Un test peut en cacher un autre - Tests unitaires - P2
Introduction
L’article d’introduction débute en listant certaines différences de visions que je peux avoir avec d'autres développeurs concernant l'architecture applicative ou encore la rédaction des tests. À travers elles, j’évoque les difficultés qu’ils peuvent rencontrer à identifier précisément quoi tester et comment.
Deux phrases extraites de l’article de Ian Cooper ont été mises en avant :
- “Le code issu d’un refactoring ne requiert pas de nouveaux tests”
- “Je vous recommande d’utiliser ports/adaptateurs et d’écrire les tests en outside-in depuis le use case”
Ces deux axes sont à mon sens essentiels. Nous allons essayer de les décortiquer un par un, à travers des exemples, pour en comprendre leur essence et en quoi ils sont si importants pour faciliter le quotidien de l’équipe de développement.
Ici, nous débuterons par le second axe : “Je vous recommande d’utiliser ports/adaptateurs et d’écrire les tests en outside-in depuis le use case” en illustrant ce qu’il implique dans l’écriture des tests.
Dans cet article : Un test peut en cacher un autre - Tests unitaires - P1, nous nous attardons davantage sur le premier axe : “Le code issu d’un refactoring ne requiert pas de nouveaux tests”. Je vous recommande de lire ce dernier avant car nous allons nous appuyer dessus.
Kata
On va travailler avec un Kata qui sera la gestion d’un système de réservation de livres dans une librairie, dont les règles sont les suivantes :
- Un client peut ajouter des livres dans son panier
- Le client peut visualiser les informations du panier (prix et livres ajoutés)
- Le panier est sauvegardé
- Tous les livres coûtent 8€
- Le prix du panier varie en fonction du nombre de livres identiques ajoutés :
- 2 livres identiques donne une réduction de 5% de la somme du prix des 2 livres
- 3 livres et plus identiques donne une réduction de 25% de la somme du prix des n livres
- Exemple pour l’achat de :
- 2 fois le livre 1
- 3 fois le livre 2
- 4 fois le livre 3
- 1 fois le livre 4
- 1 fois le livre 5
- Le montant du panier est égale à 73,20€
- Quand le client emprunte des livres :
- Les livres ne sont plus disponibles (stock de 1)
- Un SMS est envoyé
- Un email est envoyé
- Quand le client retourne des livres :
- Les livres sont disponibles
- Un email est envoyé
NDR : le code est en TypeScript, qui propose un typage statique fort. Néanmoins, le code peut être transposé dans des langages comme JavaScript, Python ou PHP qui ont nativement un typage dynamique et faible pour certains.
Les tests unitaires (TU)
Nous allons illustrer comment dans le code la phrase : “Je vous recommande d’utiliser ports/adaptateurs et d’écrire les tests en outside-in depuis le use case.****” peut être matérialisée.
Prenons pour exemple les fonctionnalités suivantes :
- Un client peut ajouter des livres dans son panier
- Le client peut visualiser les informations du panier (prix et livres ajoutés)
- Le panier est sauvegardé
Ici, nous avons le mot clef “sauvegardé” qui met en avant un choix d’architecture : sauvegarder la donnée quelque part, base de données, fichier, etc. Hors dans ce type de tests, devrions-nous connaître ces choix et en être impacté ? À priori, non.
Ces fonctionnalités n’ont pas besoin de savoir comment la donnée est enregistrée, juste que c’est possible. Dans les TU, on doit uniquement se concentrer sur les règles métiers sans être affecté par des “détails d’implémentation” !
C’est là que le principe d’inversion des dépendances (DIP) vient nous aider pour répondre à cette problématique.
Modifions les tests pour prendre en compte cette notion de sauvegarde du panier :
https://gist.github.com/mickaelw/07fa70b57b8df2a7d232be7bd7bd9056
Les TU gardent les mêmes intitulés que précédemment, uniquement l'implémentation à changée.
Apparition de trois classes :
- AddToBasket
- GetBasketInformation
- InMemoryBasketRepository
AddToBasket et GetBasketInformation :
Ces deux classes sont des Use Cases, l’une pour ajouter un livre dans le panier et l’autre pour récupérer les informations du panier.
Pour chacune de ces classes, nous devons injecter une implémentation d’un BasketRepository afin qu’elles puissent fonctionner correctement pour sauvegarder et récupérer les données nécessaires. Les dépendances sont biens inversées.
https://gist.github.com/mickaelw/f0b64379c811ba65b75901930e7e9c10
https://gist.github.com/mickaelw/e583d291b7467527d32193c2c244e638
Là, nous écrivons les tests en outside-in depuis le use case.
InMemoryBasketRepository :
https://gist.github.com/mickaelw/a6dd68497c19ab63fb58f920e8c7941a
Cette classe est une implémentation possible du contrat défini par l’interface BasketRepository :
https://gist.github.com/mickaelw/0e3ecc4e3f0ce5310fdf83388472e2fd
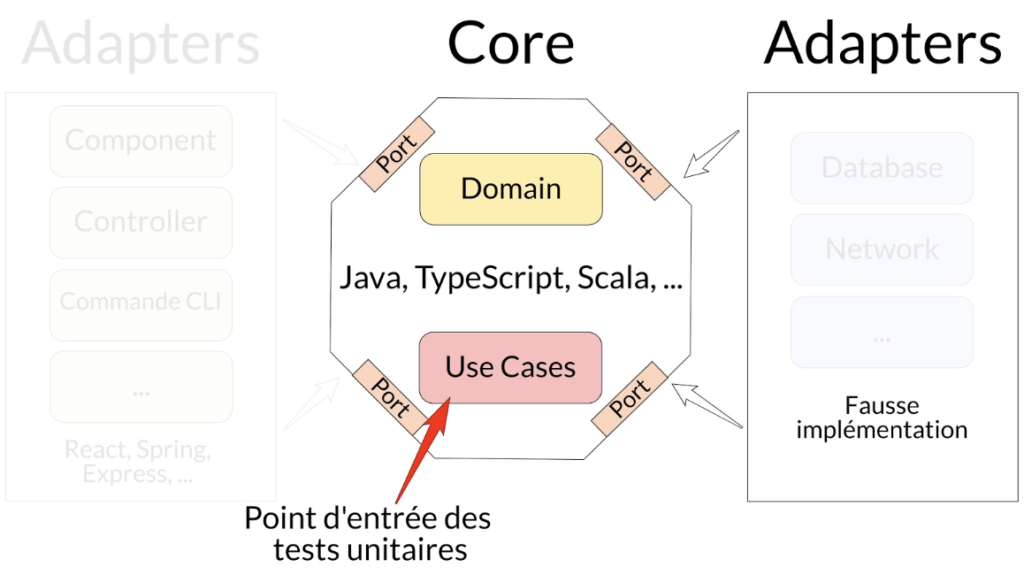
C’est la première notion évoquée plus haut : Je vous recommande d’utiliser ports/adaptateurs :
- BasketRepository est un port (le contrat)
- InMemoryBasketRepository est un adaptateur (une implémentation)
NDR : Dans les faits, InMemoryBasketRepository est une doublure de test manuel. Il est donc possible de le remplacer par une doublure générée par une librairie de tests.
Conclusion
Pour ne pas s’embrouiller entre les tâches, on évite d’en faire plusieurs en même temps, pour nos tests c’est pareil.
Les TU doivent nous permettre de se concentrer sur les règles métiers pour éviter au maximum de faire des erreurs (qui pourraient en plus coûter de l’argent à l’entreprise).
Nous utilisons le principe d’inversion des dépendances (DIP), ce qui nous aide à tester efficacement nos fonctionnalités sans se préoccuper d’un détail d’implémentation (ici, comment seront stockées les données).
Un TU a en point d’entrée un Use Case à qui on va masquer des problématiques qui vont être du ressort des Adaptateurs, afin de se concentrer sur ce qui est présent dans le Core****.
L'objectif est de tester que les règles métier s’orchestrent bien en isolation de tous choix d'implémentation technique.
N’utilisant pas l’implémentation réelle, les tests deviennent :
- Plus faciles à écrire :
- Pas de gestion du système tiers. Exemple : supprimer les données après chaque tests dans le cas d’une base de données.
- L’injection possible de fausses implémentations donne une grande souplesse pour les tests.
- Moins fragiles, si les tests dépendent d’une API, cette dernière peut être défaillante au moment de lancer les tests, ce qui va entraîner des faux négatifs.
- Plus rapides, en effet pas de latence pour l’accès de la donnée.
Résumé en une image :