Thrift et Protocol Buffers : compacité du message sérialisé dans le monde Java
Un précédent article a exposé les grands principes de la sérialisation avec Thrift et Procotol Buffers. Ces deux frameworks promettent notamment une représentation des messages optimisée en termes de taille, ce qui est avéré dans le benchmark JVM Serializers : Thrift et Protocol Buffers y obtiennent une réduction de taille du message de 73% par rapport à la sérialisation native Java. Ce benchmark regroupe par ailleurs de nombreux autres frameworks de sérialisation du monde Java, mais se limite toutefois à l'utilisation d'un unique message de test.
Le présent article analyse l'influence de la structure (nombre et taille des objets, complexité de la grappe) sur la compacité du message sérialisé pour Thrift et Protocol Buffers. La comparaison est réalisée en Java, son protocole de sérialisation standard servant de référence.
Conditions du test
Afin d'évaluer diverses structures de messages, le prototype utilise une structure arborescente. Traditionnellement, ce type de structure est récursif. Cependant, il n'est pas compatible avec la limitation de Thrift sur la déclaration avancée abordée dans le précédent article. La profondeur a donc été arbitrairement limitée au niveau 6, soit 127 nœuds au maximum pour un arbre binaire complet. Il y a un type différent par profondeur, de Node0 pour la racine à Node6 pour les feuilles les plus basses. Les arbres générés le sont selon trois paramètres :
- le nombre total de nœuds, qui permet de faire varier le nombre d'objets du message,
- la cardinalité des fratries , qui joue sur la complexité : plus cette cardinalité est faible pour un nombre de nœuds donné, plus les fratries sont petites et nombreuses, donc plus le message est complexe,
- et la taille des nœuds, qui est fonction du champ "description". Son contenu est une chaîne de caractères différente pour chacun d'eux et générée par décalage des valeurs Unicode des caractères.
La construction des arbres se fait récursivement et équitablement entre les fils d'un nœud. Ci-dessous trois exemples d'arbre à 5 nœuds avec, de gauche à droite, des tailles de fratries de 1, 2 et 3. Les numéros sont présents à titre indicatif et indiquent l'ordre de création des nœuds par l'algorithme de construction. 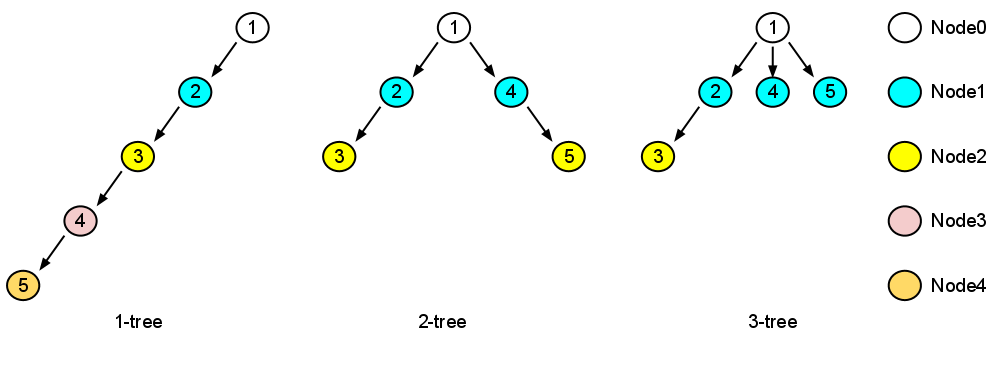
Les déclarations dans les IDLs Thrift IDL et Protocol Buffers language sont disponibles en fin d'article. Les versions utilisées sont 0.8.0 pour Thrift, 2.4.1 pour Protocol Buffers et HotSpot 1.6.0_29 pour la JVM.
Impact du nombre d'objets du message
Dans un premier temps, la complexité est fixée au minimum :
- La longueur des descriptions de chaque nœud est constante (32 caractères),
- le nombre de nœuds est variable,
- la structure choisie est le 1024-tree qui équivaut à un arbre à deux niveaux dans cette étude.
En effet, si la cardinalité des fratries est supérieure au nombre de nœuds n, on obtient un arbre à deux niveaux, une racine Node0 et n-1 enfants Node1. Les 1024-trees de cet article ont tous cette structure car n est toujours inférieur à 1024.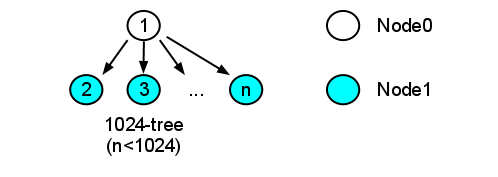
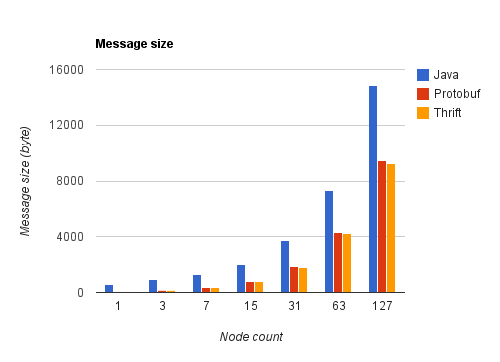
Le graphique ci-dessous rapporte leurs résultats à ceux de la sérialisation Java. On constate que leur avantage en termes de taille de message s'amenuise à mesure que l'arbre grossit.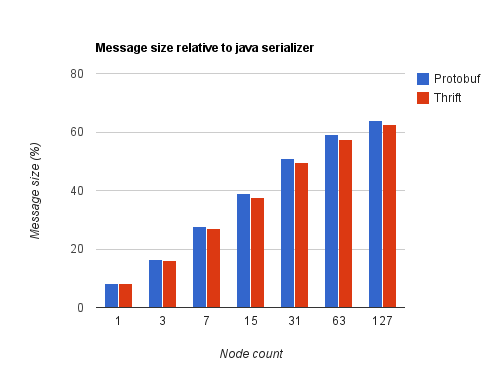
Sur le graphique suivant, on observe que la taille moyenne d'un nœud décroît rapidement pour la sérialisation Java. En effet, le protocole de sérialisation Java ajoute aux informations du message lui-même la description des classes sérialisées. Ce surcoût, important pour un petit message, devient négligeable pour des messages constitués de nombreux objets du même type.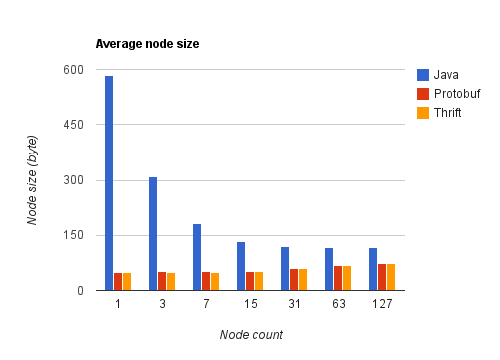
Impact de la taille des objets
Pour ce second test, on fige la structure du message pour mesurer l'influence de la quantité d'information contenue dans chaque nœud :
- Un 1024-tree est considéré comme dans le test précédent,
- sa taille est fixée à 31 nœuds,
- la taille du champ "description" est utilisé comme variable.
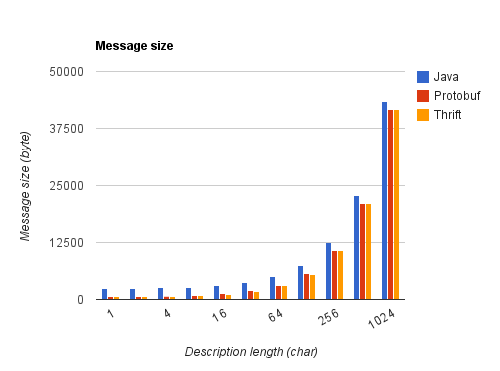
Impact de la structure du message
Pour évaluer l'influence de la structure du message :
- la description de chaque nœud est fixée à 32 caractères,
- le nombre de nœuds est variable,
- la cardinalité des fratries prend trois valeurs : 2, 4 et 1024.
Par exemple, voici les trois variations considérées de l'arbre à 7 nœuds : 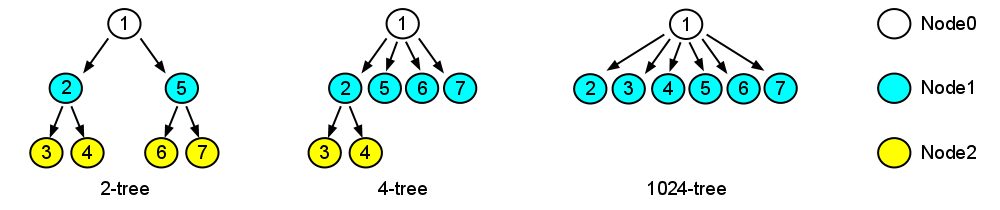
Le graphique qui suit recense les tailles des messages sérialisés.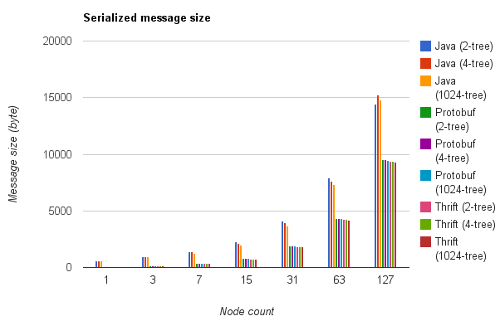
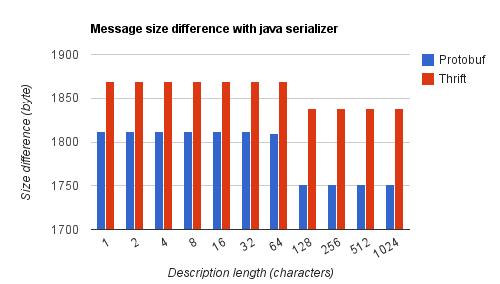
Le protocole de sérialisation Java est lui plus fortement influencé (jusqu'à 13%). En effet la quantité d'information utilisée par les descripteurs de classes est liée au nombre de types de classes mises en jeu. Plus les fratries sont grandes, moins on utilise de classes différentes. Par exemple, pour 63 nœuds, le 2-tree utilise toutes les classes de Node0 à Node5, le 4-tree s'arrête à Node3, et le 1024-tree à Node1. Le résultat particulièrement bon du 2-tree de taille 127 est lié au fait que Node6 n'a pas de liste d'enfants et est donc plus compact que les autres types de Nodes. Dans cet arbre, la majorité des nœuds (64) est de type Node6.
Les tailles moyennes par nœud sont représentées dans l'histogramme ci-dessous :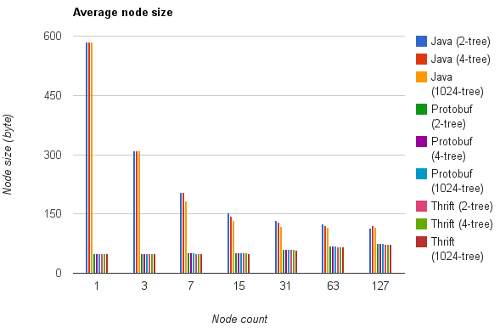
En traçant le gain apporté par les deux frameworks par rapport à la sérialisation Java on obtient :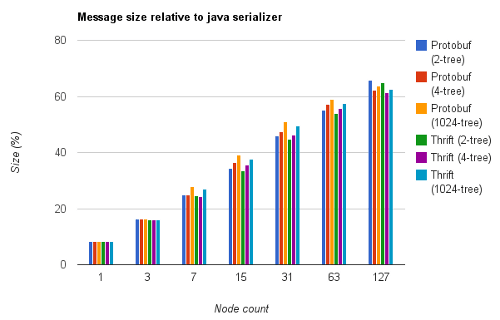
Par exemple, en considérant le message du 4-tree à 63 nœuds et un système devant soutenir une charge de 10000 requêtes/s, le remplacement de la sérialisation Java par Thrift permet de diminuer le besoin de bande passante de 75.45 Mo/s à 40.68Mo/s, soit un gain de 46%.
Conclusion
Cet article a présenté une comparaison portant sur la taille de sérialisation avec des messages complexes. Par rapport au benchmark JVM-serializers, l'avantage de Thrift et protobuf sur la sérialisation native Java est moins décisif en termes de compacité, même s'il reste intéressant.
La taille du message sérialisé par Thrift ou Protocol Buffers n'est pas influencée par la structure même du message. C'est surtout son volume qui a un impact : les deux frameworks offrent une sérialisation bien plus compacte que celle de Java surtout sur de petits messages. Cette observation rejoint le fait que Protocol Buffers n'est pas particulièrement adapté aux volumes de données importants.
Il faut rappeler qu'employer la sérialisation native Java comme référence n'est légitime que parce que cet article se limite aux protocoles de sérialisation. Thrift et Protocol Buffers offrent d'autres avantages tels l'interopérabilité avec plusieurs langages et la compatibilité ascendante et descendante des messages. Ils sont abordés dans l'article précédent.
Pour aller plus loin, on pourrait analyser les temps de sérialisation, l'empreinte mémoire, l'intégration aux processus de build...
Annexes
Voici la déclaration des objets en Thrift IDL : tree.thrift
namespace java com.octo.example.serialization.model.thrift
enum RoomType {
SINGLE =0,
DOUBLE =1,
SUITE =2
}
struct Node6 {
1: optional i32 number,
2: optional bool even,
3: optional double rate,
4: optional RoomType type,
5: optional string description,
}
struct Node5 {
1: optional i32 number,
2: optional bool even,
3: optional double rate,
4: optional RoomType type,
5: optional string description,
6: list children,
}
[...]
et ainsi de suite jusqu'au Node0, qui correspond la racine de l'arbre. L'ordre employé évite le recours à la déclaration avancée.
Ci-dessous, l'équivalent en Protocol Buffers language : tree.proto
package serialization;
option java_package = "com.octo.example.serialization.model";
option java_outer_classname = "LimitedTreeProto";
enum RoomType {
SINGLE =0;
DOUBLE =1;
SUITE =2;
}
message Node0 {
optional int32 number =1;
optional bool even =2;
optional double rate =3;
optional RoomType type =4;
optional string description = 5;
repeated Node1 children = 6;
}
[...]
message Node6 {
optional int32 number =1;
optional bool even =2;
optional double rate =3;
optional RoomType type =4;
optional string description = 5;
}
L'ordre des nœuds plus naturel est supporté par le compilateur Protobuf.