y a une dimension aléatoire dans l’apprentissage en machine learning.
Étape 3 : Concevoir des sondes
Maintenant que l’on a identifié ce qui pourrait causer des comportements inattendus de la part de notre système, il convient désormais d’identifier des propriétés attendues et les sondes associées pour les vérifier.
Une propriété est un comportement attendu du système ou des données ingérées en entrée de celui-ci. Par exemple : sur le signal cardiaque, je m’attends à mesurer des valeurs supérieures à 50. Ces propriétés doivent être déterminées avec des experts. Sur notre exemple, nous pouvons nous tourner vers des médecins et des patients.
Une sonde est un capteur qui permettra de vérifier que la propriété est respectée.
Sur notre exemple fil rouge, nous avons identifié les propriétés suivantes :
Au niveau du On / Off :
- Propriété attendue : Le patient nous a indiqué qu’il portera le système de 7h15 à 22h30 tous les jours.
- Sonde : Compteur de période où le système est allumé.
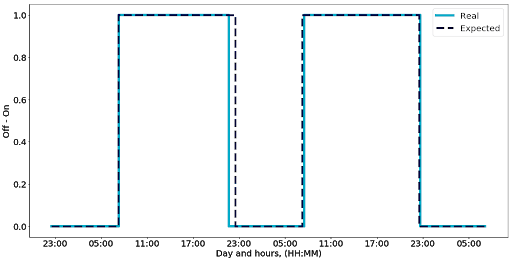
Figure 6 : Monitoring du temps de fonctionnement du système
Au moment de la prise de signal :
- Propriété attendue : Le capteur de rythme cardiaque doit donner une valeur entre 50 et 180 battements par minutes.
- Sonde : Rythme cardiaque moyen par fenêtre glissante de 60 secondes.
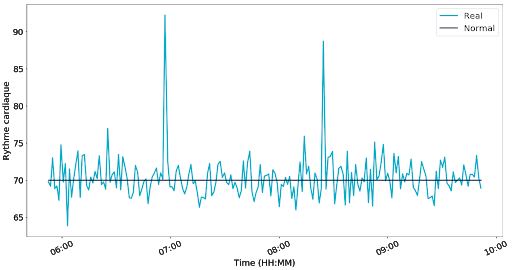
NDLR : Les deux figures précédentes donnent envie de mettre des seuils pour créer des alertes. Nous ne parlons pas de ce sujet dans cet article, mais pour aller plus loin le mot clef est alerting.
Au moment de l’annotation :
- Propriété attendue : Un signal est annoté par plusieurs annotateurs de manière similaire.
- Sonde : Mesure de la variance d’annotation entre annotateurs sur un même signal.

Figure 8 : Exemple de métrique de variance d’annotation : Intersection over Union
Au niveau du réentraînement :
- Propriété attendue : Performance au moins équivalente sinon meilleure au modèle en production.
- Sonde : Shadow production pour comparer les performances des modèles candidats par rapport au modèle déployé en production.
NDLR : La Shadow production dans le monde de la data science consiste à faire prédire l’ensemble des modèles disponibles sur les données de production pour pouvoir comparer les résultats. Bien entendu, seules les prédictions données par le modèle en production seront utilisées.
Comme il y a sans doute des problèmes que l’on n’a pas identifié, on se permet malgré tout de monitorer une distribution sans qu’elle soit directement associée à un non-déterminisme : la distribution des prédictions.
- Propriété attendue : La distribution des prédictions est stable dans le temps.
- Sonde : Suivre la distribution des prédictions.
NDLR : La distribution des prédictions est la seule distribution que l’on suit par défaut dans nos projets.
La dernière sonde dont on souhaite vous parler, qui est pour nous la plus importante, est le suivi de la performance réelle. C'est-à-dire récupérer la vérité et la comparer à nos prédictions. Cette sonde correspond à notre besoin : savoir si le système fonctionne bien. Les sondes que l’on a précédemment posées ne sont que des proxys qui nous permettent un feedback plus rapide. Récupérer la vérité peut être long, dans notre cas, il faut attendre l’annotation, mais c’est obligatoire.
Ainsi, sur cet exemple fil rouge, nous avons identifié 6 sondes relativement simples à implémenter. Ces sondes nous permettront d’avoir une confiance dans le bon fonctionnement du système. Une fois celles-ci mises en places, nous nous laissons la possibilité de découvrir de nouvelles propriétés intéressantes à monitorer.
| Propriété souhaitée | __So__nde |
| Le patient portera le système de 7h15 à 22h30 tous les jours. | Compteur de période où le système est allumé. |
| Rythme cardiaque entre 50 et 180 battements par minutes. | Rythme cardiaque moyen par fenêtre glissante de 60 secondes. |
| Un signal est annoté par plusieurs annotateurs de manière similaire. | Mesure de la variance d’annotation entre annotateurs sur un même signal. |
| Performance d’un nouveau modèle ≥ performance du modèle en production. | Shadow production. |
| La distribution des prédictions est stable dans le temps. | Mesure de la distribution des prédictions. |
| Modèle réellement performant. | Récupération de la vérité et comparaison aux prédictions. |
Figure 9 : Résumé des sondes posées sur notre système.
Principes généraux
En appliquant cette méthode sur plusieurs cas d’usage au cours de nos missions, nous avons identifié quelques principes généraux à respecter pour s’assurer que les sondes que l’on va poser soient pertinentes.
Principe 1 : Plus la sonde est loin dans le pipeline plus elle va être générique.
C’est à dire que cette sonde va attraper de nombreux comportements défaillants. La conséquence est que si elle indique un problème, elle ne sera pas très précise sur sa source.
En pratique, il faut donc chercher à mettre la sonde le plus tôt possible dans le pipeline.
Principe 2 : Les sondes ne doivent pas casser les Service Licence Agreements (SLA).
Cela signifie que les sondes ne doivent pas impacter le fonctionnement du système.
En pratique, il convient donc de faire du monitoring de manière asynchrone.
Principe 3 : Si c’est critique pour l'application, ça doit en faire partie.
Sur notre exemple fil rouge, on pourrait faire un monitoring du nombre de capteurs effectivement branchés, mais comme tous les capteurs sont nécessaires au bon fonctionnement de l’application, cette vérification n’est pas un monitoring mais fait partie de celle-ci.
En pratique, il faut donc s’assurer que la propriété n’est pas un prérequis de l’application.
Principe 4 : Seuls les aléas anticipables et probables méritent des sondes.
Dans notre exemple, nous pourrions monitorer le fait que c’est bien notre patient qui porte les capteurs, mais c’est tellement peu probable que ce soit quelqu’un d’autre que cela ne vaut pas le coût.
Sinon cela engendrera des coûts de développement importants pour rien. Dans le monde du développement logiciel en agile, ce principe s’exprime souvent sous le mantra YAGNI: You Ain’t Gonna Need It.
En pratique, il convient donc de vérifier que ce que vous voulez suivre correspond à un évènement probable.
Principe 5 : Si une sonde lève une alerte à l’étape N, mais qu’il n’y a pas d’alerte à l’étape N+1, la sonde n’est pas pertinente.
Sur notre exemple, si la sonde mesure que le rythme cardiaque est beaucoup trop haut, mais que la performance réelle du système est toujours bonne, alors cela ne servait à rien de s’assurer que le rythme cardiaque était inférieur à 180 : modifiez ou retirez cette sonde.
Dans la pratique, challengez les sondes dès leur conception (Si cette propriété n’est pas vérifiée, est-ce vraiment un problème ?). Mais aussi en production : lorsqu’une sonde dit qu’il y a un problème, mais que les suivantes disent que tout va bien, alors supprimez-la.
Principe 6 : S’il est rapide de récupérer la vérité, ce n’est pas la peine de monitorer autre chose.
Dans le cas de la publicité en ligne on cherche à proposer la publicité sur laquelle l’utilisateur est le plus susceptible de cliquer. Vous savez en quelques secondes si l’utilisateur clique ou ne clique pas. Dans ce cas, ce n’est pas la peine d’appliquer cette méthode. En monitorant votre performance réelle, vous serez alerté assez vite qu’il y a un problème.
En pratique, il convient de se demander quelle est la vitesse à laquelle on peut récupérer la vérité.
Conclusion
Partant de la conviction que le monitoring de distributions à tout va est fastidieux et souvent peu efficace, nous proposons une méthode en 3 étapes pour identifier des sondes pertinentes à mettre en place :
- Étape 1 : tracer le pipeline,
- Étape 2 : identifier le non-déterminisme,
- Étape 3 : identifier les propriétés attendues.
Vous pouvez tout de même suivre des distributions de vos données, mais cela sera plus à des fins exploratoires.
Si vous souhaitez en savoir plus, nous donnerons un talk sur le monitoring de systèmes de data science à la Duck Conf 2020.