Systèmes d'aide et d'assistance [2/2]
Après avoir étudié les systèmes d’aide traditionnels, nous allons maintenant aborder ceux, moins fréquents, qui font appel à des techniques issues de l’intelligence artificielle. Certes plus exigeants pour les utilisateurs, ces systèmes offrent en échange une aide plus pertinente et plus adaptée. Ce second article va présenter trois de ces techniques, chacune basée sur un principe différents mais ayant toutes le même objectif : s’approcher au plus près du comportement de l’être humain afin de pouvoir prédire ses objectifs et de l’assister dans la réalisation de ceux-ci.
Les réseaux Bayésiens
Pour remédier à cet absolu du système d’aide contextuel, une approche consiste à utiliser les théories de Thomas Bayes.
Présentation

{kind=link}
{kind=link}
Figure 4 Système d'aide bayésien
Alors, certes, Clippy n’a pas été le système d’aide le plus aimé du monde. C’était même plutôt le contraire. Cependant, l’approche théorique derrière le trombone se basait sur les approches de Bayes. Le principe consiste à enrichir une aide contextuelle à l’aide de probabilités, permettant d’intégrer dans cette aide l’ensemble des scénarios décrits plus haut, en leur affectant à chacun une probabilité d’être le bon. Cette probabilité n’est pas fixe et évolue en fonction d’une modélisation de l’utilisateur interne au système d’aide. Cette modélisation est primordiale, car elle fait entrer dans le système d’aide un nouvel acteur : l’utilisateur.
Dans un réseau bayésien, les probabilités d’occurrence d’un scénario sont posées en regard de l’expertise de l’utilisateur, le novice se voyant proposer des scénarios simples, alors que l’expert ne les verra pas, mais aura accès à des scénarios plus complexes. Par ailleurs, la qualité de l’utilisateur n’est pas définie sur un seul axe (simple/complexe), mais par domaine d’affinités. Les scénarios ont ainsi une affinité définie les uns avec les autres, ce qui permet, lorsqu’un utilisateur acquiert une expertise (principalement en réalisant les scénarios), celle-ci se diffuse aux domaines voisins.
On introduit ici la notion d’expertise partielle, qui est nécessaire compte tenu de la complexité des logiciels aidés.
Limitations
La principale limitation de ce type de système, criante lorsqu’on a subit Clippy, est le temps de construction du modèle d’expertise de l’utilisateur, et la garantie de l’unicité de celui-ci.
Premier problème : un ordinateur a souvent plusieurs utilisateurs qui, par facilité, n’ont pas chacun un profil différencié. Comment dans ce cas obtenir un modèle d’expertise fiable alors que, sous le même profil se trouvent l’uber-geek, son papa qui s’y connaît un peu et sa maman qui utilise Word une fois par an ? Si des tentatives ont été faites en ce sens, en relevant les incohérences entre le comportement actuel et le modèle enregistré, il n’existe pas de manière fiable de faire ce distinguo. Un tel système est donc voué à l’échec dès lors que plusieurs utilisateurs se partagent le même identifiant.
Second problème : Pour des raisons évidentes, tout utilisateur nouveau est considéré novice. Bien sur, ce n’est souvent pas le cas, puisqu’il a déjà utilisé la version précédente, voire vient de réinstaller son système. Il faut donc bâtir le modèle d’expertise de l’utilisateur et cela ne peut se faire qu’avec sa coopération. Sauf qu’un utilisateur n’est pas prêt à passer des heures à ajuster son modèle d’expertise dans le seul objectif de bénéficier de l’aide. Ainsi, à titre d’exemple, un Clippy neuf propose toujours des scénarios basiques. Avec un peu d’entraînement (de l’ordre d’un mois ou deux), il devenait pertinent, mais aucun utilisateur n’a eu la patience de l’entraîner pendant un mois ou deux, surtout en sachant que cet entraînement était perdu au changement de poste ou de version d’Office.
Comment construire un réseau bayésien
Un réseau bayésien se construit comme une aide contextuelle, avec un modèle d’expertise supplémentaire, qui sert à fixer les probabilités d’occurrence des scénarios d’aide.
La construction d’un tel système demande une phase d’opération active de l’utilisateur, pendant lequel le système d’aide se positionne sur un niveau inférieur de complexité. Ainsi, dans un premier temps, il doit être impossible de différencier réseau bayésien et système d’aide contextuelle. Puis, au fur et à mesure de l’observation de l’utilisateur, les poids des scénarios vont se modifier et l’aide pourra alors gagner en pertinence par rapport au profil de l’utilisateur.
Un réseau bayésien doit également être accepté. En effet, il impose l’utilisation d’un profil unique, ainsi que l’effort d’exporter/importer ce profil lorsqu’on change d’environnement (chose que Clippy ne proposait pas). L’utilisateur non coopératif n’en verra donc pas les bénéfices. Si, dans le cadre d’un logiciel grand public, cette coopération est dure à obtenir, elle est cependant atteignable dans les logiciels du monde professionnel, où l’utilisateur comprend l’intérêt de la manœuvre.
Les réseaux neuronaux
Une autre solution permettant de prendre en compte l’utilisateur est de lui permettre d’entraîner le système d’aide de manière à ce qu’il corresponde à ses attentes. C’est le principe du réseau de neurone, dont la vie se partage en deux grandes étapes : apprentissage et exploitation
Présentation
Le principe d’un réseau de neurone est très simple : il s’agit de faire correspondre un signal de sortie à un signal d’entrée. Calqué sur le modèle biologique, le réseau de neurone reçoit des stimuli de l’extérieur, qui proviennent de différentes sources et sont hétérogène, et produit lui-même des stimuli à destination de l’extérieur, là aussi hétérogènes et vers différentes sources.
Ainsi, les réseaux sont utilisés, par exemple, dans le domaine de la recherche pharmaceutique. L’objectif est d’accélérer la mise au point de nouvelles molécules en faisant ‘deviner’ par un réseau, en fonction des expérimentations passées, quel sera le degré de réussite d’une nouvelle molécule.
La phase d’exploitation
Un réseau de neurones possède donc deux vecteurs : un vecteur d’entrée, correspondant aux stimuli venant de l’extérieur et un vecteur de sortie, correspondant aux stimuli envoyés vers l’extérieur. Cette transformation se fait pas passage du signal à travers une ou plusieurs couches de neurones intermédiaires (dites « cachées »). Chaque neurone émet un signal en sortie en fonction de l’excitation reçue en entrée. Selon le type du neurone (à seuil, linéaire, sinusoïdal, …), la forme du signal de sortie varie, mais le résultat pour l’utilisateur est le même : en fonction de ses actions, une assistance ad hoc est proposée. Il est à noter que dans un système d’assistance, afin de prendre en compte l’aspect temporel d’une demande d’aide, qui prend place non pas en fonction d’un état mais d’un flux, il est recommandé d’avoir un feedback, c'est-à-dire soit de brancher une partie du vecteur de sortie sur le vecteur d’entrée, prenant ainsi en compte l’état T-1 dans al détermination de l’état T, soit d’utiliser des neurones avec fonction d’atténuation, c'est-à-dire des neurones dont l’état d’excitation retombe lentement et non pas immédiatement.
On voit ici l’avantage fondamental du réseau de neurones : la prise en compte du temps. Si, dans ce système, l’utilisateur n’est pas aussi finement modélisé que dans un réseau bayésien, sa trace d’utilisation, c’est à dire son action dans le temps, est prise en compte. Cela permet alors d’affiner les prédictions, en retardant ou précipitant l’aide selon ce que fait l’utilisateur. Un exemple simple est celui des commandes Undo/Redo. Une utilisation répétée de ces commandes active rapidement le réseau et produit une aide, puisque cela indique que l’utilisateur cherche, à travers des essais/erreurs, comment réaliser une tâche.
La phase d’entraînement
Bien qu’arrivant chronologiquement avant la phase d’exploitation, elle est présentée ici en dernier, car cette phase consiste simplement à déterminer quels seront les poids que chaque neurone affectera à ses entrées. La manière d’affecter ces poids est le plus souvent pavlovienne. Un réseau qui fournit la mauvaise réponse se prend une baffe et ce, jusqu’à ce qu’il donne la bonne. On l’entraîne ainsi sur un certain nombre de situations données et les autres situations sont alors prises en compte par similarité. Cette phase doit être la plus longue possible afin d’avoir le réseau le plus pertinent possible. La capacité d’un réseau de neurone à appréhender de nouveaux cas est en effet directement proportionnelle au nombre de situations « mémorisées » pendant l’entraînement.
Limitations
Le réseau de neurone perd la force du réseau bayésien. Il ne prend plus en compte l’expertise de l’utilisateur, ou alors de façon indirecte par le biais des variations dans le vecteur d’entrée, qui sont différentes selon le degré d’expertise. De plus, la phase d’apprentissage est bornée et, une fois celle-ci terminée, les poids ne bougent plus, ceci afin d’éviter que le réseau « oublie » des scénarios d’aide au fil de son évolution.
Construire un réseau de neurones
La principale difficulté à la construction d’un tel réseau est la détermination des vecteurs d’entrées et de sortie. Dans le cadre d’un système d’assistance, le vecteur de sortie est simple : il s’agit de l’aide apportée. Bien qu’elle puisse prendre de multiples formes (mise en évidence d’éléments d’interface, affichage du manuel, vidéos de tutoriel ad hoc, etc.), il est assez simple de déterminer sa forme.
Cependant, le vecteur d’entrée, lui, peut prendre de multiples formes. Doit-il être au plus prêt de l’utilisateur, c'est-à-dire basé sur les interactions clavier-souris ? Doit-il se baser sur les fonctions de haut niveau du programme aidé ? Doit-il prendre en compte le contexte local, ou est-ce un logiciel ou on travaille toujours sur de multiples fenêtres qu’il faut intégrer également ?
Bref, il s’agit de construire le modèle d’utilisation du logiciel aidé, modèle qui se construit en fonction des usages perçus du logiciel et du niveau de précision qu’on veut faire atteindre à l’aide.
La détermination du nombre de couches intermédiaire et de leur densité est ensuite une simple question technique, sachant que, plus on en met, plus le réseau est précis mais plus il demande des ressources et du temps pour traiter un vecteur d’entrée. Il ne s’agit pas que le système d’aide paralyse la machine parce qu’il est trop gourmand !
A titre indicatif, avec les meilleurs supercalculateurs du moment, on arrive à reconstruire un cerveau de mouche…
Le raisonnement à partir de cas
Prise en compte de l’utilisateur et de son expertise par domaine et temporalité. Et s’il était possible d’avoir les deux dans un seul système ? Un tel système ne peut s’envisager qu’en étant dynamique, sans cesse en état d’apprentissage. Une solution consiste à utiliser le raisonnement à partir de cas (qui sera abrégé en ràpc dans la suite).
Cette technologie est notamment utilisée dans le cadre de l’assistance aux personnes en fauteuil roulant. Les fauteuils, communiquant les uns avec les autres, peuvent se transmettre des informations sur les trajets les plus efficaces pour se rendre d’un point à un autre, en prenant en compte les problèmes rencontrés (trottoir trop étroit, lampadaire mal positionné, voitures garées à cheval sur le trottoir, …).
Présentation
Basé sur la méthode d’apprentissage de l’esprit humain, le ràpc consiste à retrouver les expériences passées similaires à l’expérience présente et à s’en servir comme d’un tremplin pour analyser et résoudre le problème courant. Le ràpc est basé sur un cycle en 4 étapes :
- Récupérer, qui consiste à explorer la mémoire pour retrouver le cas le plus similaire à la situation courante.
- Réutiliser, qui consiste à adapter le cas récupéré à la situation courante, partant du principe que deux cas ne sont jamais tout à fait identiques
- Réviser, qui consiste à résoudre le problème courant, créant ainsi un nouveau cas.
- Retenir, qui consiste à mémoriser le cas ainsi révisé, sous réserve qu’il soit intéressant, dans la mémoire.
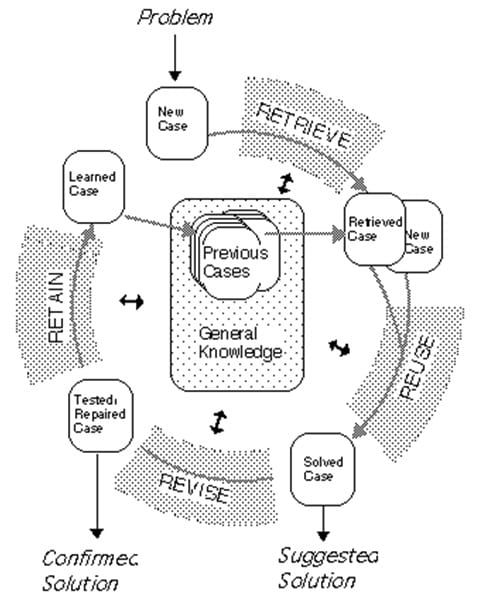
Figure 9 Le cycle du raisonnement à partir de cas
Qu’est-ce qu’un cas ?
Un cas est composé ici de deux parties, une partie problème et une partie solution. La partie problème contient la trace d’utilisation conduisant à la demande d’aide. Cette trace d’utilisation est un relevé des actions faites par l’utilisateur, qualifiée par les fonctionnalités du logiciel aidé.
La partie solution, quand à elle, est identique… sauf qu’il s’agit de la solution. En effet, l’aide est également exprimée sous forme de trace d’utilisation, permettant de guider l’utilisateur dans les actions à effectuer au sein du logiciel aidé.
De fait, la séparation entre problème et solution n’est pas tranchée de façon nette, car la demande d’aide peut intervenir à n’importe quel point du processus. Bien entendu, plus la demande interviendra tard, plus la recherche de cas similaire sera précise, puisque se basant sur une plus grande quantité de données.
La qualification de la trace d’utilisation
Un des points clefs de cette technique est de nettoyer et qualifier la trace d’utilisation afin de la rendre exploitable. En effet, un utilisateur ne reste pas concentré sur une seule tâche. Il introduit du bruit dans sa trace, que ce bruit soit du à une recherche de solution (Undo/redo là encore) ou à l’interruption d’un collègue qui vient lui demander de l’aide, il convient de détecter et supprimer ce bruit afin d’obtenir une trace exploitable.
Cette partie est la plus délicate du processus, puisqu’il est à priori impossible de déterminer ce qu’est le bruit. La trace est donc regroupée en unité sémantiquement plus significatives, afin de déterminer par gros ensembles lesquels font partie du problème.
Prise en compte du niveau d’expertise
La prise en compte du niveau d’expertise de l’utilisateur se fait à travers la granularité de la trace retenue. Ainsi, un novice sera aidé au niveau de chaque étape (commande, saisie clavier), alors qu’un expert se verra proposer uniquement les grandes lignes de résolution.
L’autre différence, liée à la granularité, réside dans la complexité des problèmes adressés. Pour des raisons évidentes de temps de calcul, la longueur maximale d’un cas est limitée. Cependant, en jouant là encore sur la granularité, il est possible d’adresser avec la même longueur des objectifs de portée différente. Ainsi le scénario « cliquer sur fichier ; cliquer sur nouveau » à la même longueur que « créer un planning projet ; affecter les ressources », mais pas la même granularité.
On positionnera le novice sur le premier, l’expert sur le second.
Limitations
Hélas, en voulant combiner le meilleur de deux mondes, on combine également les défauts.HéH Ainsi, le ràpc se base à la fois sur un profil personnalisé, ce qui implique une phase de prise de connaissance qui, même si elle est plus rapide que pour un réseau bayésien, demeure trop longue au regard de la tolérance moyenne d’un utilisateur.
Par ailleurs, la complexité des cas est limitée pour des raisons de temps de calcul. Cette limitation peut cependant être contournée en mutualisant la mémoire.
Il s’agit d’avoir une base de cas commune et enrichie par plusieurs personnes, située sur un serveur dédié. Chaque utilisateur progresse alors non seulement en apprenant des autres, mais également en apprenant aux autres, ce qui nous place à la base de la pyramide d’apprentissage.
Construire un système de ràpc
Vu qu’un tel système est autoalimenté en données, la difficulté de construction porte sur la capture, la qualification et l’analyse de la trace d’utilisation, ainsi que sur le moteur d’inférence permettant de comparer les cas entre eux.
Trace d’utilisation
L’utilisateur est imprévisible, et pourtant, un système de ràpc tente de prédire ce qu’il va faire. Pour cela, il se base sur ce que fait réellement l’utilisateur, qualifié par le logiciel aidé (on ne retient pas « clic souris en 25 ;30 » mais « ouverture du menu fichier »). Cette trace doit ensuite être agrégée, en utilisant la base de cas. Ainsi, un scénario parcouru dans son entier peut devenir une brique d’un scénario plus large, le tout formant un assemblage digne de lego, chaque brique participant à la création d’une ou plusieurs briques plus grandes, etc.
Moteur d’inférence
L’objectif du moteur d’inférence est de calculer une distance entre deux cas, étant entendu que plus cette distance est petite, plus les cas sont proches. La distance ainsi calculée doit tenir compte des multiples moyens d’accès à une même fonctionnalité (menu, raccourci clavier, …) et également des trous potentiels dans la trace, dus au fait que deux chemins légèrement différents peuvent être utilisés pour parvenir au même résultat.
Conclusion
Vous l’avez compris, cette présentation est de niveau novice, elle a pour seul objectif de présenter les différentes techniques utilisables pour créer un système d’aide et d’assistance autour d’un logiciel complexe.
Par ailleurs, point de mystère, plus les techniques sont complexes, plus le coût de mise en œuvre est important. Il convient donc de faire la balance entre le résultat apporté et l’investissement à faire.