Un test peut en cacher un autre - Tests d'intégration - P2
Introduction
L’article d’introduction débute en listant certaines différences de visions que je peux avoir avec d'autres développeurs concernant l'architecture applicative ou encore la rédaction des tests. À travers elles, j’évoque les difficultés qu’ils peuvent rencontrer à identifier précisément quoi tester et comment.
Nous avons pu voir dans ces articles autour des tests unitaires :
- Un test peut en cacher un autre — Tests unitaires — P1
- Un test peut en cacher un autre — Tests unitaires — P2
Que ces tests sont exclusivement centrés sur les règles métiers qui sont validées via de fausses implémentations.
À un moment, il va falloir réaliser des implémentations afin de pouvoir sauvegarder en base de données, envoyer un SMS ou encore afficher des données à l'utilisateur.
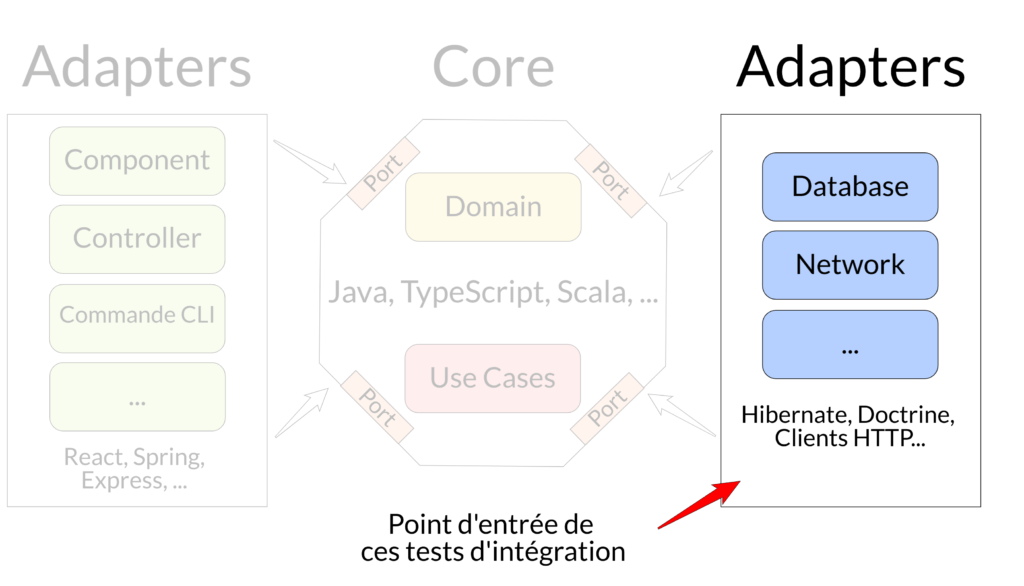
Ici, nous allons nous focaliser sur les tests d'intégration des adaptateurs de droite ou encore adaptateurs secondaires, il existe d'autres synonymes. Pour connaître leurs particularités, je vous conseille ces articles :
- https://alistair.cockburn.us/hexagonal-architecture/
- https://herbertograca.com/2017/09/14/ports-adapters-architecture/
Dans l’article : Un test peut en cacher un autre — Tests d’intégration — P1 nous nous attardons davantage sur les tests des adaptateurs de gauche.
Kata
On va travailler avec un Kata qui sera la gestion d’un système de réservation de livres dans une librairie, dont les règles sont les suivantes :
- Un client peut ajouter des livres dans son panier
- Le client peut visualiser les informations du panier (prix et livres ajoutés)
- Le panier est sauvegardé
- Tous les livres coûtent 8€
- Le prix du panier varie en fonction du nombre de livres identiques ajoutés :
- 2 livres identiques donne une réduction de 5% de la somme du prix des 2 livres
- 3 livres et plus identiques donne une réduction de 25% de la somme du prix des n livres
- Exemple pour l’achat de :
- 2 fois le livre 1
- 3 fois le livre 2
- 4 fois le livre 3
- 1 fois le livre 4
- 1 fois le livre 5
- Le montant du panier est égale à 73,20€
- Quand le client emprunte des livres :
- Les livres ne sont plus disponibles (stock de 1)
- Un SMS est envoyé
- Un email est envoyé
- Quand le client retourne des livres :
- Les livres sont disponibles
- Un email est envoyé
NDR : le code est en TypeScript, qui propose un typage statique fort. Néanmoins, le code peut être transposé dans des langages comme JavaScript, Python ou PHP qui ont nativement un typage dynamique et faible pour certains.
Les tests d'intégration (TI)
Ces tests ont pour but de s’assurer que les implémentations choisies s'intègrent bien avec nos Use Cases et respectent bien un port défini (le contrat). Ils ont en point d’entrée l’Adaptateur. Ils sont fortement couplés à un choix d'architecture (librairie, framework, technologie, etc.).
On fera de manière intelligente un ou quelques cas passant et non passant, si ces derniers existent. Le tout en évitant de re tester les règles métiers, car c’est déjà fait ! On souhaite uniquement savoir si l'interaction avec la base de données choisie fonctionnent, que notre appel HTTP s'effectue bien, etc.
Adaptateur utilisé par les Use Cases (à droite**/secondaire****)**
Je distingue deux façons (doublage du tiers et utilisation du tiers) de tester avec chacune leurs avantages et inconvénients et il en existe certainement d'autres en fonction des écosystèmes.
Doublage du tiers
Dans cette façon, on va faire des interactions “fictives” avec le tiers car on va substituer le client pour tester. Par exemple, un client HTTP, un client MySQL, etc.
On va vérifier s’il y a une bonne collaboration et comment se comporte l’implémentation quand le client retourne ses valeurs, etc.
Et pour nous faciliter la rédaction des tests, nous allons utiliser l'injection de dépendance, ce qui a pour autre effet de découpler le code.
https://gist.github.com/mickaelw/a0be671f605c28e051c44861a33ee863
On peut remarquer que les méthodes de l’HTTPClient sont doublées par une librairie de tests. Il est également possible de le faire manuellement.
L’adaptateur testé, HTTPBasketRepository :
https://gist.github.com/mickaelw/3f3ac8b565d8be40d8f71af0c414da12
HTTPBasketRepository est un adaptateur (une implémentation) réelle du port (contrat) BasketRepository.
Ici, nous vérifions les cas passant et non passant suivants :
- Bonne récupération au format défini dans le port de tous les livres
- Bon ajout d’un livre
- Erreurs lors des appels à l’API
À noter également, le jeu de mappers pour respecter les formats imposés par chaque partie.
Utilisation du tiers
Le but va être d'interagir réellement avec le tiers quand cela est possible.
À la différence du point précédent, on ne va pas se focaliser sur les interactions avec le client mais sur l’effet de bord qui résulte d’une action. C’est à dire, si on souhaite vérifier un ajout en base de données, on va vérifier qu’on récupère la bonne valeur.
https://gist.github.com/mickaelw/8eeb55c99186d8446c378545be16bd24
Nous pouvons remarquer un beforeEach et un afterEach avec respectivement, un ajout en base de données pour mettre le test dans un état propice, et la suppression de cette même donnée pour garder la base de données propre pour les tests suivants.
NDR : ici, on utilise l’ORM pour réaliser ces deux comportements. En effet, l’adaptateur qui est testé ne fait que récupérer les informations d’un client par rapport à son id.
https://gist.github.com/mickaelw/0a35d5b3a56c0f84c0a3beef97935615
SequelizeCustomerLoader est un adaptateur (une implémentation) réelle du port (contrat) CustomerLoader.
Ici, nous vérifions les cas passant et non passant suivants :
- Bonne récupération des informations du client au format défini dans le port
- Information que le client demandé n’existe pas
À noter, le jeu de mapper pour respecter le format imposé.
Conclusion
Pour ne pas s’embrouiller entre les tâches, on évite d’en faire plusieurs en même temps, pour nos tests c’est pareil.
Les TI doivent nous permettre de nous concentrer sur la bonne intégration avec un système tiers et chasser de notre esprit les règles métiers qui sont gérées par les tests unitaires et les tests d’acceptation.
L'objectif d’un TI est de tester l’intégration d’un système tiers (librairie, framework, etc.) pour être utilisé par nos Use Cases**.**
**Il va nous permettre de construire l’**Adaptateur par rapport au contrat défini par le port afférent et aux contraintes liées au système tiers choisi.
L’article n’a pas vocation à dire que l’une des façons de faire est mieux que l’autre mais à montrer les possibles et leurs implications, pour résumer :
Utilisation de test double :
Nous utilisons l’injection de dépendances dans la première façon de faire, afin de tester la collaboration entre le client et son utilisateur.
Avantages :
- L’initialisation est plutôt rapide et simple
- Les tests sont rapides
- Les tests sont indépendants du bon fonctionnement du tiers
Inconvénients :
- Peut donner des vrais négatifs.
Exemple : le test va rester vert même si la réponse API ou le schéma de la base de données a changé - Ne teste pas vraiment l’implémentation réelle
- Difficulté possible à substituer le client
Utilisation de l'implémentation réelle :
L’injection de dépendances n’est pas nécessaire dans cette façon de faire, car nous regardons l’effet de bord.
Avantages :
- Teste vraiment l’implémentation
- Va informer lorsque le contrat du tiers a changé
Exemple : la réponse API ou le schéma de la base de données a été modifié
Inconvénients :
- Peut donner des faux négatifs
Exemple : une latence réseau qui fait tomber le test en rouge - L’initialisation peut être lourde et compliquée, surtout au début
- Les tests sont plus lents
- Il faut bien nettoyer après le passage de chaque test
- Avoir un environnement dédié aux tests pour le tiers
Résumé en une image :