The case for writing (isolated) test cases #3
Divide and Conquer
Since three out of four small businesses fail, my recommendation is to start a large business.
Legacy Code and SOTA
"Legacy code" is often used to characterize old software systems inflicted with a crucial maintenance debt that accumulated for years. But legacy code can happen very soon in a project. The best intentions, plus a misaligned or degrading SOTA (State Of The Art) can change your greenfield project into a legacy code factory in a matter of 3 to 6 months, before you even realize it. Legacy software doesn't mean that the framework or language is out of fashion. It means features are slow to get into production, and bugs always follow them.
Legacy code exists partly because we can always make shortcuts: we can substitute ad hoc duplication for merciless refactoring; we can choose to deal with bugs once they'll show up rather than following an adequate defect prevention process; for a while at least, we can conflate the speed at which we deliver poorly designed code with great team performance. Features are piling at the last step of the "software factory"; a Product Owner with a packed agenda already is busy validating their suitability in the value creation chain. What could go wrong?
In the best of worlds, as a software development project starts, a State of The Art (SOTA) for this project gets explicitly or tacitly defined. The initial SOTA for the project includes all the heuristics that were bound together at inception phase as "the way we'll do this". Some parts of it might be officially documented through a "Quality Assurance Plan" for instance, or a team chart, while other parts are implicitly assumed as industry standards, and some other parts will only be discovered through the ongoing team conversation that is characteristic of any non-trivial project.
Here are some examples of heuristics that the SOTA for a particular project might include :
- [ Indent your Code ] : all the source code will follow indentation standards that are adequate for the programming language used. Although nobody on the project ever mentioned it, this heuristic is present in the SOTA as an implicit industrial standard, since developers who don't follow indentation rules are quite rare.
- [ Test Coverage Metric ] : all the code is measured in terms of branch coverage while executing automated tests. This heuristic was defined in the official QAP, with a minimal percentage that was agreed about.
- [ Architecture Decision Record ] : all important architecture decisions on the project are captured in a way that reflects the context and consequences of the decision. This heuristic was proposed by a team member a while after the project began, as a way to simplify the team's decision process and team cohesion around technical decisions.
Given a legacy code base, there is a chance that the SOTA was misaligned from the start regarding the project constraints and objectives. Maybe the testing strategy was left mostly undefined. Maybe the complexity of a critical feature was grossly underestimated, or thought to be manageable entirely through an off-the-shelf "solution". Maybe what seemed a reasonable option at the time of inception revealed itself unfeasible later. Maybe not everyone was agreeing on what "user friendly interface" means, and so on.
Of course the constraints and objectives may change as well during the project, making the initial SOTA more or less irrelevant. New learnings, decisions, discoveries, experiments, drawbacks, changes in the staff, amendments, feedbacks, Etc., all kinds of new inputs happening on a development activity are bound to impact its SOTA. Most certainly such a SOTA is not fully established once and for all like a doctrine. Teams and organizations adhering to the Lean strategy for instance constantly try to improve their SOTA. Teams and organizations that don't put much thought and effort into it let it deteriorate, sometimes to a point where their process and practices become patently unadapted to the problem at hand.
Now let's fast forward to the middle of such a project's course. Depending on the degree of misalignment that the SOTA is prone to, any proposition for the adoption of heuristics that would allow for a better design, product, or development process will be seen as a costly, unrealistic alternate way, and will most probably be dismissed as "overkill". Inasmuch as the project difficulties, lateness, and unexpected anomalies are imposing their toll on the initial budget, the team and the organization will in fact try to stick to the initial strategy, making it harder and harder to initiate change. Pictures of square wheels, and "not enough time to improve" come to mind.
An improved SOTA, a better process and set of practices that might be proposed by some of the team members and rejected by others, will seem costly until they can be proven cheaper than the current way of doing things. In any case, given that the team now pays the extra costs and sacrifices to quality that come when dealing with swarms of bugs on a poorly designed system, this improved SOTA is out of reach. We understand that it would yield better quality, and for a cheaper price even. We understand that it would have helped prevent this mess in the first place for sure. But switching to that better process, which in no way can happen overnight, seems unaffordable. We are stuck, prisoners of a past suboptimal strategy that we would not – or thought we could not – improve, like a chess player who made poor decisions and lost a piece 5 moves ago, and can only try to think fast and make good use of the amount of remaining time on the clock.
Switching from a given SOTA (the one that led to a degraded, fragile, unsatisfactory solution) to a significantly different SOTA (one that would allow for swift maintenance and evolution actions on the application while minimizing the risk of costly regressions) in a couple of week is impossible. The people you work with, their knowledge, know-how and practices, your software development lifecycle and process, the culture of your organization, won't change that fast. Replacing key technical leaders might seem like a logical albeit radical approach; it will only put your progression to a grinding halt.
Where do we go from here ?
We could try a "Divide and Conquer" approach.
Have you ever been facing the task of debugging a complex, old, mysterious, cranky program that would stubbornly fail to process an input data file ?
All you know is, when you feed the program with this faulty 15 Mb data file the customer provided you with, it crashes with a cryptic invalid format. You ask : "Where?" but unfortunately the program won't tell before dying. The file happens to be around 200 000 lines of text data, what seems to be essentially innocent numbers and labels. You have no idea where the problem could be. So you make a copy of it, and after studying its structure a bit, slice it in two halves thanks to your favorite editor. You try feeding the program with the first half-file, and nothing happens. The program just gulped the file with an OKand stopped. You try feeding it the second half-file and sure enough this time you get an invalid format . You are in luck. You halve again this second half , and try the program with these two files that are now a quarter of the initial file size. You continue with this process until you can finally find the exact location of the first incorrect line in the file. It only took you 16 trials to spot this specific line among 200 000. Congratulations: you applied a Divide & Conquer strategy.
In Computer Science, quoting Wikipedia,
A divide-and-conquer algorithm recursively breaks down a problem into two or more sub-problems of the same or related type, until these become simple enough to be solved directly. The solutions to the sub-problems are then combined to give a solution to the original problem.
Back to our legacy app maintenance situation, the original problem that we have could be stated like this:
In order to extend the application's behavior, increase its performance, improve its design or fix a default, we need to apply changes to the code.
Although most of these changes can be clearly delineated, the code has no tests and as such is prone to potential regressions.
As a result, a) we limit the changes to a strict minimum, making refactoring illegal, thus persisting in our design mistakes ; b) we postpone the changes as much as we can, delivering them through bigger, less frequent releases, so as to minimize the integration and acceptance testing effort
We want to stop doing that. We want to be able to refactor the code as soon as we sense "code smells", or when the gap between the code and our shared understanding of the problem it solves becomes too wide. We want to have small, frequent, uneventful releases. Having many small, isolated, repeatable, self-validating tests is a means to that end.
Of course as stated above, we currently don't have many small, isolated, repeatable, self-validating tests. Writing such isolated tests immediately is impossible, or very costly, because of a lack of modularity in the existing code : each time we want to "simply call" a method from an object, we find ourselves forced to setup many other objects that this object depends on, and that chain of dependencies often includes calls to external resources, like database drivers, that must be connected, and so on.
Since we cannot start with small, fast, automated isolated tests, let's start with a few tests that are large, integrated, and require human diagnosis and validation.
[write approval tests for code that can't have isolated tests] :
- write a test that captures some (possibly large) output and compares this output to an arbitrary value
- approve the first output as the expected result for future executions of the test
- whenever running the test again yields a different result, either
- find and fix the regression that caused the change in the output
- approve the output as the new reference for future executions
Once we have enough approval tests to cover the behavior we want to secure against regressions, we can start dividing the problem by applying [separation of concerns]:
- (re)assigning parts of the behavior of the application to specific modules
- creating interfaces in order to ensure encapsulation
- running the tests after each edition of the code
This revising of the design allows for better modularity, where parts of the behavior of the application that are conceptually separate are assigned to separate modules. At this point, it should be possible to [write isolated tests for the part of the behavior that are conceptually isolated] i.e. create tests that can instantiate objects or prepare data, execute methods or expressions and check the resulting state or values, and do all of this independent of external resources. If writing isolated tests is not yet possible for the part of the code we are working on, we continue by writing new, more specific if necessary, approval tests.
Once we have several isolated tests covering the specific behavior that we need to isolate, we can throw away most of our approval tests. These tests, being dependent on integrated component and external resources, prove now to be too costly to run and edit, and yield much less coverage than an adequate suite of isolated tests.
We have successfully used the Divide & Conquer heuristic.
An example would come in handy right about now
Suppose we are maintaining an online poker game application. The application doesn't have any automated tests, and we have been asked to fix some bugs with regard to hand comparison. One the bug report states:
In some cases, the showdown reveals a wrong evaluation of hand. Player with 6♦ 6♠ 6♣ J♣ 7♥ is declared the winner instead of another player with 6♥ 6♦ 6♠ Q♣ 4♠. (We couldn't reproduce the bug). The rules is that each three of a kind is ranked first by the rank of its triplet, then by the rank of its highest-ranking kicker, and finally by the rank of its lowest-ranking kicker.
After making sure we are able to run the application in our test environment, we proceed in the following sequence:
- create a first approval test by making the code output a global game state variable onto a log file at each showdown; the log contains information such as which player wins, how much they gained, with what hand.
- problem: the card deck changes at each new game, so the approval tests fails each time it's executed
- in the approval test code, make the deck a hard coded fixed list of cards (changing the code under test in the slightest possible way by use of a public member or interface), instead of calling the shuffling function, and make this substitution depend on a call parameter; now each execution of the approval test uses the same card deck
- with approval test running, refactor for separation of concerns, moving some methods into hand comparison, wages, and showdown modules
- create a second approval test for hand comparison through output of variables containing the players hands
- with approval tests running, refactor for separation of concerns, moving some methods in game status, hand evaluation, and hand comparison modules
- write an isolated test for hand evaluation : Three of a kind with equal ranks (complete equality of cards)
- write an isolated test for hand evaluation : Three of a kind with equal ranks for triplet and distinct higher-ranking kicker, observing the bug
- write an isolated test for hand evaluation : Three of a kind with equal ranks for triplet and distinct higher-ranking kicker, with cards sorted by rank, observing that the bug doesn't occur in this case.
- fix the bug
- refactor for more separation of concerns : rank comparison, grouping cards
- etc.
In most legacy code contexts, progressively bringing isolated tests to the code is the surest and most efficient strategy for the team as it is making its way to get out of the legacy trap. Isolated tests are you allies :
- they give fast, reliable feedback, and can be executed at will as soon as the code is compiled
- they are self-sufficient in that they require no extra preparation of test data nor test environment management steps
- they contribute to the team's improved agency and clarity about the actual properties and behavior of the system they are maintaining, helping documenting it as well as re-designing it
By repetitively following this strategic sequence :
- write approval tests for code that can't have isolated tests
- refactor for modularity, applying step 1) until you can go further
- write isolated tests
we can put legacy code under isolated tests and thus achieve our objective of securing each change we make to the code.
This way is faster than trying immediately to write isolated tests on the code : instead of creating a complex grid of mock objects to try to get rid of external dependencies, we use approval tests as a temporary workaround that helps us to secure the first refactoring actions. In this heuristic, the tests we write help us efficiently secure the changes we make to the code, just like a vise that constrain a mechanical piece we are working on.
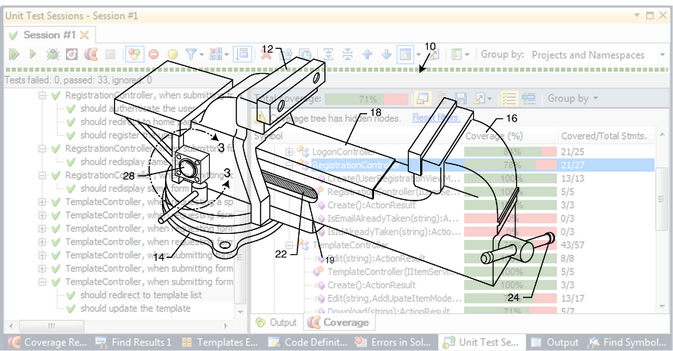
It is also a much faster way than trying to achieve high coverage through integrated tests : instead of managing external test data and test environment to cover a large combination of cases, we create simpler "unit" tests (the unit here being the specific behavior that we isolate, not necessarily a single file of code, class or method).
Of course integrated tests keep being used in the project, but only for what they are done for, i.e. to check the interaction of components together, and not to check every specific part of the components behavior.
Then what happens?
Any code base, be it the result of a successful project or a grueling one will turn into legacy code eventually. This is not necessary a problem, depending on what specific goals and constraints will be attached to working with this code base then. It can definitely become a problem if you are not aware, or denying, that the code that plays such an important role in your business success has become legacy code. What is legacy code after all ? Code that is hard, costly and risky to change. What inevitably comes after the first release of a successful project ? Changes.
Sometimes the folks in charge of maintaining the code base or some consultants hired to diagnose the process and help reduce the "time to market" will formulate a technical debt instead of _legacy code_problem. Some of them will even tape a 5 or 6 digit figure to the problem. But what is technical debt ? It is the same thing as what we call legacy code : a misalignment in the specific state of the art of this application, a gap that is large enough to hinder any significant functional or technical improvement that you want to bring to your product.
Supposing we want to deal with this problem instead of ignoring it, what is the best course of action?
We suggest this one:
- start writing isolated tests for the code you want to change
- writing isolated tests will probably be quite difficult at first, so instead start with some approval tests
- then divide and conquer your way through testing and refactoring your legacy