The Esper CEP ecosystem
Mathieu’s introduction to Complex Event Processing (CEP) has announced a series of articles on various CEP solutions. We begin this series with a post about Esper.
Esper, maintained by EsperTech, is a Java platform dedicated to complex event processing and event stream processing (ESP), that is, a collection of frameworks and tools that can be combined to build event-oriented applications and integrate them together. Most of the foundation of such applications is brought by the 3 different Esper packages. These are advertised as “editions”, but are rather complementary building blocks.
Building an event-oriented application with Esper involves:
- coding the main applicative logic with event processing statements, using the core algorithmic engine Esper Event Stream and Complex Event Processing (Esper Engine for short). It is distributed as an open-source project with a GPLv2 license
- packaging, integrating and deploying the application. A good candidate for these tasks is the dedicated Esper Enterprise Edition (EsperEE)
- optionally securing the event processing logic with EsperHA, which brings persistence capabilities to Esper, thus enabling high-availability and recovery scenarios
This post thus offers a global vision of the Esper ecosystem as a CEP platform. The article concerns version 4.5.0 of the platform, but at the time of this writing the latest released version is 4.6.0.
NB: the documentation for EsperEE and EsperHA can be found in the download packages from EsperTech’s website.
The Esper engine
This is the common ground of the 3 editions and where the core event processing logic is implemented. It comes in two flavours: Esper for Java and NEsper for .NET. We will concentrate on the Java version for the rest of this post, because it is the most mature and because the other editions, EsperEE and EsperHA, are only available in a Java environment.
The engine is a JAR, and instantiated by the means of a Java API and an XML configuration file. Thus, used alone, the Esper engine is embedded inside a Java or JEE application, along with business logic, GUI, integration and other frameworks.
If we recall Mathieu’s classification of event processing approaches, Esper implements the first paradigm: it processes incoming events by the means of statements executed against event streams. In this case, an event is a plain Java object (POJO), and a stream is a pipe of events of a given type (class). Streams are used to feed events into the engine, and to “connect” the output of a statement to the input of another, thus allowing statement composition (chaining). Here streams have no physical existence but inside the JVM where the engine is running.
Statements are a central notion in Esper. They are continuous queries, registered with the engine, which continuously monitor the streams they depend on. They are written in EPL, a SQL-like language designed for querying data streams, with similar constructs like projection, selection, aggregation functions, joins (correlations), named windows (akin to SQL views). It also provides language constructs for more elaborate and event oriented features such as pattern matching and sliding windows, to account for the temporal nature of event streams.
-- Detects products pertaining to abandoned carts
insert into AbandonEvent (productId)
select cart.productId
from pattern [
every cart=AddToCartEvent
-> (timer:interval(10 min) and not CheckoutEvent(cartId = cart.cartId))
];
-- Gives statistics on abandoned products (moving aggregate over a sliding window)
insert into AbandonStats
select
productId,
count(*) as abandons
from AbandonEvent.win:time(10 min)
group by productId;
Unlike classical SQL queries, statements are triggered by incoming events, evaluated against them, and forward matching events to their associated listeners – or to another statement in the case of chaining.
Statements can also correlate event streams with a relational database, by the means of a regular SQL query joined with other streams. This can be used when real-time events are to be correlated with historical data, or enriched with lookups against reference tables stored in a database.
So Esper’s main job is matching events against patterns, and emitting high-level (complex) events. Being able to explain how bigger events are produced is essential. This requires keeping a detailed history of each triggering, at every stage, so that output events can be drilled down to the finest ones. Esper has auditing facilities at the statement level, but they are designed for debugging purposes by logging statement activity. There is, as of yet, no such thing as a native event repository and history, but this is planned for the next major release (5.0).
Beside these core functionalities, the capabilities of the Esper engine can be extended by means of plugins, which are deployed as separate JARs alongside the main engine, and activated through configuration. Many EsperHA and EsperEE functionalities (DDS, JMX, ...) are shipped as plugins.
With the community edition of the engine, all processing state (sliding window contents, event flows, current values for aggregated expressions) is stored in memory, as are statement definition and statement-listener bindings. All these are lost in case of a failure. Persisting all these elements is possible with the HA edition, described below.
EsperHA
The HA plugin is responsible for storing the internal state of the engine, for recovery purposes. This is enabled on a statement-by-statement basis, through annotations appearing before the actual EPL code, and with a bit of XML configuration. When a failed engine is brought up again, or when a backup engine is started, the saved state is restored automatically – though with some limitations regarding event size or statement complexity. The state is not saved continuously during normal operations: checkpoints are issued at regular (configurable) intervals measured in seconds or number of events, so a complete recovery cannot be guaranteed unless the input feed can detect and replay incompletely processed events.
More precisely, there are 4 persistence profiles to choose among, to fine tune the persistence needs of a particular statement:
| Piece of state | @Transient | @Durable | @Resilient | @Overflow |
|---|---|---|---|---|
| Events needed by windows & patterns | X | X | ||
| EPL definition of the statement | X | X | X | |
| Statement state | X | |||
| Statement-to-listener bindings and listener state(*) | X |
(*) this is the serialized contents of the Java listener object at the time of the binding, not at the time of the crash. Generally speaking listeners should be stateless, and delegate the persistence of data to another component (service writing to a database, messaging system for the publication of a derived event, ...)
- @Transient is the default profile, with no persistence whatsoever, and the only one available from the Esper community edition
- @Durable tells the engine to automatically restart statements, without having to register and bind them again
- @Resilient is the most complete profile, because almost everything is stored, including statement state (e.g. the current value of an average over a sliding window, whose value would be incorrect after a @Durable or @Overflow statement is restarted)
- @Overflow is used to flush events that partake in state to disk, so the space they occupy on the heap can be reclaimed when memory is scarce
The type of persistence store is configurable, and can be either of BerkeleyDB, Cassandra (beta) or JDBC with support for Oracle, MySQL and Microsoft SQL Server. Note that persisting events adds a serialization overhead and might impact performance.
You will notice that this is all about recovery, i.e. being able to catch up after a crash with losing as little data as possible. What about clustering and load balancing? The engine and the APIs give very little support for these needs. The only provision is for switching between a primary and a backup EsperHA engines, in a shared-data situation where the store is a BerkeleyDB database:
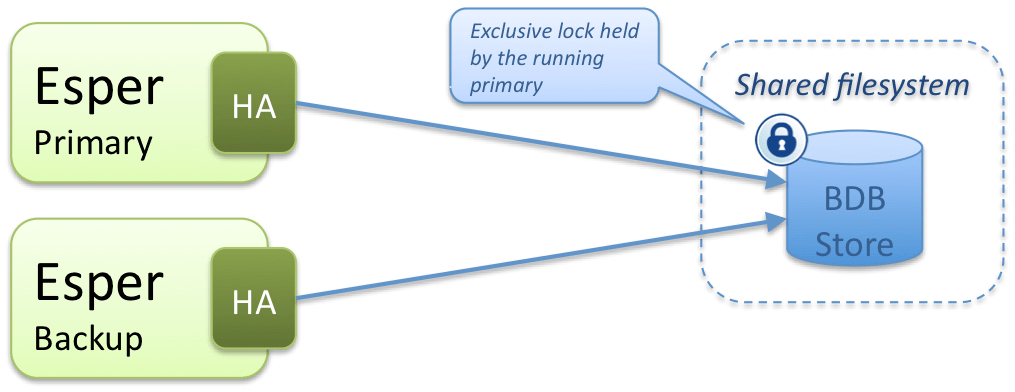
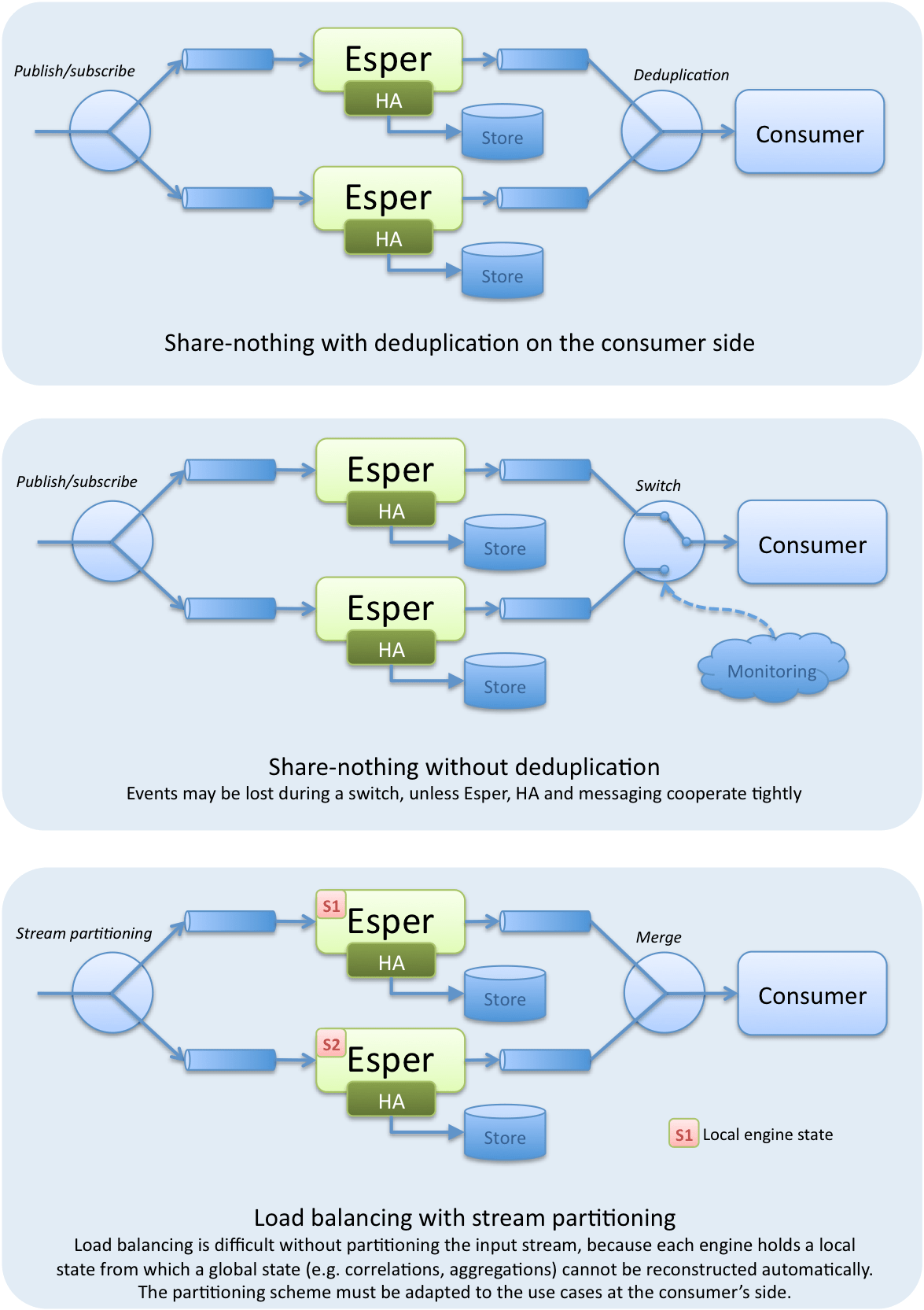
All other situations (load balancing, share-nothing, global persistence across CEP engines and messaging system) must be handled outside of the engine with message routing patterns, possibly with the help of the monitoring facilities offered by EsperEE:
EsperEE
EsperEE is not a plugin in itself, like EsperHA. It is rather a collection of plugins and interactive applications, aiming at managing and integrating Esper engines together
EsperHQ
EsperHQ is a versatile application, combining functionalities of different kinds of tools:
- A runtime container for Esper engines and for CEP applications packaged as WAR archives. This makes it an alternative to traditional platforms like JEE or servlet containers
- A management console for hosted or remote Esper engines, using EsperDDS described below
- A basic IDE for EPL statements and eventlets
- A frontend to local CEP engines, to issue on the spot EPL queries or launch event-driven continuous displays
Regarding statement creation, EsperHQ provides a crude but comprehensive EPL designer. There is no graphical flow language such as can be found in a fully integrated CEP platform like StreamBase, but it eases the task of writing complex EPL code.
EsperHQ also has a wizard for creating eventlets, i.e. graphical Flex components subscribing to events produced by a contained engine, and updating their display accordingly. Such eventlets are kept in a local repository, and can be either packaged and exported, or reused in mashups along with static content, for example to create dashboards. The push technology underneath is Adobe’s BlazeDS.
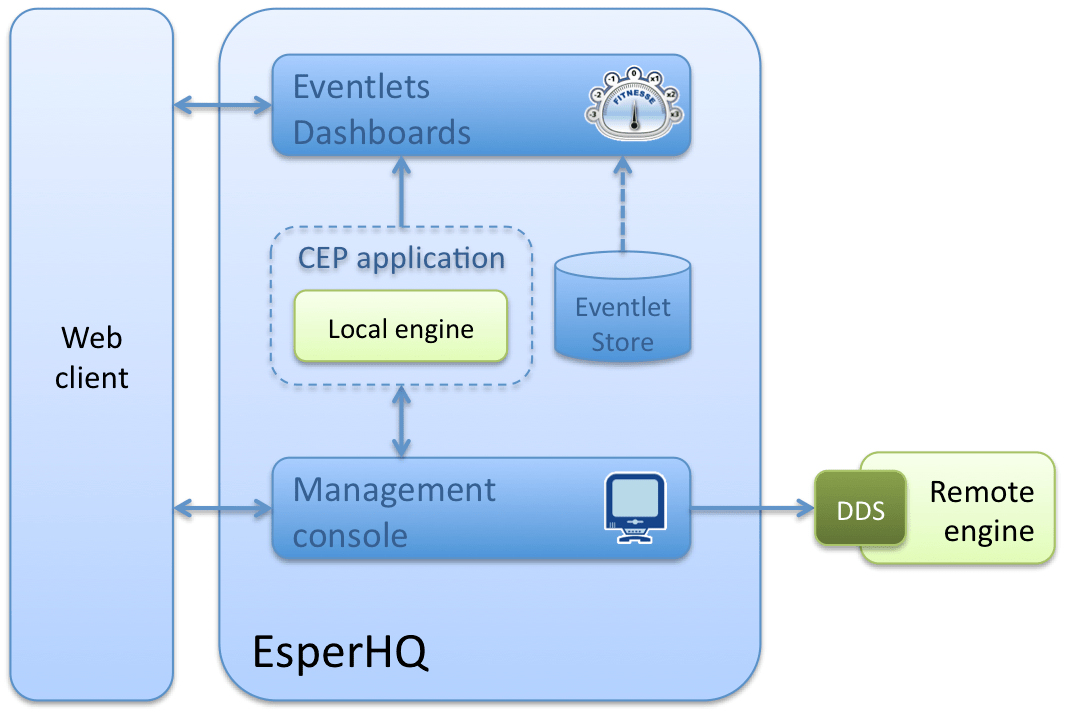
Miscellaneous components
EsperHQ makes a fairly big step towards an integrated CEP platform. On the other hand, the components described below are lightweight plugins or tools that augment Esper with ancillary functionalities.
EsperIO is a collection of adapters (Java classes) that help exchange events between Esper and the outside world, or from an engine to another. They give support for well-known protocols and formats like JMS, CSV, HTTP. More specific needs like social networks, trading platforms or other brokers (e.g. AMQP) must be addressed with custom connectors built on top of the included SDK.
EsperJDBC allows one to query Esper statements and named windows from a Java application in the form of traditional JDBC calls. Its primary use is the integration with reporting tools.
EsperJMX exposes 6 MBeans that give some control over an engine: mostly configuration, statement management and metrics, on the spot querying of a statement or a named window.
EsperDDS does very much the same job as EsperJMX, but uses dedicated APIs that rely on JMS channels to expose the management services and to push the results to the client. The resources to manage are addressed through predicates operating on their metadata (e.g. statement name or annotations). Note that EsperDDS is not (yet?) capable of establishing a subscription to events produced by a remote statement – it deals with engine management.
Conclusion
The three “editions” described herein, Esper Engine, EsperEE and EsperHA, are building blocks of an almost-complete CEP/ESP platform. In our opinion, to compete with commercial solutions, Esper is still missing:
- more user-friendly interfaces – that is, a graphical language as an alternative to EPL authoring
- enhanced simulation and backtesting features – they are expected in the upcoming 5.0 version, with the announced event capture and replay features
- true HA functionalities – native load balancing and cluster management – which still require custom development and architectural design, including careful integration with an external messaging system between checkpoints
EsperHQ mitigates the complexity of EPL by letting one graphically chain smaller statements together inside an engine. Cross-engine statement chaining would be a real plus as it would allow one to graphically compose applications by routing events between them through “gateway” statements. In the meantime, this can be done in CEP applications, either manually or with EsperIO input/output façades. Still, at this time Esper is the leading general-purpose low-cost CEP solution, especially with its open-source engine. But another emerging solution, Microsoft StreamInsight (.NET), is evolving rapidly, and leverages LINQ, a framework now well known to developers, to query event streams. Although the roadmap of StreamInsight is unclear, it may be a matter of time before it is mature enough to compete with Esper on its own grounds.
Are there any aspects of the Esper suite that you want covered in greater detail? Let us know by leaving a comment with ideas for a next article!