SPARK + AI Summit Europe 2019
Introduction
Les 16 & 17 Octobre 2019, nous sommes rendus à Amsterdam afin d’assister à la conférence annuelle organisée par Databricks, le Spark+AI Summit, événement devenu incontournable dans le monde du Big data et de l’IA.
Cette année, ce sont plus de 2300 personnes qui ont fait le déplacement pour assister à de nombreuses présentations réparties sur 11 tracks en parallèle. Autant dire que les sujets étaient très denses et nous allons tenter de vous partager l’essentiel de ce qui a retenu notre attention.
Un des premiers constats de la conférence est la grande place prise par l’IA : la moitié des talks étaient pour Spark et son écosystème tandis que l’autre moitié était destinée à l’IA et plusieurs REX d’entreprises sur le sujet. L’impression donnée par la précédente édition s’est confirmée cette année : Spark n’est plus la seule préoccupation de Databricks. L’objectif de Databricks est désormais de fournir une plateforme unifiée, à la fois pour les populations de Data Engineers, de Data Scientists et de Data Analysts. Au programme, Spark 3.0, Delta Lake, Koalas, MLFlow, le Streaming et quelques REX d’entreprises.
Delta Lake
Dans la première keynote, Michael Armbrust introduit le produit star du Spark Summit : Delta Lake, qui permet aux ingénieurs de se concentrer sur l’extraction de la valeur des données
Au cours de la keynote, Michael Armbrust annonce également que Delta Lake a rejoint la fondation Linux pour aider la communauté à grandir.
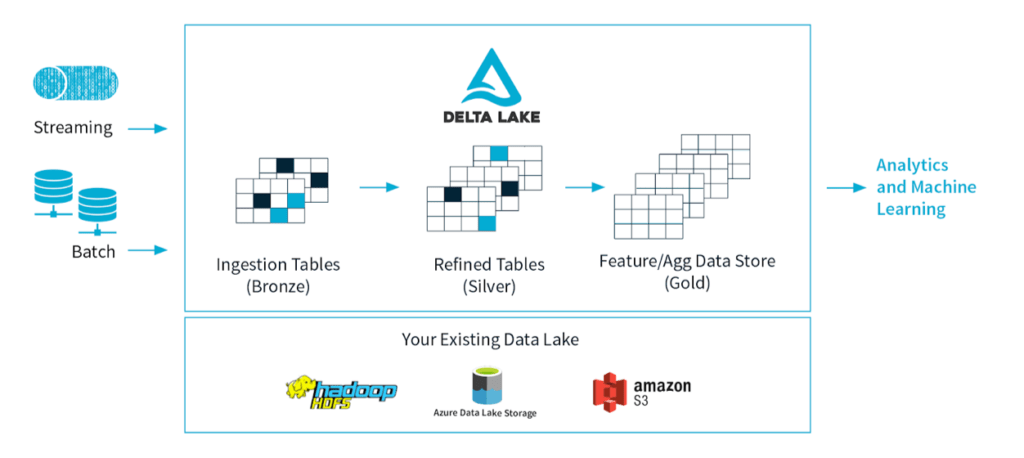
Delta Lake est une couche de stockage open source qui permet d’améliorer la qualité de la donnée de façon incrémentale jusqu'à ce qu'elle soit prête à la consommation. La donnée est répartie sur plusieurs niveaux de qualité:
- Bronze: ingestion des données de streaming et batch et sauvegarde dans un format de fichiers optimisé (Delta)
- Silver: nettoyage, filtrage, enrichissement et transformation des données
- Gold: ajout d’une logique et des agrégats business, création des features pour les cas d’usage de Machine Learning
Source: https://delta.io/
Delta Lake utilise Apache Spark comme moteur de processing et permet d’unifier le streaming et le batch. Il facilite également la modification des jobs existants pour les passer en streaming.
Delta Lake apporte des transactions ACID (Atomicité, Cohérence, Isolation et Durabilité) dans Apache Spark. Par exemple, cela veut dire qu’il est désormais possible de réaliser des transactions de type INSERT et UPDATE de façon atomique - la transaction se fait au complet ou pas du tout. Le mécanisme se base sur un log de transactions, appelé DeltaLog qui enregistre chaque opération réalisé sur une table Delta. DeltaLog peut être vu comme source unique de vérité ou un repository central.
Delta Lake fournit une isolation snapshot pour les lectures / écritures concurrentes et permet d’effectuer des opérations de upsert, de suppression et de rollback. Les fichiers sont optimisés via la compaction et le partitioning Z-Order (co-localisation des données connexes dans le même ensemble de fichiers) qui améliore la performance de 100x. Le problème des petits fichiers est désormais résolu.
Kyle Weller (Product Manager chez Azure Databricks) explique comment Delta Lake fait possible le “voyage dans le temps” via la nouvelle fonctionnalité : Time Travel.
Time Travel travaille sur des fichiers versionnés et sur un log de transactions qui garde la trace de toutes les actions effectuées.
Les applications de Time Travel sont:
- Audit des modifications de données: l’historique de toutes les opérations est enregistré.
Avec la commande DESCRIBE HISTORY <events> nous avons accès à plusieurs types d’information: le type d’opération, les identifiants des utilisateurs, du cluster et des notebooks, les timestamps des opérations et les versions
- La reproductibilité des données: il est possible de reproduire les résultats d’une requête. Par exemple, nous avons la possibilité de récupérer facilement le données utilisées pour l'entraînement d’une version ancienne d’un modèle de Machine Learning.
- Le débogage des pipelines de données
- Le rollback: nous avons la possibilité de revenir à une version spécifique de données et de corriger les données incorrectes.
Pour résumer, l'écosystème Spark est en train d’exploser en unifiant les meilleures caractéristiques du Data Lake et des bases de données relationnelles.
Koalas
Koalas : ou comment scaler du Pandas?
Nouveau projet open source de Databricks, Koalas est une librairie qui souhaite faciliter la transition des habitués du mono noeud au monde distribué en adaptant les fonctionnalités des librairies pySpark et pandas
Lors du Spark Summit Koalas est présenté comme une librairie qui se substitue à Pandas avec le minimum d’effort :

Il suffit de changer le import pandas as pd en import databricks.koalas as ks et voilà le tour est joué !
Maintenant toutes les Dataframes déclarés et les transformations qui leurs sont appliquées sont calculés de manière distribuée dans le cluster Spark. Un constat très intéressant, en somme Koalas se positionne comme l‘un des projets permettant de réduire le fossé entre les profils Data Scientist et Data Engineer.
Mais une question se pose : aujourd’hui qu’en est il vraiment ?
Tim Hunter précise que pour le moment que 60% des fonctions Pandas de base sont implémentées dans Koalas ainsi que toutes les fonctionnalités de Spark. Cependant, il existe des différences propres à la philosophie du moteur Spark qu’il faut prendre en considération :
- Spark est lazy par nature, ce qui veut dire que l’évaluation d’un Dataframe ainsi que toutes les transformations se font lors d’une action. (Principe de Lazy Evaluation)
- Spark est incapable de maintenir l’ordre des lignes.
- Spark est plus performant en distribué.
Pour réussir cette transition, les développeurs se sont appuyés sur les composants techniques suivants:
- Les InternalFrames : des structures qui permettent le mapping entre les Dataframes Spark qui sont immuables et les Dataframes Pandas en apportant un nombre de metadata en plus.
- Le default index : si aucun indice n’est précisé dans le Pandas Dataframe, Koalas attribue un par défaut pour gérer la distribution des données sur le cluster Spark, avec trois modes de distributions possibles : séquentiel, distribué, hybride
L’équipe de Databricks invite toutes les personnes intéressées à contribuer. Avec une volonté de terminer le développement des différentes fonctions pandas dans les mois à venir, optimiser les fonctions koalas déjà implémentés et réduire les latences éventuels lors des différentes transformations.
IA & Machine learning
Sur la partie IA et ML, le sujet principal était le déploiement en production des algorithmes de Machine Learning. On constate à travers des talks que les entreprises commencent à être de plus en plus matures sur le sujet. Le papier de Google a notamment été cité plusieurs fois sur la prise de conscience de l’effort et la complexité que cela implique. Plusieurs entreprises ont partagé leurs REX sur le sujet, avec pour certains des solutions construites en internes en l'absence d’un vrai acteur qui fait la différence sur ce sujet. Databricks souhaite fournir une solution standard et open source avec MLFlow.
On retiendra le talk d’IBM qui a partagé leur REX sur la mise en pratique d’une méthodologie de CI/CD au travers de quelques modèles de deep learning mis en open source.
MLFlow, Une plateforme machine learning open source
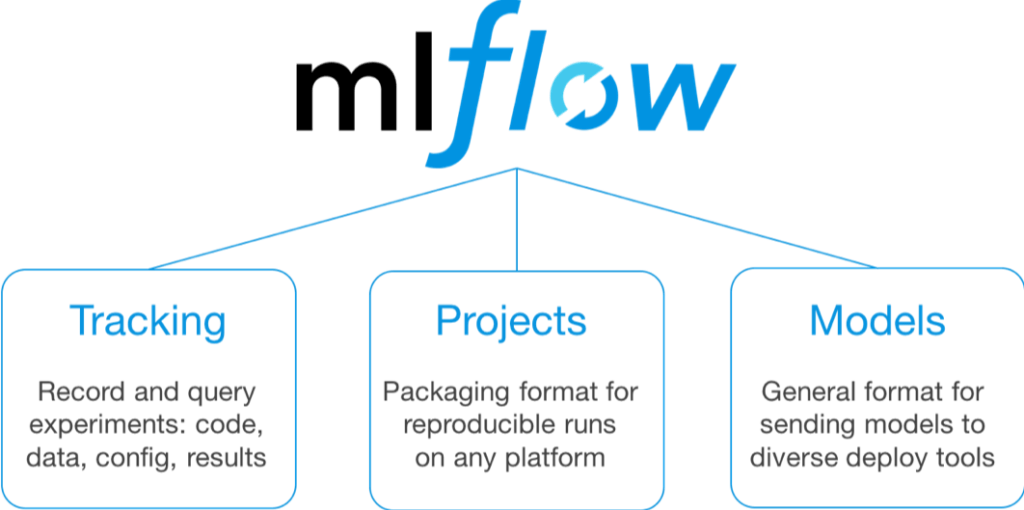
L’année dernière, Matei Zaharia faisait déjà l’annonce de la solution de Databricks, MLFlow pour faciliter la gestion des projets de ML à travers trois composantes principales : MLFlow Tracking pour tracer les données, les paramètres et les métriques pour un modèle donné, MLFlow Projects pour faciliter la création des projets de ML et MLFlow Models pour exposer les dits modèles.
Source : https://databricks.com/
Cette année, il a présenté les nouveautés incluses dans la nouvelle release 1.3.0.
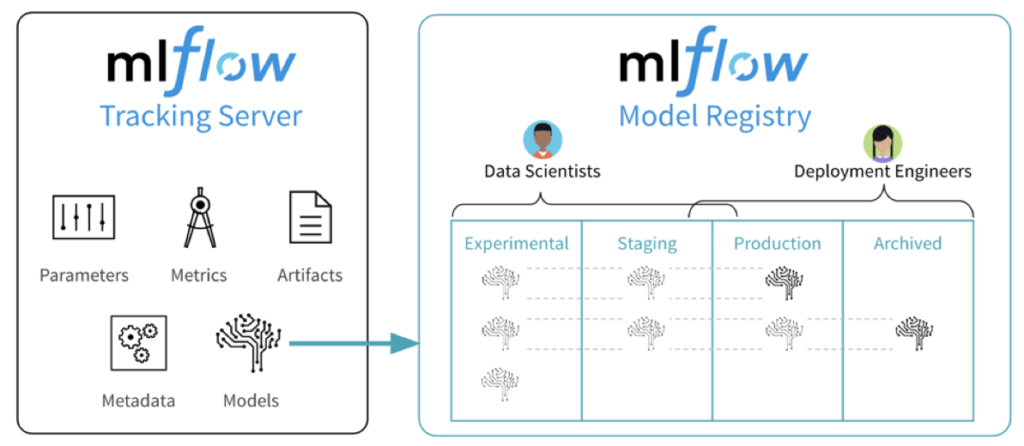
La grande nouveauté de MLFlow faite par Matei Zaharia était l’annonce de MLFlow Model Registry pour gérer le versionning des modèles et leur déploiement.
Source : https://databricks.com/
MLFlow Model Registry offre la possibilité d’avoir un hub central pour partager les modèles au sein d’une équipe et savoir quel modèle a été déployé ou et quand. Matei a pointé le fait que le management des modèles était la fonctionnalité la plus demandée par la communauté open source et devrait donc être intégrée dans la prochaine release. On a hâte de voir ce que ça donne avec des REX de la vraie vie.
Spark on Kubernetes
Des talks abordaient le déploiement de Spark conteneurisé dans le cloud, en utilisant l'orchestrateur de conteneurs Kubernetes.
Parmi ceux-ci, nous avons suivi celui d’ingénieurs de chez Palantir: Will Manning et Matthew Cheah. Ils nous présentent comment ils ont réussi à avoir des performances fiables en déployant Spark sur Kubernetes.
Depuis Spark 2.3, il existe une intégration native avec Kubernetes.
Lors de ce talk, ils nous racontent pourquoi et comment ils ont abandonné YARN au profit de Kubernetes.
Dans un cluster, on veut pouvoir gérer au mieux l’allocation des ressources, Spark on YARN propose une allocation dynamique où Spark définit lui-même les ressources à allouer dynamiquement à chaque job. Les avantages sont les suivants :
- extrait les performances maximales des ressources statiques
- fournit des masses de ressources pour un seul gros batch
- peut toujours lancer “un job de plus” en faisant de la place sur les clusters même dans des situations de contention pour la nouvelle tâche
MAIS ! C’est sur ce dernier point que les problèmes de l’allocation dynamique de Spark on YARN émergent :
- on n’a pas de réelle cohérence d’un run à un autre
- l’isolation des performances entre différents users/tenant devient compliquée car les jobs se font concurrences
Du coup, envisager Kubernetes pour ces raisons :
- conteneurisation native : pour pallier les lacunes de conteneurisation d’Hadoop/YARN security
- très extensible (scheduler, networking/firewalls) : pour pallier les lacunes de sécurité d’Hadoop/YARN security, passer de clusters statiques -> dynamiques
- une communauté très active avec une code-base qui évolue constamment
- une seule et même plateforme pour les microservices et le calcu
“Kubernetes scheduler is excellent for web services, not optimized for batch”
Un premier problème se présente. Comment assurer de bonnes performances dans un contexte conteneurisé ?
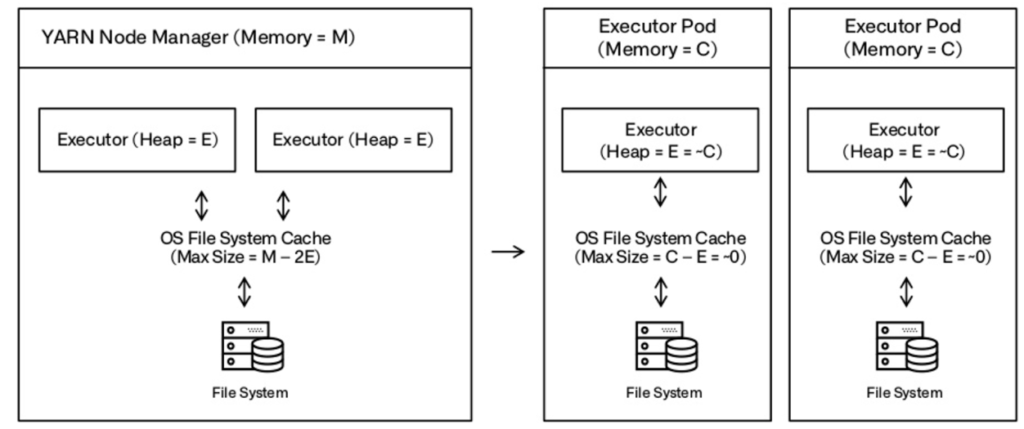
Spark on YARN, en se basant sur le file system cache avec HDFS pour stocker la donnée, a de très bonnes performances notamment sur les I/O. Kubernetes, s'il se base sur le file system, va avoir de piètres performances, car les file system des conteneurs sont plus petits et les accès par Docker sont plus lents qu'un accès direct au disque.
Les conteneurs ont chacun leurs systèmes de fichiers locaux. Chaque conteneur se voit allouer une quantité de mémoire qu’il est autorisé à utiliser. Pour faire tourner Spark, nous avons besoin de file system cache ainsi que de mémoire de la JVM Heap. Or cette dernière prend approximativement toute la mémoire que le conteneur est autorisé à utiliser. Il ne reste donc plus de mémoire pour le file system cache.
Sur Kubernetes on peut cependant utiliser ce que l’on appelle des volumes. Ce sont des stockages associés aux conteneurs. Il en existe différents types : il peut s’agir de fichiers/dossiers présents sur la machine hôte et qui sont montés sur le conteneur, de disques que l’on demande sur le cloud provider que l’on utilise ...
Source : https://www.slideshare.net/databricks/reliable-performance-at-scale-with-apache-spark-on-kubernetes
Solution : N'ayant pas assez de mémoire pour avoir des performances satisfaisantes, l'équipe a associé des volumes de type EmptyDir aux conteneurs, pour écrire directement sur des disques plus performant (SSD via un protocole Nvme).
Après avoir obtenu des performances satisfaisante dans Kubernetes, l’équipe Palantir a opté pour l’utilisation d’un scheduler maison pour répondre à un problème lié à la typologie d’utilisation des ressources spécifique à Spark. Le scheduler fourni par Kubernetes n’est pas fait pour des batchs distribués. Historiquement, il est bon dans l’optimisation pour les instances de microservice ou les tâches uniques.
Typiquement, l’exemple ci-dessous illustre parfaitement le fonctionnement de Kubernetes. Qui tente d’optimiser la valeur “nombre de pod schédulé”. Mais dans un contexte de batchs comme Spark, ce choix peut entraîner des cas de famine ou une tâche gourmande en ressources se retrouve bloquée par un grand nombre de petites tâches. Le risque est notamment important qu’un driver bloque ses propres executors...

Source : https://www.slideshare.net/databricks/reliable-performance-at-scale-with-apache-spark-on-kubernetes
Pour une utilisation de Spark dans Kubernetes, la solution proposée par l’équipe Palantir nous a semblé être une bonne alternative pour répondre aux problématiques de gestion dynamique des ressources, de stabilité et de performance.
Optimisations Spark 3.0
Dynamic partition pruning
La version 3.0 de Spark introduit une nouvelle optimisation afin d’augmenter la vitesse d’exécution des jobs SQL: le pruning dynamique des partitions. L’optimisation consiste à détecter et à éviter de scanner de données non pertinentes pour l'exécution d’une requête.
Bogdan Ghit et Juliusz Sompolski de Databricks montrent qu’en ce qui concerne la vitesse d’exécution d’un job, des améliorations notables ont été obtenues. Par exemple pour une requête TPC-DS sur un dataset de 10TB, la vitesse a été augmenté de 100x, en ne lisant que les données pertinentes pour le résultat final.
Le pruning statique des partitions est déjà présent dans le monde des bases de données standard : l’optimiseur évite de lire des fichiers qui ne peuvent pas contenir les données recherchées. La plupart des optimiseurs classiques utilisent la technique de Filter Pushdown qui permet d’éviter le scan complet d’un dataset - un filtre est appliqué avant le scan. Si le dataset est partitionné et que le filtre est appliqué sur une colonne de partition, des fichiers entiers correspondant aux autres partitions peuvent être ignorés.
La limitation du pruning statique apparaît quand on veut faire par exemple une jointure entre une table de dimensions de taille réduite et une table de faits de taille importante. Pour rappel une table de faits est composée de données de type clé de dimension (le contexte) et de données de type mesure (les faits). Les dimensions correspondent aux axes d’analyse. Le filtre peut n’être appliqué que sur la partie droite de la jointure (les dimensions) qui ne va pas éviter le scan complet de la table de faits.
En pratique, les plupart des data engineers réalisent la jointure faits - dimensions en amont et ensuite ils définissent des requêtes de filtrage. Les inconvénients de cette pratique sont:
- le coût important de la jointure
- la duplication des données - une table intermédiaire de grande taille est généré
- la difficulté de mise à jour des dimensions - le job coûteux de la jointure doit être relancé
Le pruning dynamique des partitions propose une autre approche qui consiste à réutiliser le filtre des dimensions afin de limiter les données lues de la table de faits.
L’optimisation opère à 2 niveaux: logique et physiques.
- Logique: le filtre dimensionnel est propagé à travers la jointure de l'autre côté du scan
- Physique: le filtre est exécuté une seule fois côté dimensions et les résultats sont ensuite réutilisés dans le scan de la table de faits
- Si la table de dimensions est de taille réduite (< 10 MB par défaut), Spark va réaliser une jointure de type Broadcast Hash. Les résultats filtrés sont broadcastés et utilisés comme filtre dynamique dans le scan de la table de faits.
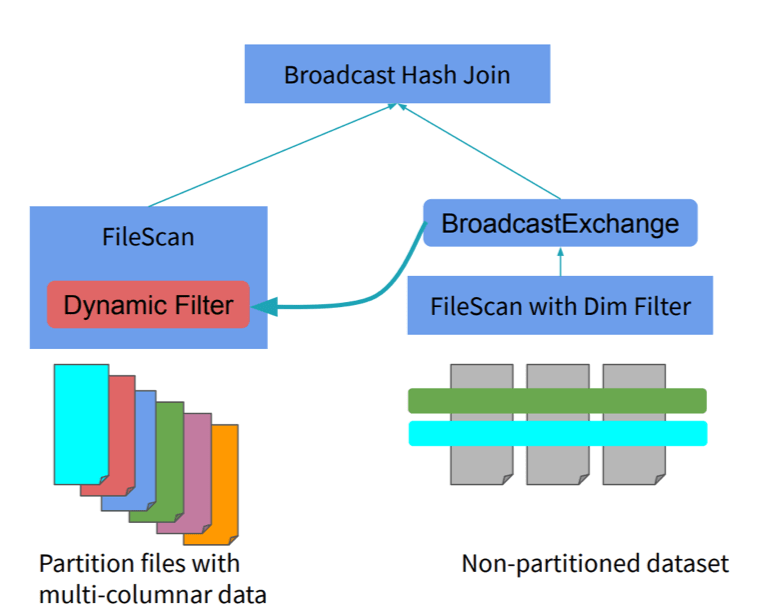
Source: https://www.slideshare.net/databricks/dynamic-partition-pruning-in-apache-spark
Avec cette nouvelle optimisation, Spark propose à améliorer la performance des requêtes de type star-schema et à éviter le ETL (Extract Transform Load) sur les tables dénormalisées.
Spark et les Graphes
Depuis quelques années, Databricks permettait la gestion de modèles en Graph à travers sa librairie Spark Graph. Mais cela restait un bout à la marge des développements.
D’un autre côté, Neo4J s’est imposé comme le leader des bases de données Graph et a même fait de son langage de requête CYPHER, est en passe de devenir un standard pour requêter les bases graphes.
Néanmoins une des limitations de l’outils de Neo4J est de ne pas pouvoir bien distribuer les traitements de données, ce que Spark peut faire aisément.
C’est ainsi que depuis quelques années, des équipes de Neo4J s’attellent à développer des outils pour pouvoir s'ajuster à Spark. Suite aux votes de la communauté des développeurs Spark, il a été décidé d’intégrer le langage CYPHER dans l’implémentation Graph de Spark 3.0.
C’est ainsi que Neo4J a développé un nouveau produit Morpheus, permettant d’utiliser pleinement CYPHER directement dans du code Spark, d’unifier les données transactionnelles de Neo4J avec la puissance analytique de Spark en permettant l’accès à des sources de données multiples.
La difficulté principale de cette intégration est la représentation des éléments propres aux bases graphes tels que les noeuds et les propriétés dans un format compris par le moteur Spark.
Pour ce faire, le type propertyGraph a été implémenté en s’appuyant sur la brique SparkSQL déjà existante. Concrètement, un propertyGraph est constitué d’un ou plusieurs DataFrame représentant les noeuds et les relations.
Côté développeur, la transition se fait assez simplement: on déclare un nouvel objet, le cypherSession qui s’appuie sur la sparkSession. A partir de là, on peut aisément écrire des requêtes CYPHER dans du code Spark comme dans l’exemple ci-dessous.
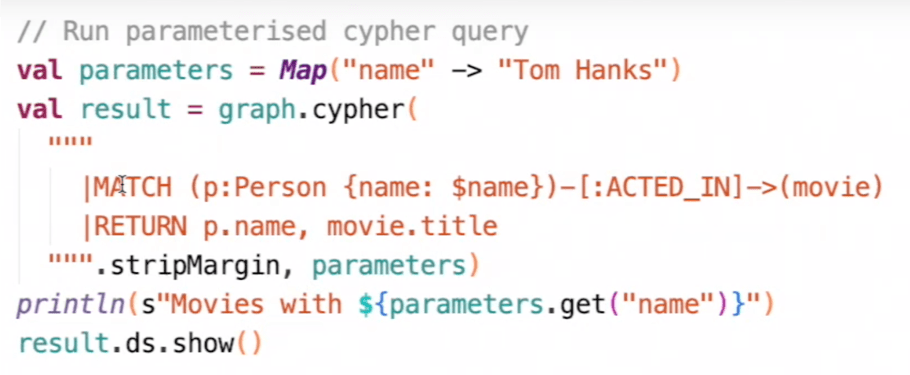
Sans rentrer plus en détail dans l’implémentation technique, il faut retenir que ce nouveau produit de Neo4J permet de:
- D’intégrer plus facilement des données venant de différentes sources dans un ou plusieurs ‘property graph’
- De permettre d’effectuer des requêtes Cypher de manière distribuée
- D’utiliser les algorithmes du monde Graph dans des travaux de Data Science grâce à la compatibilité avec les autres librairies Spark
Ainsi, il est intéressant de voir les efforts de Neo4J pour se rapprocher de Databricks et rendre ces deux solutions compatibles. Peut-être que cela permettra de rendre plus populaire l’usage de bases Graph, en tout cas nous avons pu voir des cas d’usage très intéressants pour des projets de Data Science dans le secteur pharmaceutique.
Pour aller plus loin avec les graphes :
- Tutoriel sur l’usage des graphes dans Spark :
Graph Features in Spark 3 0 Integrating Graph Querying and Algorithms in Spark Graph
- Cas d’usage dans la recherche pharmaceutique :
Transforming AI with Graphs: Real World Examples using Spark and Neo4j
Conclusion
Databricks a pour ambition de fournir une plateforme unifiée pour toutes les populations data (data analystes, data engineer et data scientist) grâce à des projets comme Delta Lake, Koalas et MLFlow, qui participent à la concrétisation de cette dynamique.
Cependant il reste du chemin à parcourir avant d’atteindre pleinement cet objectif, les data engineers de Zalando on vu par exemple le temps de leurs traitements augmentés lors de leur passage sur Delta Lake.
Plusieurs événements ont été organisés autour des femmes qui travaillent dans le domaine de la Data afin de partager sur le sujet de la diversité mais aussi des expériences professionnelles, des tendances technologiques et des opportunités de carrière. Dans cette optique Katie Bouman a présenté les méthodes et procédures mises en place pour la production de la première image d’un trou noir.
Finalement peu de chose ont été présenté sur les nouveautés de Spark 3.0 contrairement à ce qu’on pouvait s’attendre. Du côté des data scientists, la plus grande annonce reste MLFlow model Registry, un outil de management des modèles de ML.
Pour aller plus loin, nous partageons une liste de talks qui ont retenu notre intérêt:
- Apache Spark At Scale in the Cloud
- Apache Spark Core – Practical Optimization
- Stream Processing: Choosing the Right Tool for the Job
- Stream, Stream, Stream: Different Streaming Methods with Apache Spark and Kafka
- Imaging the Unseen: Taking the First Picture of a Black Hole
- The Parquet Format and Performance Optimization Opportunities