The lo(n)g way to Loki
Dans cet article, nous vous proposons de faire un modeste tour de Loki, une solution d'agrégation de log, afin de partager notre retour d’expérience sur cet outil. Nous espérons, au travers de cet article, aider toutes les personnes qui cherchent à déployer une architecture Loki prod-ready en y partageant nos réflexions et un exemple fonctionnant sur AWS.
Cet article a été réalisé avec la version 1.6.0 de Loki.
Le besoin
Sur notre projet actuel, nous avons des applications qui tournent sur un cluster Kubernetes. Un combo Fluent-Bit/Fluentd se charge de récupérer les logs et d’effectuer divers traitements dessus avant de les envoyer à un Elasticsearch. Un Kibana surplombe le tout pour l’accès aux logs.
Il a premièrement fallu choisir une stratégie d’indexation pour nos logs :
- Index de logs journaliers,
- Rétention des logs d'une durée d'un mois,
- Logs indexés par namespace kubernetes (des indexes par applications auraient été préférables mais plus il y a d’index plus il y a consommation de mémoire vive).
Ces spécifications devaient nous permettre de cloisonner les accès aux logs et limiter la taille des machines Elasticsearch. Cependant, la quantité de ressources allouées à ce dernier ne cessait de grossir, à un point où cela devenait irrationnel par rapport à la quantité de logs traités.
La question s’est donc posée : existe-t-il une solution moins coûteuse qu’Elasticsearch pour gérer nos logs ? C’est ainsi que nous avons décidé d’essayer Loki.
Description de Loki
Loki est une solution d'agrégation de logs, scalable horizontalement, à haute disponibilité et multi-tenant. Ce produit est développé par Grafana Labs et s’appuie sur leur produit éponyme pour l’affichage des logs. L’une des principales informations à savoir sur Loki est que seules les métadonnées de vos logs sont indexées. C’est ce qui le différencie d’Elasticsearch et qui lui permet aussi de consommer moins de ressources que ce dernier.
Concrètement cela signifie qu’il est impossible de chercher les logs qui ont le champs `level` valant `error`. Loki vous permet seulement de chercher les logs qui contiennent `level` et `error`. Cela revient à avoir accès aux logs et à rechercher ce qui nous intéresse à coup de `grep`. Loki introduit aussi un nouveau langage pour requêter vos logs : le LogQL.
Si Loki vous intéresse toujours, il est temps de le déployer pour la première fois !
Déploiement d’une instance Loki de test
Pour tester et vous familiariser avec les fonctionnalités de Loki, vous pouvez déployer Loki à partir de l'exemple fourni dans leur documentation. Étant beaucoup plus familier avec Helm que Tanka pour le templating de manifestes Kubernetes, c’est le dossier production/helm du dépôt de code de Loki qui va nous intéresser ici.
Installons tout ça :
helm repo add loki https://grafana.github.io/loki/charts helm repo update helm upgrade --install loki loki/loki-stack --set grafana.enabled=true --set grafana.adminPassword=demo
On se retrouve ainsi avec Promtail, Loki et Grafana déployés :
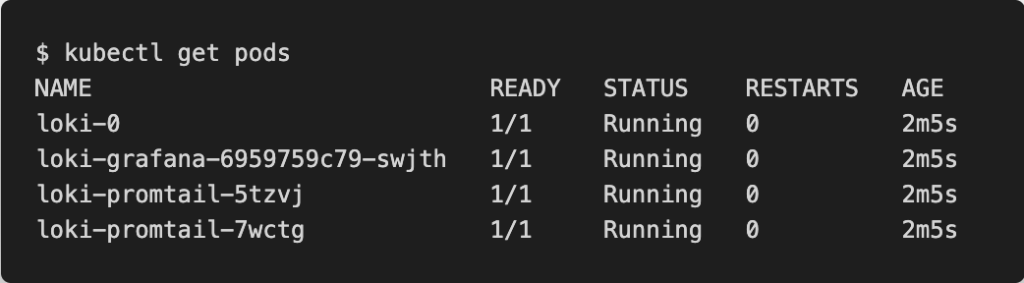
Promtail est la solution proposée par Grafana Labs pour collecter et envoyer les logs au pod Loki. Fluent-bit ou Fluentd peuvent se substituer à Promtail mais pour l’exemple, nous utiliserons Promtail. Il y a 2 pods Promtail car ce dernier est déployé sous la forme d’un DaemonSet et notre cluster dispose de 2 noeuds.
Le pod Loki stocke les logs envoyés par Promtail et le pod Grafana permet d’accéder à nos logs depuis notre navigateur, à l’aide d’un port-forward sur le service :
kubectl port-forward service/loki-grafana 3000:80
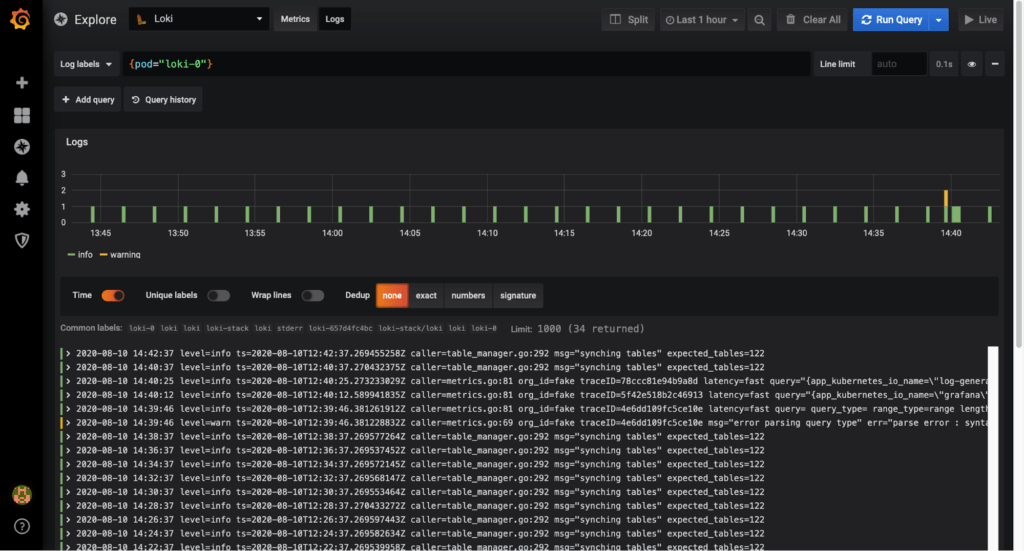
Dans cet exemple, nous avons déployé la version 7 de Grafana. À partir de la version 6, Grafana intègre la datasource de type Loki qui nous permet donc, une fois configurée, d’accéder aux logs dans l’onglet Explore. Ci-dessous, les logs du pod loki-0 :
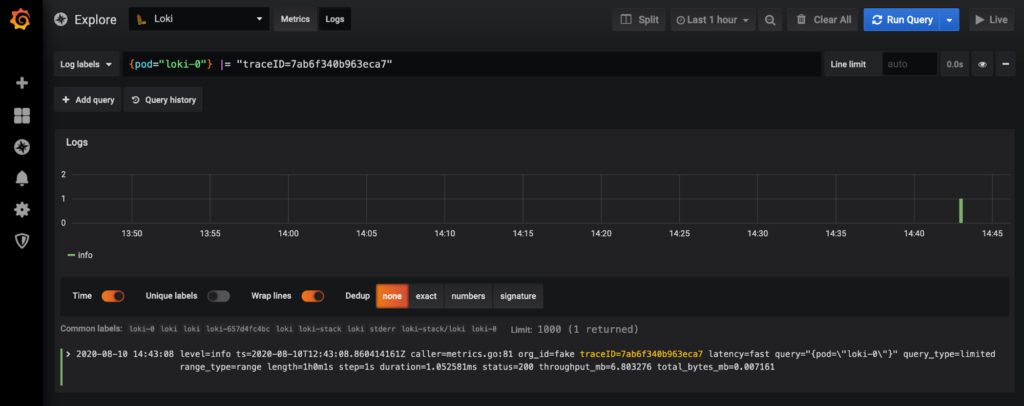
Si nous souhaitons n’avoir que les logs pour lesquels le champs traceID vaut 7ab6f340b963eca7, la requête LogQL devient :
Maintenant que nous avons vu comment l’accès aux logs et la recherche se font, il est temps de s'intéresser à la scalabilité, la haute disponibilité et la gestion du multi-tenant, pour avoir une architecture “production ready”.
Pour l’instant, l’exemple n’est rien de tout ça. En effet, le pod Loki déployé par le chart Helm joue plusieurs rôles différents qu’il est nécessaire de séparer pour rendre Loki scalable.
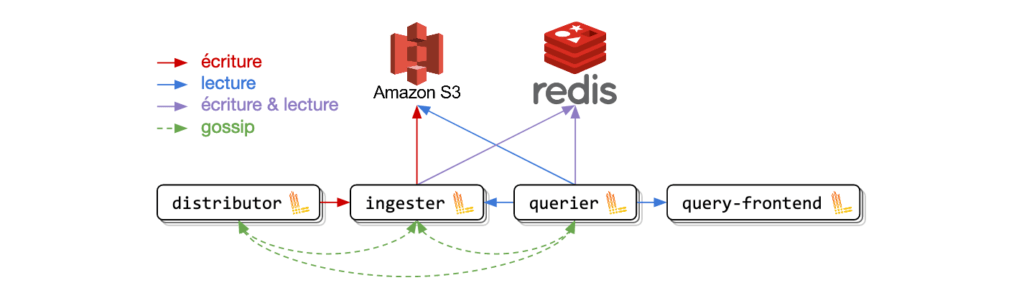
Architecture scalable
Une architecture inspirée de Cortex
Pourquoi parlons-nous de Cortex ?
Car, Grafana Labs en a repris l’architecture pour Loki. Ainsi, vous trouverez parfois des informations utiles dans la documentation ou dans les issues de Cortex qui ne sont pas présentes dans celle de Loki.
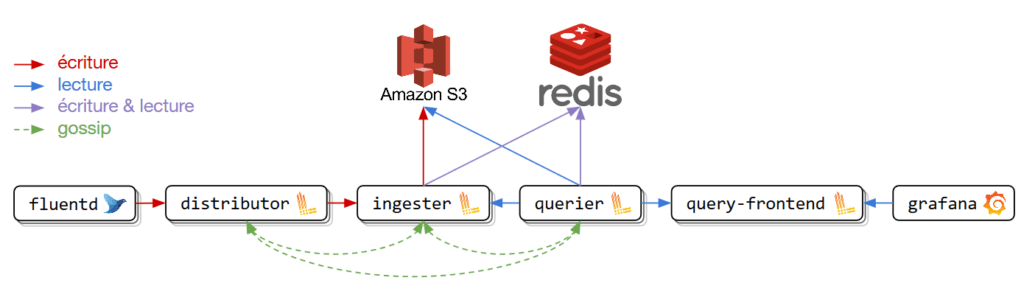
Jusqu’à présent, dans l’exemple déployé, un seul pod Loki était créé et portait plusieurs rôles : distributor, ingester, querier et table-manager. Pour avoir une architecture scalable et optimiser les ressources du cluster, ce mode de fonctionnement est impossible car il est nécessaire de pouvoir scaler individuellement chacun de ces composants.
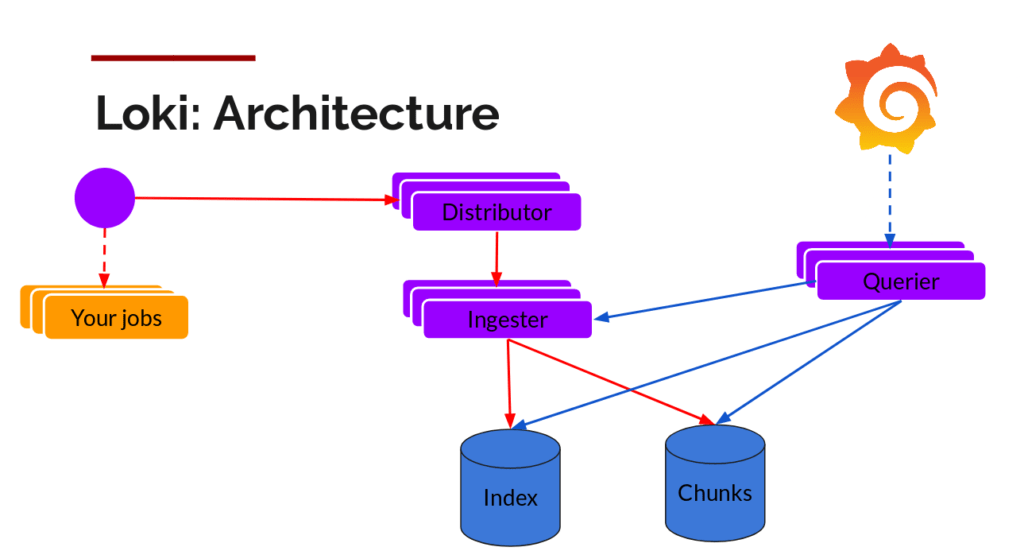
Dès lors que vous utilisez Loki, il est fondamental de lire la documentation qui présente les différents rôles de celui-ci : https://grafana.com/docs/loki/latest/architecture. Toutefois, pour la lecture, simplifions les rôles principaux de la manière suivante :
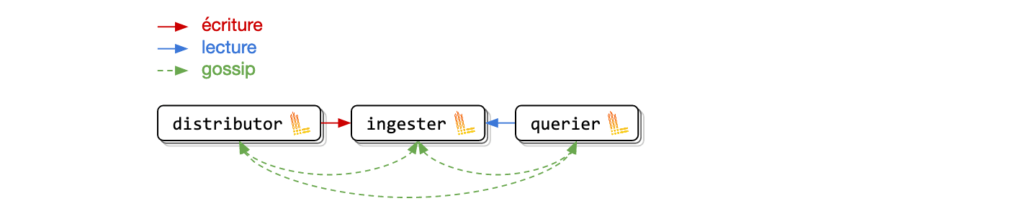
- Le distributor : Il reçoit les logs du collecteur et va les envoyer sur un ou plusieurs ingesters en fonction de la réplication désirée.
- L’****ingester : Il reçoit les logs du distributeur et se charge de leur persistance.
- Le querier : Il reçoit les requêtes en LogQL et va récupèrer les données où elles sont stockées pour remonter les résultats.

Quelle base clé-valeur pour stocker l’état de Loki ?
Pour Loki, l’état à stocker est ce qui est appelé le “hash ring” ou “ingester ring”. Pour simplifier, cela permet aux distributors de connaître l’état des ingesters et donc de savoir à quel ingester envoyer quelle donnée.
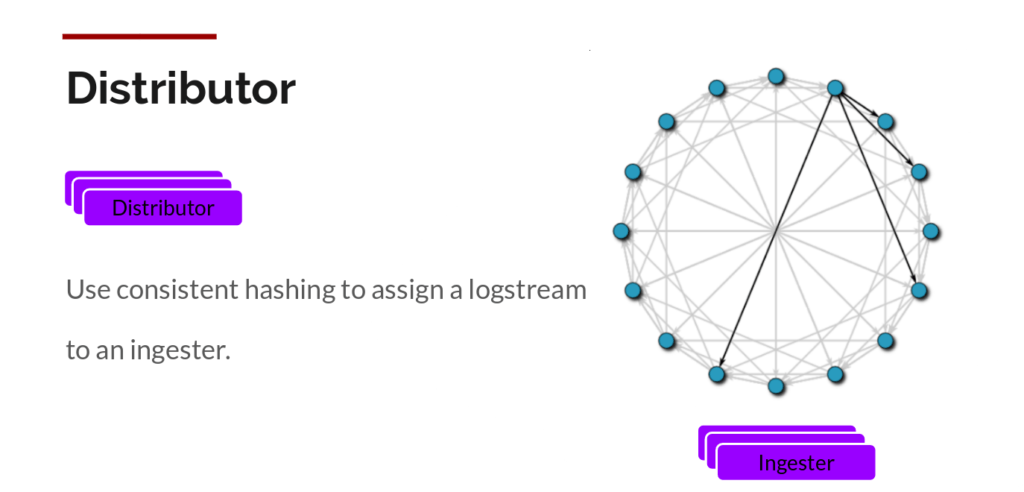
Loki propose plusieurs options pour stocker cet état que nous avons explorées.
Consul, la solution par défaut
Utiliser Consul est une bonne solution si Consul n’a pas de secret pour vous. Dans notre cas, l’installation avec Helm et son intégration avec Loki se sont bien passées. Cependant, rajouter un nouvel outil tel que Consul, qui permet de faire du Service Mesh, du Service Discovery en plus de base de données clé-valeur paraît un peu overkill. De plus, cela nécessite de déployer 3 pods pour le rôle server et 1 pod par noeud pour le rôle client dans le chart Helm que nous avons testée.
Etcd, une solution appropriée encore mal intégrée
Nous avons testé Etcd car il nécessitait moins de pods et car Etcd est une base clé-valeur distribuée, ce qui est tout ce dont nous avons besoin. Cela paraissait donc pertinent d’utiliser cette solution qui ne fait qu’une chose mais le fait bien.
Le problème avec Loki, c’est que pour l’instant, il n’y a pas moyen de sécuriser la connexion avec Etcd via certificat (voir l’issue correspondante). Si cela avait été le cas, c’est sûrement la solution que nous aurions choisie.
Du gossip entre les pods avec memberlist
C’est la solution qui semble la mieux adaptée à notre environnement Kubernetes car elle ne nécessite pas l’installation d’un autre composant. Il suffit d’un service headless pour obtenir la liste des pods (distributors, ingesters et queriers), et en se basant sur la librairie memberlist.go ceux-ci vont faire du gossip entre eux afin de se communiquer leur état.
C’est la solution la plus simple à mettre en oeuvre et c’est celle que nous avons choisie.
Si vous utilisez le gossip, nous vous conseillons de mettre le paramètre publishNotReadyAddresses à true dans la définition de votre service headless car sinon, vos ingesters ne seront pas visibles quand ils seront dans l’état Terminating ou tant qu’ils ne seront pas Ready.
Cela pourrait laisser le ring dans un état incorrect (avec un ingester qui a déjà terminé), ce qui peut bloquer vos updates. Et si vous utilisez un déploiement pour les ingesters, cela empêchera les ingesters sortants et entrants de se découvrir les uns les autres et de se transférer des données (voir la documentation sur le Handoff).
Pour en savoir plus sur le fonctionnement de cette solution : leur article de blog.
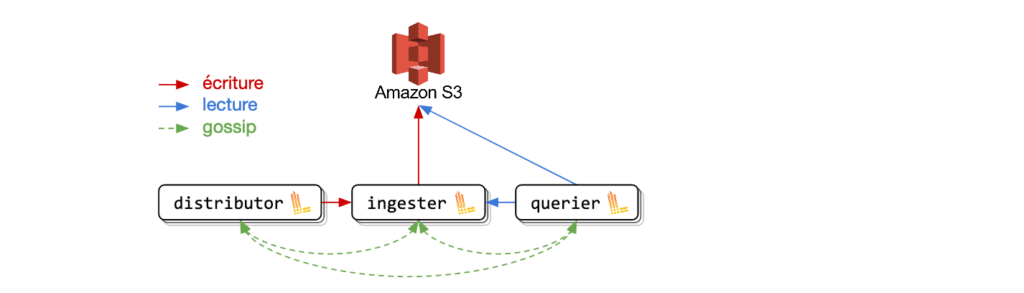
Comment stocker les logs ?
Dans notre déploiement de test, les données étaient stockées localement. En cas de crash de l’application, les logs sont donc perdus. Or, pour avoir une architecture “prod ready”, il est nécessaire que les logs soient sauvegardés de manière persistante.
Loki offre d’autres solutions pour stocker les logs. Étant sur AWS, nous avons d’abord utilisé un bucket S3 pour stocker nos chunks et DynamoDB pour stocker les indexes. Malheureusement, après quelques temps, nous avons observé que la facture pour DynamoDB ayant dépassé les 4000$, ce service ne nous permettait pas de réduire les coûts.
Nous nous sommes donc tournés vers une solution expérimentale qui s’appelle boltdb-shipper. Elle permet de s’affranchir de DynamoDB en stockant les indexes dans le bucket S3. À noter qu’un statefulset sera nécessaire dans ce cas là car les indexes ne sont envoyés que toutes les 15min.
Si vous préférez tout de même rester avec DynamoDB, pour gérer les tables qui vont stocker nos indexes, il vous sera nécessaire de déployer un nouveau composant de Loki : le table-manager. Son rôle est de gérer le cycle de vie des tables (provisionnement, suppression ...) en fonction de votre configuration.
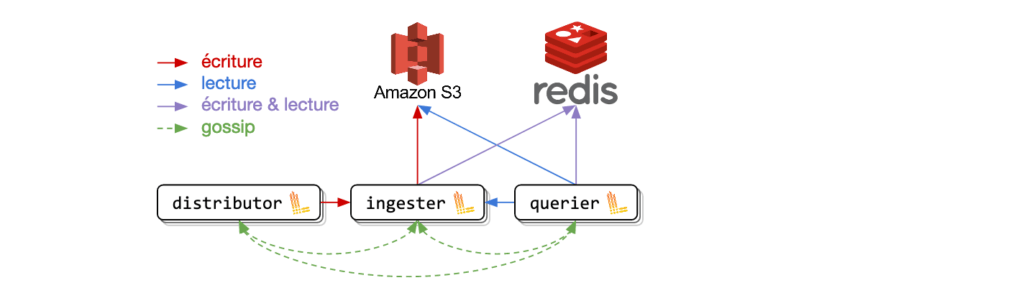
Avec du cache
Loki peut fonctionner sans cache. Toutefois, celui-ci apporte un meilleur temps de réponse lorsque l’on fait des requêtes en lecture. De plus, Loki utilise le cache pour éviter de dupliquer les données lors de l’upload. Vous trouverez ce principe dans leur article de blog.
Pour le cache, vous avez la possibilité d’utiliser un cache en mémoire, Redis ou Memcached qui est la solution mise en avant. Nous avons choisi Redis car nous avons la possibilité d’en déployer un managé par AWS et car nous avons les paramètres disponibles côté Loki pour sécuriser cette communication.
Répartir la charge sur les queriers
Si vous utilisez seulement les queriers, lorsque vous allez faire une requête, elle sera traitée par un pod querier seulement, laissant les autres pods queriers inoccupés (principe du service ClusterIp qui fait du round robin sur l’ensemble des pods).
Pour pallier à cette inactivité des autres pods, vous pouvez utiliser le query-frontend. Celui-ci se place en amont des queriers et va “découper” la requête si elle est considérée trop grosse et va émettre plusieurs sous-requêtes aux queriers afin de répartir la charge.
Multi-tenancy
Nous allons ici séparer nos données en fonction des équipes, nous allons donc utiliser la possibilité qu’offre Loki de définir des tenants.
Comme énoncé dans le document d’architecture de Loki, pour définir le tenant, il suffit d’envoyer le header X-Scope-OrgID à Loki : aux distributors lors d’une requête en écriture et aux queriers (ou query-frontends si présent) lors d’une requête en lecture.
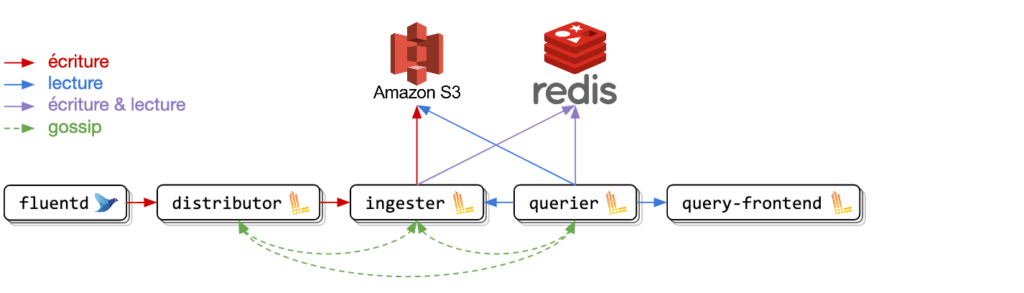
Le multi-tenant en écriture
Pour envoyer vos logs à Loki, vous pouvez utiliser Promtail qui est l’agent par défaut. Cependant comme nous utilisons déjà Fluentd dans notre projet, nous allons utiliser le plugin Fluentd officiel fluentd-plugin-grafana-loki pour envoyer nos logs à Loki.

Avec cette configuration d'exemple de Fluentd pour Loki, vous retrouverez vos données stockées dans votre bucket S3 et séparées par tenant comme illustré ci-dessous.
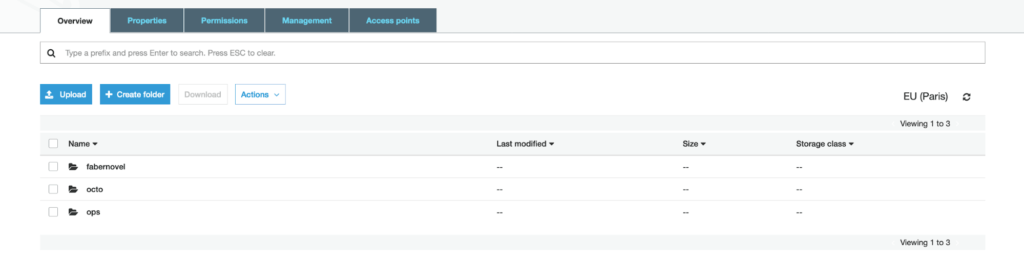
À noter que dans sa configuration par défaut, Fluentd envoie des chunks de 8Mo. Loki doit donc accepter des messages grpc dont la taille dépasse 8Mo, ce qui n’est pas sa configuration par défaut (voir cette issue). Nous avons donc dans notre exemple augmenté la taille maximale autorisée des messages grpc.
Le multi-tenant en lecture
En écriture nous nous reposons sur le plugin fluentd-plugin-grafana-loki pour ne pas avoir à explicitement définir le header X-Scope-OrgID. Cependant, bien que les queriers acceptent le header, Grafana ne définit pas le header automatiquement en fonction de votre organisation. Cependant, à partir de la version 7, Grafana introduit la possibilité d’ajouter des headers HTTP personnalisés à vos appels à la datasource Loki.
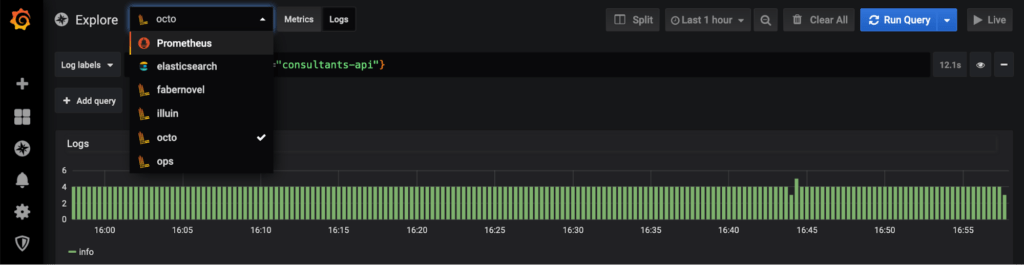
Nous utilisons donc cette fonctionnalité pour définir une datasource `octo` et ajouter un header X-Scope-OrgID valant `octo` (si nous déployons Loki dans un namespace logging grâce à Prometheus Operator) :
additionalDataSources: - name: octo type: loki access: proxy url: http://loki-query-frontend.logging:3100 jsonData: maxLines: 1000 httpHeaderName1: 'X-Scope-OrgID' secureJsonData: httpHeaderValue1: 'octo'
Une fois Grafana configuré, vous pourrez accéder aux logs en fonction de leur tenant (1 tenant = 1 datasource) :
Ayant maintenant accès aux logs, il se pourrait qu’un tenant vienne à faire trop de requêtes en lecture, pénalisant ainsi les autres tenants. Pour éviter cette situation, le query-frontend dispose d’un paramètre max_outstanding_per_tenant afin de configurer une limite par tenant.
Déploiement de l’architecture de production
Dans le dépôt de code de Loki, Helm ou Tanka peuvent être utilisés pour déployer l’application sur Kubernetes. Cependant, l’équipe de Loki n’a pas mis à disposition de chart Helm permettant de déployer l’architecture de production.
Seule la partie Tanka permet de la déployer. Cependant, ne souhaitant pas ajouter un nouvel outil pour le templating/déploiement sur notre cluster, il ne restait qu’une solution : Do It Yourself !
Statefulset ou deployment ?
Nous nous sommes posés la question suivante : devons-nous déployer les ingesters en tant que statefulset ou en tant que deployment ?
Avec un deployment
Lorsqu’ils sont en train de s’éteindre, les ingesters ont la capacité de transférer leurs données à un autre ingester qui vient d’être créé.
Prenons l’exemple de la mise à jour des ingesters avec un deployment dont la cinématique est la suivante :
- J’applique les modifications à mon deployment (kubectl apply …).
- Un pod ingester de l’ancien replicaset reçoit un signal SIGTERM alors qu’un nouveau pod du nouveau replicaset apparaît.
- Sur réception du signal SIGTERM, l’ancien ingester va se mettre dans un état LEAVING.
- Il va essayer de transférer ces chunks à un nouvel ingester dans un état JOINING.
- Le nouveau ingester, une fois démarré, va se mettre dans un état JOINING pour un temps donné.
- L’ancien ingester trouve le nouvel ingester et initie le transfert de ses données.
- Une fois le transfert terminé, l’ancien ingester va s’arrêter.
- Au bout d’un timeout donné, le nouvel ingester va passer à l’état ACTIVE.
Avec un deployment, nous sommes donc censés avoir toujours 3 ingesters acceptant des requêtes en écriture. Malheureusement si le RollingUpdate se passe mal ou si un ingester s’éteint mal, le ring peut rester dans un état indésirable et cela nécessite une opération manuelle pour corriger le soucis.

Pour accéder à cette interface : kubectl port-forward svc/loki-distributor 3100 puis aller sur localhost:3100/ring dans votre navigateur.
Avec un statefulset
Avec un statefulset, le problème précédent n’arrive pas car le pod reprend la même identité (le nom du pod étant le même).
De plus :
- les données sont transférées vers notre S3 avant l’arrêt complet de l’ingester (c’est le comportement par défaut lorsqu’il n’y a aucun ingester dans l’état JOINING).
- les tokens, qui définissent quels logs seront traités par quel ingester, sont persistés grâce à un volume donc le nouveau pod se retrouve avec la même configuration que l’ancien pod.
Ayant donc les mêmes avantages qu’avec le deployment tout en nous prémunissant de se retrouver avec un ring erroné, un statefulset semble plus indiqué pour les ingesters.
De plus, avec le boltdb-shipper, l’utilisation d’un statefulset devient obligatoire pour ne pas perdre les indexes.
Un exemple d’architecture de production
Pour synthétiser tous nos choix et afin que vous puissiez facilement déployer cette architecture, nous avons mis à disposition ce dépôt de code qui reflète ce que nous avons déployé en production.
Conclusion
Les points négatifs
Un chart Helm officiel de production qui manque
En effet, alors que cela est proposé avec Tanka, rien n’est proposé pour déployer simplement Loki en version prod-ready si on ne veut pas utiliser Tanka.
Vous avez cependant maintenant un exemple, avec nos manifests pour une architecture de production.
Une architecture complexe héritée de Cortex
Cela ne facilitera pas votre découverte de Loki ni votre débogage. On est forcé de se demander si cette architecture n’est pas overkill pour de petits clusters où un agent qui tourne sur chaque noeud grâce à un daemonset aurait “peut-être” pu faire l’affaire.
Une documentation qui fait défaut
Si vous devez configurer Loki, vous allez surement regarder sa documentation. Vous vous apercevrez alors, en fonction de votre cas, qu’il faut fouiller dans celle-ci et qu’elle peut contenir des exemples qui ne sont plus à jour ou qu’il vaut mieux parfois aller voir la documentation de Cortex pour comprendre Loki.
Une logique qui nécessiterait un opérateur Kubernetes
On aurait aimé un opérateur Loki pour Kubernetes qui masquerait la complexité de la configuration et pourrait gérer les mises à jour (c’est toujours le bazar si un RollingUpdate ne se passe pas bien). Un peu à la manière de l’opérateur d’Elastic Cloud.
Les points positifs
Moins gourmand en ressources qu’Elasticsearch
Niveau consommation, pour la production, côté Loki nous sommes aux environs de 1 VCPU et 4500Mi alors que côté Elastic Cloud, nous sommes aux environs de 4 VCPU et 16Gi.
Loki nous permet donc de réduire nos factures cloud. En rapportant la consommation de Loki à la capacité de nos instances et à leur prix, nous pouvons estimer que cette architecture nous coûte 40$/mois par cluster (en excluant les coûts de S3) alors que côté Elastic Cloud, cela nous coûte 1500$/mois pour 4 clusters.
Un nombre d’outil réduit
Si Grafana est déjà utilisé pour le monitoring, il n’y a plus besoin d’un kibana.
Scalable
Les différents rôles de Loki sont portés par des deployments différents donc il est facile d’augmenter ou de diminuer le nombre de replicas en fonction de la charge. Pour peu qu’on ait les bonnes configurations.
Infra as code
On aime le fait que tout se fasse en infra as code : une fois déployé plus rien n’est à créer (pas d’index pattern, pas d’index policy management et autres pour faire la comparaison avec Elasticsearch).
En bref
Oui c’est moins cher. Cependant, vu le temps qui nous a été nécessaire pour s’approprier les concepts de Loki et arriver à trouver une configuration de prod fonctionnelle, nous nous demandons si Loki sera facile à maintenir.
En espérant toutefois que cette article puisse aider ceux qui essayent de déployer Loki sur leurs clusters Kubernetes.
Bon courage !