Une pincée de CQRS avec RavenDB
Dans de précédents articles, nous avons abordé ce qu'est CQRS et quels avantages nous pouvions tirer de la séparation entre l'écriture et la lecture dans une application.
Il n'est cependant pas nécessaire d'avoir une architecture complexe pour en bénéficier : on peut parfaitement commencer par baser ses interfaces de consultation sur des facilités offertes par son système de persistance. Par exemple, on utilisera les vues proposées par les SGBD relationnels pour simplifier au maximum le mapping entre la base de données et les objets à afficher.
Certaines bases de données NoSql proposent des fonctionnalités très poussées (notamment du Map/Reduce) qui peuvent être très pratique. Dans cet article, nous allons nous intéresser de plus près à une base documentaire, RavenDB, et voir comment l'utiliser pour aborder certains préceptes de CQRS à moindre coût en environnement .NET

RavenDB ?
C'est une base de données documentaire entièrement réalisée en .NET. Elle s’intègre donc très naturellement dans un développement autour de cette plateforme et les amoureux de LINQ seront ravis. RavenDB expose son API en REST, il est donc possible de l'utiliser avec bien d'autres langages...
Voici les caractéristiques qui vont nous intéresser ici :
- Utilisée en mode "document store" (lecture et stockage d'un document, du JSON en l'occurrence pour RavenDB), elle présente les caractéristiques ACID, nous pouvons donc l'utiliser pour gérer le côté "Write" de notre application en étant assuré de la consistance et de la pérennité des données comme avec un SGBD plus classique
- Utilisée en requêtage massif, elle présente des caractéristiques similaires à BASE : rapidité de réponse au détriment éventuel de la fraîcheur des données.
- Son système d'indexation poussé basé sur Lucene va nous permettre d'implémenter des recherches élaborées et efficace
- Elle gère des concepts avancés, comme le multi-tenancy et le sharding pour permettre de tenir des charges importantes... mais restons simples : voyons déjà ce qu'un seul serveur a à à nous offrir
Un serveur RavenDB associe donc les deux facettes prônées par CQRS : la consistance attendue par l'aspect "Write" en mode Document Store, et la rapidité nécessaire à une bonne expérience utilisateur en mode requetage massif pour l'aspect "Read"
Les binaires de RavenDB sont disponibles depuis le site du produit. Il suffit de télécharger le zip de la dernière build stable, de décompresser le tout dans le répertoire de votre choix et de lancer le serveur.... c'est tout ! Bien sûr la base de données peut être lancée en tant que service ou même hostée dans un IIS. Elle peut également être embarquée dans une application, ce qui est d'ailleurs très pratique pour les tests unitaires.
L'exemple
(ou comment glisser une référence à sa série préférée du moment)
Des fans de Game of Thrones cherchent à savoir quel est le personnage le plus charismatique de la série. Pour cela, une petite application de vote est mise en place. On y stocke des comptes utilisateurs, des fiches de personnages et des votes en positif ou en négatif. Voilà une partie de notre modèle en écriture:
public class Character {
public string Id { get; set; }
public string Name { get; set; }
public Allegiance Allegiance { get; set; }
}
public class Vote {
public string UserId { get; set; }
public string CharacterId { get; set; }
public int Points { get; set; }
public string Comment { get; set;}
}
Notez qu'il s'agit de Plain Old CLR Objects (POCOs), objets simples sans dépendance à un framework technique (pas d'héritage etc...)
Voyons comment alimenter notre base toute neuve : après avoir intégré le package NuGet du client RavenDB, il faut initialiser la connexion au server, en créant un objet DocumentStore.
var documentStore = new DocumentStore {
Url = "http://localhost:8080/databases/Example"
};
documentStore.Initialize();
Une application aura la plupart du temps une seule instance de DocumentStore utilisée en tant que singleton.
Voyons comment en stocker une fiche de personnage dans RavenDB : voilà le code qu'on pourrait trouver dans un Handler de commande par exemple :
var character = new Character {
Name = "Tyrion Lannister" ,
Allegiance = Allegiance.Lannister
};
//Ouverture d'une session,
using (var session = documenStore.OpenSession())
{
session.Store(character);
// Si on n'utilise pas SaveChanges, rien n'est stocké,
// c'est une sorte de commit
session.SaveChanges();
}
Ici, nous laissons RavenDB décider de l'identifiant du document car nous ne l'avons pas affecté. Pour récupérer un document, c'est aussi très simple :
using (var session = documenStore.OpenSession()) {
var character1 = session.Load("character/1")
// ... modification etc...
}
Des indexes au top
En tant que fan de Game of Thrones, je veux pouvoir afficher une liste de personnages classée par popularité. Une simple liste avec le nom du personnage et le nombre de votes à son actif, le tout correctement trié, cela suffit largement. Comment faire ?
Notre base NoSql ne dispose pas de jointures, et croiser une multitude de requêtes pour arriver à notre résultat est une mauvaise approche.
CQRS nous incite à développer un modèle dédié qui serait mis à jour à chaque vote ou à chaque modification du personnage, ce qui nous permettrait d'afficher la liste sans refaire les calculs à la consultation. On accepte que la mise à jour de ce modèle puisse être parfois légèrement retardée
RavenDB nous propose une fonctionnalité taillée sur mesure : les indexes.
Un index est une fonction map/reduce appliquée à un ensemble de documents sur le serveur. Comme ce traitement est fait en tâche de fond, il ne gêne pas les performances en insertion ou en mise à jour. Par contre, un index peut tout à fait ne pas être encore à jour au moment d'être interrogé. Le parti pris de RavenDB est alors de répondre rapidement avec des données éventuellement périmées, mais de l'indiquer au client si cela l’intéresse : c'est notre fameuse Eventual consistency. Le client peut aussi indiquer vouloir les données les plus fraîches, mais peut-être devra-t-il attendre.
Voyons comment définir notre index afin d'agréger les votes.
public class CharacterByPopularity : AbstractIndexCreationTask<Vote,CharacterByPopularity.Result>
{
//Une classe pour porter les résultats de notre map/reduce
public class ReduceResult
{
public string CharacterId { get; set; }
public int Popularity { get; set; }
}
public CharacterByPopularity()
{
// De quelles informations avons nous besoin
// Mais aussi quels sont nos critère de recherche éventuels
Map = votes => from vote in votes
select new {vote.CharacterId, Popularity = vote.Points};
// Quelle opération effectuer sur l'ensemble des documents,
Reduce = votes => from vote in votes
group vote by vote.CharacterId into g // on groupe par id de personnage
select new {CharacterId = g.Key, Popularity = g.Sum(c=>c.Popularity)}; // et on somme les votes
// Donner un indice à Raven sur comment trier le champs
// Si aucune indication n'est donnée, le tri est alphanumérique
Sort(c=>c.Popularity,SortOptions.Int);
}
}
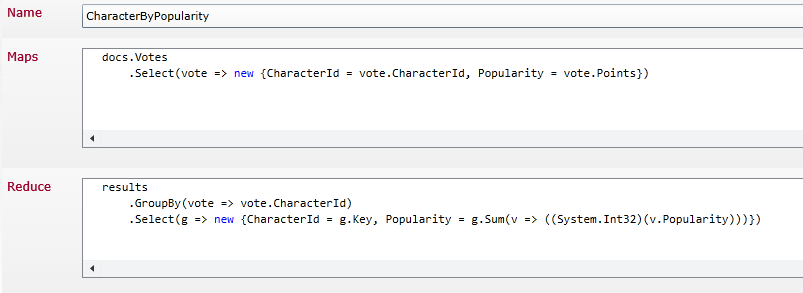
Notez que si la définition de l'index se fait ici par le code C#, le serveur RavenDB n'a lui aucune connaissance des types utilisés coté client : les expressions LINQ concernent ici des propriétés de document, les types vont désigner les collections à interroger, ce sont des facilités d'écriture. D'ailleurs, la définition de l'index peut être faite directement par l'API en passant des chaines de caractères ou dans l'outil de consultation embarqué dans le serveur. Voyons d'ailleurs ce que ça donne dans Raven Studio
La définition de l'index
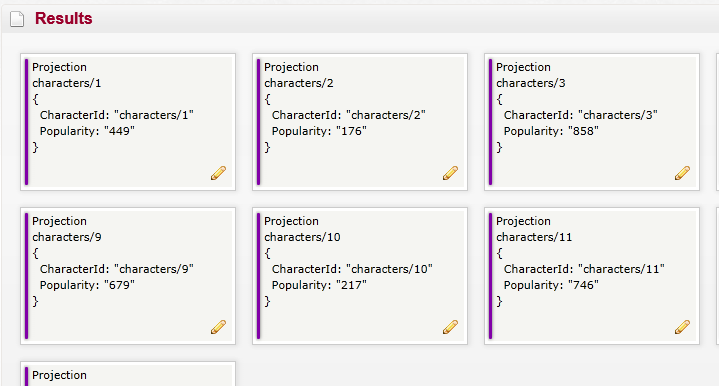
Les résultats
On interroge l'index comme ceci :
session.Query<CharacterByPopularity.Result,CharacterByPopularity>().OrderByDescending(c => c.Popularity)
Ça se lit : je cherche à interroger des objets qui ressemblent à des CharacterByPopularity.Result en utilisant l'index CharacterByPopularity et je les trie
On pourrait tout à fait chercher à savoir si ces données sont fraîches...
RavenQueryStatistics stats;
session.Query<CharacterByPopularity.Result,CharacterByPopularity>()
.Statistics(out stats)
// stats a une propriété IsStale pour savoir si les données sont fraiches
// entre autres choses pratiques
.OrderByDescending(c => c.Popularity)
... ou demander explicitement des données à jour
session.Query<CharacterByPopularity.Result,CharacterByPopularity>()
.Customize(c => c.WaitForNonStaleResults())
// s'il te plait Raven, attend que ton index soit à jour
// avant de me répondre
.OrderByDescending(c => c.Popularity)
Coup de projecteur
Il ne nous manque que le nom du personnage pour avoir un "top" utilisable. On pourrait dénormaliser cette propriété au niveau des votes, c'est à dire stocker le nom dans le document Vote pour l'avoir sous la main. Néanmoins, cela va poser problème si le nom du personnage est modifié (faute d'orthographe... mais aussi mariage, changement d'identité, c'est qu'il s'en passe des choses dans Game of Thrones !)
Encore une fois, RavenDB va nous aider grâce à une fonctionnalité appelée "Live Projections" qui va nous permettre de charger des propriétés d'autres documents au moment de la requête. Ce traitement est à nouveau fait sur le serveur, on ne multiplie donc pas les requêtes Dans le constructeur de notre index, on ajoute :
TransformResults = (database, votes) => from vote in votes //pour chaque resultat du reduce
let characterName = database.Load(vote.CharacterId) //on retrouve le document Character
select new { characterName.Name, vote.Popularity }; // et on utilise son nom dans le résultat
Et notre index nous donne maintenant :
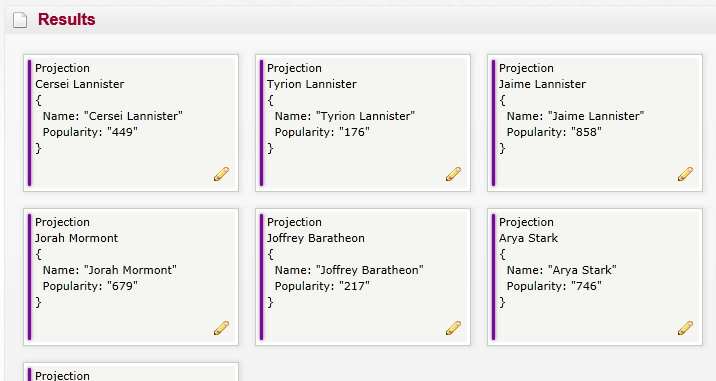
Voilà qui correspond à notre pile à notre demande. Il n'y a plus qu'à interroger notre index coté client.
La syntaxe est un peu particulière.
session.Query<CharacterByPopularity.Result,CharacterByPopularity>() // on cherche des Result dans l'index CharacterByPopularity
.As() //mais les résultats ressembleront à des objets CharacterWithPopalurity
.OrderByDescending(c => c.Popularity).ToList()); // et on trie
Le serveur fait tout le travail en tâche de fond, le client n'a plus qu'à afficher le résultat
En conclusion
Nous avons vu comment utiliser RavenDB à la fois pour stocker simplement nos données mais également pour créer un modèle en lecture performant et sur mesure comme le préconise CQRS. Le choix d'un système de persistance n'est pas anodin et peut grandement faciliter la tâche. L'exemple qui a servi de support est bien sûr un peu naïf et améliorable. On pourrait par exemple créer un agrégat "utilisateur" contenant les votes et ainsi contrôler plus aisément que des règles métiers soient bien respectées (un vote par personnage et par utilisateur, attribution complexe de points). Les indexes s’accommodent tout à fait de documents complexes. De même, nous n'avons pas exploré les possibilités de RavenDB liées à Lucene. Peut-être au prochain épisode ?