Un test peut en cacher un autre - Un peu de théorie
Introduction
En discutant avec des développeurs, je remarque plusieurs choses :
- Nos approches sur l’architecture applicative du code sont différentes
- Les définitions que nous donnons aux catégories de tests sont différentes
- Les façons de rédiger les tests sont différentes
Sans généraliser, je pense qu'il est parfois difficile dans ce contexte d'identifier précisément quoi tester et comment.
Être au clair sur ces trois points me semble important et permet de me faciliter la vie et d'être plus confiant au quotidien, laissant beaucoup moins de place à l'ambiguïté sur des questions comme :
- Comment je vérifie cette problématique ?
- Est-ce que je ne vérifie pas trop de choses ? (Par exemple : les règles métiers plus les interactions avec la base de données en même temps)
Les grandes approches TDD
Les premières questions que l’on se pose lorsque l’on débute par les tests, c’est : “Mais par où vais-je commencer ? Quel sera mon premier test ? Avec quelle approche vais-je résoudre ce problème ?”
Est-ce que le meilleur départ est de commencer par les détails pour laisser grandir l’architecture au fur et à mesure ? Ou, au contraire, débuter avec une big picture et laisser les détails se révéler d’eux-mêmes ?
Il existe deux grandes approches :
Inside Out ou Chicago School ou Approche Classique
Cette approche vise à s’assurer des dénouements précis et non de la collaboration entre les objets. Ainsi, elle a tendance à partir de l’intérieur vers l’extérieur. C’est une pratique qui emploie un très faible usage de mocks pour se suffire des stubs. Pour avoir plus de précisions sur les mocks et stubs : https://martinfowler.com/bliki/TestDouble.html
Outside In ou London School ou Approche Mockiste
Cette approche vise à s’assurer d’une collaboration précise entre les objets. Elle a donc tendance à promouvoir l'usage de mocks, et ainsi de démarrer depuis l’extérieur (REST API/swing, etc.) vers l’intérieur.
Pour aller plus loin sur ces deux approches :
- https://8thlight.com/blog/georgina-mcfadyen/2016/06/27/inside-out-tdd-vs-outside-in.html
- https://cleancoders.com/videos/comparativeDesign
- https://codurance.com/2015/05/12/does-tdd-lead-to-good-design/
Malheureusement, elles ne permettent pas de répondre ou très indirectement à la question : Comment je peux développer et vérifier efficacement la solution à un problème donné (une règle métier, une interaction avec une base de donnée, etc.) ?
Les fondements d’une nouvelle approche
Pour appréhender au mieux l’approche que je vais proposer, il est préférable d’avoir deux pré requis.
Le principe d’inversion des dépendances pour se recentrer sur la valeur métier et ses règles
Ce dernier est au centre de plusieurs architectures.
Permettre à une application d’être pilotée aussi bien par des utilisateurs que par des programmes, des tests automatisés ou des scripts batchs, et d’être développée et testée en isolation de ses éventuels systèmes d’exécution et bases de données. - Alistair Cockburn (Hexagonal Architecture ou Ports/Adapters Architecture)
L’élément clé d’une application ne réside pas dans sa base de données et les frameworks utilisés. Les use-cases d’une application sont l’élément central. - Robert C. Martin (Clean Architecture)
Pour explorer davantage les concepts et le lexique de ces architectures, je vous conseille ces articles :
- https://blog.octo.com/architecture-hexagonale-trois-principes-et-un-exemple-dimplementation/
- http://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
- https://herbertograca.com/2017/09/14/ports-adapters-architecture/amp/
- https://alistair.cockburn.us/hexagonal-architecture/
Dans la suite, j’utiliserai le schéma ci-dessous pour mettre en avant les différentes parties utilisées :
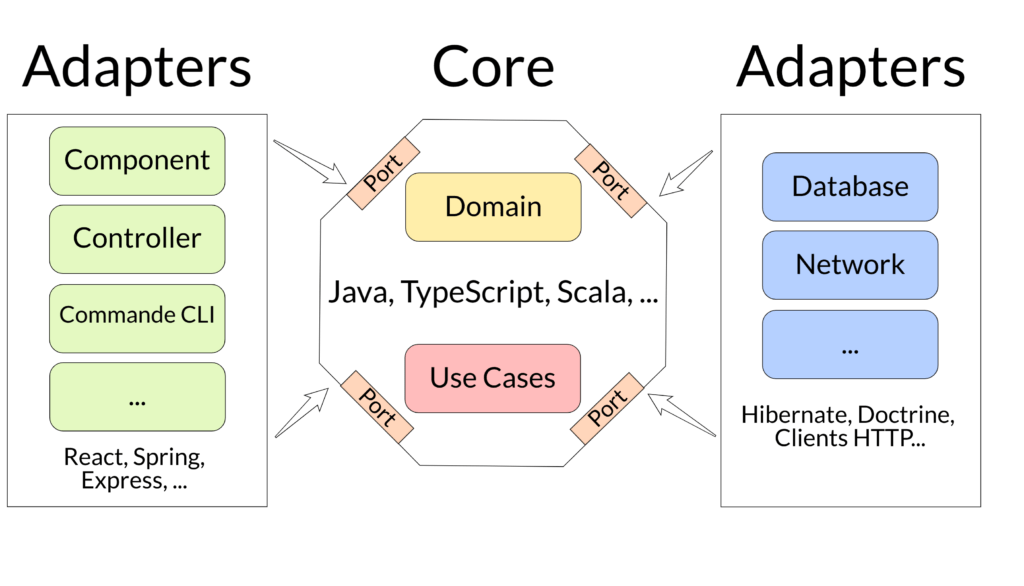
Les flèches représentent le sens des dépendances, ce sont les côtés Adapters qui dépendent du centre Core qui détient les règles métiers et non l’inverse.
L’approche de Ian Cooper sur le TDD
Pour lui un gros problème porte sur l’interprétation des gens de la propriété unitaire d’un test. En effet, un test unitaire doit pouvoir se lancer en isolation des autres, ce qui est résumé par : “si je crée cette classe alors elle doit être testée toute seule pour respecter la propriété”.
Cette vision nous éloigne d’une approche basée sur le comportement et c’est plutôt cela que l’on souhaite vérifier. C’est bien un test sur un comportement qui doit être isolé d’un autre.
Un autre problème, les développeurs/ses testent leurs détails d’implémentation. Du coup, ils écrivent beaucoup de tests, ce qui ralentit le développement et quand ils refactorent (activité qui consiste à changer l’implémentation sans changer le comportement d’un code) beaucoup de tests cassent. Cela engendre des abandons de TDD.
Alors qu’écrire ses tests via l’API publique de son code réduit le nombre de tests et rend plus productif, de plus le code devient plus simple à refactorer.
Pour résumer ces deux points donnent les avantages suivants :
- Réduction du nombre de tests
- Amélioration du refactoring
Enfin, il recommande d’utiliser des architectures permettant d’isoler son domaine des frameworks ou autres technologies (exemple : accès à la base de données), comme l’architecture Ports/Adapters.
Conférence TDD, where did it all go wrong :
- Version courte (4 min 30) : https://youtu.be/HNjlJpuA5kQ
- Version longue (1h) : https://vimeo.com/68375232
Article : http://codebetter.com/iancooper/2011/10/06/avoid-testing-implementation-details-test-behaviours/
On peut extraire deux points d’attention qui se suivent dans l’article ci-dessus :
- Le code issu d’un refactoring ne requiert pas de faire de nouveaux tests ! Car ce dernier est déjà couvert par les tests qui ont amené à la première implémentation, on a juste nettoyé et rangé proprement le code.
- La compréhension du point précédent, démontre qu’une approche “un fichier de tests par classe/fichier de production” n’est pas une bonne approche pour saisir l’essence de TDD. Ajouter une nouvelle classe ne déclenche pas forcément l’écriture de tests. Je vous recommande d’utiliser ports/adaptateurs et d’écrire les tests en outside-in (cf. vu au début) depuis le use case.
L’application théorique
Si nous reprenons la pyramide des tests, on peut distinguer quatre grandes catégories :
- Tests unitaires
- Tests d’acceptation/fonctionnels
- Tests d’intégration
- Tests de bout en bout
La première catégorie me semble essentielle. Elle permet d’avoir une boucle de feedback des plus rapides sur le développement en cours et reste relativement simple à mettre en place.
Maintenant, mettons en évidence les points d’entrée et les parties vérifiées par chacune des catégories.
Tests unitaires
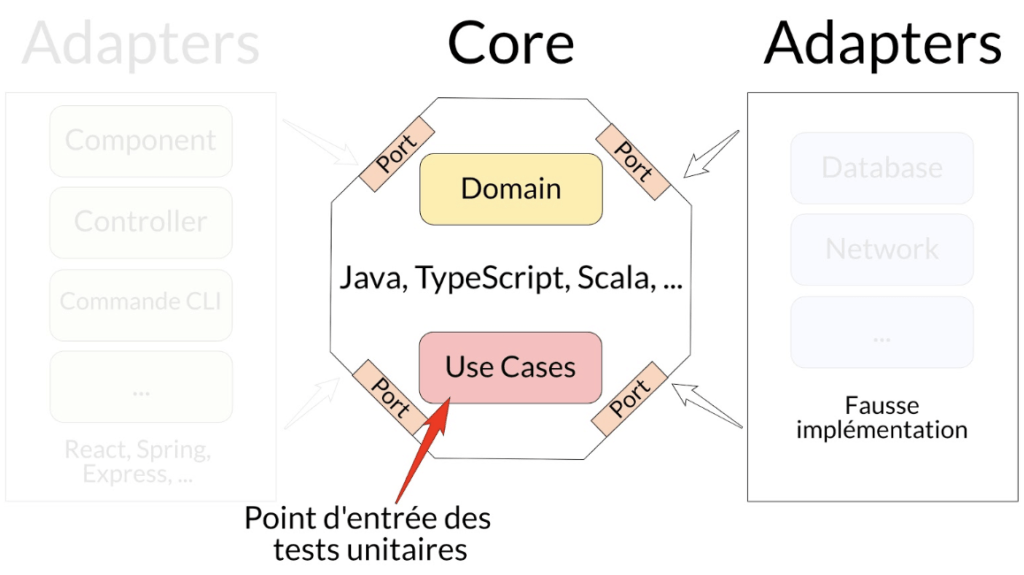
Les points d’entrée sont les Use Cases de l’application et avec les tests qui s’arrêtent aux frontières du Core avec l’utilisation d’une fausse implémentation d’un Adapter de droite (cf. les articles pour connaître leurs particularités).
Ils se focalisent sur la vérification de la bonne implémentation des règles métiers et de ce qui a de la valeur pour l’entreprise.
Articles associés :
- Un test peut en cacher un autre — Tests unitaires — P1
- Un test peut en cacher un autre — Tests unitaires — P2
Tests d’acceptation/fonctionnels
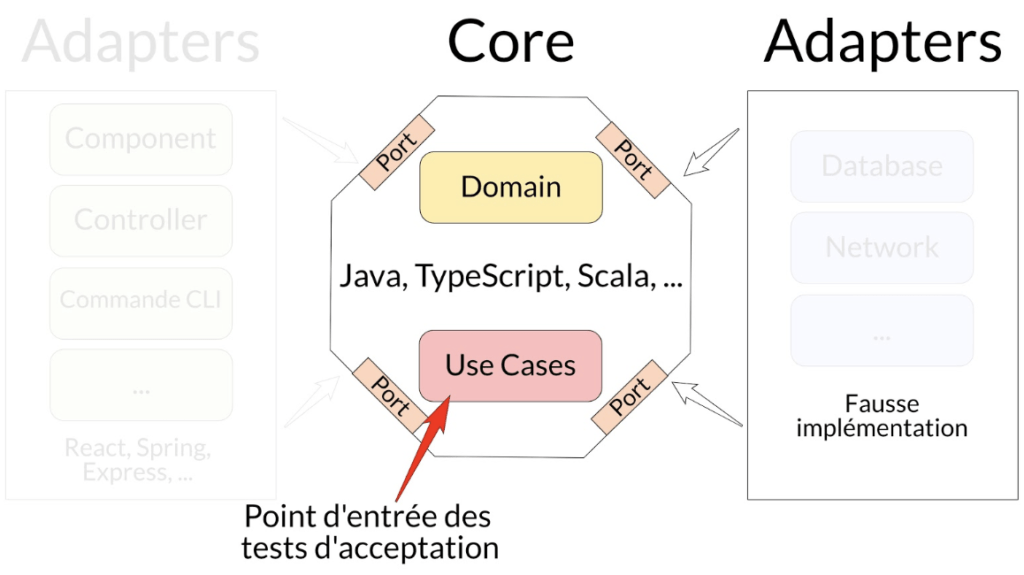
Les points d’entrée sont les Use Cases de l’application et avec les tests qui s’arrêtent aux frontières du Core avec l’utilisation d’une fausse implémentation d’un Adapter de droite (cf. l’article pour connaître leurs particularités).
Ils se focalisent sur la vérification de la bonne implémentation des règles métiers et de ce qui a de la valeur pour l’entreprise.
À la différence des tests unitaires, ils émergent d'une autre manière et se focalisent sur la variété des possibles. Nous verrons un cas d’usage dans un article dédié.
Article associé :
Tests d’intégration
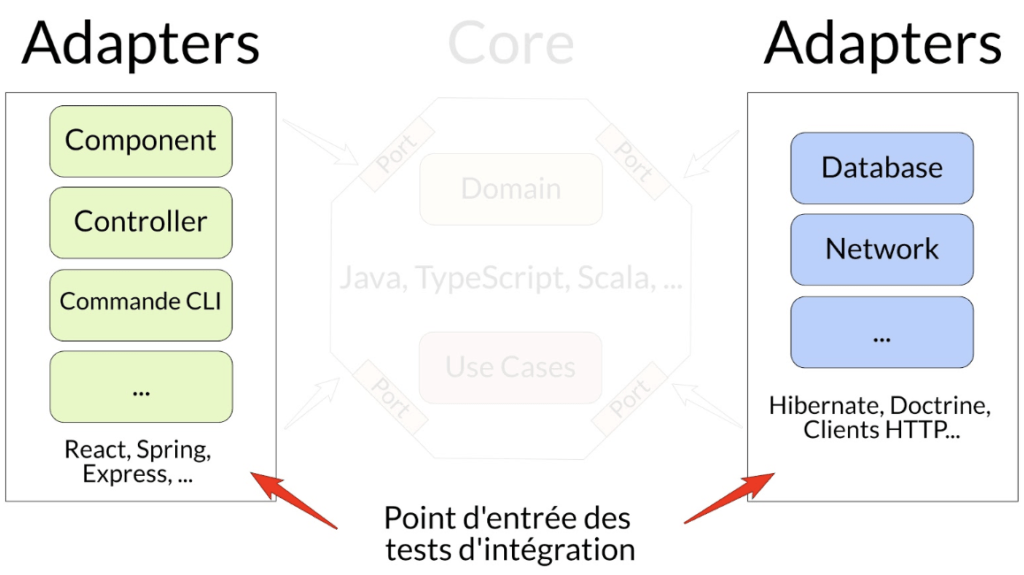
Les points d’entrée sont les Adapters de l’application et avec les tests qui s’arrêtent à cette case.
Ils se focalisent sur la vérification de la bonne intégration avec un système tiers (ex. une base de données, une REST API, l’affichage des données pour un client, etc.), sans se préoccuper des règles métiers.
On fera en général un ou quelques cas passants et non-passants, si ces derniers existent.
Exemples :
- D’un cas passant : Bonne réception de données venant d’une base de données
- D’un cas non-passant : Que se passe-t-il quand la REST API nous informe que les données envoyées sont incorrectes (400 - Bad Request) ?
Articles associés :
- Un test peut en cacher un autre — Tests d'intégration — P1
- Un test peut en cacher un autre — Tests d'intégration — P2
Tests de bout en bout
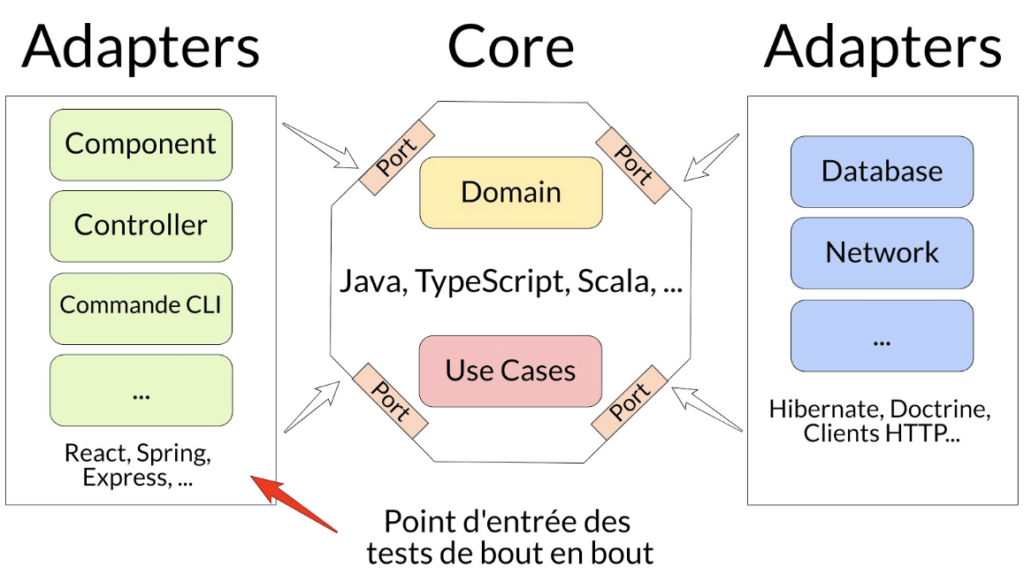
Les points d’entrée sont les Adapters de gauche de l’application (cf. l’article pour connaître leurs particularités) et avec les tests, orientés fonctionnels, qui ont pour but de traverser toutes les couches de l’application ; Adapters et Core en étant ou non connecté aux systèmes tiers (base de données, REST API, etc.).
Ils se focalisent sur la vérification du bon fonctionnement de l’ensemble du projet. On pourra par exemple faire un chemin critique de celui-ci.
Article associé :
Conclusion
Nous avons vu qu’il y avait deux grandes approches, mais elles ne répondent pas à certaines interrogations et laissent des délimitations floues de l’application.
En conjuguant, l’approche de Ian Cooper avec le principe d’inversion des dépendances porté par certaines architectures (Clean Architecture, Hexagonale Architecture), nous pouvons avoir des associations plus claires :
- Tests unitaires et tests d’acceptation : règles métiers
- Test d’intégration : intégration avec un système tiers
- Test de bout en bout : bonne collaboration de l’ensemble du système
Pour terminer, on remarquera qu‘il n’y a pas de distinction entre front-end et back-end, cela pour mettre en avant que la démarche réalisée durant cette série d’articles est valable pour les deux mondes.
Annexe : https://www.stevefenton.co.uk/2013/05/my-unit-testing-epiphany/