Supervisez votre JVM
La performance est un sujet qui revient souvent dans les projets. Mais la plupart du temps, le sujet est abordé après que les premiers problèmes soient survenus. Dans le précédent article, Sébastien insistait sur la nécessité de s’outiller. Effectivement, on améliore ce que l’on mesure. Nous allons donc nous intéresser au monde Java et voir quels sont les outils pour mesurer, présenter et suivre dans le temps des indicateurs de performance.
Récupérer des indicateurs : JMX
Lorsque votre application n’offre pas la qualité de service attendue, la première étape consiste à investiguer et observer le comportement de l’application dans l’environnement de production, puisque c’est le lieu qui pose problème. JMX (Java Management Extensions) est au Java ce que SNMP est au monde réseau : c’est un standard pour dialoguer avec une JVM. JMX permet à un client distant :
- d’obtenir des valeurs
- de modifier des valeurs
- d’appeler des méthodes.
Ces différents éléments sont exposés par la JVM ou l’application, Cela permet par exemple d’obtenir des indicateurs en temps réel sur la santé de la JVM. Voici les options à ajouter sur la ligne de commande de la JVM pour activer l’accès à distance aux objets JMX : -Dcom.sun.management.jmxremote.port=1234 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
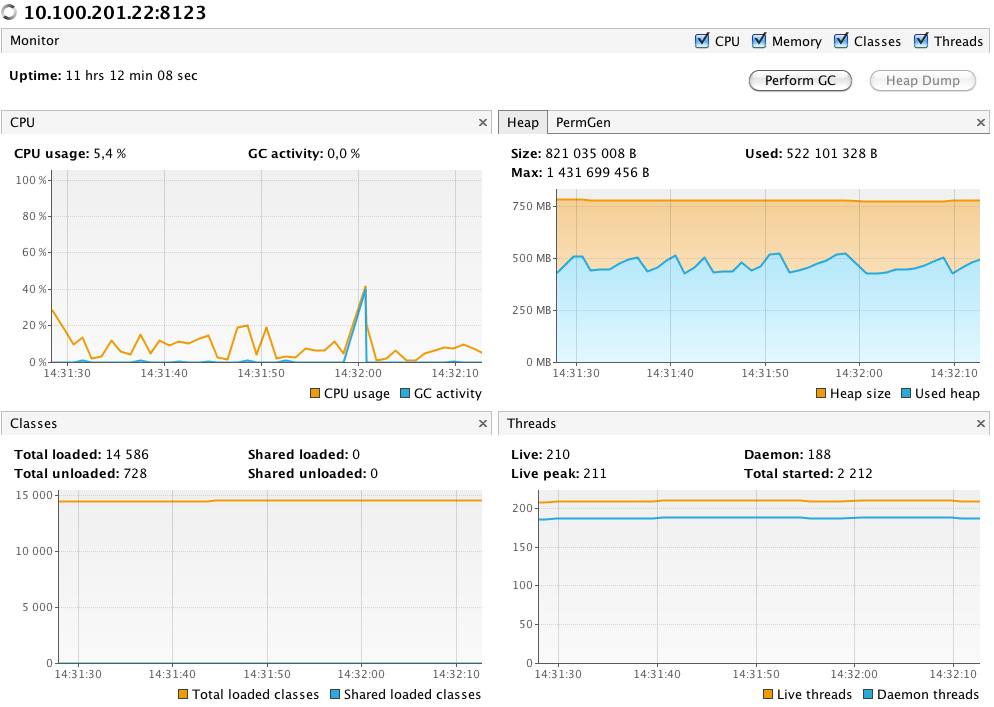
En standard, la JVM fournit nombre d’informations sur son activité. Dans l’exemple ci-dessous, VisualVM utilise JMX pour
- afficher le CPU utilisée par la JVM, ainsi que le CPU utilisé par le Garbage Collector
- afficher la taille du Heap (taille actuelle et taille utilisée)
- afficher le nombre de classes chargées
- afficher le nombre de threads actifs
- appeler explicitement le Garbage Collector (bouton en haut à droite).
Par ailleurs, beaucoup de frameworks ou de serveurs d’applications utilisent JMX pour exposer eux aussi des indicateurs sur leur activité. Vous vous demandez si votre cache L2 Hibernate sert à quelque chose ? Hibernate permet d’exposer via JMX ses statistiques : SecondLevelCacheHitCount, SecondLevelCacheMissCount, SecondLevelCachePutCount. Tomcat propose aussi des informations sur son activité : nombre de connexions à la base de données ouvertes, nombre de sessions actives… On peut alors détecter des problèmes de contentions (un exemple : l'application ouvre trop de connexions à la base et sature le pool défini).
Remonter des indicateurs métiers par JMX
Votre application peut elle aussi exposer des informations complémentaires, orientées métiers qui vont permettre d’analyser plus finement le comportement de l’application. Ex : le nombre de transaction effectuée, le temps de réponse du service Back-Office dont dépend notre application et qui impacte directement la qualité de service ressentie par les utilisateurs. Avec Spring, c’est trivial : il suffit d’annoter la classe à exposer par @ManagedResource(objectName = "MonBeanJMX"). On annote ensuite les méthodes, ou getter, ou setter, par @ManagedAttribute, et Spring expose la méthode par JMX. Voici un exemple pour exposer via JMX le nombre de commandes qui ont été prises :
@Service
@ManagedResource(objectName = "CommandeManager")
public class JMXCommandeManager {
@Autowired
private ICommandeManager commandeManager;
@ManagedAttribute
public int getCommandeCount() {
retrun commandeManager.getCount();
}
}
Cela peut vous servir pour configurer votre application : il suffit d’annoter un setter et un getter pour rendre modifiable à distance un paramètre. Vous pouvez aussi annoter une méthode. Par exemple, une méthode qui réinitialise un composant de l’application, que vous pourrez alors très facilement appeler à distance.
Il faut aussi noter que JMX est peu intrusif. Il ne va pas entrainer de surcharge vraiment significative de CPU sur la JVM. Par contre, c'est assez consommateur en réseau. Avec VisualVM, il existe un plugin, le sampler, qui permet de faire du profiling 'grossier' sans instrumenter les classes. Ce n'est pas aussi précis qu'un vrai profiler, mais cela permet d'arriver à des résultats gratuitement, sans perte de performances, et sans utilisation d'un outil qui peut être coûteux et difficile à mettre en place. JMX permet aussi de faire des threads dumps, et de récupérer le résultats à distance, très facilement : on peut l'utiliser pour détecter des threads bloqués (en attente d'une ressource) voire des deadlocks entre plusieurs threads.
Historiser les indicateurs
S’il est utile de consulter ces informations à la demande lorsqu’un problème survient, il est préférable d’essayer de les anticiper et ainsi passer d’un réactif à un mode proactif. Au même titre que l’on supervise les équipements réseaux et les serveurs, il est intéressant de suivre dans le temps le comportement de l’application et de détecter des situations anormales. Pour ca, les outils du monde de l’infrastructure peuvent répondre à notre besoin très simplement : Zabbix, Cacti sont deux outis OpenSource parmi d'autres qui permettent d’historiser les indicateurs souhaités dans la durée et ensuite de les présenter sous forme de graphique. Voici 2 exemples, fait avec Zabbix. Dans le premier, on suit le nombre de sessions actives sur la production. La production comporte 6 serveurs, chaque serveur à sa couleur. On voit très bien le creux à midi pendant la pause déjeuner. 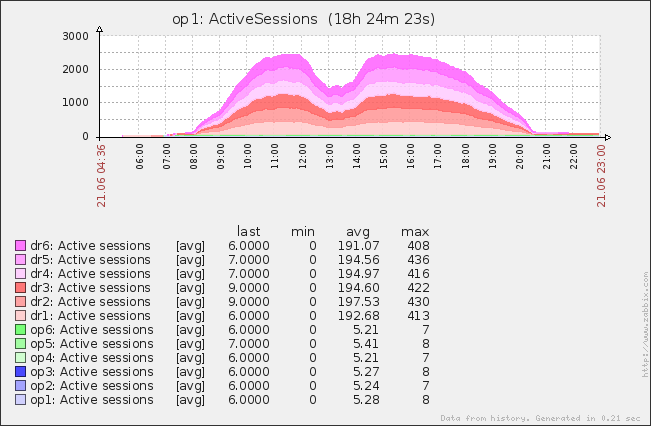
Dans le deuxième exemple, on suit le nombre de commandes prises dans la journée. C’est aussi une information consolidée depuis tous les serveurs (courbe verte). On trace aussi la dérivée, afin de pouvoir suivre le nombre de commandes prises par heure (courbe rouge). On retrouve le creux de midi. 
- un mail est envoyé dès qu’un serveur ne répond plus pendant 20 secondes
- un mail est envoyé toutes les nuits contenant les principaux indicateurs métiers de la journée.
Voici l'architecture mise en place : 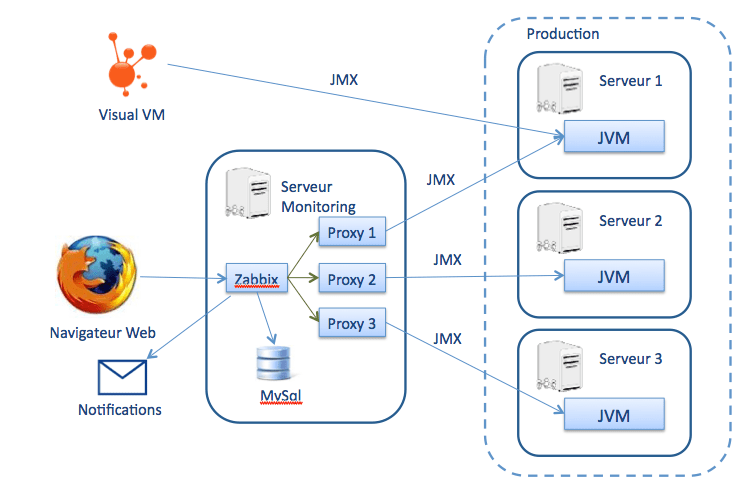
Pour finir
Bien souvent les équipes de développement sont dépendantes des équipes de production sur les aspects supervision, suivi des performances et donc au final qualité de service. Avec JMX et les quelques outils présentés, il est possible de remettre en cause ce mode de fonctionnement. C'est souvent utile, car les personnes les mieux à même d’analyser le comportement de l’application sont ceux qui la construisent. Pour paraphraser Werner Vogels (CTO d’Amazon), « You build it, you monitore it ».