Tezos - LIGO patterns - Lambda
Cet article est une fiche technique illustrant l’utilisation de fonctions lambda lors de l'implémentation d’un smart contract Tezos. Le pattern de lambda permet de modifier la logique d’un smart contract déjà déployé, et ainsi le faire évoluer sans perdre les données du storage (voir l’article “Tezos - Gestion des évolutions d’un smart contract”). Ce genre d’anti-pattern peut être utile si notre service décentralisé est voué à évoluer (par exemple, à cause de règles étatiques). Dans cet article, un exemple d'implémentation est proposé sur le thème de l’exploration spatiale (un référentiel des astres du système solaire) !
Principe du pattern “Lambda”
Dans une blockchain, les données sont immuables, c’est-à-dire que les transactions une fois validées et intégrées dans un bloc ne peuvent plus être modifiées. De même, il n’est pas possible de modifier un smart contract déployé.
Par contre, le storage (la zone de stockage persistante associée à un smart contract) est évidemment voué à changer via les entrypoints (fonctions publiques appelable) du smart contract. En général, le storage contient des données, mais en Michelson, il est également possible de définir des fonctions anonymes (appelées Lambda en référence au lambda-calcul). Le compilateur LIGO supporte cette fonctionnalité; tout comme les autres compilateurs (Morley, SmartPy).
L’idée est de déporter une partie du code du smart contract dans une lambda dont le corps de la fonction est défini dans le storage. Le corps de la fonction lambda peut être modifié par l’invocation d’un entrypoint du smart contract. (C’est le même principe que pour les données du storage qui sont modifiées via des entrypoints). Le schéma ci-dessous illustre ce principe de définir la logique du contrat dans le storage sous forme de lambda.

Le schéma ci-dessous illustre l'exécution d’une transaction qui utilise une lambda. Les instructions à exécuter sont récupérées depuis le code du smart contract en fonction de l’entrypoint invoqué; et (dans le cas où une lambda est appelée) les instructions de la fonction lambda sont récupérées depuis le storage.
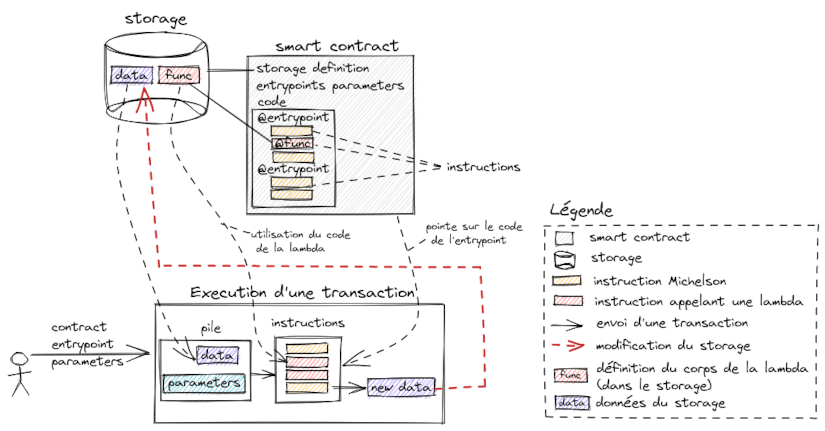
Il est donc possible de modéliser le comportement de notre smart contract à l’aide de fonctions lambda; et ainsi se laisser la possibilité de modifier le comportement attendu en fournissant une nouvelle implémentation de la fonction lambda.
Syntaxe d’une fonction lambda en LIGO
En LIGO, une fonction lambda est une fonction anonyme définit par un type (indiquant ses paramètres et son retour) et une suite d’instructions (le corps de la fonction).
Un type de lambda suit la syntaxe suivante (en cameligo) :
Dans le code de l’exemple
L’initialisation d’une fonction lambda suit la syntaxe suivante (en cameligo) :
Use case
Dans l’esprit de la blockchain le comportement d’un smart contract devrait être immuable, le code ne change pas donc le comportement reste invariant. La lambda pourrait être considérée comme un anti-pattern puisque l’idée de déporter la logique d’un smart contract dans le storage (qui lui est dynamique) brise cette “idée” d’invariance.
En s’appuyant sur le fait que le storage est dynamique contrairement au code du smart contract, l’implémentation à l’aide de lambda permet de faire évoluer le comportement d’un smart contract déjà déployé.
En pratique, si la gouvernance du service décentralisé est instaurée, il devient possible de faire évoluer son service sans perdre ses données, faire évoluer le fonctionnel malgré le fait que ce soit un smart contrat déployé !
Attention, ici, seul le fonctionnel est modifiable; on ne touche pas à la structure des données (storage), et le prototype de la fonction lambda ne peut pas être modifié. Par contre, il est possible d’utiliser un dictionnaire (map) pour généraliser le stockage des données et ainsi permettre un peu de souplesse vis-à-vis des paramètres attendus par la lambda.
En théorie, pour une blockchain publique, la modification du code d’un smart contract déjà déployé représente un risque potentiel. De plus, la gouvernance est un enjeu majeur lorsqu’il s’agit de modification du code du smart contract !
Exemple
Dans cette section, nous allons voir en détail, l’implémentation d’un smart contract utilisant une fonction lambda.
Nous appliquerons ce “pattern” à un cas peu concret, le système solaire ! En 2006, l’International Astronomic Union a changé les règles définissant l'appellation “planète” (règles).
Si un service (référentiel d’astres célestes du système solaire) décentralisé (c’est-à-dire implémenté au sein d’un smart contract) devait faire face à un tel changement, comment fait-il pour s’adapter aux nouvelles règles ? Il y a plusieurs scénarios possibles:
- (batch) un nouveau contrat , on recode tout , on perd toutes les données du storage (toutes les informations liées à l’ancien contrat). Dans le cas de Bitcoin, ça revient à perdre les balances des utilisateurs !!! bref beaucoup de données critiques !
- (à la volée) un nouveau contrat qui récupère données sur l’ancien contrat (Il fallait que le contrat soit prévu pour extraire les données, et qu’il utilise la fonction get_entrypoint_opt) et fait le calcul avec la nouvelle logique, et enfin sauvegarde la nouvelle valeur dans le storage.
- La bonne pratique en LIGO consiste à utiliser des lambdas. On change les règles et potentiellement on met à jour le storage.
Implémentation
Considérons un smart contract StarMap qui a pour rôle de répertorier les corps célestes du système solaire et de les classifier. Par classifier ,on entend attribuer une "catégorie" à un astre céleste; plus génériquement, une propriété calculée en fonction d’un algorithme.
Le script LIGO est implémenté en cameligo.
Voici le code complet de notre exemple.
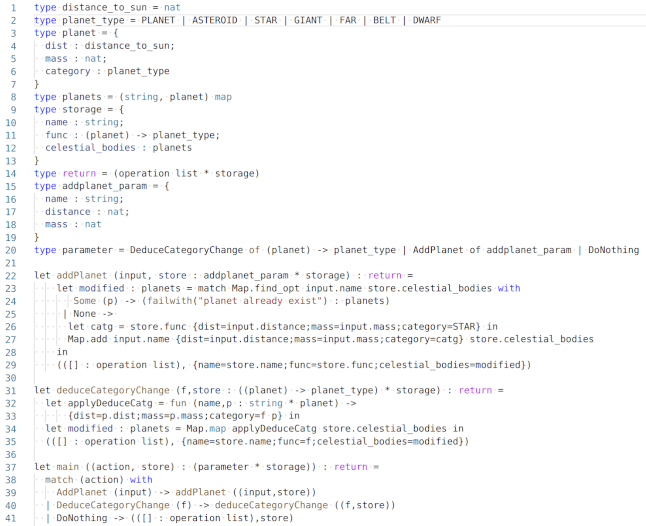
Les points à retenir dans le code
Tout d’abord, on peut remarquer que ce smart contract possède 2 entrypoints (AddPlanet, DeduceCategoryChange), et un entrypoint par défaut (DoNothing) qui ne fait rien.
Ligne 11 - le prototype de la fonction lambda définit dans le storage
Ligne 20 - la définition d’un entrypoint qui prend en paramètre la fonction lambda
Ligne 26 - l'application de la fonction lambda (qui est enregistrée dans le storage)
Ligne 33 - l'application d’une fonction lambda (passée en paramètre)
Ligne 35 - le remplacement de la lambda avec une nouvelle implémentation
Dans la section suivante , nous verrons l'implémentation du corps de la fonction lambda. La syntaxe est similaire à la fonction applyDeduceCatg (L32-33).
On peut remarquer l’utilisation de Map.map (L34) qui permet d’appliquer une fonction à tous les éléments d’une map.
Définition de la lambda lors du déploiement
La commande suivante permet de préparer un storage (c’est-à-dire de produire une expression Michelson correspondant à un storage écrit en LIGO). Ce storage (en Michelson) sera utilisé lors du déploiement, mais cette commande permet de s’assurer que la lambda est syntaxiquement bien écrite.
Dans notre exemple, il faut définir le nom du système solaire, les astres et la lambda permettant de catégoriser les astres.
On peut remarquer dans le storage, que la fonction lambda func est spécifiée par un algorithme très simple (“si la masse est plus grande que 100 alors c’est une planète sinon c’est un astéroïde”).
fun (p : planet) -> if p.mass > 100n then PLANET else ASTEROID
Ici les mot clé fun déclare une fonction lambda prenant en paramètre p de type planet.
Le corps de la fonction est déclaré après l’opérateur -> suivant la syntaxe :
fun (<parameters>) : <returned> -> <body>
Notez que le type de retour est optionnel car dans certains cas il peut être déduit directement par le typechecker.
Invocation du smart contract
Ajout d’une planète
Le smart contract Starmap propose l’entrypoint AddPlanet pour ajouter de nouveaux astres célestes dans notre référentiel du système solaire.
La commande suivante permet de simuler l’exécution de l’entrypoint AddPlanet, dans notre cas le système solaire contient la terre et le soleil, et on tente d’ajouter une planète (mars).
La sortie de cette commande permet de visualiser le storage résultant.
On remarque que le storage contient une nouvelle planète (“mars”) et sa catégorie (PLANET) a été calculée en appliquant l’algorithme spécifié dans la fonction func. On remarque que tous les astres sont des planètes.
Voyons maintenant, si on change la règle.
Modification de la lambda (du storage)
La commande suivante permet de simuler l’exécution de l’entrypoint DeduceCategoryChange qui permet de changer la fonction de catégorisation. La nouvelle implémentation de la lambda est enregistrée dans le storage (L35, avec func=f), et appliquée à tous les astres répertoriés (L34, à l’aide d’un map.map).
On peut remarquer que la nouvelle lambda (passée en paramètre à l’entrypoint DeduceCategoryChange) possède un algorithme un peu plus complexe et gère plus de catégories différentes. La sortie de cette commande permet de visualiser le storage résultant :

On peut remarquer que les catégories de chaque astre ont été mises à jour avec le nouveau comportement (le soleil est une étoile et Jupiter une géante gazeuse, ...).
Conclusion
Nous avons vu en détail l’implémentation d’un smart contract utilisant une fonction lambda permettant de modifier le comportement du smart contract.
Cet “anti-pattern” lambda peut être très utile pour garantir un minimum d’évolutivité d’une Dapp, par contre il ne touche pas à la structure des données. Il est intéressant de prévoir une gestion dynamique des données (en utilisant une map) en plus de la lambda.
Penser l’implémentation d’un smart contract avec des lambdas a ses avantages car il permet de faire évoluer son service, mais par contre il nécessite une gouvernance (qui décide du nouveau comportement ? Comment se passe la transition entre l’ancien et le nouveau comportement ? ). La responsabilité d’un tel changement pourrait être partagée grâce à un pattern de multi-signature.
Autre point à noter, changer le comportement d’un smart contract peut induire de changer beaucoup de données et donc être coûteux lors de l'exécution.