Le front, au delà du coloriage : émergence des composants applicatifs
Notre utilisation du Web change. Initialement conçus pour consulter des documents, les navigateurs sont devenus de puissants moteurs de rendu capables d'exécuter des applications complexes permettant la création de documents riches tels que Google Doc, ou la consommation de média en streaming via Netflix ou Spotify.
Les documents se sont peu à peu transformés en applications. Là où quelques scripts suffisaient pour ajouter de simples animations ou effets graphiques, nos applications sont devenues de véritables clients riches et les bases de code se sont rapidement alourdies. La surface d’apparition de bugs s’en est trouvée augmentée.
Fort heureusement, les artisans que nous sommes avons dans notre boîte à outil un ensemble de pratiques et de techniques qui nous permettent de gérer cette complexité : refactorisation, tests automatisés, principes de code, …
Or, si ces pratiques sont bien documentées pour une certaine classe d’applications, elles laissent bien souvent les développeurs dubitatifs quant à leur applicabilité dans le développement d’IHM. Cet article propose de montrer qu’il est tout à fait possible de les utiliser, avec des exemples d’implémentation concrètes à la clé.
Test unitaire ? Test d’intégration ?
Aucun test ne sera qualifié de test “unitaire” ou “d’intégration”. L’objet de cet article est d’écrire des tests et de concevoir des composants en isolation :
- de potentielle logique métier ;
- des contraintes du navigateur ;
- des entrées / sorties telles que le réseau.
Les tests prenant en compte ces contraintes, dits tests intégrés, feront l’objet d’un prochain article.
Pour les lecteurs qui souhaitent suivre avec le code sous les yeux, le support est disponible :
- sur un éditeur en ligne : https://bit.ly/38K9l9c
- sur Github : https://bit.ly/3vxcYsX
Approche par l’exemple
Afin de découvrir comment maîtriser la complexité grandissante de nos applications clientes, nous vous proposons une approche par l’exemple. Fidèle à la tradition du Hello World version IHM, nous avons ainsi choisi comme exemple un Compteur Chat. Il doit permettre d’envoyer des messages et les afficher dans une conversation.
Afin de se concentrer sur l’essentiel, le périmètre fonctionnel de notre interface est volontairement réduit. De plus, les communications réseaux, les règles métiers, … ne sont pas portées par l’interface et à ce titre ne sont pas l’objet de cet article.
L’application cible que nous souhaitons réaliser s’inspire de la maquette suivante :
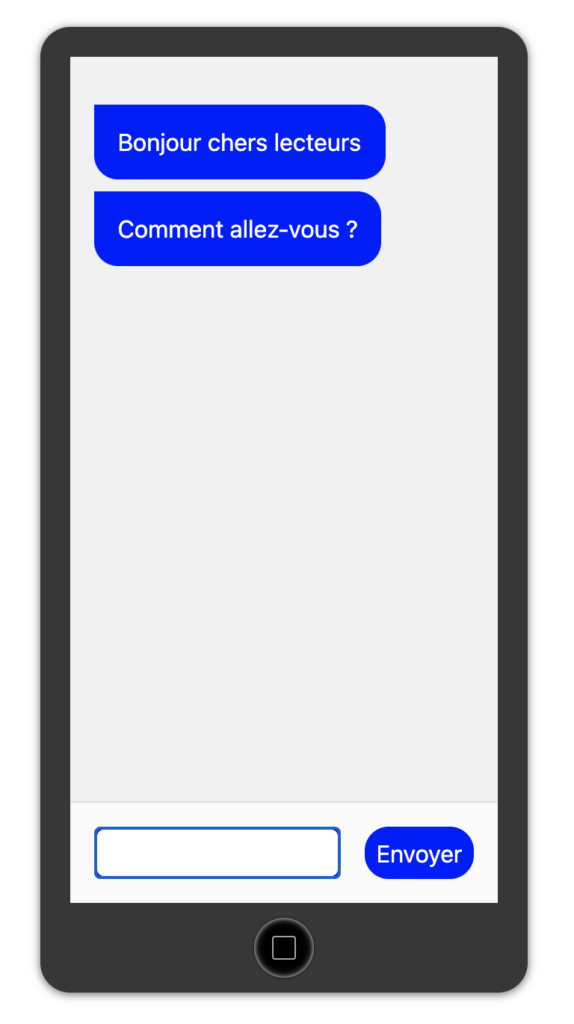
Cette messagerie offre la possibilité aux utilisateurs de saisir leurs messages (dans la zone “Votre message…”) et de les envoyer pour qu’ils apparaissent dans la conversation (la liste de messages en haut de l’écran). La fonctionnalité est décrite ainsi :
Fonctionnalité : Participer à une conversation
Scénario : Envoi de messages non vide
Etant donné une conversation
Lorsque j’ajoute un premier message “Bonjour”
Et que j’ajoute un deuxième message “Comment allez-vous ?”
Alors les deux messages apparaissent dans la conversation dans l’ordre chronologique
Et la zone de saisie est vidée
Scénario : Envoi d’un message vide
Etant donnée une conversation
Et que la zone de saisie contient le message “ “
Lorsque je tente d’envoyer mon message
Alors celui-ci n'apparaît pas dans la conversation
Et la zone de saisie contient toujours le message “ “
L’exemple étant présenté et spécifié, il est temps de s’attaquer à l’implémentation de notre fonctionnalité. En tant qu'artisans du Web convaincus par la pratique des tests automatisés, la première étape de notre démarche consiste à écrire un test rouge.
Commençons par un test rouge
Un test qualifié de “rouge” est un test qui ne passe pas. Dans l’approche test-first, le développeur commence par écrire un test en échec qui montre que le code actuel ne couvre pas la fonctionnalité attendue. La mission de notre nouveau test sera de garantir le cas d'utilisation : envoyer un message.
Lorsque nous adoptons la pratique du test automatisé, nous écrivons du code qui va vérifier les effets observables d'un système en fonction des entrées qui lui sont fournies. Cela peut vouloir dire que l'on teste la valeur de retour d'une fonction par rapport aux paramètres donnés ou encore les valeurs persistées suite à un appel API avec un certain payload.
Dans cet exemple, l’objectif est de vérifier que notre application répond bien à l'utilisateur en fonction de son état initial et des différentes interactions. L’utilisateur va envoyer un message en le saisissant et en cliquant sur Envoyer. Le test consiste alors à vérifier que le résultat de ce scénario - les messages, sont présents dans le DOM.
On veut voir du code !
Une note sur le tooling...
Il fallait pour cet article faire le choix d’une implémentation des composants. Nous avons choisi React et @testing-library/react comme librairie de tests, mais les principes sont applicables à n'importe quelle autre implémentation. Les exemples seront rédigés en TypeScript.
… et sur TDD
Dans cet article, nous utilisons les tests pour guider le design de nos composants. Pour des raisons de concision, TDD n’est pas utilisé dans cet article puisque l’exemple deviendrait trop verbeux. Il reste toutefois très adapté à cette approche.
Un bon test se lit facilement. Dans notre exemple, l’utilisateur est la métaphore qui nous inspire et permet d’écrire un test expressif : il clique sur des éléments, et utilise son clavier pour saisir des informations. Ces interactions sont le point d’entrée de nos tests.
Le test doit également dévoiler son intention, raconter une histoire. Il doit par exemple vérifier que lorsque l’utilisateur tente d’envoyer trois messages, dont un vide, alors les deux messages non vides apparaissent bien à l’écran. Ce test doit pouvoir s'écrire rapidement, sans friction, et en quelques lignes.
Bien qu’étant des tests d’IHM, nos tests doivent également respecter les principes F.I.R.S.T.^<a href="#ref-1">1</a>^ Les tests doivent :
- se lancer de manière automatique ;
- produire toujours le même résultat ;
- fonctionner en isolation les uns des autres ;
- s'exécuter dans un temps raisonnable ;
- être écrits de préférence avant le code d'implémentation.
Avec ces éléments en tête, nous proposons le test suivant :
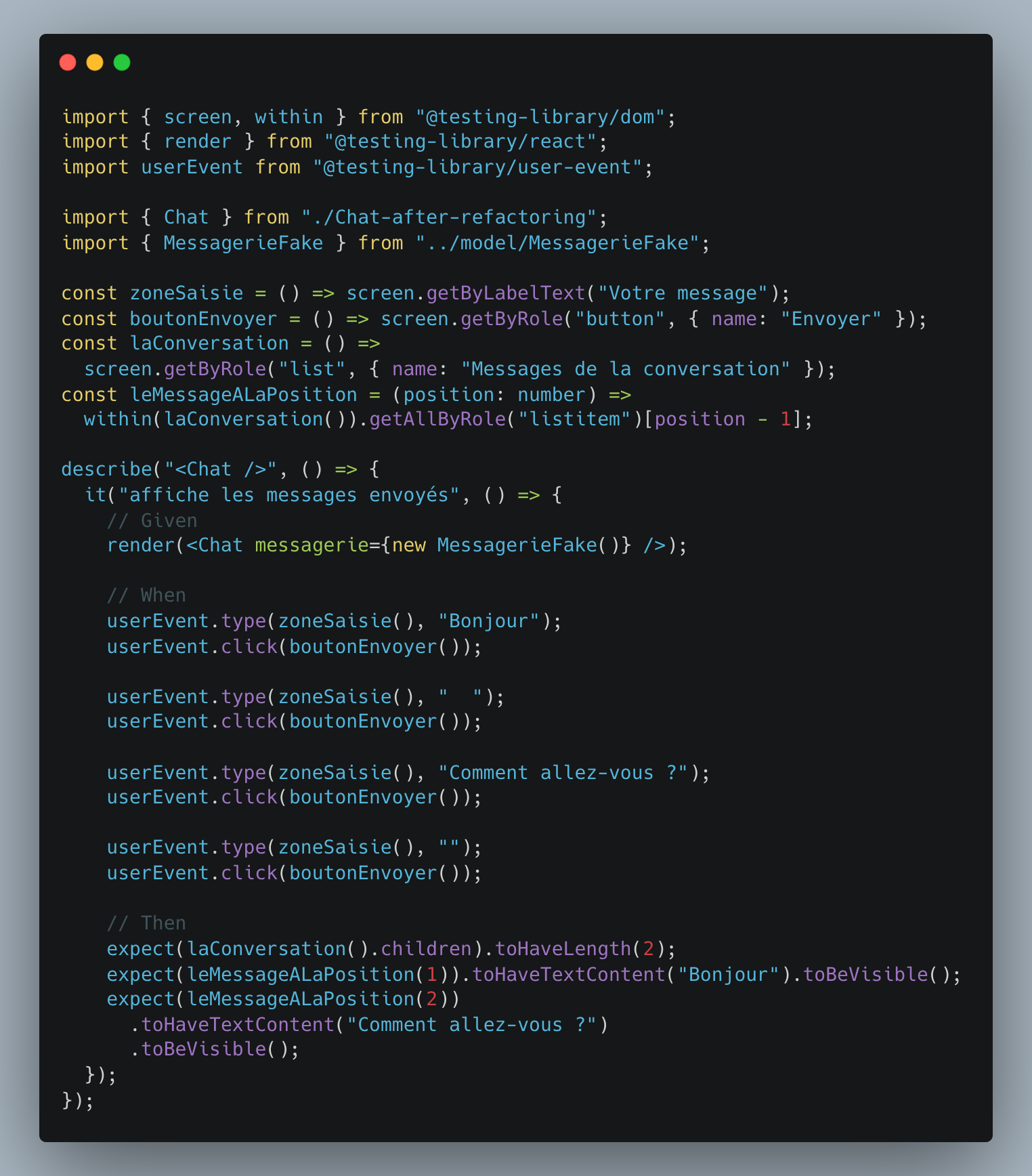
Bien que le système testé soit une portion d’IHM, ce test tourne dans un environnement qui émule le DOM : il est donc isolé et rapide. Une implémentation de test (MessagerieFake) de l’interface Messagerie est injectée dans notre <br><Chat /><br> : il est donc également isolé de la couche métier et des détails techniques tels que les communications réseau. Ce <br><Chat /><br> sera compatible avec n’importe quelle implémentation de Messagerie. Deux autres implémentations (WebSocket et HTTP) sont disponibles pour référence sur le code support de l’article.
Voyons si d’autres propriétés sont vérifiées par ce test.
Tester ce que fait notre IHM
Si le comportement de l’IHM change, alors les vérifications faites dans ce test doivent changer. Il est couplé aux comportements observables du système testé. Si le comportement testé change, mais que le test reste vert, alors ce test n’est pas comportemental.
Comportemental : Les tests devraient être sensibles aux changements de comportement du code testé. Si le comportement change, alors les résultats du test changent.
Ne pas tester les détails d'implémentation
Pour autant, ce test ne repose sur aucun détail d’implémentation. Il ne comporte aucune mention des fonctions, classes et structures de données sous-jacentes : notre test est donc insensible à la structure du code de production. Si un test doit être modifié suite à une refactorisation du code de production, alors il est sensible à la structure de celui-ci.
Insensible à la structure : Le résultat des tests ne doit pas changer si la structure du code de production change.
A propos du Snapshot Testing
Le snapshot testing permet de comparer le DOM suite à une modification du code avec celui d'une précédente implémentation, utilisée comme référence. Lors du premier run, la sortie du composant testée est enregistrée. Le test échoue si la nouvelle sortie ne correspond pas à cette référence.
Il s’agit de la forme ultime de couplage aux détails d’implémentation exposés dans le DOM : il empêche par exemple la refactorisation d’un <br><input type=“submit“ /><br> et <br><button type=“submit“><br>, sémantiquement équivalents. De plus, le snapshot testing ne révèle aucune intention et n'est absolument pas insensible à la structure.
Leur utilisation peut par contre être justifiée dans le cadre d’une intégration avec du legacy, où d’autres composants se basent sur la structure interne du composant testé à des fins stylistiques.
Inclure l’accessibilité dans la stratégie de tests
Il aurait été possible de tester l’interface par des sélecteurs techniques incluant par exemple :
- les sélecteurs par identifiant :
<br>#mon-element<br>; - les sélecteurs par classe
<br>.mon-element<br>; - les sélecteurs composites
<br>header > a<br>
Néanmoins, nous choisissons d’accéder aux éléments en utilisant leur contenu accessible (les accessible names). Ils incluent par exemple :
- les labels ou les rôles pour les éléments interactifs ;
- le contenu textuel affiché à l’écran pour le contenu non interactif
Cette pratique a un double avantage. D’une part, elle permet de s’assurer à travers nos tests que le contenu affiché à l’écran est accessible par défaut : si le composant n'est pas accessible, alors ni l'utilisateur, ni le test ne pourra interagir avec lui. L’accessibilité est intégrée dans notre stratégie de tests.
D’autre part, cette pratique offre de la flexibilité : il est possible de remplacer chaque élément du DOM par un autre sémantiquement équivalent. Il serait tout à fait envisageable de passer d’un <br><input type=”submit” /><br> à un <br><button type=”submit”><br> pour faciliter la customisation graphique sans impacter nos tests.
Une pratique répandue consiste à rajouter des attributs data-testid dans le DOM pour sélectionner nos éléments. Elle apporte les mêmes défauts que l’approche par sélecteurs techniques, et pollue le code de production. Après tout, vous ne rajoutez pas de code de production dans votre backend afin de pouvoir le tester, n’est-ce pas ?
Vérifications automatisées et accessibilité
Beaucoup de critères sont contextuels et méritent une appréciation humaine : comme la hiérarchie de titre, par exemple. On estime cependant qu’environ 25% des critères d’accessibilité sont vérifiables de manière automatique : éléments sémantiques, labels, et contrastes de couleurs par exemple. Le but de notre approche est donc d’inclure au maximum les éléments automatiquement vérifiables dans notre stratégie de tests.
<HelloWorld /> : Bienvenue dans le monde des composants
Maintenant que nous avons écrit un test, nous pouvons commencer à écrire le code de production. Le point d’entrée de notre fonctionnalité est un élément incontournable des applications web modernes : un composant. Le composant est l’unité de travail principal du développement d’IHM. Nous allons le voir par la suite, il permet l’encapsulation et la réutilisation de vues et d’interactions avec les utilisateurs.
Un premier jet
Après quelques minutes de réflexion, le code minimal nous permettant de faire passer le test au vert est le suivant :
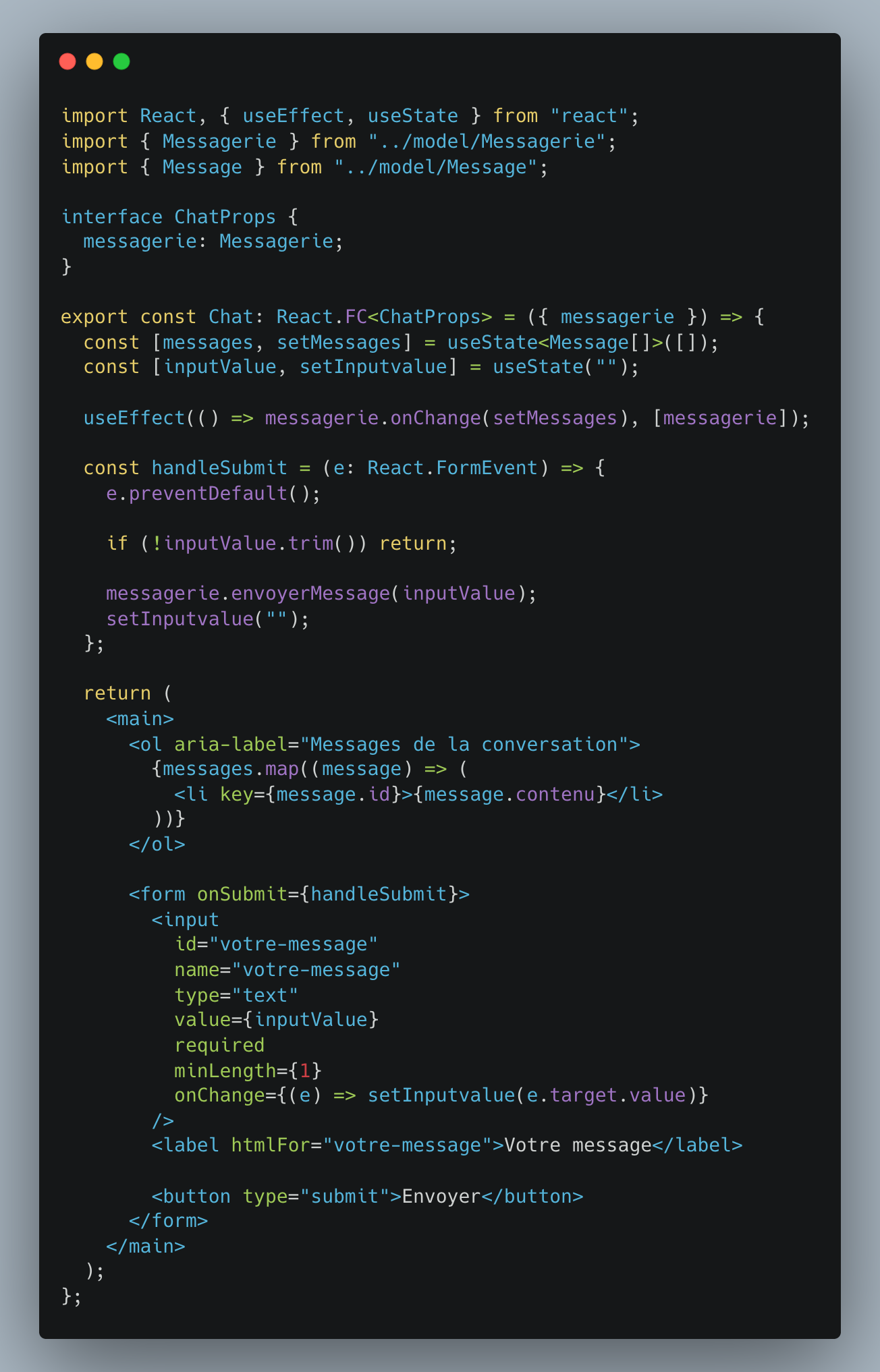
Il s’agit d’un unique composant <br><Chat /><br> qui :
- affiche la liste ordonnée (
<br><ol /><br>) des messages de la conversation ; - affiche un formulaire contenant la zone de saisie (
<br><input /><br>) permettant la rédaction d’un nouveau message non vide
Ce code de production, bien que premier jet, présente déjà les bénéfices de l’approche orientée composants. A travers un simple appel à <br><Chat messagerie={messagerie} /><br>, les utilisateurs du composant bénéficieront d’un widget fonctionnel permettant la saisie d’un message et l’affichage de la conversation. Les composants permettent donc d’encapsuler et de réutiliser des comportements.
Cependant, le code interne au composant <br><Chat /><br> est devenu lui-même porteur de complexité. Nous pouvons notamment observer que du code permettant la gestion des messages - un concept haut-niveau proche de notre domaine - est mélangé avec du binding vers notre <br><input /><br> html - un concept bas niveau proche de l’infrastructure. Le constat : le principe Single Layer of Abstraction (aussi connu comme l’expression don’t mix different levels of abstraction^<a href="#ref-2">2</a>^) n’est pas respecté.
La refactorisation
Heureusement, nous connaissons déjà des outils permettant d’ajuster le niveau d’abstraction dans notre code : il s’agit bien souvent des fonctions et des méthodes. Dans le cadre du développement d’interfaces, le meilleur outil permettant d’ajuster le niveau d’abstraction est le composant (Un lecteur attentif aura d’ailleurs noté qu’avec la forme function component de React, un composant est une fonction).
Nous entrons alors dans l'étape de refactorisation de notre cycle de développement, avec des outils parfaitement adaptés pour améliorer le design du composant <br><Chat /><br>.
La méthode “extract component”, une technique similaire à “extract function^<a href="#ref-3">3</a>^” , permet d’uniformiser les niveaux d’abstraction. En résultent alors deux nouveaux composants :
<br><Rédaction />,<br>composant responsable de la saisie d’un nouveau message ;<br><Conversation /><br>, composant responsable de l’affichage de la liste des messages par ordre chronologique
Le code de production est alors refactorisé :
Cette étape permet d'harmoniser les niveaux d’abstraction :
- le composant
<br><Chat /><br>utilise le langage omniprésent^<a href="#ref-4">4</a>^ de notre domaine métier : message, conversation, rédaction ; - la logique d’infrastructure, les éléments de formulaires, sont encapsulés dans le composant
<br><Rédaction /><br>, qui expose la fonctionnalité en utilisant des termes de notre domaine ; - le viewmodel a été isolé dans la fonction useChat (La notation
<br>useXXX<br>est propre à React).
Une propriété intéressante se dégage de cette ré-écriture : les composants <br><Conversation /><br> et <br><Rédaction /><br> ne sont pas exportés. C’est ce que l’on qualifie de communément de détails d’implémentations, Ils n’existent pas aux yeux du reste de l’application. Ils sont privés, locaux à notre composant <br><Chat /><br>.
Il peut être tentant de les considérer séparément et de vouloir les tester en isolation. Cette stratégie peut être porteur de sens dans certaines situations spécifiques. Néanmoins, il nous semble qu’elle amène avec elle les deux inconvénients majeurs suivants :
- D’une part, elle consommerait du temps de développement sans apporter aucune valeur ou documentation métier, en faisant écrire des tests sur chacun d’entre eux.
- D’autre part, et de façon plus problématique, elle couplerait fortement la structure de notre code à son comportement. Or ce couplage introduit un frein majeur à la liberté de pouvoir refactorer librement la structure en toute sécurité, sans être pénalisé dans le développement par des tests cassants à la moindre modification ! Cela nous semble être un risque pour la qualité du code sur le long terme.
A propos du Shallow Rendering
Comme montré dans notre exemple, les composants ont des enfants, qui eux mêmes peuvent avoir des enfants. Le shallow rendering consiste à n'effectuer, dans les tests, le rendu que d’un seul niveau de profondeur des composants.
Il n'est pas nécessaire d’utiliser le shallow rendering puisque le comportement des composants enfants est testé à travers leurs interactions avec le composant parent. Si l'ensemble produit le comportement attendu, alors on admet que tous les composants sont implémentés correctement. Le shallow rendering ajoute encore un point de couplage entre nos tests et notre framework graphique puisqu’on ne fait plus nos vérifications sur des éléments du DOM, mais des composants du framework.
C'est même contre productif, car dans notre exemple, il aurait fallu modifier le test dans la phase de refactorisation pour l’adapter à la nouvelle structure.
Et bien entendu, nos tests sont toujours verts !
Conclusion
Cet exemple montre qu’il est possible d’utiliser les tests pour guider l’implémentation d’une IHM dans un paradigme composants. En utilisant l’API publique des composants - ce qui est exposé de manière accessible dans le DOM - les détails d’implémentation sont ignorés, ce qui offre une opportunité d’améliorer le design du code librement. Au cours de cette étape de refactorisation, les développeurs peuvent appliquer des techniques de refactorisation classiques, telles que extract function, lorsque des anti-patterns tels que Single Layer of Abstraction sont détectés.
Le fait d’avoir écrit un test insensible à la structure du code de production permet d’extraire des composant ainsi que le viewmodel qui est responsable de l’interactivité, faisant ainsi émerger la structure de l'application.
Pour découpler encore plus les tests de notre code de production, nous utilisons exclusivement des sélecteurs du DOM basés sur le contenu accessible de notre application. Il est important de noter qu’un élément non sélectionnable avec cette stratégie depuis un test est un signe de défaut d’accessibilité.
En utilisant les composants comme unités d’abstraction, nous avons réussi à diviser notre interface en sections nommées selon le langage omniprésent de notre domaine. Ces pratiques nous permettent de maitriser la complexité grandissante de notre système.
Pour autant, un lecteur attentif aura remarqué que nous n’avons pas beaucoup parlé de réutilisation : celle-ci n’est pas la vocation de ces composants dits applicatifs. Les composants permettent l’encapsulation, et par extension peuvent être réutilisables.
Dans un prochain article, nous nous intéresserons aux composants génériques, dits UI, dont le but n’est pas de découper l’application pour s’aider à se la représenter mentalement, mais d’être réutilisés pour accélérer les développements.
Pour aller plus loin
Pour ceux qui souhaitent aller plus loin, le code est disponible dans un éditeur en ligne, à cette adresse : https://bit.ly/38K9l9c.
<sup id="ref-1">1.^ Ces propriétés sont aussi connues sous l'acronyme F.I.R.S.T popularisé dans Clean Code (page 132) par Robert C. Martin
<sup id="ref-2">2.^ Robert C.Martin (2008) - Clean Code: A Handbook of Agile Software Craftsmanship (page 36)
<sup id="ref-3">3.^ Martin Fowler (2018) - Refactoring: Improving the Design of Existing Code
<sup id="ref-4">4.^ Eric Evans (2003) - Domain-Driven Design : Tackling Complexity in the Heart of Software