Les patterns des Grands du Web - TP versus BI : la nouvelle approche NoSQL
Dans les SI traditionnels, les architectures de traitement de données structurées se sont généralement organisées en deux pôles distincts. Toutes les deux s’appuient certes sur une base de données relationnelle, mais avec des modèles et des contraintes propres
- D’un côté, le Transactional Processing (TP), à base de transactions ACID
- De l’autre la Business Intelligence (BI), à base de tables de faits et de dimensions
Les Grands du Web ont mis en place à la fois de nouveaux outils et de nouvelles façons d’organiser les traitements pour répondre à ces deux besoins. La distribution du stockage et des traitements est notamment largement utilisée dans les deux cas.
Les besoins métiers
L’une des particularités récurrente de ces acteurs est de devoir manipuler une donnée semi-structurée voire non structurée, différente du traditionnel tableau de données que l’on utilise en informatique de gestion : pages web pour Google, graphe social pour Facebook et LinkedIn. La modélisation relationnelle qui s’appuie sur des tables bidimensionnelles dont l’une des dimensions est stable (le nombre et le type de colonnes) correspond alors mal à ce genre de besoin. D’autre part, comme nous l’avons vu dans l’article sur le sharding, les contraintes de volume de données et de nombre de transactions imposent souvent à ces acteurs de partitionner la donnée. Ce modèle rend caduque la vision traditionnelle dans le monde du TP d’une base transactionnelle avec une donnée en permanence cohérente. Les solutions de BI, enfin, sont dans nos SI majoritairement utilisées à des fins d’aide à la décision interne. Pour les grands du web, la BI est souvent le socle à de nouveaux services directement exploitables pour les utilisateurs : le service People You May Know de LinkedIn, les propositions de nouveaux morceaux sur des sites comme Last.fm[1], les recommandations d’Amazon sont autant de services nécessitant de manipuler d’énormes quantités de données pour fournir ces recommandations dès que possible aux utilisateurs.
Chez qui cela fonctionne ?
La nouvelle approche des grands du web au niveau TP et BI repose principalement sur un stockage généraliste et une approche favorisant les traitements différés. Ainsi, l’objectif principal du stockage sous-jacent est uniquement d’absorber d’énormes volumes de requêtes de façon redondante et fiable. Je le qualifie de généraliste car il est plus pauvre en termes d’indexation, d’organisation de la donnée et de cohérence que nos bases de données traditionnelles. **Le traitement, l’analyse de la donnée en vue de son requêtage et la gestion de la cohérence sont déportées au niveau applicatif.**Voici donc les stratégies qui sont mises en œuvre.
TP : La contrainte ACID limitée aux besoins strictement nécessaires
Le pattern sharding rend très complexe la vision traditionnelle d’une seule base de données cohérente utilisée pour le TP (Transaction Processing). Les grands acteurs comme Facebook et Amazon ont ainsi adapté leur façon de considérer la donnée transactionnelle. D’une part la cohérence n’est plus permanente mais uniquement assurée lors de la lecture de la donnée pour l’utilisateur. On parle de cohérence in-fine[2] : c’est à la lecture de l’information que d’éventuelles versions différentes au sein du stockage seront identifiées et les conflits résolus. Amazon a poussé cette démarche dès la conception de son système de stockage distribué Dynamo[3]. Sur un ensemble de N machines, la donnée est répliquée sur W d’entre elles avec une information de version. A la lecture N-W+1 machines sont interrogées, assurant de toujours fournir à l’utilisateur la dernière version[4]. Le géant du e-commerce a fait le choix de réduire la cohérence des données pour gagner en disponibilité sur son système distribué. En effet, comme le spécifie le théorème de CAP[5], il n’est pas possible d’avoir simultanément dans un système la cohérence, la disponibilité et la capacité à fonctionner en cas d’interruption réseau entre les instances (tolérance à la partition). D’autre part, pour répondre à ces enjeux de performances, les critères de fraîcheur de la donnée ne sont plus globaux mais catégorisés. Facebook ou LinkedIn conservent une fraîcheur temps réel sur les données mises à jour par l’utilisateur : ces modifications doivent être immédiatement visibles et durables pour que l’utilisateur ait confiance dans le système. En revanche, la consistance au niveau global est relâchée : lorsque l’utilisateur s’abonne à un groupe chez Facebook par exemple, il le verra immédiatement mais les autres membres du groupe sont susceptibles de voir son entrée dans le groupe avec un peu de retard[6]. Chez LinkedIn, les services sont également catégorisés. Dans des services non critiques, comme un retweet, l’information est propagée de façon asynchrone[7]. Au contraire, toutes les modifications effectuées par l’utilisateur sur ses données sont immédiatement propagées afin que celui-ci les voie apparaître à l’écran. Ce choix de traitement asynchrone leur permet de mieux gérer les forts trafics auxquels ils sont soumis. Au final, pour garantir la performance et la disponibilité, les grands du Web s’appuient sur des systèmes de stockage dont la cohérence est adaptée en fonction de l’usage. Ainsi l'objectif n’est pas nécessairement d’être cohérent à chaque instant, mais plutôt de garantir une cohérence à terme.
BI : Le mécanisme d’indexation à la base de toute recherche
Pour fournir des informations sur de vastes volumes de données, ces acteurs ont également l’habitude de pré-calculer des index, c'est-à-dire des structures de données conçues spécifiquement pour répondre aux types de questions offertes aux utilisateurs. Pour détailler ce point, nous allons nous intéresser à la construction de ces index par Google. Google est le premier exemple d’indexation par son ampleur : à la taille du web. Au niveau implémentation, Google utilise le sharding pour le stockage des données brutes (base de données colonne BigTable basée sur le système de fichier distribué Google File System[8]). Des index par mots clés sont ensuite produits de façon asynchrone et ce sont eux qui serviront à répondre aux requêtes des utilisateurs. Les données brutes sont analysées avec un algorithme distribué implémenté à partir du modèle de programmation MapReduce. Celui-ci repose sur un découpage en deux grandes phases : map() qui applique en parallèle un traitement identique à chaque donnée et reduce() qui agrège les différents résultats en un seul résultat final. La phase map() est aisément distribuable en envoyant chaque traitement (le rond bleu sur la figure suivante) et la donnée correspondante (chaque ligne bleu) sur une machine différente. 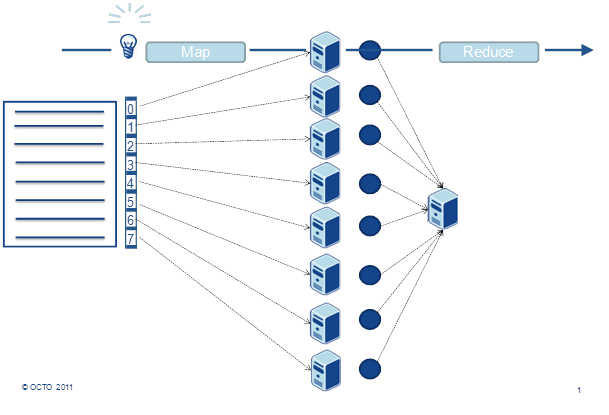
Exceptions
Ces exemples ont un point commun : ils ciblent des besoins assez spécifiques. Nombre de grands acteurs du web utilisent également des bases de données relationnelles pour d’autres applicatifs. Celles-ci, par leur approche généraliste (« One size fits all ») sont plus faciles à utiliser mais aussi plus limitées, notamment dans la scalabilité. Les modes de stockage distribué et les traitements décrits ci-dessus sont mis en œuvre uniquement sur les services les plus sollicités de ces acteurs.
Et dans mon entreprise ?
C’est sans doute sur les solutions d’indexation et de BI sur de gros volumes de données (Big Data) que le marché est le plus mature. L’existence d’une implémentation Open Source éprouvée, Hadoop, a permis le développement d’un grand nombre de solutions de support, d’outils connexes ou de ré-implémentations ou de repackaging commerciaux s’appuyant sur les mêmes APIs. Les projets nécessitant d’indexer de grandes quantités de données, ou des données semi ou non structurées sont donc les premiers candidats à l’utilisation de ce genre de méthode. Le principal avantage réside dans le fait que toutes les données sont conservées grâce à un stockage à plus faible coût. Il n’y a plus de perte d’information liée à des agrégations précoces. Ainsi, les algorithmes d’analyse de la donnée qui produisent des index ou des rapports peuvent également être affinés plus facilement au cours du temps car ils fonctionnent en permanence sur l’ensemble des données disponibles et non sur un sous-ensemble pré-filtré. La remise en cause de la base de données relationnelle dans le cadre du TP prendra probablement plus de temps. Différentes solutions distribuées inspirées des technologies des grands du web sont apparues sous le nom NoSQL (Cassandra, Redis). D’autres solutions distribuées, plus à la croisée des bases de données relationnelles et des grilles de données en termes de consistance et d’API, apparaissent sous le nom NewSQL (SQLFire, VoltDB). Des patterns architecturaux comme Event Sourcing et CQRS[14]peuvent également contribuer à établir des ponts entre ces différents mondes. En effet, ils permettent de modéliser les données transactionnelles comme un flux d’événements à la fois non corrélés et semi-structurés. La construction d’une vision globale et consistante de la donnée vient dans un second temps pour permettre de diffuser l’information. Les modèles des grands du web n’étant pas transposables directement pour les besoins TP généralistes d’une entreprise, de nombreuses approches coexistent encore sur ce marché pour répondre aux limites traditionnelles des bases de données.
Patterns associés
Ce pattern est principalement lié au pattern du sharding, d’une part parce qu’il rend possible par des algorithmes distribués le travail sur ce nouveau type de stockage. On remarquera également ici l’influence du pattern Build vs Buy qui a conduit les grands du web à adopter des outils très spécialisés pour leurs besoins.
Retrouver toutes les pratiques des Géants du Web sur le site dédié (www.geantsduweb.com) : pdf de l'ouvrage à télécharger, vidéo et compte-rendu de la présentation "Décrypter les secrets des Géants du Web"
[1] Hadoop, The Definitive Guide O’Reilly, juin 2009
[2] Eventual consistency
[3] http://www.allthingsdistributed.com/2007/10/amazons_dynamo.html
[4] Ainsi on est certain de toujours lire la données sur au moins une des W machines sur laquelle la donnée la plus fraîche a été écrite. Pour plus d’information se référer à http://www.allthingsdistributed.com/2007/10/amazons_dynamo.html
[5] http://en.wikipedia.org/wiki/CAP_theorem
[6] http://www.infoq.com/presentations/Facebook-Software-Stack
[7] Interview de Yassine Hinnach
[8] Voir le pattern sharding
[9] Ou capable de passage à l’échelle, c’est-à-dire la capacité à traiter plus de données en faisant croître le système
[10] http://research.google.com/archive/mapreduce.html
[11] http://hadoop.apache.org/
[12] http://wiki.apache.org/hadoop/PoweredBy
[13] Google Percolator http://research.google.com/pubs/pub36726.html
[14] Command and Query Responsibility Separation