Tour d'horizon du Cold Start avec AWS Lambda
Le serverless apporte de nombreux bénéfices pour le déploiement d’applications web comme l’autoscaling, la disponibilité et le fait d’avoir une granularité très fine sur les coûts (facturation aux 100ms pour AWS lambda). Et bien entendu l’absence de gestion des serveurs (installations, patches,...). Cet article a pour objectif de faire un état des lieux sur le cold start et le warm call avec AWS Lambda pour différentes implémentations de code, tout en s’appuyant au maximum sur des mesures.
Le serverless est un terme ambigu qui laisse entendre qu’il n’y a plus de serveurs : ce n’est pas le cas ! Le terme adapté aurait pu être server [management]less mais il faut croire que cela paraissait moins vendeur. Toujours est-il que le serverless englobe 2 notions à la fois différentes et se chevauchant. Comme l'a défini Mike Roberts dans son article sur le serverless :
Le terme serverless a d’abord été utilisé pour décrire des applications qui incorporent de nombreux services tiers pour gérer la logique backend et la gestion de l’état. Ces services sont aussi connus sous le terme Backend as a Service. Serverless peut également désigner des applications ou la logique serveur est toujours codée par des développeurs mais, contrairement aux architectures traditionnelles, est exécutée dans un conteneur stateless, éphémère et entièrement géré par un tiers. Traduit de l'article "Serverless Architecture", Mike Roberts
Présentation cold start / warm call
Pour comprendre ce qu’est le cold start et comment il impacte du code FaaS, il faut commencer par regarder comment fonctionne le Function as a Service et notamment le service AWS Lambda. Le talk de Chris Munns au AWS re:invent 2017 donne une bonne introduction sur le sujet. Voici donc les principales étapes de l'exécution d’une Lambda. Tout d’abord, il faut créer et configurer la Lambda : à cette étape, le code à exécuter ainsi que la configuration des ressources de la Lambda sont simplement stockés. Ensuite, lors de l'exécution de la lambda, un conteneur est monté avec les ressources définies par la configuration et le code est chargé en mémoire pour être exécuté. Le laps de temps qui correspond au chargement du code, à la création du conteneur et à l’amorçage est appelé “cold start” ou encore “initialisation de la Lambda”. Schématiquement voilà ce que ça donne : 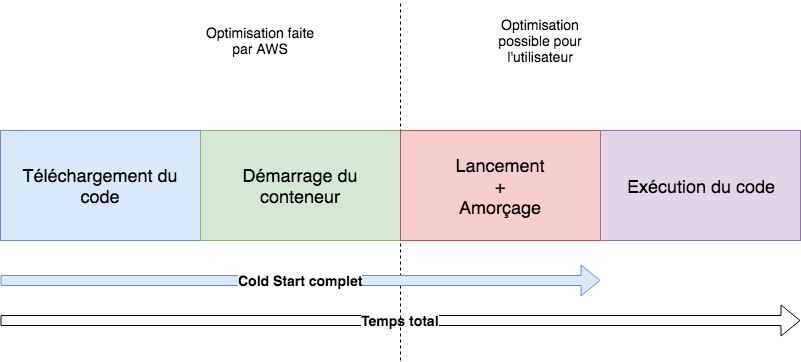
Ce schéma montre qu’une partie du cold start est gérée par AWS (chargement du code, création du conteneur) et donc que les possibilités d’optimiser le cold start sont limitées.
Le temps d’initialisation d’une Lambda représente une partie non négligeable du temps total. Après un cold start, la Lambda va rester instanciée un certain temps (5 minutes). Les appels effectués pendant cette période sont appelés “warm call”, cela signifie que le code est chargé en mémoire et prêt à être exécuté dès l’appel de la Lambda. Schématiquement voici à quoi cela ressemble : 
Le cold start a donc un impact sur le temps d'exécution du code d’une application. Cet impact est-il significatif ? Y-a-t-il des moyens de le minimiser ?
Impact du cold start sur un code simple
Pour avoir une idée de l’impact d’un cold start sur le temps d’exécution, les mesures ont été prises sur 2 Lambdas renvoyant un “Hello world”. L’une écrite en Java, l’autre en NodeJS. Les ressources mémoire allouées pour chacune des Lambda étaient de 128MB. Voici les résultats de ces mesures :
Dans les 2 cas, le cold start augmente le temps d'exécution de la Lambda. Le temps mesuré est celui du lancement + amorçage de la Lambda et du temps d'exécution. Ensuite, il est à noter que le langage utilisé à une incidence sur le temps d'exécution lors d’un cold start et que de manière générale les langages Java et C# s’en sortent moins bien que Go, Python et Node. D’autre part, la partie montage des conteneurs est optimisée par AWS et n'apparaît pas sur ces graphes, ce qui laisse entendre que Java est beaucoup plus lent que Node pour exécuter un “Hello world”. Cela parait surprenant, mais cela s’explique en grande partie à cause du fait que le code Java à exécuter est contenu dans un fat jar. Ce qui signifie qu’un certain temps est consommé à parcourir le code et charger la JVM.
Néanmoins, comme Yan Cui l’a démontré dans son article Comparing AWS Lambda Performance les mauvaises performances des langages Java et C# lors du cold start sont à réajuster avec leurs bonnes performances lors des warm calls.
De plus, la configuration des ressources allouées à la Lambda ont un impact sur le temps d’exécution. La configuration des Lambdas pour la mémoire peut varier de 128 à 3008 MB. Il faut aussi noter que les ressources CPU sont liées au choix des ressources mémoire, par exemple, une Lambda de 256MB aura 2 fois plus de CPU qu’une Lambda de 128MB. De manière très synthétique, en augmentant les ressources le temps d’exécution diminue, mais cela n’est pas un règle vérifiable dans tous les cas. Dans l’exemple du code renvoyant un “hello world”, cela se vérifie pour le code Java mais c’est moins évident pour le code Node pour lequel il n’y a quasiment pas de gain entre 512MB et 1024MB.
D’autre part, les coûts augmentent en fonction des ressources ce qui nécessite de faire une étude sur le rapport prix/temps/qualité du service. AWS a mis en ligne un outil qui permet d’estimer le coût des appels Lambda.
Impact du cold start sur une application
Faire des mesure sur un code “hello world” permet d’avoir les premières indications sur le temps d’exécution d’une Lambda et d’avoir des pistes d’optimisation pour l’améliorer. Mais, cela reste basique, c’est pourquoi dans cette partie il sera question de faire des mesures sur un code plus élaboré.
Le code utilisé pour faire les mesures est une application très simple qui prend en entrée une requête HTTP et ensuite va lire une base de données pour renvoyer les données lues en réponse, le code est disponible ici. Voici un schéma pour visualiser les composants de l’application et leurs interactions : 
Ce code a été implémenté dans deux langages différents Java et Node, ainsi qu’avec différents frameworks (springboot, springcloudfunction, express) et sans framework.
Que faut-il retenir de ces graphes ?
Globalement, ajouter un framework pour structurer le code déployé dans la Lambda augmente le temps d’exécution de la Lambda. Pour les langages interprétés comme javascript cette augmentation du temps d’exécution est visible, mais sans avoir un impact trop négatif pour l’utilisateur (120 ms pour du node contre 180 ms pour du express). Pour les langages comme Java c’est une autre histoire. Le cold start a plus d’impact sur du code Java et cela se répercute sur l’utilisation d’un framework jusqu’à être très pénalisant pour l’utilisateur avec des temps de cold start supérieurs à 10 secondes. La comparaison entre différents frameworks montre que l’utilisation d’un framework orienté serverless comme spring cloud function permet de diminuer le temps d’exécution par rapport à un framework web comme springboot. En ce qui concerne les warm calls, l’utilisation d’un framework a très peu d’impact sur le temps d’exécution, les mesures montrent qu’en moyenne un appel à chaud s'exécute en 30 millisecondes avec des variations d’une dizaine de millisecondes.
Passer d’un code simple à une application web entraîne une forte augmentation du temps d’exécution. La question qui peut se poser est de savoir où passe ce temps. Voici donc quelques mesures supplémentaires pour y apporter des réponses. 
En mesurant le temps d'initialisation de SpringContext lors d’un cold start et lors d’un warm call, il apparaît que dans le cas ou SpringContext est démarré et exécuté dans une Lambda déjà initialisée, le framework démarre plus rapidement. Ce n’est donc pas le framework en lui-même qui pénalise le cold start, mais plutôt l’initialisation de la JVM qui est lié à la taille du jar déployé dans la Lambda. Cela explique aussi le faible impact d’express dans le cas d’une application en javascript. 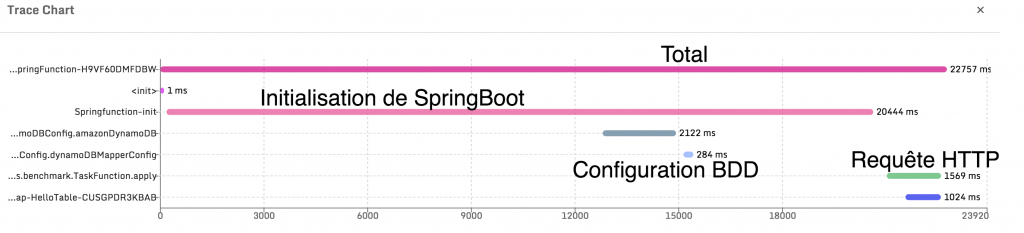
Le détail des temps ci-dessus montre que si ce n’est pas Spring qui est lent à s'exécuter, le fait d’ajouter des librairies (spring-boot-starter-web, spring-data-dynamo, etc.) rend l’ensemble long à initialiser au cold start. Une optimisation possible serait donc de nettoyer les dépendances pour ne garder que l’essentiel. Dans le cas de l’utilisation du framework Spring cela demande d’y passer beaucoup de temps pour garder un code fonctionnel en retirant un maximum de dépendances.
À partir de ces mesures, une conclusion s’impose, le cold start est à éviter dans une application destinée à des utilisateurs et ce d’autant plus lorsque l’application est développée dans un langage comme Java.
Présentation keep warm
Le cold start représente donc un inconvénient quant à la mise en place d’application serverless, puisque cela induit un temps d’attente au premier appel pour l’utilisateur. Un contournement a donc été mis en place dans les applications serverless pour éviter que les utilisateurs ne subissent trop de cold start, cette technique peut prendre le nom de “keep warm” ou “keep alive” selon les articles. Le cold start est dû au fait que la Lambda a une durée de vie fixe de 5 minutes, ce qui veut dire qu’au-delà de 5 minutes la Lambda n’est plus allumée. Donc, après 5 minutes la Lambda doit être initialisée de nouveau. Le principe est simple, puisque que le but est d’empêcher la Lambda de s’éteindre, il faut mettre en place un cron qui invoque la Lambda à intervalle régulier pour qu’elle reste allumée. Schématiquement, cela peut être représenté de la façon suivante : 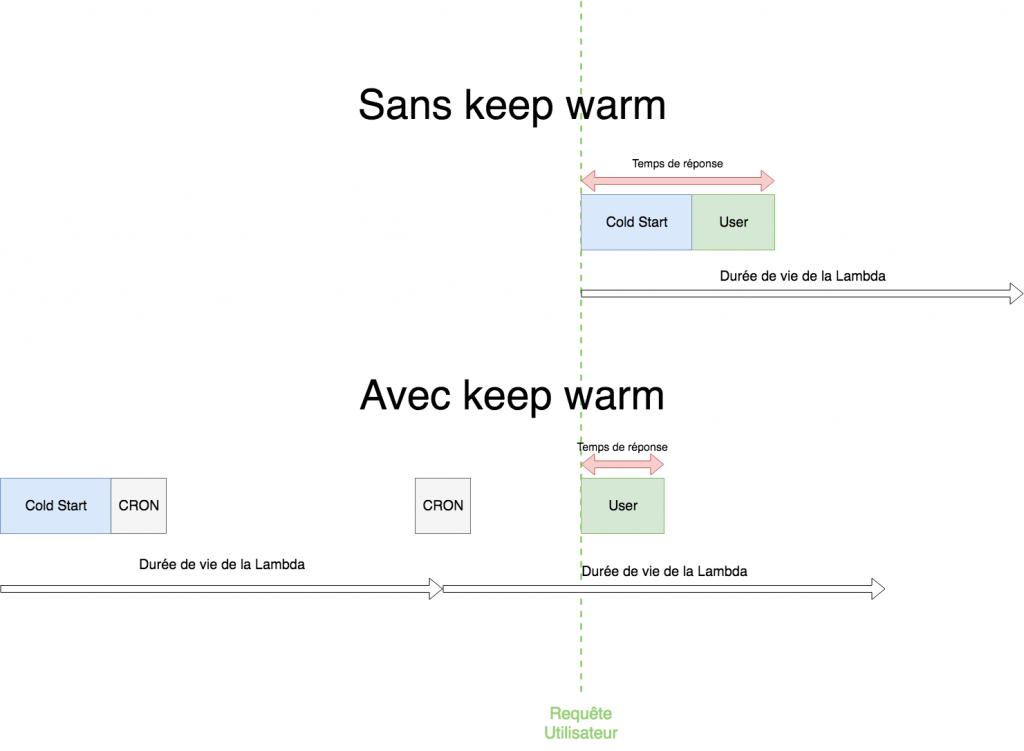
Cette technique du keep warm semble donc répondre au problème du cold start, mais il faut tenir compte de certaines limites liées à AWS Lambda. La première est que la Lambda sera réinitialisée toute les 4 heures même en faisant du keep warm. La seconde est qu’il faut tenir compte de l’autoscaling d’AWS.
Le keep warm et les appels concurrents
L’un des avantages de développer des applications en serverless est la gestion automatique de l’autoscaling. Cela signifie qu’en cas d’appels concurrents, la charge sera répartie sur plusieurs Lambdas. Mais chaque nouvelle Lambda initialisée correspond à un temps d’attente plus long pour l’utilisateur à cause du cold start. Voici un exemple simple qui illustre le cas des appels concurrents (cet exemple ne représente pas le fonctionnement réel de l’autoscaling des Lambdas, mais sert à comprendre son comportement) 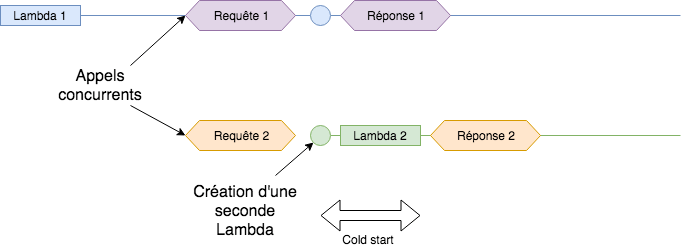
Une façon d’éviter les cold start avec le keep warm dans le cas d’appels concurrents consiste à créer un pool de Lambdas qui sont maintenues allumées pour pouvoir traiter des appels concurrents en évitant les cold start. Le même exemple que plus haut avec un pool de Lambdas et du keep warm donne donc ceci : 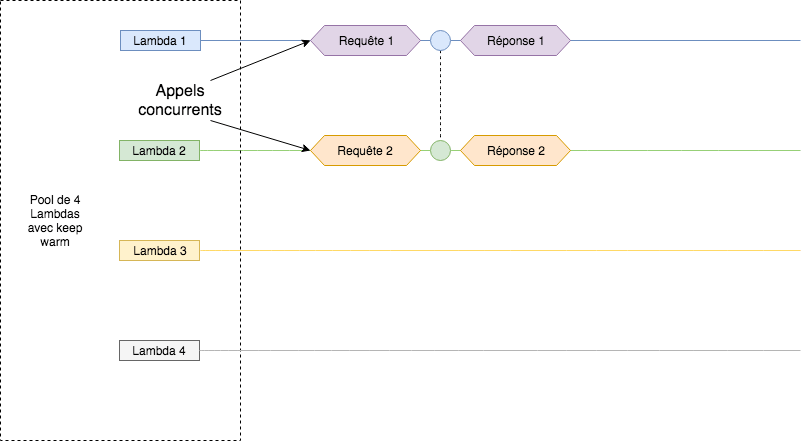
Faire des pools de Lambdas avec du keep warm permet de diminuer les probabilités pour un utilisateur de subir un cold start lors d’appels concurrents. Mais, cette technique à un inconvénient, s’il n’y a pas ou peu d’appels concurrents, des Lambdas sont maintenues allumées alors qu’elles n’effectuent aucun traitement. Il faut donc déterminer le nombre optimal de Lambda par pool afin de ne pas maintenir allumé des Lambdas inutilement. De plus, cela à un coût, le keep warm consistant à faire des appels sur une Lambda à intervalles réguliers, chacun des appels seront facturés. Dans le cas d’un pool les coûts sont donc multipliés par le nombre de Lambdas qui le constitue. Cela reste à mettre en perspective avec d’autres infrastructures comme des EC2 ou des conteneurs Fargate. Le graphe suivant permet de voir que pour une petite application (avec moins de 5 millions de requêtes par mois) l’utilisation de Lambda reste avantageuse. 
Frameworks serverless et outils de monitoring
Le keep warm est apparu comme un contournement permettant de maintenir des Lambdas allumées en déclenchant des événements avec une autre Lambda. Cela nécessite de créer une Lambda qui sera en charge de faire ces appels ou alors de créer un évènement CloudWatch pour chaque Lambda à maintenir allumée. Depuis les débuts de cette technique, les frameworks et les outils autour du serverless ont proposé leur propre manière d’implémenter le keep warm de façon à ce que cela nécessite peu de configuration et de code à écrire pour pouvoir le mettre en place.
Par exemple, thundra.io qui est un outil de monitoring pour AWS Lambda permet, entre autre, d’avoir des métriques et du tracing sur les Lambdas déployées, mais aussi de faire du keep warm pour limiter les cold start dans une application web en serverless. Thundra n’est pas le seul outil/framework qui permet d’implémenter le keep warm, cela existe avec serverless et Zappa notamment.
Actuellement, thundra est en version beta et son utilisation est gratuite dans la limite de 1000 requêtes par minute. Dans un environnement en production il faut aussi tenir compte du coût d’un service comme thundra. Comme cela est décrit dans cet article, le keep warm n’a pas vocation à éviter tous les cold start mais, à minimiser son impact dans le cas d’une application web serverless. L’approche de Thundra pour le keep warm nécessite de jouer sur 2 paramètres qui sont : le nombre de Lambda dans la pool de Lambda en keep warm et le laps de temps entre les appels pour maintenir les fonctions allumées. 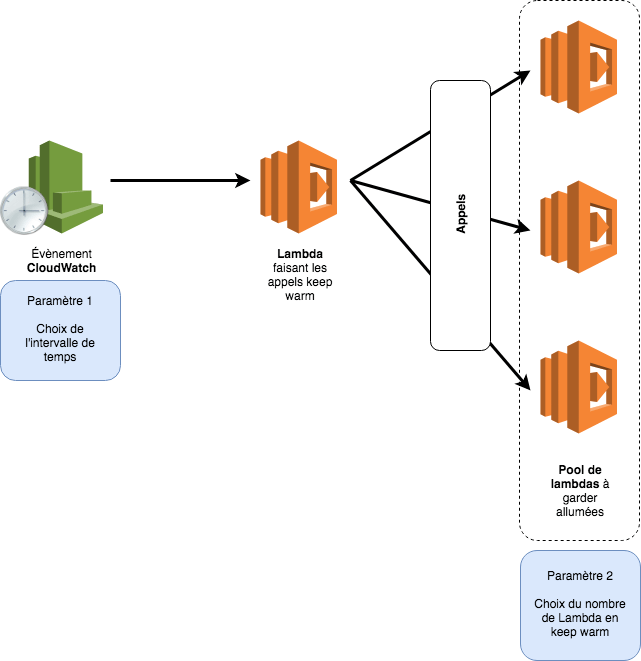
Par défaut, Thundra va créer un pool de 8 Lambdas et envoyer un événement toutes les 5 minutes. Pour créer un pool de lambda et s’assurer de les garder allumées, il faut que la Lambda en charge du keep warm fasse des appels sur les Lambdas cibles. Le code des Lambda présentes dans la pool doit gérer les requêtes de type keep warm différemment. Dans ce cas, le code déclenche un sleep pour que la Lambda paraisse occupée et que la requête suivante soit envoyée sur une autre lambda du pool. En récupérant, l’id de chaque Lambda, il est possible de s’assurer que toutes les Lambdas du pool soient maintenues allumées.
Avec cette configuration, sur 5 appels concurrents de 5 requêtes, Thundra enregistre 5 cold start alors qu’avec le keep warm les Lambdas ne le subissent pas. Après avoir mis en place cette technique sur le code de test et avec l’aide de l’outil Thundra pour avoir des retours de mesures. Voici le détails des invocations (avec et sans cold start). 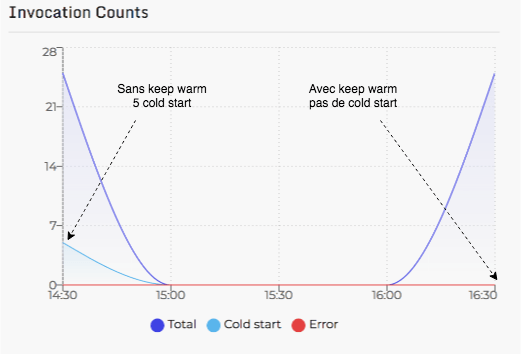
Pour conclure, le cold start a un impact important sur les applications serverless destinées à des utilisateurs. Le cold start peut être minimisé grâce à la technique du keep warm mais cela nécessite encore des efforts de la part des développeurs pour optimiser cette technique. Les outils intègrent de plus en plus la mise en place du keep warm de façon automatisée. Pour le moment, cela reste encore primaire, mais il faut garder en tête que ces outils sont jeunes et avec le temps, ils gagneront en maturité et proposeront des solutions plus robustes.
Liens et sources : Articles:
- https://martinfowler.com/articles/serverless.html
- https://read.iopipe.com/understanding-aws-lambda-coldstarts-49350662ab9e
- https://theburningmonk.com/2017/06/aws-lambda-compare-coldstart-time-with-different-languages-memory-and-code-sizes/
- https://medium.com/thundra/dealing-with-cold-starts-in-aws-lambda-a5e3aa8f532
- https://read.acloud.guru/comparing-aws-lambda-performance-when-using-node-js-java-c-or-python-281bef2c740f
- https://blog.symphonia.io/the-occasional-chaos-of-aws-lambda-runtime-performance-880773620a7e
Vidéos: