Thanos : une extension de Prometheus ?
Le monitoring, un domaine resté stable pendant plusieurs années, a été récemment bouleversé avec l’apparition de nouvelles technologies remettant en question les pratiques existantes. Depuis de nombreuses années, l’outil Prometheus a été la solution de référence pour superviser une infrastructure de type Cloud, SaaS/Openstack, OKD, K8S. Développé à l'origine par SoundCloud, mis en open source et accepté en 2016 comme deuxième projet de la CNCF (Cloud Native Computing Foundation), Prometheus est devenu tellement populaire que même certains cloud providers (Azure avec Azure Monitor et GCP avec Stackdrivers) proposent une intégration avec ce dernier, aussi bien pour de la consommation de métriques que de l’exposition. J’irai même jusqu'à dire que certains comme Amazon avec AMP l’utilisent pour remplacer leur solution classique à l’aide d’une version managée.
Nous vous avons déjà parlé de Prometheus par le passé, comme par exemple dans cet article (“Exemple d’utilisation de Prometheus et Grafana pour le monitoring d’un cluster Kubernetes”). Ici, nous nous focaliserons non pas sur Prometheus mais sur les nombreuses nouvelles technologies qui ont émergé au cours des dernières années. Il serait difficile de toutes les lister en un seul article. C’est pour cela que nous vous proposons une série. Dans celui-ci nous aborderons la première solution sur laquelle j’ai pu travailler. Elle fait référence au plus grand méchant de Marvel, vous l’aurez deviné, je parle bien évidemment de Thanos.
Cet article ne sera pas un tutoriel détaillé de mise en place de la stack Thanos, mais plus un retour d’expérience sur le fonctionnement et les raisons pour lesquelles Thanos a été développé et dans quel cas il peut s’avérer plus pratique qu’un simple Prometheus.
Les limitations de Prometheus at scale
Avant tout, afin de bien comprendre les raisons pour lesquelles ces solutions émergentes ont été développées, nous allons étudier les limites de Prometheus.
Pour rappel, cet outil permet de collecter et stocker des métriques sur les applications, les middleware, et les serveurs qui savent exposer une interface au format OpenMetrics. Il est ensuite possible de consulter les séries temporelles stockées à l’aide du langage de requêtage PromQL.
Ses capacités de Service Discovery et son intégration avancée avec Kubernetes (notamment au travers du projet PrometheusOperator) lui donnent une longueur d’avance sur le monitoring d’objets volatiles, comme les conteneurs. De plus, à travers celui-ci, il devient encore plus simple à configurer et la transmission de compétence est plus simple à réaliser. Prometheus fonctionne très bien nativement pour récupérer les métriques des applications dans le cluster et pour stocker ces métriques à court terme.
Mais voici une petite histoire qui vous permettra de bien comprendre les limites de Prometheus :
“ Il était une fois un client qui possédait un cluster de production avec un Prometheus ainsi qu’un magnifique tableau de bord créé via Grafana. Ensuite, est venu un deuxième cluster également équipé d’un Prometheus et d’un Grafana. Jusqu'à maintenant, il n’était pas dérangeant d’avoir deux dashboard récapitulant l’état des deux clusters. Mais à mesure que le nombre de clusters augmentait, le client commença à partager quotidiennement les liens des instances de Prometheus et de Grafana. À un moment donné, il commença à réaliser qu’il passait plus de temps sur le monitoring que sur ses applications fonctionnant dans ces clusters.
Puis un jour, le client souhaita que ses analystes aient la possibilité de vérifier l'utilisation des applications dans les clusters, et que ses développeurs aient une vue d'ensemble des instances en cours d'exécution. Enfin, il souhaita également que sa Direction dispose de toutes ces informations ainsi que la performance de ses applications sur l’année dans un seul tableau de bord. Parallèlement le disque d’un des Prometheus fus corrompu et perdu 15 jours de métriques.“
Vous voyez où je veux en venir ?
Ainsi on remarque que lorsque l'échelle grandit (multi-cluster, “long terme”) de nouvelles questions se posent :
- Comment gérer la rétention des métriques dans le temps ?
- Comment avoir une vue globale de l'état de sa plateforme quand les données sont réparties entre plusieurs instances Prometheus ?
Quelles sont les solutions proposées nativement par Prometheus ?
Rétention des métriques
Par défaut Prometheus agrège ses métriques sur les 15 derniers jours dans des bases de données de types TSDB (base de données orientée Time Series). La durée de rétention reste configurable mais au-delà de la valeur par défaut cela peut vite devenir problématique, notamment en coûts de stockage et en ressources utilisées. De plus, que se passe-t-il si celui-ci dysfonctionne ? Sans back-up, les données sont perdues.
Depuis la version 2.0, Prometheus est capable de scaler ses bases TSDB verticalement ce qui améliore ses performances et sa capacité à agréger plus de métriques. En revanche, cela augmente la difficulté pour le maintenir (backups, ...) ainsi que ses coûts de stockage.
Une autre solution proposée par Prometheus consiste à déléguer le stockage long terme à des fournisseurs externes. Au travers de remote endpoints, Prometheus est capable d'effectuer des remotes read et des remotes write pour récupérer ou ajouter des données. La liste des fournisseurs proposés est disponible ici. On remarque que pas mal d’entre eux ne sont pas compatibles read and write. Nous reviendrons plus en détail sur cette faculté d'effectuer des remotes read et des remotes write un peu plus tard dans la série d’article.
Sharding et Vue globale
Il faut savoir que Prometheus n’offre pas de mécanisme de partitionnement interne (sharding). C’est à la fois une force (très simple à déployer et à administrer) mais aussi une faiblesse pour les gros parcs à monitorer. En revanche, il est quand même possible, au niveau des instances, de distribuer la charge de récupération de données. Dans certains environnements, on se retrouve même obligé de sharder les Prometheus soit pour des raisons de gouvernance où chaque équipe est responsable de son application et de ses métriques ; soit pour des raisons techniques, par exemple pour contourner le fait que Prometheus ne sait pas gérer le multi-cluster.
Par contre, lorsque l’on veut produire une vue globale de notre plateforme, c’est-à-dire si on cherche à visualiser toutes les métriques depuis un seul point d’entrée, il faut pouvoir regrouper les données.
Pour ce faire, Prometheus propose un modèle de fédération permettant d'agréger des métriques depuis une autre instance Prometheus.
Dans le modèle de fédération imaginé par Prometheus, on retrouve 2 approches :
- Une fédération hiérarchique qui consiste à remonter seulement les données intéressantes pour une vue globale et à garder toute la vue détaillée dans le Prometheus local (approche en forme d'arbre)
- Une fédération Cross-service qui consiste à regrouper des métriques d'une application issue de plusieurs instances Prometheus pour donner une vue fonctionnelle d'une application. (les métriques “custom” applicatives et les métriques techniques de l'application sont dans 2 Prometheus différents)
La fédération dans Prometheus est très simple à utiliser. Prometheus expose ses métriques au format open-metrics sur l'url “/federate”. Il suffit juste de déclarer un nouveau job pour que les métriques soient remontées comme n'importe quelle application L'interface federate propose également un paramètre pour filtrer les données que l'on souhaite remonter.
Une notion de federate_labels apparaît aussi lorsque cette url est appelée pour décorer les métriques avec des labels en plus.
Le mode fédération de Prometheus est intéressant mais il est limité dans certains contextes, notamment lorsqu'on veut afficher une vue globale assez détaillée. Cela est dû au fait que le Prometheus fédérateur ne récupère qu’une portion des métriques des Prometheus qu’il fédère. On peut donc être amené à définir les métriques que l'on souhaite récupérer, ce qui peut être un travail titanesque. De plus, cela augmente la complexité au niveau du stockage car l'instance Prometheus construisant la vue globale aura aussi énormément de données à stocker puisque celle-ci va ingérer toutes les données.
Thanos to the rescue
Prometheus est connu pour sa simplicité et sa fiabilité mais nous avons vu que celui-ci, à partir d’une certaine échelle, présente certaines limites. Pour y remédier, en 2018 Improbable sort sa première version d’un projet open source sous le nom de Thanos visant à fédérer des serveurs Prometheus dans un environnement multi-cluster avec un stockage quasi-illimité des données historiques et cela via l’utilisation d’Object Storage (AWS S3, Google Cloud Storage…)
Architecture Scalable
Principe de fonctionnement
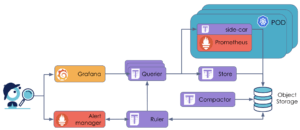
Tout comme Prometheus, le modèle de fonctionnement de Thanos est extensible par construction. En revanche, contrairement à Prometheus qui est basé sur un modèle de type “pull”, Thanos est basé sur un modèle de type “query”. Au travers de ses composants, il va interroger nos instances Prometheus ou notre stockage distant et va récupérer uniquement les métriques dont il a besoin pour ensuite les exposer. Mais avant de comprendre comment Thanos réponds aux problématiques citées plus tôt dans l’article, il est important de lire la documentation qui présente les différents rôles de ses composants qui le composent : https://thanos.io/tip/thanos/getting-started.md/. Toutefois, pour la lecture, simplifions les rôles principaux de la manière suivante :
- Le Sidecar : Le Sidecar tourne comme son nom l'indique dans le même pod que Prometheus et observe celui-ci lorsqu'il enregistre de nouveaux blocs de stockage sur disque, ce qu'il fait par défauts environ toutes les 2 heures. S'il est configuré pour le faire, il enverra ces blocs de données dans un stockage distant. Une autre caractéristique importante est qu'il donne accès au contenu du Prometheus auquel il est attaché via une gRPC Store API.
- Le Store : Thanos Store implémente la même Store API que le Sidecar et grâce à celui-ci met à la disposition du Thanos Querier les métriques stockées dans le stockage distant. Pour ce faire, il observe le bucket S3 configuré et lit les métadonnées du stockage disponible stockées dans le bucket pour ensuite les exposer au Querier.
- Le Querier : Compatible avec PromQL, il utilise l'API v1 de Prometheus pour agréger les données des composants sous-jacents. Pour ce faire, il envoie les requêtes en utilisant le fameux Store API aux autres composants Thanos et attend les métriques, que ce soit directement de Prometheus via le Sidecar ou les métriques stockées dans le stockage distant via Thanos Store.
- Le Ruler : Composant équivalent au “Recording Rule” de Prometheus. Des règles lui seront données pour définir des alertes. Il s’occupera ensuite d’aller vérifier en temps réel si les seuils configurés sont atteints en interagissant avec le Store API. Si tel est le cas, il préviendra l’Alertmanager.
- Le Compactor : Ce composant a été créé parce qu'il n'y a pas beaucoup de sens à conserver indéfiniment de vieilles métriques qui sont récupérées toutes les 15 ou 30 secondes. À un moment donné, cette précision devient superflue. C'est là qu'intervient le Compacteur Thanos, composant totalement indépendant des autres. Il crée des agrégats d'anciennes données sur la base de règles. Il permet par exemple de regrouper des mesures datant de plus de 30 jours en morceaux de 5 minutes. Cela permet d'économiser des ressources tout en offrant une précision presque identique sur des périodes plus longues. Une fois que ces mesures ont été agrégées, elles sont réécrites dans le bucket S3 et les métadonnées sont mises à jour.
Un point important à noter est que chaque composant peut être scalable et peut se déployer indépendamment. On remarque également que Thanos a été construit en se basant sur Prometheus. En effet, il faut savoir qu’ils ont repris le code source de Prometheus et qu’il ne vise absolument pas à remplacer Prometheus mais au contraire à construire une solution pour fonctionner avec celui-ci. Prometheus permet toujours de collecter et stocker nos métriques (du moins pendant un certain temps…)
Comment fait-il pour récupérer uniquement les métriques dont le Querier à besoin ?
Comme nous venons de voir, c’est le composant Querier qui s’occupe de rassembler les métriques demandées par la requête. Celui-ci va commencer par demander à ses Sidecars si le Prometheus qui leur est local contient les métriques qu’il recherche. Si parmi ces Sidecars l’un d’entre eux lui répond que oui, le Querier viendra récupérer directement les métriques auprès du Prometheus. C’est pour cela que l’on dit que Thanos est basé sur un modèle de type “query”.
Ensuite, en fonction de la façon dont la rétention du Prometheus a été configurée, il est possible que les métriques que l’on recherche ne soient plus disponibles car celles-ci sont trop anciennes. Dans ce cas, le Querier demandera auprès du composant Store Gateway si celui-ci contient les métriques recherchées. Si nos Sidecars ont été configurés pour envoyer par bloc les métriques de leur Prometheus à notre stockage distant. Celles-ci devraient donc être exposées par notre composant Store et ainsi permettre au Querier de les récupérer si besoin.
Comment les composants de Thanos se parlent entre eux?
Sans trop rentrer dans les détails, chaque composant Thanos (mis à part le Compactor) implémente et expose le gRPC Store API. Ce Store API va être utilisé par un service qu’on appelle généralement le Store Gateway, qui va donc exposer tous les composants Thanos. Ce Store Gateway va permettre aux composants par exemple aux Sidecars d’annoncer au Querier que les métriques qu’il recherche se trouve dans son Prometheus. Ou encore permettre au Querier de prévenir le composant Ruler qu'une de ses règles est active par exemple.
A savoir également que le Store Gateway est utilisé pour envoyer les queries et les métriques entre composants. Ainsi sans ce service les composants de thanos sont completement perdu.
La réponse de Thanos aux limites de Prometheus
Nous avons vu brièvement le fonctionnement de Thanos ainsi que son approche et les différences de celle-ci par rapport à celle de Prometheus. Rentrons maintenant dans le vif du sujet : Comment l’approche de Thanos répond-elle aux problématiques de Prometheus ?
Prenons un exemple:
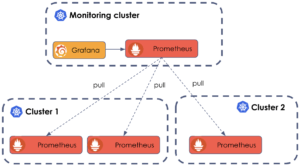
Si on se réfère à notre schéma ci-dessus, nous avons 3 clusters, chacun avec son ou ses Prometheus, se partageant la charge de récupération des métriques. Nous avons vu qu’il était tout à fait possible d'utiliser le mode Fédération de Prometheus pour rassembler toutes ces métriques en un seul point, mais que celui-ci comportait des limites, d’autant plus significatives à plus grande échelle. Ainsi, l’objectif va être d'intégrer Thanos à cette infrastructure.
Il est relativement simple d’intégrer la solution Thanos à celle de Prometheus. Il suffit dans un premier temps de déployer un Sidecar accroché à chacun de nos Prometheus et de le configurer en fonction de nos besoins. Ensuite dans un deuxième temps, déployer également un Querier par clusters ou plusieurs si vous voulez être plus hautement disponible. Enfin, vient la partie un peu plus complexe, il va falloir lier tous nos composants déployés.
Concernant le Sidecars et le Prometheus, il n’y a rien à faire si ce n’est de le déployer correctement, voir cet article pour plus de détails.
Maintenant en ce qui concerne le Querier et les Sidecars intra à leurs clusters, il va falloir faire quelques modifications et déployer notre fameux service “Store Gateway” dans chaque cluster de la façon suivante :
Il y a deux éléments importants à noter dans la création de ce service :
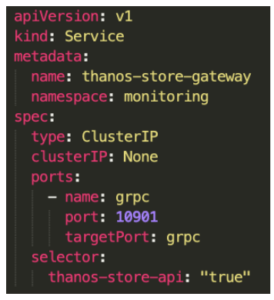
- Le premier est le port utilisé, qui correspond au port du framework grpc qui sera utilisé par notre fameux Store API et qui permettra donc non seulement à nos composants de se parler entre eux mais également de s’envoyer les queries
- Le deuxième est le selector, c’est grâce à ce selector qu’on va pouvoir attacher ce service à tous nos composants Thanos.
Ensuite une dernière petite configuration à faire : prévenir notre Querier de l'existence de ce service pour qu’il puisse parler et recevoir les queries provenant des autres composants de Thanos. Pour ce faire, il suffit lors de son déploiement de lui donner l’argument suivant :
“--store=dnssrv+thanos-store-gateway:10901”
Voilà le tour est joué ! Chaque cluster est maintenant capable de se monitorer lui-même. Mais nous n'avons toujours pas résolu notre principal objectif : pouvoir récupérer toutes ces métriques depuis une seule et unique URL. Pour ce faire, rien de plus simple : ajouter quelques derniers arguments (en fonction du nombre de querier que l’on souhaite attacher) à notre Querier dit “fédérateur” lors de son déploiement comme ceci :
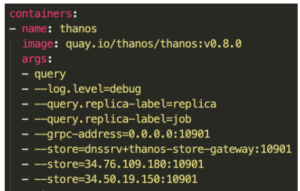
Enfin, si nous souhaitons réaliser de beaux dashboards via Grafana, il faudra connecter celui-ci à notre Querier fédérateur, de la même manière qu’à un simple Prometheus. C’est ainsi que nous obtenons une nouvelle infrastructure quasi-complète avec la solution Prometheus couplée à celle de Thanos offrant une vue globale sur nos métriques :
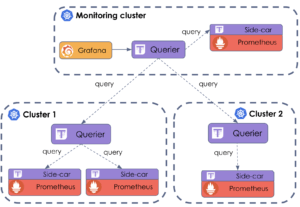
Ce qui est intéressant ici, c'est que l’infrastructure comporte plusieurs instances de Prometheus avec plusieurs Sidecars et il se peut que ces Prometheus récupèrent les mêmes métriques. Heureusement pour nous, Thanos gère la déduplication des données et cela grâce au label appliqué au métriques(plus d’info ici). Les données téléchargées à partir des Sidecars contiennent des informations sous la forme de label sur l'instance de Prometheus à partir de laquelle les métriques sont récupérées. Le Querier peut ensuite dédupliquer ces données afin que les métriques indiquées dans Grafana soient cohérentes et ne proviennent pas parfois du Prometheus A et parfois du Prometheus B.
En revanche, nous avons toujours un petit problème avec cette infrastructure puisque nous stockons toujours nos données dans nos Prometheus. Nous sommes toujours limités en termes de rétention et nous n’avons pas de réel backup au cas où un de nos Prometheus dysfonctionne. Pour résoudre ces deux problèmes, il va donc falloir rassembler nos données dans un stockage distant apte à contenir beaucoup de données et cela au moindre coût (qu’il soit financier ou en ressources utilisées). La solution la plus évidente et la plus facile à mettre en place serait d’utiliser un Object Storage. Nous allons donc commencer par configurer tous nos Sidecars pour envoyer les données par bloc de 2h (valeur par défaut mais modifiable) de leurs Prometheus au fameux Object Storage :
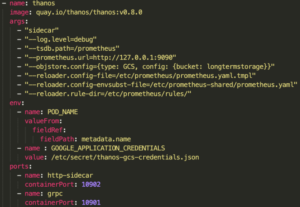
Puis du côté du provider choisi, dans notre cas GCP, il faudra créer le bucket qui stockera toutes nos métriques.
Ce stockage distant offrira bien plus de rétention qu’un simple Prometheus Vanilla. Nous permettant ainsi de réaliser des requêtes sur des données de longue date et de tracer plus efficacement l’évolution de notre infrastructure ou de notre application.
Maintenant que nos données sont au chaud dans un stockage distant, il faut pouvoir les récupérer et les mettre à disposition pour notre Grafana. Il faut déployer le composant Store et tout comme le Sidecars le faire pointer vers notre bucket :
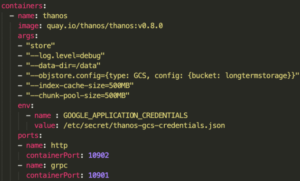
Enfin pour la touche finale, on peut également déployer un Compactor et le faire pointer vers le bucket de la même manière que le Store et les Sidecars.
On obtient ainsi l’infrastructure finale suivante :
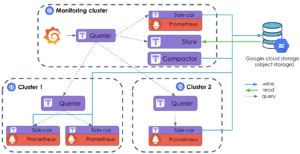
Cela a bien évidemment un coût. Cependant, contrairement à Prometheus, avec un Object storage, nous ne payons que pour les transactions sortantes. Cela nous permet d’avoir un stockage quasi-illimité sans avoir à se soucier du coût. En revanche, on pourrait croire que cela soit onéreux en termes de requêtage des données sur un grand intervalle. Heureusement pour nous, Thanos a tout prévu et propose via son composant Compactor de l’échantillonnage et de la compression sur les blocs de données, réduisant ainsi le coût et le temps de requête. Il faut tout de même noter qu’il y a bien évidemment un impact sur l’intégrité des blocs de données, mais qui reste négligeable la plupart du temps.
C’est ainsi que non seulement Thanos va pouvoir répondre aux problématiques de Prometheus, mais tout cela en travaillant avec celui-ci, et c’est ce qui fait sa force.
Conclusion
Les points négatifs
Une infrastructure plus complexe
On passe d’un simple Prometheus à déployer à 4 composants Thanos ainsi que le service Store-Gateway, et le stockage distant. D’autant plus qu’il faut également configurer chacun de ces composants indépendamment. En outre, à échelle “multi-cluster”, tout comme avec Prometheus fédérateur on va devoir renseigner manuellement chaque endpoint pour notre Querier fédérateur ce qui demande un travail supplémentaire. Ainsi, même si tous les composants ne sont pas forcément obligatoires, on a tout de même une infrastructure plus complexe, qui demande plus de temps à mettre en place.
Une utilisation de ressources plus conséquente mais raisonnable
Nous n’avons pas abordé ce sujet dans cet article, mais lorsque nous avons testé Thanos, nous nous sommes entre autre intéressés à l'utilisation des ressources de la solution Thanos. Il faut savoir, que bien évidemment elle va utiliser plus de ressources qu’un simple Prometheus. Mais nous avons trouvé que la consommation reste tout de même raisonnable, la plupart des composants ne travaillant que lorsqu'ils sont sollicités tels que le Querier et le Store. Ainsi au niveau de l'utilisation du CPU, et de la RAM, je n’ai pas remarqué de changement significatif. En revanche, en termes de bande passante, étant donné que si l’on a configuré notre Thanos pour stocker ses données dans un stockage distant, celle-ci sera bien évidemment supérieure à celle d’un Prometheus qui ne l’utilise pratiquement jamais.
Mais la vraie raison pour laquelle l’utilisation de ressources se trouve dans les points négatifs est qu’à grande échelle, Thanos, malgré l'échantillonnage, va tout de même utiliser plus de ressources qu’un Prometheus. Ce que nous entendons par là est que contrairement à Prometheus, Thanos offre un stockage quasi-illimité, nous permettant ainsi de récupérer des métriques sur des intervalles beaucoup plus grands et requêter jusqu’à 1 an de métrique si on le souhaite. Sauf que vous l’aurez deviné, cela à bien évidemment un coût et notamment au niveau de l’utilisation des ressources. En outre, plus y’a de données dans le bucket, plus y’a un risque que nos composants Compactor et Store plantent lorsqu’ils sont sollicités. Heureusement pour nous, il est possible de partager la charge grâce au sharding.
Les points positifs
Un Prometheus plus hautement disponible avec une scalabilité optimisée
On a vu que Thanos départageais le travail de Prometheus parmi plusieurs de ces composants indépendants et très facilement scalable selon notre besoin. On sait également qu’il gère la déduplication des métriques et qu’il délègue toute la partie stockage à un Provider contrairement à Prometheus qui le gère en interne. Ainsi, là où Thanos soulage la gestion d'état, Prometheus se retrouve coincé avec des objets Stateful rendant la scalibilité assez limités, d’autant plus que celui-ci ne gère pas la déduplication à échelle multi-cluster.
Un stockage quasi-illimité et plus résilient
Nous savons que Thanos offre la possibilité de backup les données de Prometheus dans un stockage distant qui peut être un Object Storage géré par un Provider. Cela nous permet non seulement de stocker énormément de données sans nous coûter trop cher, mais également d’être résilient et sans le moindre effort. C’est le rôle du Cloud Provider de s’assurer que l’on puisse continuellement stocker nos données et que celles-ci soient toujours accessibles. La seule possibilité de perte de données est lorsqu’un Prometheus dysfonctionne, et selon notre configuration, il est possible de perdre toutes les données non envoyées au stockage distant. Heureusement, il existe plusieurs solutions pour pallier ce problème comme par exemple scaler nos Prometheus et de laisser Thanos gérer la déduplication et les trous de données.
Une vue globale à échelle multi-cluster
Enfin, nous avons vu que Thanos permettait à échelle multi-cluster d’avoir une vue globale sur nos Prometheus et cela de manière beaucoup plus optimisé qu’avec une fédération de Prometheus grâce à son approche ‘query’ qui récupère uniquement ce dont il a besoin.
En bref
Même si Thanos vient avec une architecture plus complexe, ainsi que plus de dépendances entre ses composants, je dois dire qu'après l'avoir utilisé pendant un certain temps, je pense qu'il en vaut totalement la peine. Ce qui fait son point fort, c’est son intégration avec Prometheus. Comme nous avons pu le voir, il est tout à fait possible d’ajouter la solution Thanos au-dessus d’un, voire de plusieurs Prometheus, nous permettant ainsi d’avoir un stockage quasi-illimité, une infra hautement disponible et une vue globale à échelle multi cluster. Tout cela de manière optimale sans forcément rendre notre infra plus coûteuse par rapport à la solution Prometheus.
En espérant vous avoir donné envie d’essayer Thanos, et qu’a tout utilisateur de Prometheus, vous avoir convaincu de ne pas hésiter à "upgrader" vos Prometheus à l’aide de la solution Thanos puisqu'à mon sens il faut vraiment voir celle-ci comme une extension à un prix non nul mais qui peut être justifié selon les besoins, d’autant plus qu’elle est maintenue par la communauté de Prometheus.
Dans le prochain article de la série, nous verrons une autre solution, encore plus récente, et avec sa propre approche, il s’agit de Victoria Metrics.