Stratégies et patterns pour déployer automatiquement un modèle de machine learning
Automatiser un déploiement c’est pouvoir rendre accessible une nouvelle version de son logiciel en un clic. En ce qui concerne le déploiement d'un modèle de machine learning, il s’agit d’automatiser deux choses :
la construction de l’artéfact modèle, communément appelé entraînement ;
le déploiement du service d’inférence.
| Service d’inférence | Pipeline de construction de l’artefact modèle | |
| Rôle | Sert les prédictions | Produit un modèle à partir de données et de code |
| Enjeu | Pouvoir déployer une nouvelle version du modèle utilisable par le logiciel à la demande | Pouvoir lancer un entraînement à la demande |
Nous avons abordé l’automatisation de la pipeline de construction du modèle dans un article précédent. Nous nous concentrons ici sur l’automatisation du déploiement du service d’inférence.
Pourquoi est-ce différent pour un logiciel avec machine learning ?
D’un point de vue pratique, un déploiement automatique est l’exécution d’une série de scripts permettant de configurer l’environnement cible et d’y déposer un ou plusieurs artéfacts qui serviront à lancer un service logiciel. Ces artefacts sont typiquement le produit d’un procédé d’intégration continue, qui les construit à partir du code fourni par les développeurs.
figcaption {color: grey; text-align: center; font-style: italic; margin-bottom: 12px}
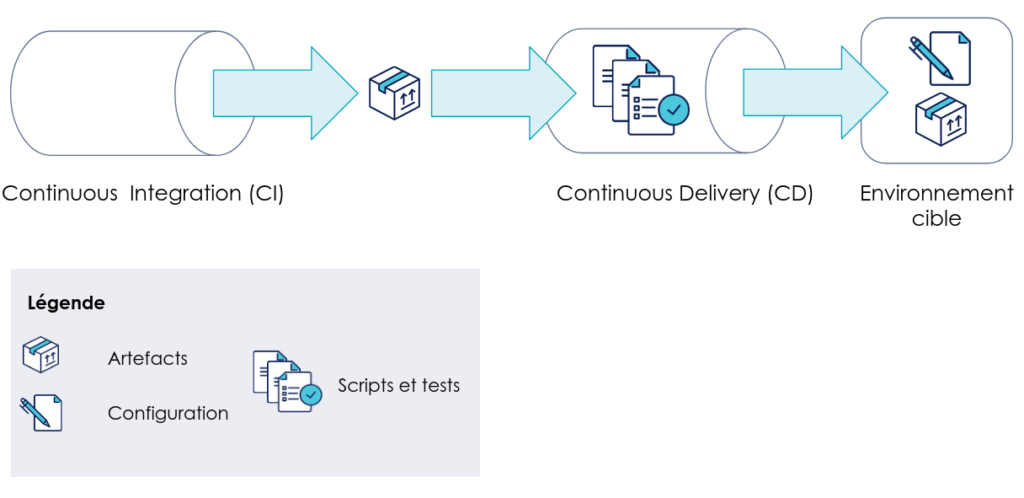
La CI/CD dans un contexte sans ML
Pour un logiciel avec machine learning, l’idée générale derrière l’automatisation des déploiements reste la même. Cependant, un artéfact supplémentaire doit être déployé : le modèle. Ce dernier est produit lors de la phase d’entraînement.
Une première particularité de cet artéfact est que son cycle de vie n’est pas nécessairement le même que celui du reste du logiciel. En effet, l’évolution des écrans du logiciel n’est pas forcément liée à l’évolution du modèle.
Une deuxième particularité est que le besoin de déployer un nouveau modèle peut provenir de deux évènements de type différent :
L’évolution du code d’entraînement : l’utilisation de nouvelles variables dans la modélisation, une évolution dans le pré-processing, l’utilisation d’un algorithme de machine learning différent…
L’évolution des données sur lesquelles il a été entraîné : un nouvel entraînement est déclenché avec le même code mais des données d’entrée différentes, plus représentatives de la réalité actuelle.
Une dernière particularité est que sa production mobilise des compétences particulières : des personnes sachant gérer des données analytiques, modéliser mathématiquement une problématique métier, mettre à disposition une infrastructure permettant d’exécuter les scripts d’entraînement… qu’il faudra faire interagir avec le reste des équipes développant le logiciel.
Ainsi, la problématique principale du déploiement continu du service d’inférence est de déterminer une architecture permettant un déploiement fluide. Dans la suite de cet article, nous vous proposons quelques patterns d’architecture et le contexte dans lequel les mettre en œuvre.
Le choix du pattern de déploiement
Il n’y a pas une seule façon de déployer son logiciel avec ML [1]. En effet, celui-ci est composé de trois briques :
le modèle
l’inférence
l’application consommatrice
Choisir une stratégie de déploiement revient à choisir quelles briques nous souhaitons coupler ou découpler [2].
Les 4 stratégies de déploiement
| Avantages | Défauts | Quand l’utiliser | |
| Coupler le modèle, inférence et application | Un seul artéfact à construire, livrer et déployer Faible latence dans l’inférence | Les cycles de vie de l’application et du modèle sont liés Il faut redéployer tout à chaque fois | Pour commencer, c’est la stratégie la plus simple Quand le modèle évolue peu ou pas Quand c’est la même équipe qui gère l’application, l’inférence et l’entraînement Quand le ML est au coeur de l’application |
| Découpler le modèle, coupler inférence et application | Permet de mettre à jour le modèle indépendamment de l’application Permet à l’application d’avoir la main sur l’inférence pour mieux coller aux besoins spécifiques l’application | Complexifie l’architecture à cause du besoin de gérer des interfaces entre le modèle et l’inférence Complexifie l’architecture car il faut gérer un model repository et son éventuelle indisponibilité | Quand le modèle a souvent besoin d’être mis à jour Quand la modélisation est un problème complexe et qu’on souhaite lui dédier une équipe de spécialistes Quand il y a un seul consommateur du modèle Quand le ML est au coeur de l’application Quand les besoins de hardware ne sont pas les mêmes pour déployer le modèle et l’application |
| Coupler modèle et inférence, découpler l’application | Permet de mettre à jour le modèle indépendamment de l’application Permet aux consommateurs de faire abstraction des spécificités du ML | Complexifie l’architecture à cause du besoin de gérer des interfaces entre l’inférence et l’application Complexifie l’architecture car il faut gérer un nouveau service et son indisponibilité [3] | Quand il y a plusieurs consommateurs Quand le modèle est une fonctionnalité parmi d’autres pour ses consommateurs Quand les besoins de hardware ne sont pas les mêmes pour l’inférence et l’application |
| Découpler modèle, inférence et application | Permet de mettre à jour le modèle indépendamment de l’application Permet aux consommateurs de faire abstraction des spécificités du ML | Complexifie l’architecture à cause du besoin de gérer des interfaces entre le modèle et l’inférence et entre l’inférence et l’application Complexifie l’architecture car il faut gérer un model repository, le service d’inférence et leurs éventuelles indisponibilités | Quand le modèle a souvent besoin d’être mis à jour Quand la modélisation est un problème complexe et qu’on souhaite lui dédier une équipe de spécialistes Quand il y a plusieurs consommateurs du modèle Quand le modèle doit être exposé suivant plusieurs interfaces Quand les besoins de hardware ne sont pas les mêmes entre l’entraînement et le déploiement et/ou l’application et l’inférence Quand il devient nécessaire de scinder des équipes en gardant leur autonomie |
Les patterns associés aux 4 stratégies de déploiement
Ces quatre stratégies sont déterminées par la réponse à deux questions :
Coupler ou découpler le déploiement du modèle de celui de l’inférence ?
Coupler ou découpler le déploiement de l’inférence de celui de l’application ?
Voyons dans les détails quels patterns utiliser selon la réponse à ces deux questions.
1. Coupler ou découpler le modèle et l’inférence ?
Le cas du Embedded Model
Réponse : Coupler
Le modèle est packagé avec son service d’inférence
figcaption {color: grey; text-align: center; font-style: italic; margin-bottom: 12px}
Exemple d’application avec embedded model : modèle et inférence sont déployés ensemble
Cette approche est généralement la plus simple. Le modèle est embarqué dans le service d’inférence. Du point de vue du déploiement, ils sont considérés comme un seul et même artéfact. Ils sont donc construits et packagés ensemble. Bien entendu, cette technique aboutit à un cycle de vie partagé : livrer un nouveau modèle implique la livraison du service d’inférence et réciproquement. Il est plus efficace dans ce cas que ce soit une seule équipe qui prenne en charge le développement du modèle et du service auquel il est couplé.
Le cas Model as Data
Réponse : Découpler
Le modèle est mis à disposition dans un model repository
figcaption {color: grey; text-align: center; font-style: italic; margin-bottom: 12px}
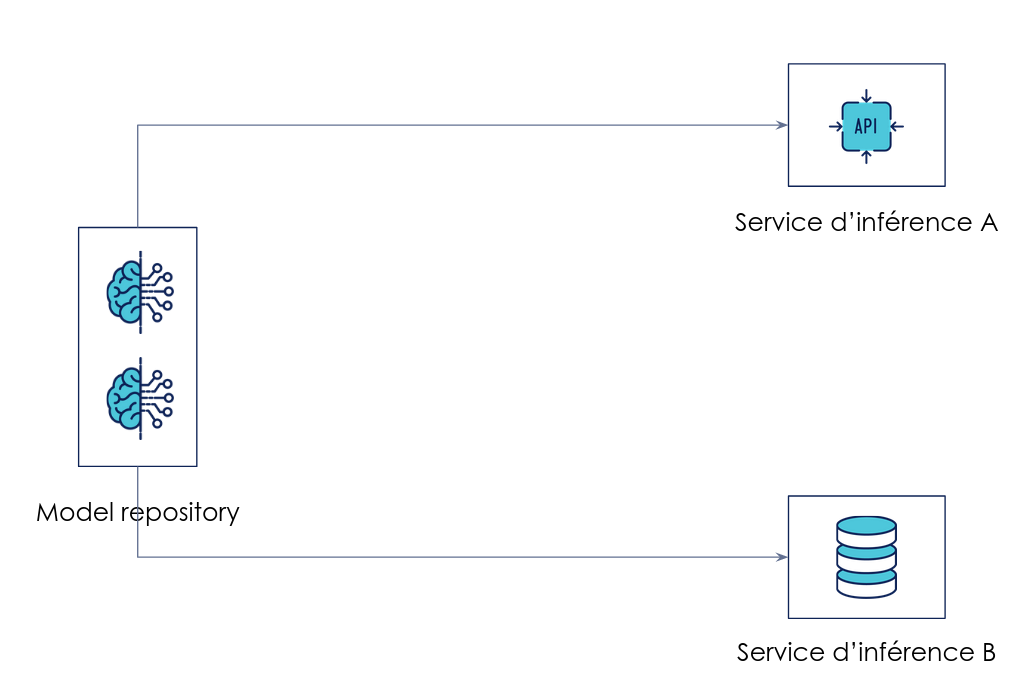
Exemple de model as data : des applications mettent à jour leur inférence lorsqu’un nouveau modèle est publié dans le repository
Cette approche permet de séparer le déploiement du modèle de celui du service d’inférence. Ce dernier récupère la version du modèle dont il a besoin pour faire sa prédiction au runtime. Cette version peut être mise à jour en changeant la configuration du service d’inférence (par une montée de version manuelle, automatisée via un CRON ou automatisée en réponse à une notification).
2. Coupler ou découpler l’inférence et l’application ?
Le cas où l’application embarque l’inférence
Coupler
L’inférence est faite par un module de l’application
figcaption {color: grey; text-align: center; font-style: italic; margin-bottom: 12px}
Exemple d’application embarquant l’inférence
Le code de l’application comporte un module permettant de faire de l’inférence. L’application appelle directement ce module pour réaliser les inférences nécessaires à son fonctionnement. Notons que le module d’inférence peut tout aussi bien faire appel à un modèle intégré au code de l’application ou à un modèle récupéré dans un repository.
Le cas où le modèle est consommé par plusieurs applications
Le pattern d’exposition des prédictions
Réponse : Découpler
L’inférence est faite par batch et exposée en tant que donnée
figcaption {color: grey; text-align: center; font-style: italic; margin-bottom: 12px}
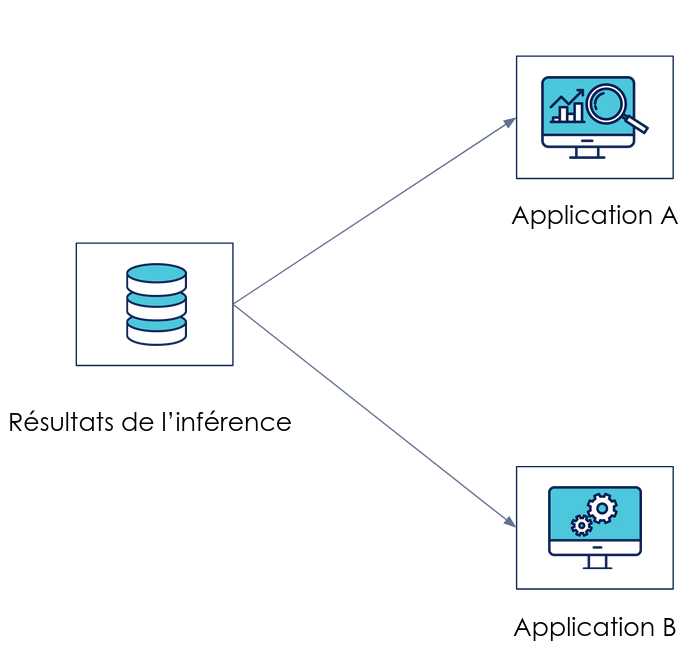
Exemple de modèle exposé par ses prédictions et servant plusieurs applications
Un script est exécuté afin de produire des prédictions en batch. Elles sont stockées puis exposées aux consommateurs. Dans ce cas-là, le rythme d'inférence est décorrélé du rythme de consommation. Le format de stockage est un contrat d’interface à définir selon les besoins des applications consommatrices : une base de données pour une application front-end ou un simple fichier texte pour la génération de dashboard de visualisation [4].
Le pattern Model as a Service synchrone
Réponse : Découpler
L’inférence est assurée par un service dédié en synchrone
figcaption {color: grey; text-align: center; font-style: italic; margin-bottom: 12px}
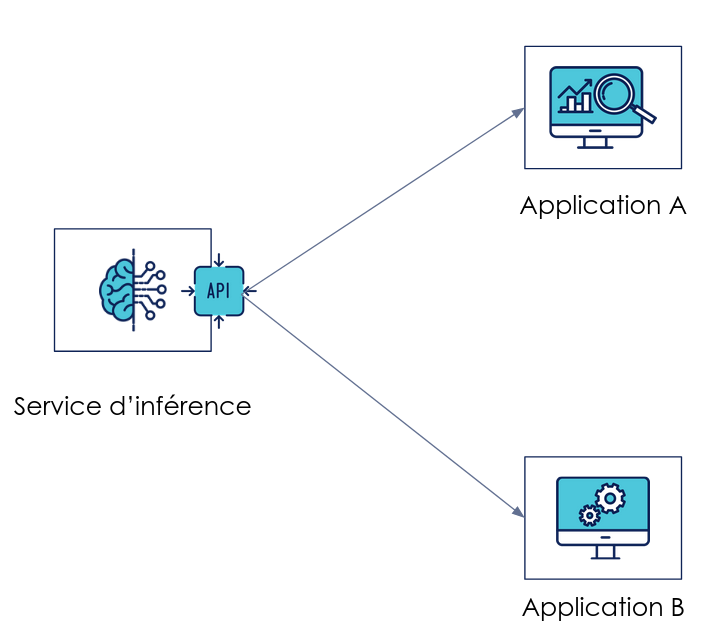
Exemple de modèle exposé via un service d’inférence et servant plusieurs applications de façon synchrone
Un service est appelé à la demande et renvoie une prédiction en se basant sur la donnée d'entrée fournie par le consommateur. L’inférence peut ainsi être déployée indépendamment de l’application. Cependant, un contrat d'interface doit être mis en place et respecté entre l'API et les consommateurs. À l'instar de n'importe quelle API ou service web, les problèmes de rétrocompatibilité doivent être gérés pour pouvoir déployer de nouvelles versions de manière autonome et indépendante.
Le pattern Model as a Service asynchrone
Réponse: Découpler
Le modèle répond à des demandes d’inférence en asynchrone
figcaption {color: grey; text-align: center; font-style: italic; margin-bottom: 12px}
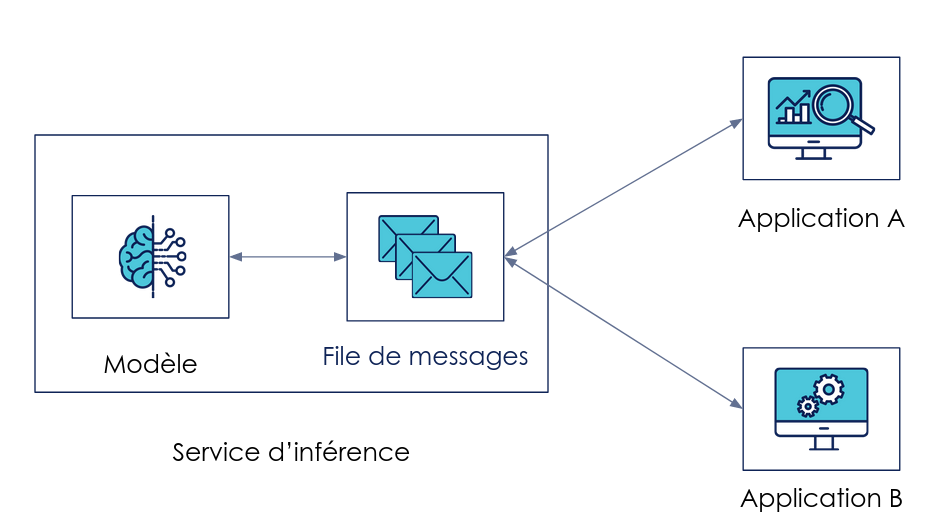
Exemple de modèle répondant à une file de messages et servant plusieurs applications de façon asynchrone
Une variante asynchrone du pattern ci-dessus est le pub/sub model, où le modèle est en attente de requêtes de la part des consommateurs (sous forme de message ou d'événements) pour envoyer les prédictions voulues. Cette architecture est intéressante parce qu'elle permet de gérer une grosse charge de demandes en créant un buffer de requêtes qui seront consommées au fur et à mesure. Elle suppose le même type de contraintes que le model as a service.
Notons que, pour ces trois exemples, le modèle peut tout aussi bien être déployé avec le service d’inférence comme être déposé sur un model repository.
À retenir
La brique ML d’un logiciel a un cycle de vie et des enjeux propres, qui nécessitent des stratégies de déploiement spécifiques.
La stratégie de déploiement la plus pertinente pour un logiciel avec ML dépend :
de la place prépondérante ou non que le modèle a dans l’application ;
de la maturité du produit (MVP, produit grand public…)
de la fréquence de mise à jour du modèle ;
de la taille et de la composition de l’équipe ;
de la complexité des modèles déployés ;
du nombre de consommateurs du modèle…
Plusieurs patterns de déploiement répondent à ces besoins en couplant ou découplant modèle, service d’inférence et application :
l’embedded model ;
le model as data ;
l’application embarquant le service d’inférence ;
l’exposition des prédictions ;
le model-as-a-service synchrone ou asynchrone.
[1] CD4ML en propose trois :
L’embedded model ;
Le model deployed as a different service ;
Le model published as data et leurs implications.
[2] Pour un point de vue socio-technique sur les questions de couplage et découplage dans un logiciel avec ML, voir “Pourquoi et quand découpler ses architectures de projets de Machine Learning pour en accélérer le delivery”.
[3] Le pattern associé le moins complexe à mettre en place étant l’exposition des prédictions et le plus complexe le model as a service asynchrone.
[4] Dans un contexte data mesh, nous pouvons parler de data product (voir Dehghani, Z. (2022). Data Mesh. O'Reilly Media.).
Remerciements : Emmanuel-Lin Toulemonde pour ses conseils et relectures. Julien Tellier, Ali El Moussawi et Mehdi Houacine pour leur relecture et commentaires.