Sortir de sa bulle : diversifier les recommandations d'offres culturelles
Cet article est issu d'un travail de recherche effectué au sein de la SAS pass Culture par OCTO. Il n'engage pas la SAS pass Culture et les algorithmes tels qu'évoqués dans cet article ne sont à ce jour pas ceux implémentés dans l'application. Les différents jeux de données utilisés ne sont que partiels et les analyses ne sauraient être interprétées comme des éléments d'évaluation du dispositif en tant que tel.
Au cours des dernières décennies, avec l'essor de Youtube, Amazon, Netflix et de nombreux autres services Web de ce type, les systèmes de recommandation ont pris de plus en plus d’ampleur et de place dans nos vies. Du e-commerce (proposer aux acheteurs des articles qui pourraient les intéresser) à la publicité en ligne (proposer aux utilisateurs les bons contenus, en fonction de leurs préférences), les systèmes de recommandation sont aujourd'hui incontournables dans nos parcours quotidiens en ligne.
De manière très générale, les systèmes de recommandation sont des algorithmes visant à proposer des éléments pertinents aux utilisateurs (les éléments étant des films à regarder, du texte à lire, des produits à acheter ou tout autre élément selon les secteurs).
Par ailleurs, ces systèmes de recommandation sont essentiels dans certaines industries dans la mesure où ils peuvent générer d'énormes revenus lorsqu'ils sont efficaces ou être un moyen de se démarquer de manière significative des concurrents.
Dans cet article, nous parlerons de la diversification des recommandations ayant pour but d’identifier une liste d’éléments qui sont, à la fois, différents les uns des autres et pertinents pour les utilisateurs.
Quelques éléments de contexte
Nous nous intéresseront aux recommandations d’offres culturelles dans le contexte du pass Culture (https://pass.culture.fr/), un dispositif porté par le ministère de la culture, conçu pour faciliter aux jeunes, l’accès à la culture.

Il sied de rappeler que, le pass Culture a créé une application, lancée en février 2019 et qui propose aux jeunes de 18 ans, des offres culturelles pendant une durée de 2 années. Ces jeunes utilisateurs se verront attribuer un crédit de 500 euros qu’ils peuvent dépenser dans des offres de types très variés. Il peut s’agir de spectacles vivants, de pratiques artistiques, de musique, de livres audio, de la presse, etc. En mars 2020, l'application a atteint 64 000 utilisateurs et 1 121 388 offres.
Le principe, est que, quand un utilisateur se connecte, une offre lui est directement recommandée et il peut cliquer dessus pour avoir plus de détails sur ladite offre. Si elle l'intéresse, il peut la mettre en favoris, la partager ou la réserver. En revanche, si elle ne l'intéresse pas, il peut défiler et passer à l’offre suivante.
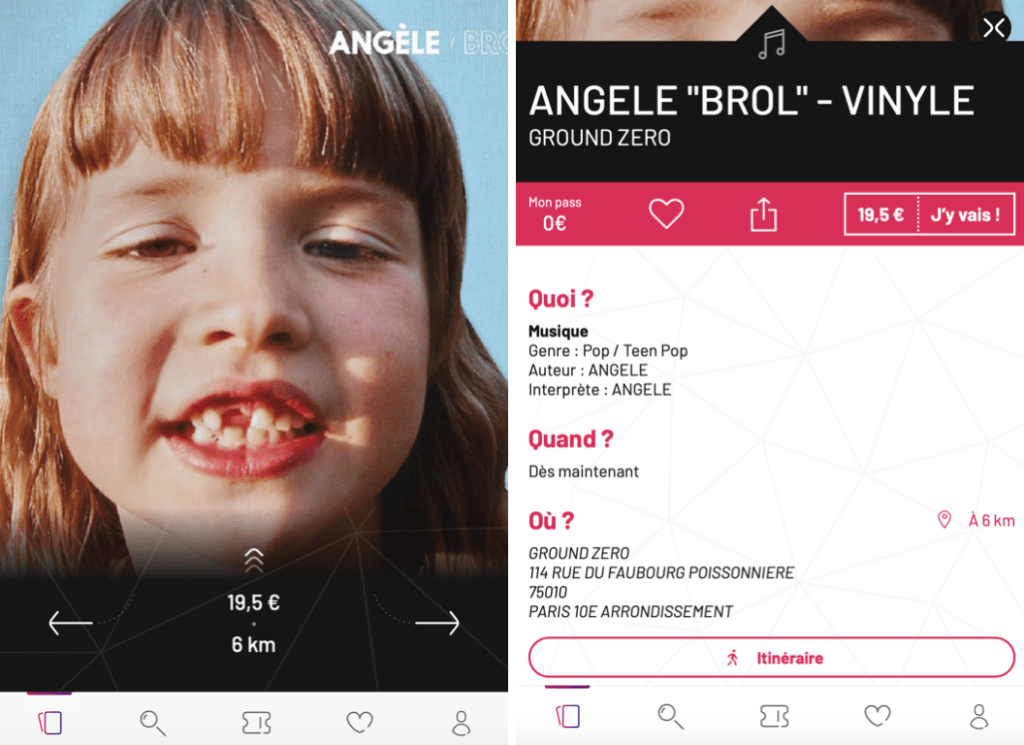
Application pass Culture
Notre objectif est de recommander des offres culturelles pour ces jeunes de façon personnalisée afin de leur proposer des offres pertinentes. Par exemple, on souhaite éviter de recommander des offres de concerts de rap à un utilisateur qui déteste ce genre de musique. Cependant, les utilisateurs seront mécontents si toutes les offres recommandées sont trop similaires les unes aux autres. Donc, un utilisateur qui réserve une offre d’encyclopédie une fois ne voudra pas qu’on lui recommande d’autres offres d’encyclopédie.
D’autre part, comme le pass Culture a comme objectif de faire découvrir de nouvelles activités et d’élargir les pratiques culturelle de ses bénéficiaires, un utilisateur fan de films ne doit pas avoir comme recommandation des offres de cinéma uniquement. D’où le deuxième objectif qui est de diversifier les offres recommandées aux utilisateurs.
Nous allons donc, dans un premier temps passer en revue les algorithmes de recommandations personnalisées et dans un second temps, explorer ce qui se fait en matière d’algorithmes de recommandations diversifiées afin de les appliquer à notre cas d’usage.
Algorithmes de recommandations personnalisées
Il existe deux grandes catégories d’algorithmes de recommandations personnalisées qui dépendent des différents types de données sur lesquelles ils s’appuient :
- L’algorithme basé sur le contenu ;
- L’algorithme du filtrage collaboratif.
L’algorithme basé sur le contenu : un risque de surspécialisation
L’algorithme basé sur le contenu va identifier le sujet d’une offre en répertoriant tous les mots du titre ou de la description de cette offre, puis va comparer tous les mots de l’offre analysée aux autres offres. Plus les offres auront un nombre de mots similaires, plus ces offres seront considérées comme «proches». Une fois ces offres regroupées en fonction de leur similarité, lorsqu'un utilisateur réserve une offre, le système lui recommandera des offres similaires à celle-ci.
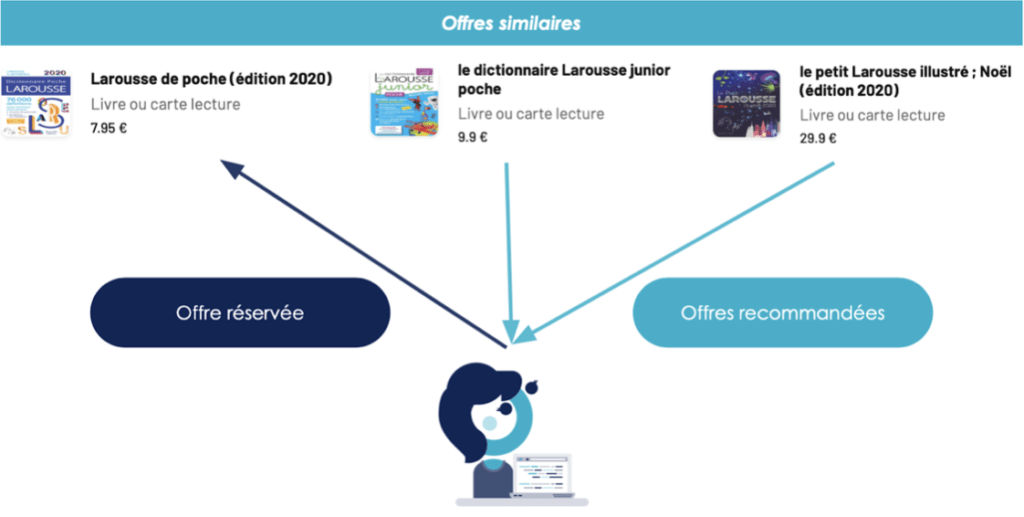
Principe de l'algorithme basé sur le contenu
Pour plus de détails concernant l’algorithme basé sur le contenu, veuillez vous référer à l’article du blog d’Octo “Introduction aux algorithmes de recommandation : l’exemple des articles du blog Octo“ (https://blog.octo.com/introduction-aux-algorithmes-de-recommandation-lexemple-des-articles-du-blog-octo/).
Toutefois, cette première approche ne répond pas à notre problématique de diversification, compte tenu de la surspécialisation des offres recommandées. Ce qui nous amène à une deuxième méthode qui ne se base pas, cette fois-ci ,sur le contenu des offres mais sur les interactions des utilisateurs au sein de l’application.
L'algorithme du filtrage collaboratif
Le filtrage collaboratif est l’une des approches les plus populaires pour construire un système de recommandation.
Dans le filtrage collaboratif, les interactions antérieures des utilisateurs sont analysées afin d'établir des connexions entre les utilisateurs et les offres. Le but est de recommander une offre à un utilisateur en fonction de ses interactions et celles des autres utilisateurs avec les offres proposées. Cette approche part du principe que les utilisateurs, qui ont des goûts similaires dans le passé, auront des goûts similaires à l'avenir. De même, un utilisateur évaluera deux offres de manière similaire, si les utilisateurs qui lui sont similaires ont donné les mêmes évaluations à ces deux offres.
Pour plus de détails concernant l’algorithme du filtrage collaboratif, veuillez vous référer à : https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe0
Le principe du filtrage collaboratif est d’utiliser les interactions des utilisateurs avec les offres afin de déterminer une affinité de chaque utilisateur avec chacune des offres. Ces interactions observées ou prédites peuvent être représentées sous forme de matrice :
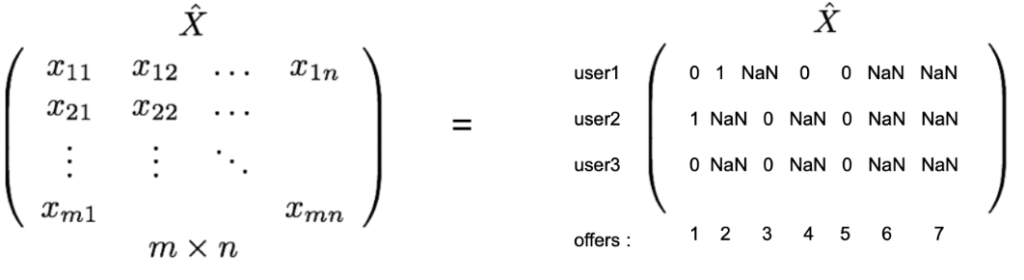
Cette matrice désigne les utilisateurs en ligne, les offres en colonne et l’intersection sera la note donnée par l’utilisateur à l’offre. L’affinité, chez Amazon ou Netflix, par exemple, vient de notes données par les utilisateurs, chose qu'on n'a pas au sein de l’application. Il faut donc modéliser cet attrait.
Quand un utilisateur réserve une offre ou la met en favoris, nous interprétons cela comme une manifestation de son intérêt. Nous labélisons cette action par un 1.
Quand un utilisateur swipe vers la droite pour passer à l’offre suivante ou quand il clique pour voir le détail puis passe à l’offre suivante, nous interprétons cela comme un manque d’intérêt. Nous labélisons cette action par un 0.
Si l’offre n’a jamais été recommandée à l’utilisateur, nous labélisons cette action par un NaN (Not a number). Il s’agit d’une valeur manquante que l’algorithme va devoir prédire.
Nous nous retrouvons avec une matrice ayant 70 milliards d’interactions entre les offres et les utilisateurs avec seulement 14 millions de notes (0 ou 1). C’est donc une matrice sparse qui est très grande et principalement vide puisque le taux de remplissage de notes est égal à 0.08 %. Toutes les autres valeurs sont des valeurs manquantes que l’algorithme doit prédire.
Une façon de gérer ce problème, consiste à tirer parti d'un modèle à facteurs latents pour capturer la similitude entre les utilisateurs et les offres. L’algorithme SVD, qui est la décomposition en valeurs singulières est le modèle à utiliser et plus particulièrement en faisant une factorisation matricielle. Cela va permettre de diminuer la dimension de la matrice en extrayant ses facteurs latents.
Pour plus de détails, veuillez vous référer à : https://hackernoon.com/introduction-to-recommender-system-part-1-collaborative-filtering-singular-value-decomposition-44c9659c5e75
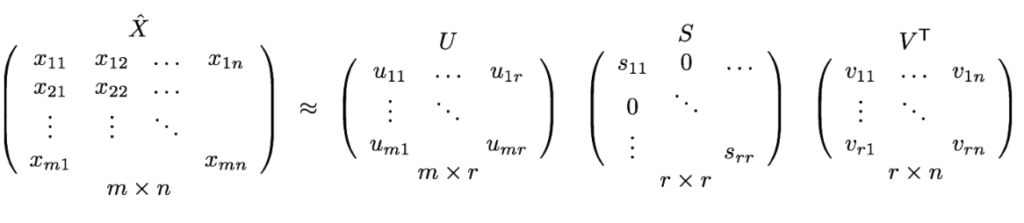
Décomposition en valeurs singulières
U est une matrice singulière gauche représentant la relation entre les utilisateurs et les facteurs latents, S est une matrice diagonale décrivant la force de chaque facteur latent, tandis que V est une matrice singulière droite, indiquant la similitude entre les offres et les facteurs latents.
Ce que l’on entend par facteur latent est une idée large qui décrit une propriété ou un concept réunissant plusieurs utilisateurs ou offres. Ces facteurs sont déterminés par l’algorithme et sont parfois interprétables. C’est le cas quand toutes les offres ont une valeur élevée pour un facteur latent sur un même genre de musique par exemple.
Une fois la matrice factorisée, l'algorithme prédit un score entre 0 et 1 pour les offres n’ayant pas encore été recommandées aux utilisateurs. Plus le score est proche de 1, plus l’offre est susceptible d'intéresser l'utilisateur et plus il est proche de 0, moins elle l’est. Pour se faire, les offres seront triées pour chaque utilisateur, par ordre de score pour ne prédire que les offres les plus pertinentes.
Un exemple d’offres que l’on recommande à un utilisateur :
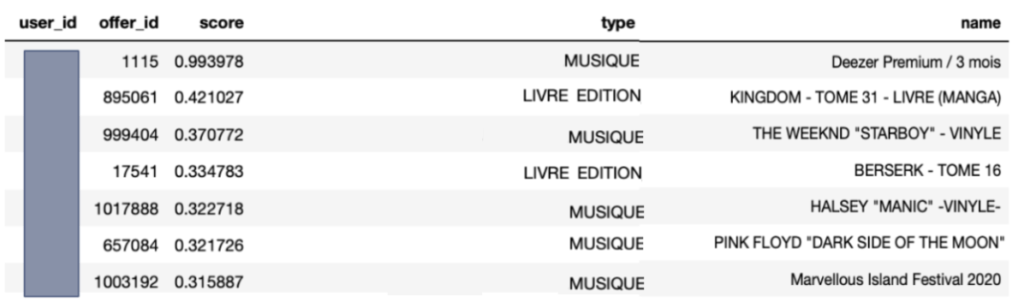
Offres recommandées à un utilisateur
Ensuite, étant donné que le but ultime est de diversifier les offres recommandées aux utilisateurs, il serait judicieux de regarder la distribution des types des offres :
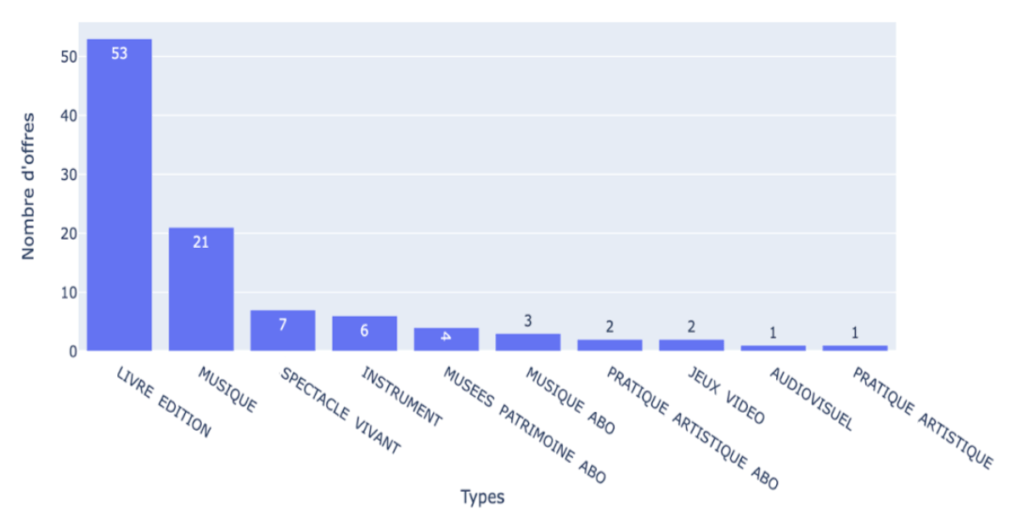
Distribution des offres par type
Dans cet exemple, plus de la moitié des offres recommandées sont de type “LIVRE” et plus d’un quart sont de type “MUSIQUE”. Le but va être de diversifier les types que l’on recommande.
Algorithme de recommandations diversifiées
Étant donné les offres à recommander obtenues grâce à l’algorithme du filtrage collaboratif, le scénario optimal de recommandation est de trouver un ensemble d’offres, qui a la distance de diversité la plus élevée et la pertinence agrégée la plus élevée. En général, un tel ensemble optimal n'existe pas : la maximisation de la diversité et le choix des offres les plus pertinentes sont souvent antagonistes. Par conséquent, nous devons explorer un équilibre entre la pertinence et la diversité, ce qui nous conduit à l’algorithme Swap.
L’algorithme Swap : bon compromis entre pertinence et diversité
L’algorithme Swap scinde en deux l’ensemble d’offres à recommander avec d’un côté, les K offres ayant le score le plus élevé (ensemble top-K), et de l’autre, les N-K offres restantes. Ensuite, l'idée de base derrière cet algorithme est d'échanger l’offre qui contribue le moins à la diversité de l'ensemble top-K avec la première offre de l’ensemble des N-K offres restantes qui contribue le plus à la diversité de l’ensemble top-K, c’est-à-dire la première offre qui a une distance de diversité supérieure à l’offre échangée.
Pour aller plus loin : https://openproceedings.org/2009/conf/edbt/YuLA09.pdf
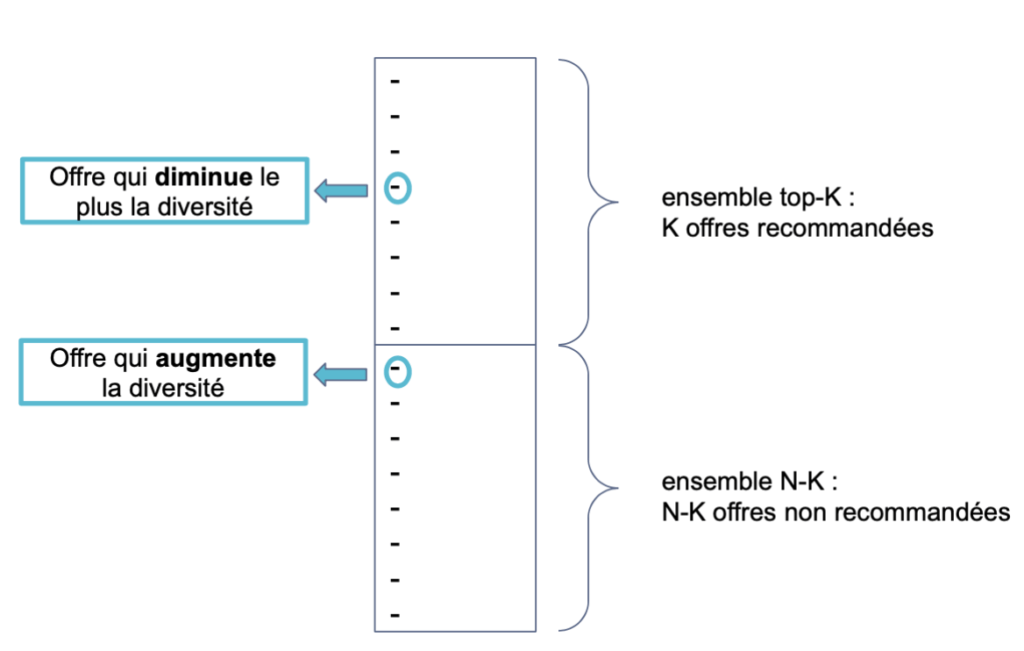
Principe de l'algorithme Swap
À chaque itération, une offre candidate de moindre pertinence de l’ensemble N-K est échangée avec une offre de l'ensemble top-K, si et seulement si, elle augmente la diversité globale de l'ensemble.
Pour mettre en place cet algorithme, Il faut définir cette distance de diversité.
La distance de diversité
Le but est de trouver une distance de diversité entre toutes les offres recommandées, mais ce n’est pas évident.
- En effet, la première méthode utilisée est le TF-IDF (https://www.quentinfily.fr/tf-idf-pertinence-lexicale/), elle se base sur les mots de la description des offres afin de trouver une distance entre toutes les offres. L’inconvénient, c’est que toutes les offres ne possèdent pas de description et donc n’ont pas de distance de diversité avec les autres offres.
- La deuxième méthode consiste à regarder la corrélation entre les offres en se basant sur les interactions des utilisateurs au sein de l’application. Or, cette méthode se trouve redondante avec l’algorithme du filtrage collaboratif, ce qui impacte la pertinence des offres recommandées.
En outre, comparer toutes les offres entre elles, pour trouver une distance de diversité, nécessite beaucoup de ressources de calcul; compte tenu du nombre d’offres que l’on doit comparer.
Finalement, l’approche retenue est de raisonner à partir des types et de trouver une distance de diversité entre les types, en se basant sur les réservations antérieures des offres par les utilisateurs. La question qui se pose est de savoir quelle est la corrélation entre réserver un type A et un type B ?
L’idée derrière cette question, c’est que, si plusieurs utilisateurs ont réservé des offres de types A et B, alors ces types sont fortement corrélés entre eux positivement. Cela veut dire que la distance de diversité entre ces deux types est petite. En revanche, si plusieurs utilisateurs ont réservé des offres de type A et jamais d’offres de type B, alors ces types sont fortement corrélés entre eux négativement et la distance de diversité entre ces deux types est grande.
Pour ce faire, il faut créer une matrice avec, en ligne les utilisateurs et en colonne les types d’offres. L’intersection est égale à 1 si l’utilisateur a réservé une offre de ce type, sinon elle est égale à 0.
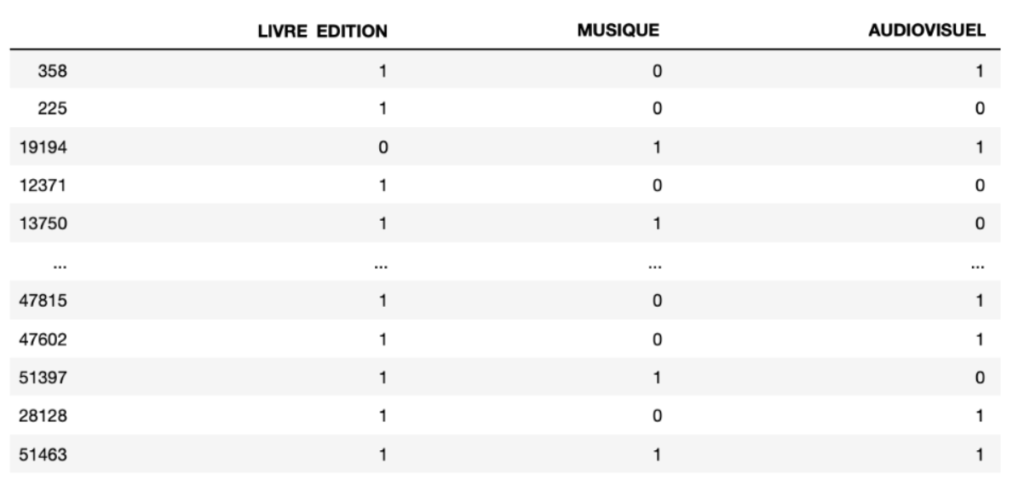
Réservation des utilisateurs en fonction des types
Ensuite, nous pouvons construire une matrice de corrélation entre les types. Plus la corrélation est proche de 1, moins les types sont diversifiés :

Matrice de corrélation entre les types
Nous pouvons aussi visualiser en mettant des couleurs, notamment, rouge, bleu et gris, à la matrice de corrélation ci-après, pour voir quels types sont les plus corrélés entre eux. Les valeurs rouges sont de fortes corrélations positives, les bleues sont des corrélations négatives et les grises ne sont pas corrélées :
→ Les utilisateurs qui réservent une offre de type LIVRE AUDIO vont aussi réserver des offres de type PRESSE ABO.
→ En revanche, les utilisateurs qui réservent les offres de type LIVRE ÉDITION ne vont pas réserver des offres de type MUSIQUE.
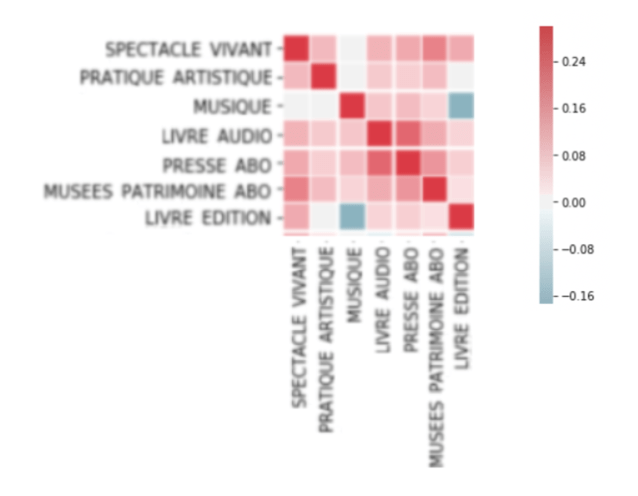
Une fois cette corrélation entre les types récupérée, nous pouvons appliquer l’algorithme Swap pour diversifier les offres recommandées.
Application de l’algorithme SWAP
Nous récupérons, grâce à l’algorithme du filtrage collaboratif, les offres recommandées à l’utilisateur, classées par ordre de score, puis nous scindons en deux cet ensemble, avec d’un côté, les K offres ayant le score le plus élevé (ensemble top-K) et de l’autre, les N-K offres restantes.
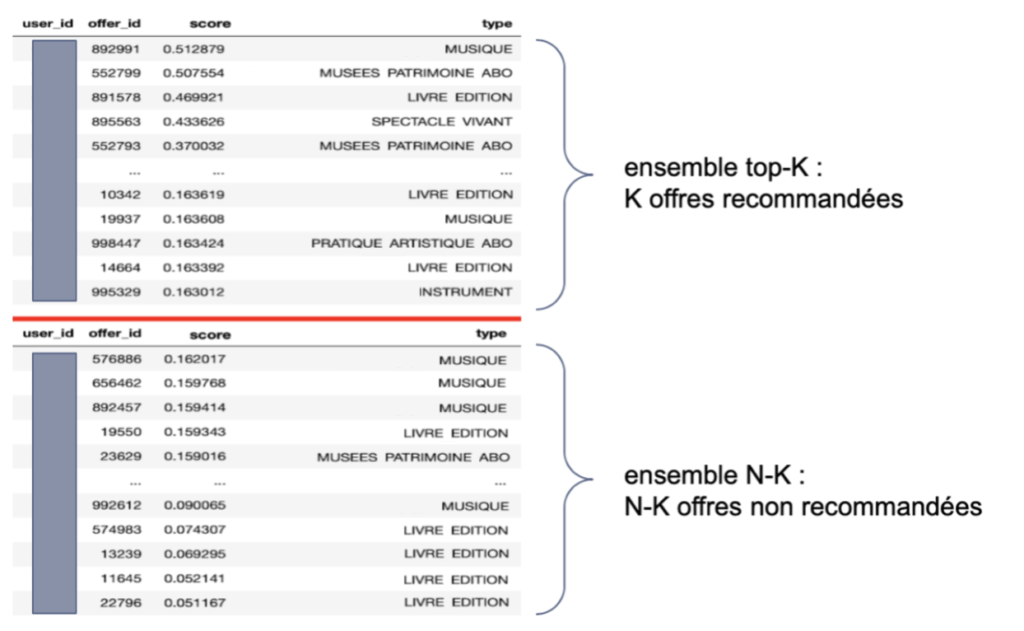
Séparation de l’ensemble d’offres recommandées en deux
Pour chaque offre de l’ensemble top-K, nous calculons la distance d’une offre avec les autres offres en se basant sur leur type. Pour cela, nous additionnons la corrélation entre le type de l’offre en question avec tous les types des autres offres.
Par exemple, pour la première offre, nous additionnons la corrélation entre : “MUSIQUE” et “MUSÉES PATRIMOINE ABO”, puis nous ajoutons la corrélation entre “MUSIQUE” et “LIVRE ÉDITION”, ensuite la corrélation entre “MUSIQUE” et “SPECTACLE VIVANT” et ainsi de suite.
Etant donné que, plus la corrélation est proche de 1, moins les types sont diversifiés, en additionnant les corrélations, nous nous retrouvons avec une mesure de similarité. En outre, maximiser la distance de diversité revient à minimiser la similarité des types. Plus la mesure de similarité est grande, moins les offres diversifient l’ensemble. Ici l’offre à échanger sera la troisième offre de type “LIVRE ÉDITION” du fait qu’elle ait la mesure de similarité la plus grande :
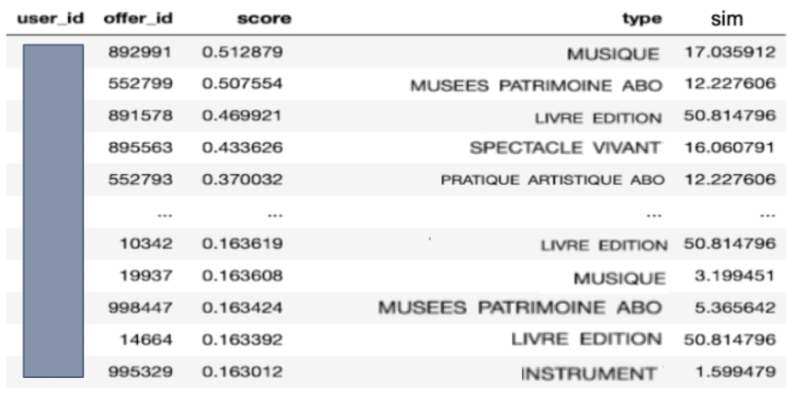
Mesure de similarité entre les offres en se basant sur leur type
Ensuite, Il faut chercher la première offre de l’ensemble des N-K offres restantes qui contribue le plus à la diversité de l’ensemble top-K, c’est-à-dire celle qui a une mesure de similarité inférieure à l’offre échangée. Pour ce faire, nous calculons la corrélation entre la première offre de l’ensemble des N-K offres restantes avec toutes les offres de l’ensemble top-K. Ici, l’offre de type “MUSIQUE” a une mesure de similarité inférieure à celle de type “LIVRE ÉDITION”, ce qui nous amène à les échanger.
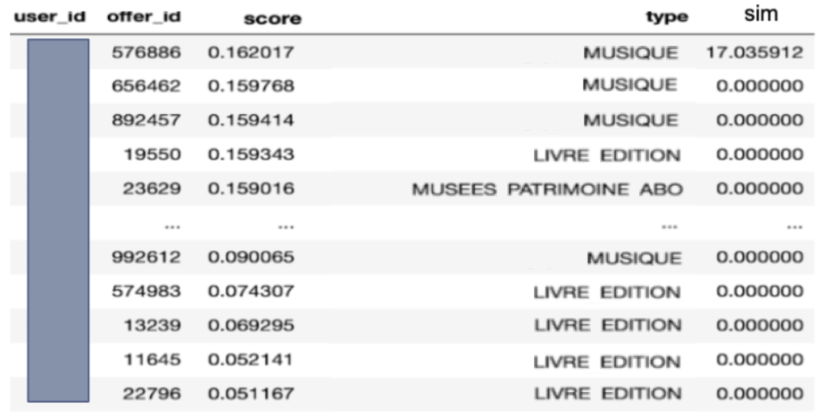
Mesure de similarité entre la première offre de l’ensemble N-K et les offres de l’ensemble top-K en se basant sur leur type
Ces échanges sont faits un nombre de fois limité en fonction du seuil de diversité et de pertinence que nous voulons atteindre.
Pour trouver ce seuil, nous calculons et traçons la similarité de l’ensemble d’offres à recommander après chaque échange en sommant la corrélation entre chaque offre et celles du dessous en fonction de leur type.

Exemple avec 4 offres différentes de types différents
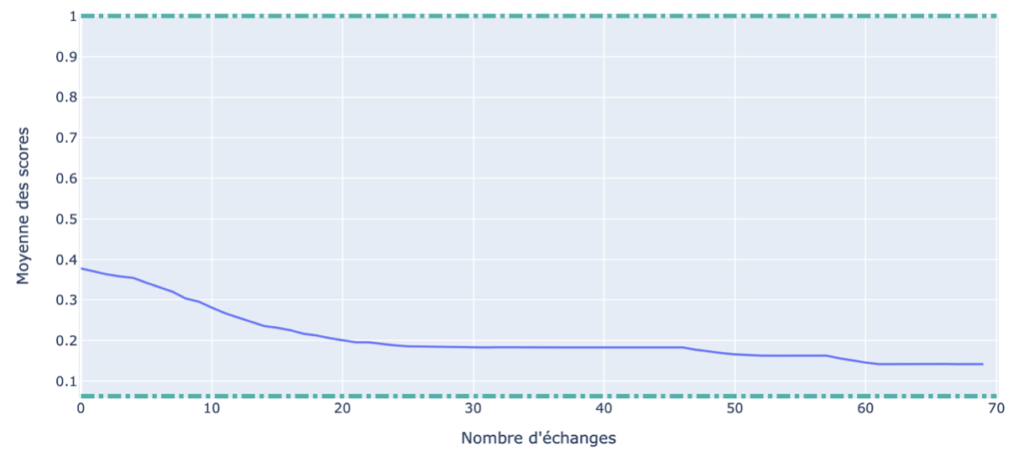
Similarité après chaque échange d’offres
Bien évidemment, après chaque échange d’offres, la similarité baisse puisque le but est de diversifier l’ensemble. Par contre, nous remarquons qu’il n’est pas nécessaire de faire plus de 70 échanges d’offres puisqu’à partir de seulement 20 échanges, la similarité de l’ensemble ne baisse presque plus.
Une fois le seuil trouvé, nous devons vérifier que la pertinence des offres que l’on recommande n’a pas totalement baissé. Pour cela, nous calculons la moyenne des scores après chaque échange grâce à la formule suivante :
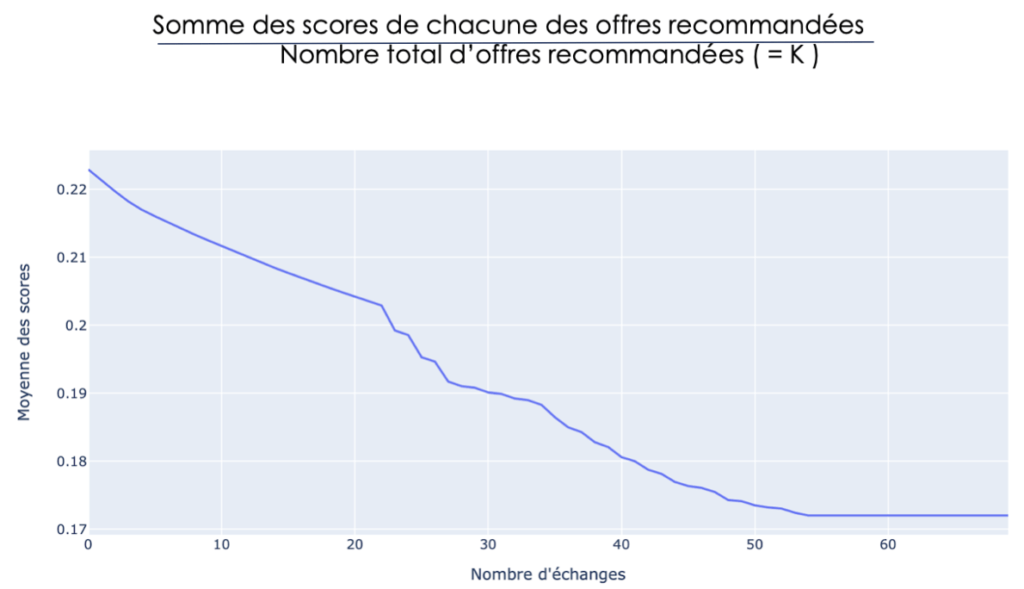
Moyenne des scores après chaque échange d’offres
Manifestement, l’ensemble d’offres recommandées perd de la pertinence mais, nous remarquons qu’après 20 échanges, la moyenne des scores ne baisse que d’un quart.
Au final, en faisant ces 20 échanges, nous nous retrouvons avec une distribution des types plus équilibrés.
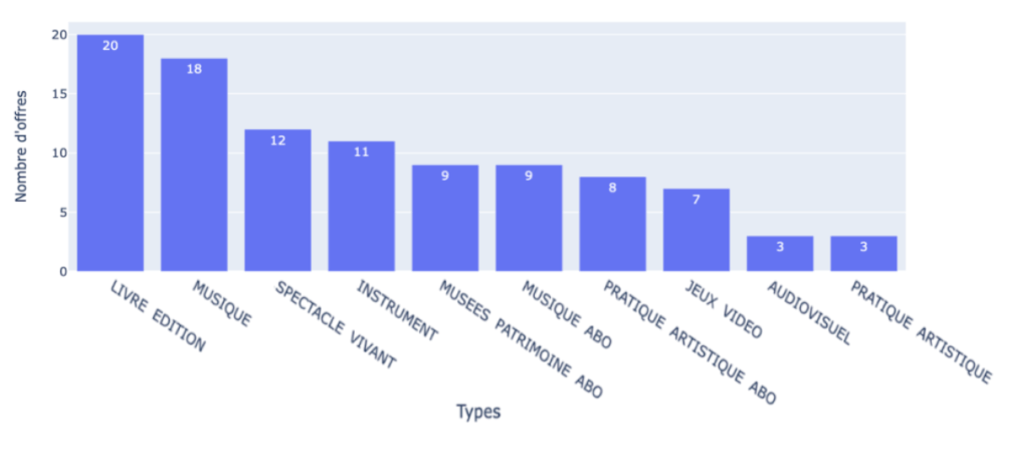
Distribution des offres par type après 20 échanges
Conclusion
En guise de conclusion, il y a lieu de signaler que l’algorithme basé sur le contenu n’est pas le plus optimal dans notre cas pour faire de la recommandation d’offres culturelles compte tenu de la surspécialisation des offres recommandées. Le risque de cet algorithme étant de ne recommander aux utilisateurs que des offres similaires et de ne pas diversifier leur pratique culturelle.
En revanche, l’algorithme du filtrage collaboratif se trouve être un bon moyen de faire de la recommandation pertinente d'offres culturelles aux utilisateurs. Cet algorithme analyse les interactions des utilisateurs avec les offres au sein de l'application permettant d’établir des connexions entre les utilisateurs et les offres_._ L’algorithme prédit un score compris entre 0 et 1 pour chaque couple << utilisateur, offre>>. Plus le score est proche de 1, plus l’offre est pertinente et donc, sera recommandée à l’utilisateur.
Cet algorithme est ensuite combiné avec l’algorithme Swap qui nous permet de diversifier les offres recommandées en se basant sur une distance de diversité calculée à travers les types des offres.
Pour finir, l’inconvénient majeur de ces méthodes est le manque de données des nouveaux utilisateurs . En effet, ces utilisateurs n’auront encore aucune interaction au sein de l’application et le risque serait de ne leur proposer aucune offre. Pour pallier à ce problème, il est possible de leur recommander des offres populaires afin de récupérer leurs interactions avant de pouvoir utiliser notre système de recommandation.