SRE : Les bonnes pratiques pour améliorer la fiabilité de ses services
Durant le printemps, nos experts OCTO vous proposent un cycle de contenus autour du Cloud. Le sujet vous intéresse ? Pour découvrir le programme et ne rien rater, inscrivez-vous sur notre page Cloud, DevOps & Plateformes.
Comme nous l'avons vu précédemment, le Cloud est un formidable outil qui vient aussi avec ses contraintes. L’agilité qu'il permet est un accélérateur pour mettre en place une stratégie de livraison continue. Mais sans maîtrise la puissance n’est rien… Passons donc maintenant du côté du “run” pour nous intéresser aux meilleures pratiques d’exploitation et d’opération, en décortiquant ce qui se cache derrière le terme “SRE”.
L'origine du terme SRE et l'importance de la fiabilité
fiable, adjectif : en qui ou en quoi on peut avoir toute confiance, auquel on peut se fier
La fiabilité est la caractéristique la plus importante de vos services. Peu importe que vous ayez les fonctionnalités les plus jolies, si votre site ressemble à ça lors des périodes de pics :
Personne ne l’utilisera.
Peu importe que vous ayez la meilleure fonctionnalité, si elle est lente ou retourne une erreur une fois sur deux, personne ne perdra son temps à l’utiliser.
Cette caractéristique est tellement importante que certaines organisations ont décidé d’en faire une discipline à part entière : le Site Reliability Engineering. SRE est un terme inventé par Google en 2003, il a vraiment été popularisé en 2016 lors de la sortie du livre du même nom.
En 2003, Google n'était pas encore le mastodonte que l'on connaît aujourd'hui et son principal asset était le site google.com, les revenus de Google étaient directement liés à la disponibilité de leur site. Le terme “Site” dans Site Reliability Engineering est aujourd’hui un peu réducteur et on pourrait le remplacer par "Service" ou "Product" mais la philosophie reste la même : si la fiabilité et la qualité des opérations est un domaine important pour votre organisation (au même titre que la vélocité ou la livraison de nouvelles fonctionnalités), alors vous avez tout intérêt à y dédier un rôle, une équipe et des pratiques.
Quand on parle de fiabilité, on peut parler de différents moyens, objectifs ou activités :
La disponibilité
La résilience
Le monitoring et l'observabilité
La gestion des incidents
La sécurité
Le release management
Le capacity planning
...
Mais finalement, qu’est ce qui fait que tout le monde parle de SRE aujourd’hui ? Est-ce que vous avez intérêt à implémenter une démarche SRE dans votre organisation ? En quoi est-ce que cela peut vous aider ?
Nous vous proposons dans la suite de cet article de détailler les 5 idées qui nous paraissent les plus importantes à comprendre et à retenir lorsque l’on parle de SRE.
Un système fiable est un système observable
Les premiers utilisateurs d’un système technique sont ceux qui l’opèrent, le font vivre et le font évoluer. Un système fiable est donc un système dans lequel les opérateurs (Développeurs, Ops…) peuvent avoir confiance, un système qu’ils peuvent comprendre facilement, un système dont ils peuvent en un clin d'œil savoir s'il est fonctionnel ou en panne, s'il rend le service correctement ou non.
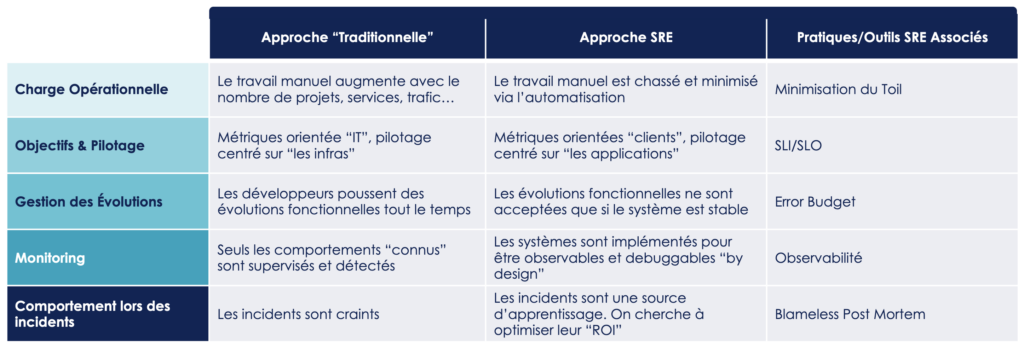
On dit d'un système qu'il est observable s'il peut être appréhendé par un humain pour qu'il puisse le comprendre, le modifier et le corriger facilement. L'observabilité est en quelque sorte une extension du monitoring : là où le monitoring va surtout chercher à exposer une vision d'ensemble de notre système à travers la répétition régulière de "tests" (ce qui implique que nous sachions à l'avance quoi tester), les techniques d'observabilité vont quant à elle chercher à outiller le débuggage du système : ce seront des outils permettant d'explorer nos systèmes, de comprendre et de diagnostiquer nos problèmes d'infrastructure, de logiciel ou les problèmes d'interactions/intégrations entre les services.
Là où le monitoring aide surtout à améliorer le MTTD (Mean Time To Detect), l’observabilité va aider à améliorer le MTTR (Mean Time To Repair) en facilitant l’investigation et la résolution d’incidents.
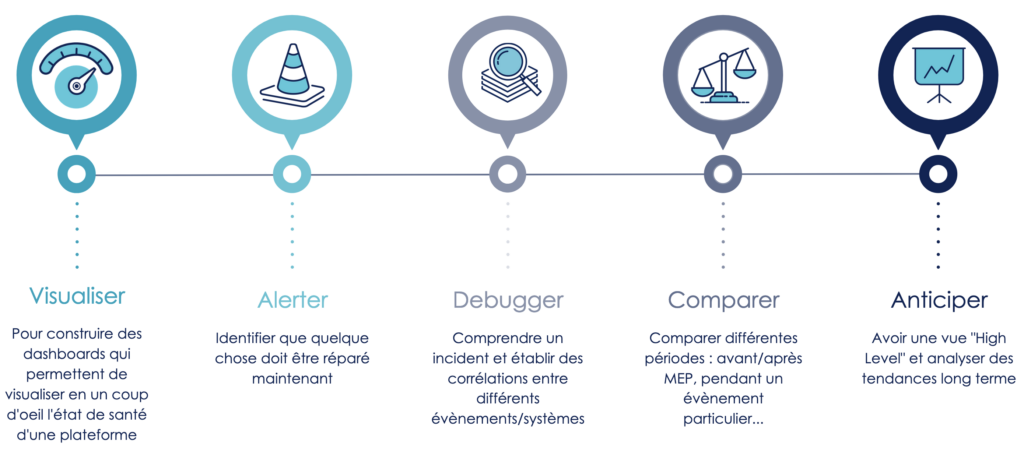
Les outils d’observabilité et de monitoring sont indispensables à toute démarche d’amélioration continue de la fiabilité des systèmes : ils permettent de mesurer, d’améliorer la détection d’anomalie, la compréhension des systèmes ainsi que la résolution des incidents.
L’importance des “Non Functional Requirements”
Le lancement d’un nouveau produit naît généralement de la réponse à un “problème utilisateur”. Ainsi, lorsqu'on conçoit un système, on porte en premier lieu attention aux pré-requis fonctionnels qui permettent de répondre aux besoins des utilisateurs. Cependant, pour construire un bon socle sur lequel ces fonctionnalités vont pouvoir se baser, il est également primordial de penser à tous les pré-requis non fonctionnels nécessaires au bon fonctionnement et à la bonne évolutivité du service, on parle en anglais de NFR pour “Non Functional Requirements".
Un "Functional Requirement" définit ce qu'un système fait, le service qu'il rend
Un "Non Functional Requirement" définit comment un système doit être
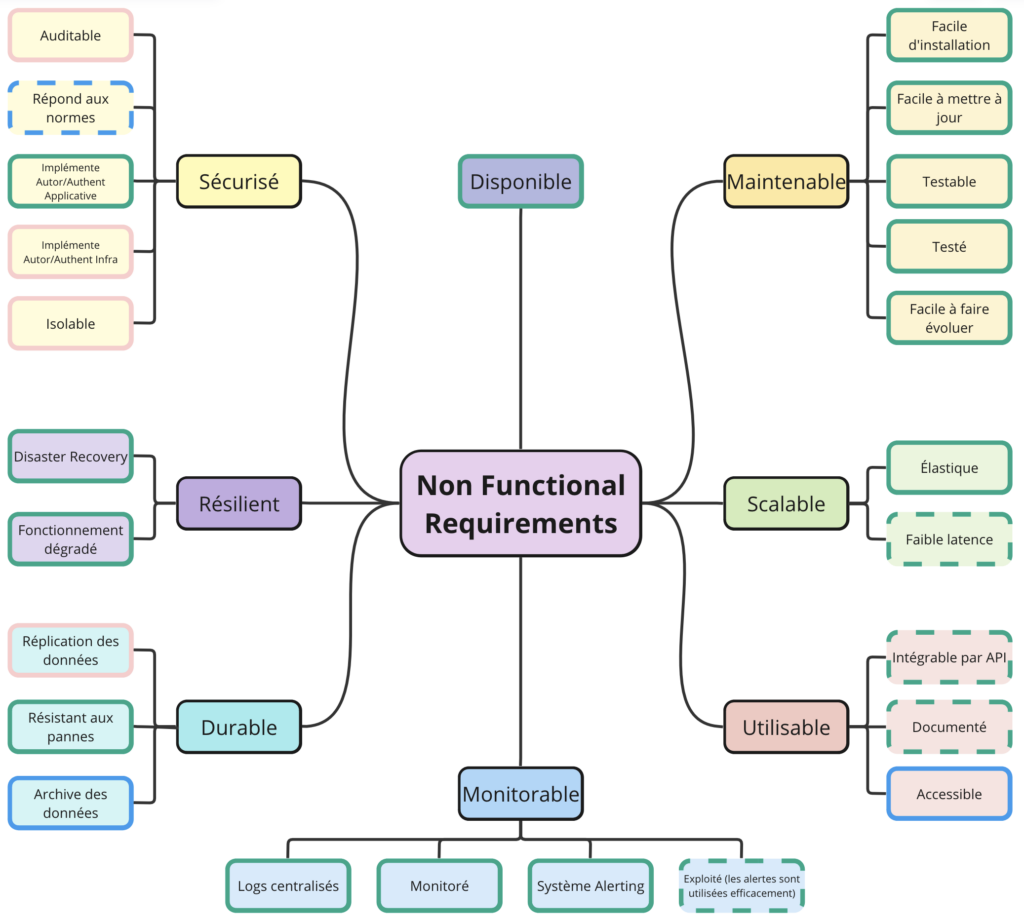
Ces "Non Functional Requirements" doivent être pris en compte au plus tôt dans le design des solutions et à chaque étape du cycle de conception. Au même titre qu'il est souvent compliqué de rendre du code testable s'il n'a pas été implémenté dans l’idée d’être testable, il est compliqué de rendre un système observable, sécurisé ou résilient s'il n'a pas été conçu dès le début avec l’intention d’être observable, sécurisé ou résilient.
Le "Production Readiness Review" est une pratique SRE permettant de qualifier un service ou un système pour s'assurer qu'il respecte tous les pré-requis non fonctionnels à sa bonne exploitation.
On peut simplement commencer par une checklist qui sert de base de discussion entre les équipes afin d'identifier à la fois les pré-requis "techniques" :
Est-ce que mes données sont sauvegardées ?
Est-ce que mon déploiement est complètement automatisé ?
Est-ce que les métriques, logs et traces de mes systèmes sont centralisés et recherchables dans le bon outil ?
et "organisationnels" :
Est-ce que les services owner et matrices de communication/escalade sont bien renseignés ?
La documentation est-elle suffisante et accessible à tous ?
L’idée d’avoir des personnes en charge de s’assurer que les règles et normes de sécurité sont bien partagées et respectées commence à faire son bout de chemin (démarche DevSecOps, importance des rôles de RSSI ou de Security Champions…), il est désormais temps d’étendre cette pratique à toutes les NFRs, et en particulier à la fiabilité des systèmes.
Avoir des personnes dans son organisation dont l'objectif principal est de s'assurer que ces NFRs sont bien respectées a énormément de sens, elles servent de corde de rappel ou de contrepoids nécessaire quand le reste de l'organisation est mécaniquement concentré sur la livraison de nouvelles fonctionnalités.
L’outil central de la démarche SRE : le budget d’erreur
Les interactions du trio Business, Développeurs, Ops ont historiquement été appréhendées comme un flux séquentiel et “descendant” : le business définit et spécifie le “besoin”, les développeurs implémentent et les ops opèrent le système ainsi construit. Ces interactions ne sont pas linéaires, elles doivent plus être vues comme une boucle de rétroaction. Le “build” et le “run” d’un service sont deux faces d’une même pièce, tous les intervenants ne voient pas forcément les mêmes aspects de cette pièce, mais c’est le partage de toutes ces visions qui permet d’avoir le bon produit, bien fait, au bon moment.
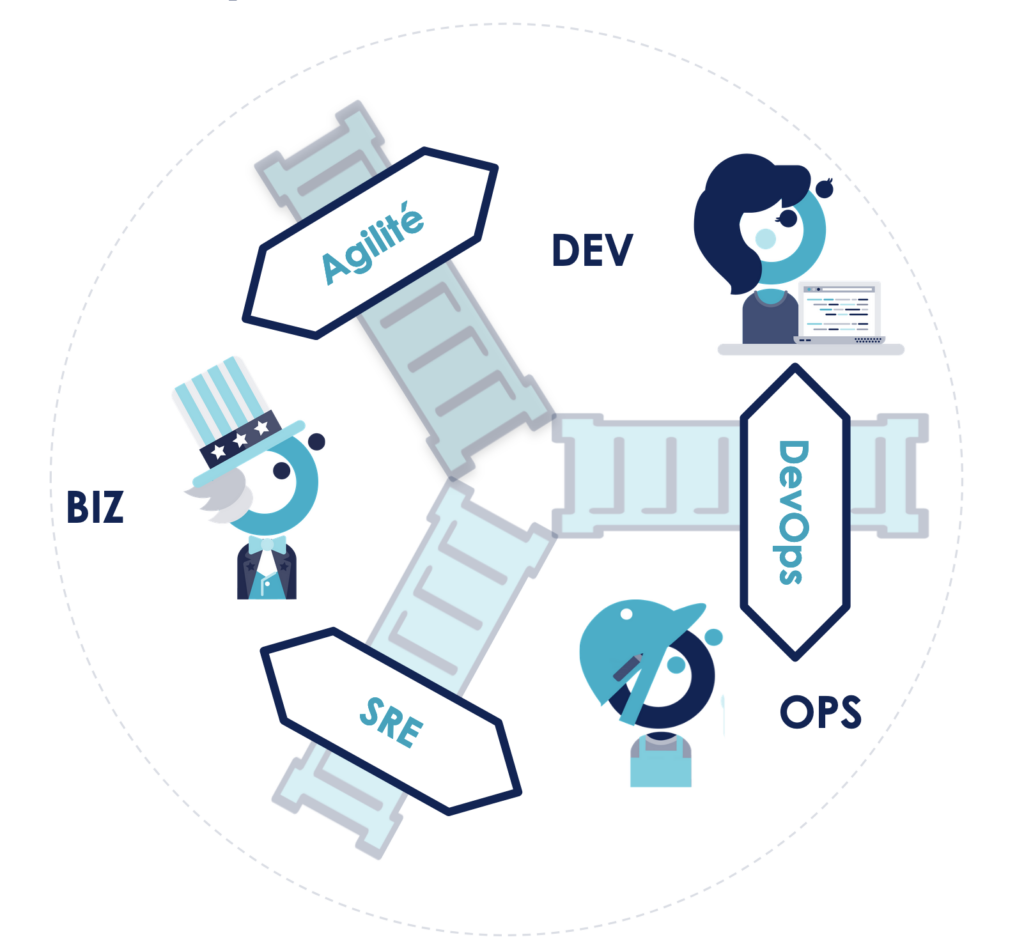
Le mouvement agile s’est attaqué en priorité au mur entre le business ou les représentants des utilisateurs et les développeurs.
Le mouvement DevOps a principalement permis de casser le mur entre Développeurs et Ops en rendant la boucle de feedback entre ces 2 types de profils plus courte et plus efficace.
Pour fermer la boucle, il restait un mur à casser : celui entre Opérations et Business. La démarche SRE permet de s’attaquer à ce mur en utilisant un outil méthodologique particulièrement malin, le budget d'erreur.
Le budget d'erreur c'est la quantité d'erreurs ou d'indisponibilité que je pense que mon utilisateur est prêt à accepter sans pour autant perdre confiance en mon produit ou mon service. Ce budget d'erreur est décidé à 3 entre équipes Business, équipes de Développement et équipes Opérations.
Prenons un exemple : nous opérons un service de streaming vidéo, et notre équipe produit mesure que si 99,5% des vidéos se lancent sans erreur, alors nos utilisateurs considèrent que le service est fiable. Sur 1000 sessions vidéos, notre budget d’erreur est de 5 vidéos qui ne se lancent pas.
Ce budget sert alors de monnaie d'échange entre nouvelles fonctionnalités (functional requirements) et fiabilité (non functional requirements) : tant que mon budget d'erreur n'est pas consommé (tant qu’il y a moins de 5 lancements vidéo sur 1000 qui partent en erreur sur les 4 dernières semaines), je considère que mes utilisateurs sont satisfaits, j'ai donc le droit de dépenser mon budget, d’innover et de déployer de nouvelles fonctionnalités.
En revanche, dès que j'atteins 0,5% d'erreurs sur le mois en cours, je dois arrêter tout travail sur du fonctionnel pour me concentrer sur la fiabilité du service. Nous le rappelons ici encore : la fiabilité est la caractéristique la plus importante de votre système, si votre système n'est pas considéré comme fiable par vos utilisateurs, alors vous perdez leur confiance et si les utilisateurs ont le choix, ils arrêteront de l’utiliser.
Le budget d'erreur permet ainsi deux choses :
de faire rentrer les incidents ou les interruptions de service dans le cycle de vie "normal" du logiciel : un objectif de fiabilité de 100% c’est avoir un budget d’erreur de 0% et donc aucune capacité d’amélioration continue, de prise de risque ou d’innovation.
de faire dialoguer sur la base de mesures factuelles et d’un indicateur commun centré sur la satisfaction utilisateur les équipes Produit (qui vont plutôt avoir tendance à pousser des nouvelles fonctionnalités) et les équipes opérations/SRE (qui vont plutôt avoir tendance à pousser des évolutions "non fonctionnelles" pour améliorer la fiabilité).

Le budget d’erreur est donc l’outil central de la démarche SRE qui permet de s’assurer que la fiabilité du système est suffisamment priorisée sans pour autant empêcher l’innovation et la livraison de nouvelles fonctionnalités aux utilisateurs.
Fiabiliser les systèmes à travers l'automatisation
Quand on pense aux activités d’une équipe de production, on pense rapidement à la gestion des incidents ou des tâches opérationnelles. La communauté SRE a d’ailleurs un terme bien précis, pour ces tâches “de run” qui n'apportent pas de valeur ajoutée au service : le "toil" (qu'on peut traduire par "labeur" ou "charge opérationnelle).

Un effort intentionnel doit être mis pour minimiser cette charge opérationnelle, et le meilleur moyen de limiter ce “toil”, c’est l’automatisation.
Automatiser ses tâches et son système a plusieurs avantages qui améliorent directement la fiabilité des systèmes :
La vitesse : La vitesse est la monnaie de l'économie digitale d'aujourd'hui. Automatiser permet de livrer plus rapidement, d'apprendre plus rapidement et donc de s’adapter plus rapidement
La consistance : Une action automatisée sera exécutée de la même manière de la première à la millième fois. L'automatisation élimine la principale source d'erreur : l'humain
La confiance : L'automatisation donne confiance en ses process de déploiement. Quand on est confiant dans son déploiement, on déploie plus souvent
La résilience : Automatiser son déploiement, c'est se permettre de redéployer rapidement en cas d'erreur ou d'incident
La transparence : Les process automatiques sont plus transparents : lire le code suffit pour comprendre ce qui est fait
Un meilleur temps de réaction : L'automatisation permet de détecter et corriger les incidents plus rapidement
L’autonomisation : à force d’automatisation on finit par arriver à un système autonome qui sait s’adapter à la charge (auto-scaling) ou qui est capable de s’auto-réparer (self-healing).
L'automatisation a également un avantage "indirect" non négligeable : elle permet de rendre l'organisation scalable.
Sans automatisation, la charge opérationnelle et manuelle est directement proportionnelle à une combinaison du nombre de serveurs, du nombre de service, de la taille de l'infrastructure ou du nombre de clients. L'automatisation est le meilleur moyen de minimiser le ratio “travail / trafic” et de découpler la charge opérationnelle de la taille de l'infrastructure ou de la quantité de trafic : ce que l'on cherche à avoir, c’est la même charge de travail qu'on ait 10, 50 ou 200 serveurs.
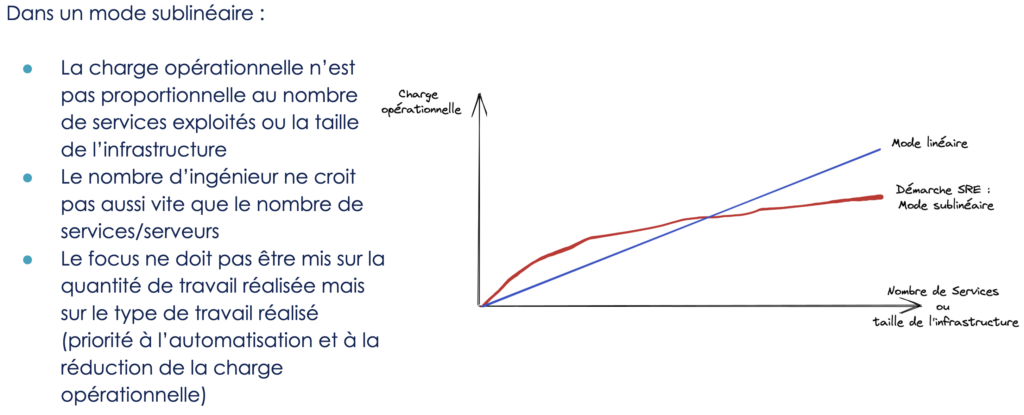
Cependant, si nous avions une chose à retenir de l'expérience cumulée de toutes les équipes opérations que nous avons pu croiser, c'est qu'une équipe de prod a beaucoup plus de chances de passer son temps sur des sujets urgents (incidents, opérations manuelles) que sur des sujets importants (ingénierie, automatisation, documentation...), les équipes se retrouvent régulièrement submergées par l'urgence et n'ont jamais le temps de travailler sur les tâches de fond.
La communauté SRE, et Google en particulier, a fait émerger une règle assez simple : au moins 50% du temps d'un SRE doit être dédiée à des tâches d'ingénierie : automatisation, documentation, architecture... Dit autrement, si un SRE passe plus de 50% sur du "toil" c'est qu'il y a un “bug” dans l'organisation ou sur la fiabilité des systèmes et qu'il faut "résoudre” en priorité ce bug. Le mode “par défaut” d’une équipe SRE, ce ne sont pas “les opérations”, c’est “l’ingénierie des opérations”.
Maximiser le retour sur investissement de vos incidents
Un incident en production, c'est toujours désagréable, mais quitte à dépenser de l’argent, de l’énergie ou de temps dans la résolution, autant maximiser le retour de cet “investissement”.
Le Post Mortem est un outil bien connu et régulièrement utilisé par les équipes qui opèrent des systèmes en production, l'objectif est de "refaire le match" après un incident afin de comprendre le déroulé ainsi que les causes racines de l’évènement. On étudie le contexte qui a mené à l’incident afin d’en tirer des enseignements :
Le cadre
L'environnement
Les process
Les décisions
Le post Mortem est un exercice difficile qui demande une certaine discipline pour s'assurer qu'on cherche à comprendre "pourquoi" un incident est survenu plutôt que "à cause de qui" un incident est survenu.
La littérature parle de "Blameless Post-Mortem" (rétrospective sans reproche en français).
Cette discipline est indispensable pour optimiser sa boucle d'amélioration continue : nous n’apprenons jamais mieux qu’à travers nos échecs, à travers nos situations d'incidents, mais pour tirer un maximum d’apprentissage d'un incident, il est indispensable que la culture de l'entreprise permette de partager ses erreurs, partager ce qui n'a pas fonctionné, partager ce qu'on a mal fait en toute transparence. Il est indispensable que les collaborateurs aient assez confiance dans l’organisation pour pouvoir lever la main et dire “c’est peut-être mon action qui a déclenché l’incident”.
Cette confiance en l’organisation a un impact immédiat sur les temps de résolution des incidents, et donc sur l’argent dépensé ou perdu à leur résolution. Une organisation dans laquelle les Post Mortems peuvent aller rapidement au fond des sujets et identifier les vraies causes racines permet d’apprendre vite et d’améliorer en continu la qualité et la fiabilité des services opérés.
SRE : Avant tout un changement culturel
En conclusion, le Site Reliability Engineering est avant tout une démarche de changement de culture et de manière d’opérer à adopter et à adapter en fonction des besoins spécifiques de son business. C’est un ensemble de bonnes pratiques, d’outils méthodologiques et techniques plutôt qu’un framework à appliquer à la lettre.
Ce que le SRE cherche, c’est avant tout l'amélioration continue des activités de “run” de son SI avec un objectif central : aborder les opérations et la fiabilité des systèmes de manière pro-active plus que réactive.
Pour tout savoir sur les enjeux Cloud, DevOps et Plateformes, cliquez ici.