Un test peut en cacher un autre - Tests d'acceptation
Introduction
L’article d’introduction débute en listant certaines différences de visions que je peux avoir avec d'autres développeurs concernant l'architecture applicative ou encore la rédaction des tests. À travers elles, j’évoque les difficultés qu’ils peuvent rencontrer à identifier précisément quoi tester et comment.
Deux phrases extraites de l’article de Ian Cooper avaient retenu l’attention :
- “Le code issu d’un refactoring ne requiert pas de faire de nouveaux tests dessus !”
- “Je vous recommande d’utiliser ports/adaptateurs **et d’écrire les tests en outside-in depuis le use case.**”
Nous allons nous appuyer sur le second axe pour l’écriture des tests d’acceptation ou fonctionnels. Pour avoir plus de détails sur celui-ci, je vous recommande cet article.
Kata
On va travailler avec un Kata qui sera la gestion d’un système de réservation de livres dans une librairie, dont les règles sont les suivantes :
- Un client peut ajouter des livres dans son panier
- Le client peut visualiser les informations du panier (prix et livres ajoutés)
- Le panier est sauvegardé
- Tous les livres coûtent 8€
- Le prix du panier varie en fonction du nombre de livres identiques ajoutés :
- 2 livres identiques donne une réduction de 5% de la somme du prix des 2 livres
- 3 livres et plus identiques donne une réduction de 25% de la somme du prix des n livres
- Exemple pour l’achat de :
- 2 fois le livre 1
- 3 fois le livre 2
- 4 fois le livre 3
- 1 fois le livre 4
- 1 fois le livre 5
- Le montant du panier est égale à 73,20€
- Quand le client emprunte des livres :
- Les livres ne sont plus disponibles (stock de 1)
- Un SMS est envoyé
- Un email est envoyé
- Quand le client retourne des livres :
- Les livres sont disponibles
- Un email est envoyé
NDR : le code est en TypeScript, qui propose un typage statique fort. Néanmoins, le code peut être transposé dans des langages comme JavaScript, Python ou PHP qui ont nativement un typage dynamique et faible pour certains.
Les tests d’acceptation ou tests fonctionnels
Ces tests peuvent être le point de départ du développement d’une nouvelle fonctionnalité. Beaucoup de monde a entendu parler de Behavior-Driven Development (BDD), qui se concentre sur de la discussion entre les 3 Amigos. La méthodologie, mise en avant ici, sera plutôt l’Acceptance Test-Driven Development (ATDD), qui va plus loin en formalisation la discussion pour la rendre compréhensible et exécutable dans le code.
La démarche a comme objectifs (non exhaustif) :
- De s’aligner sur un vocabulaire clair et non ambiguë entre client(s), testeur(s) et développeur(s), alias les 3 Amigos,
- De s’aligner sur des exemples/scénarios métiers en français, précis et parlant pour tout le monde,
- De rendre les scénarios exécutables dans le code.
Prenons le calcul de la réduction à appliquer sur le prix du panier après l’ajout de livres dans celui-ci. Les scénarios ci-dessous sont une possibilité d’écriture, car ils vont résulter de la discussion entre les 3 Amigos.
https://gist.github.com/mickaelw/7ef18392098d34d044d78e9bbbd9deb3
On vient de faire le lien entre les phrases présentes dans le fichier Gherkin et le langage de programmation choisi afin de les rendre exécutables par le code.
https://gist.github.com/mickaelw/ceb172eecdc76d8a1a26825a37a14195
On peut remarquer plusieurs points :
il n’y a aucun aspect technique dans les scénarios (url d’API, information graphique, etc.). C’est uniquement du français. Pourquoi devrait-on ré écrire ces tests si demain, l’url de l’API ou l’interface graphique change ? Aucune raison !
Comme pour les tests unitaires :
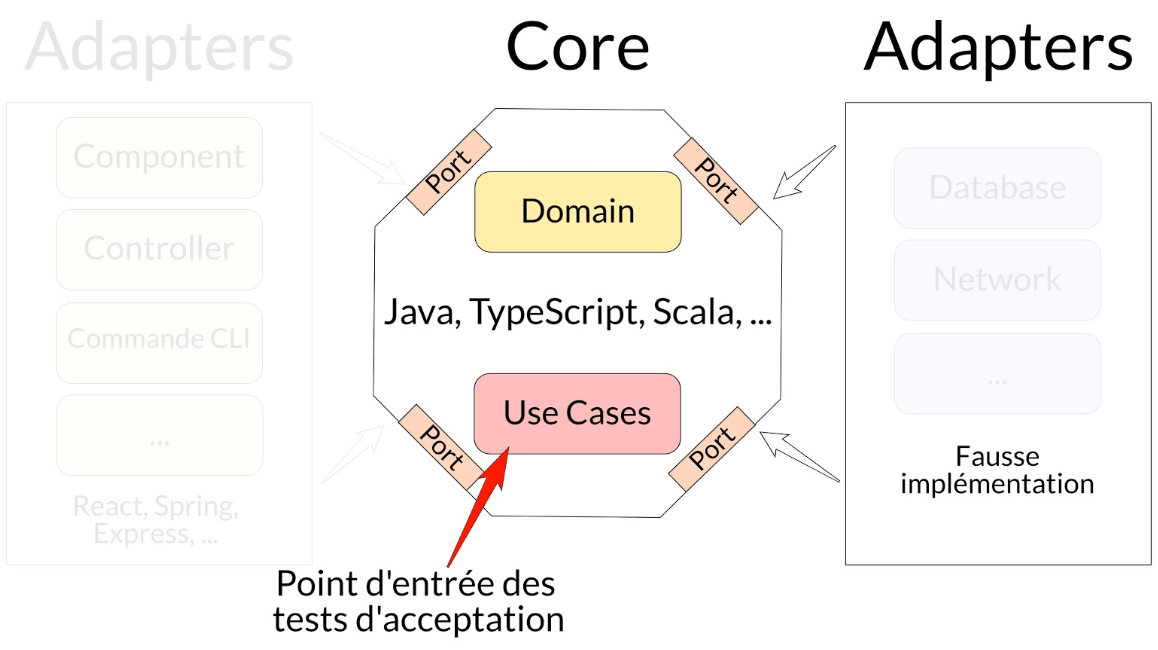
- Mes points d’entrées sont mes Use Cases (AddToBasket et GetBasketInformation)
- On utilise une fausse implémentation pour les tests d’un BasketRepository
Au lancement de ces tests, ils seront rouges. Nous allons écrire des tests unitaires jusqu’à faire passer tous les scénarios au vert. Cette pratique est appelée la Double Loop TDD. Pour la partie TU, vous pouvez consulter les articles suivants :
- Un test peut en cacher un autre — Tests unitaires — P1
- Un test peut en cacher un autre — Tests unitaires — P2
Les tests d’acceptation prennent la problématique au global quelque soit sa complexité. Alors que, les tests unitaires vont prendre cette même problématique, en la simplifiant à travers plusieurs cas pour la résoudre de manière itérative et simple.
Ainsi, les tests d’acceptation vont permettre de valider le “quoi”, alors que les tests unitaires vont nous guider dans la construction du “comment”.
NDR : Ici, je prends l’exemple de l’outil Cucumber pour les avantages qu’il apporte (exécution d’un fichier Gherkin). Mais fondamentalement, on peut s’en passer et utiliser la librairie de tests standard (JUnit, Jest, ScalaTest, PHPUnit, etc.).
L’outil n’est pas important à la différence du but de ce type de tests.
Conclusion
Si vous n’avez pas la possibilité de réunir les 3 Amigos****, ce type de tests est difficile à mettre en place.
À l’instar des tests unitaires, de nouveau on doit uniquement se concentrer sur les règles métiers sans être affecté par des “détails d’implémentation” !
Nous utilisons le principe d’inversion des dépendances (DIP), ce qui nous aide à tester efficacement nos fonctionnalités sans se préoccuper d’un détail d’implémentation (ici, comment seront stockées les données).
Un test d’acceptation doit décrire, en français, des scénarios compréhensibles par tout le monde même des personnes non technique, sans révéler une implémentation possible**, ce qui permet d’avoir une documentation fonctionnelle.**
Un test d’acceptation a en point d’entrée un Use Case à qui on va masquer des problématiques qui vont être du ressort des Adaptateurs**, afin de se concentrer sur ce qui est présent dans le** Core**. L'objectif est de tester que les règles métier s’orchestrent bien en isolation de tous choix d'implémentation technique.**
N’utilisant pas l’implémentation réelle, les tests deviennent :
- Plus faciles à écrire :
- Pas de gestion du système tiers. Exemple : supprimer les données après chaque test dans le cas d’une base de données.
- L’injection possible de fausses implémentations donne une grande souplesse pour les tests.
- Moins fragiles, si les tests dépendent d’une API, cette dernière peut être défaillante au moment de lancer les tests, ce qui va entraîner des faux négatifs.
- Plus rapides, en effet pas de latence pour l’accès de la donnée, du réseau, etc.
Résumé en une image :