Sortir d’un mainframe complexe via une stratégie de Double RUN
La transition d'une infrastructure vieillissante complexe vers une infrastructure plus moderne est un défi de taille, surtout lorsqu'il s'agit de décommissionner un mainframe en place depuis plusieurs décennies.
C’est dans ce contexte que le programme Alpha (nom volontairement modifié pour des raisons de confidentialité) a été lancé, avec pour objectif de remplacer un mainframe âgé de plus de 30 ans, utilisé pour gérer des dizaines de millions de dossiers, avec une activité intense : 250 000 opérations quotidiennes, servant d'outil de travail à plus de 3 000 utilisateurs quotidiens.
La refonte complète du système d'information (SI) s'est imposée comme une nécessité. En plus d'offrir une expérience utilisateur très complexe, peu intuitive, le tout reposait sur une technologie obsolète, non maîtrisée, provoquant une explosion des coûts d’exploitation et de maintenance. Le système avait atteint ses limites d'évolution alors que des évolutions majeures étaient indispensables pour répondre aux besoins métiers. De surcroît, les données étaient fragmentées et dupliquées dans plusieurs systèmes annexes, ce qui engendrait des difficultés d'exploitation et des problèmes de cohérence des informations.
Cet article explore les étapes clés, les défis rencontrés et les leçons tirées de cette transformation technologique ambitieuse.
Une stratégie pilotée par les risques et garantie par un double run
Quelques années plus tôt, une première tentative de modernisation avait échoué, principalement en raison de la complexité des règles de gestion (moteur de calcul) et de la difficulté à reprendre les données existantes. Après plusieurs années de développement, il s'était avéré impossible de récupérer les données de l’ancien système tout en obtenant des résultats aux traitements métiers équivalents à ceux du mainframe.
Pour cette seconde tentative, il était crucial pour les parties prenantes de sécuriser ces deux aspects critiques. Un Proof of Concept (PoC) a donc été lancé afin de démontrer la faisabilité de la reprise de données et de l'application des règles métiers. Pour garantir la qualité et la fiabilité des résultats, le développement d’un outil de comparaison des données s’est révélé indispensable. Cet outil permettait de confronter les données "froides" (reprise des données historiques et données calculées) et les données "chaudes" (données entrantes, sortantes et l’activité en temps réel sur l’application) entre le mainframe et le nouveau SI.
Par la suite, l’ensemble des fonctionnalités a été développé de manière itérative, assurant ainsi une transition fluide et maîtrisée.
Valider les fonctionnalités les plus risquées grâce au double run
L’enjeux majeur de ce projet : s’assurer que le moteur de calcul est au moins iso au mainframe. Pour sécuriser cette transformation, une stratégie de double run a été adoptée. Cette approche consiste à faire coexister l’ancien et le nouveau système pendant une période de transition, permettant ainsi de comparer les résultats et de valider progressivement les fonctionnalités les plus risquées.
Voici les étapes clés de cette stratégie de double run:
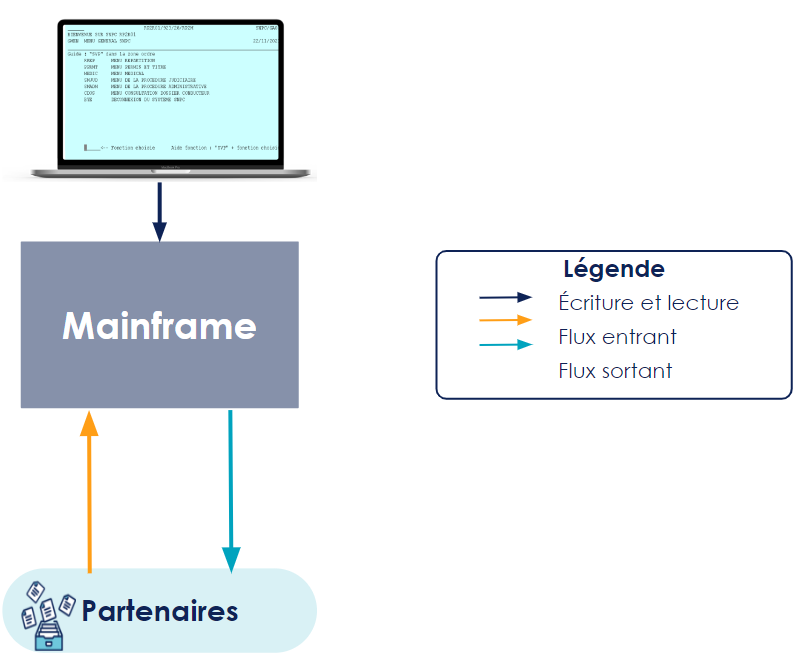
1. Situation initiale : les lectures et les écritures se font sur le mainframe uniquement.
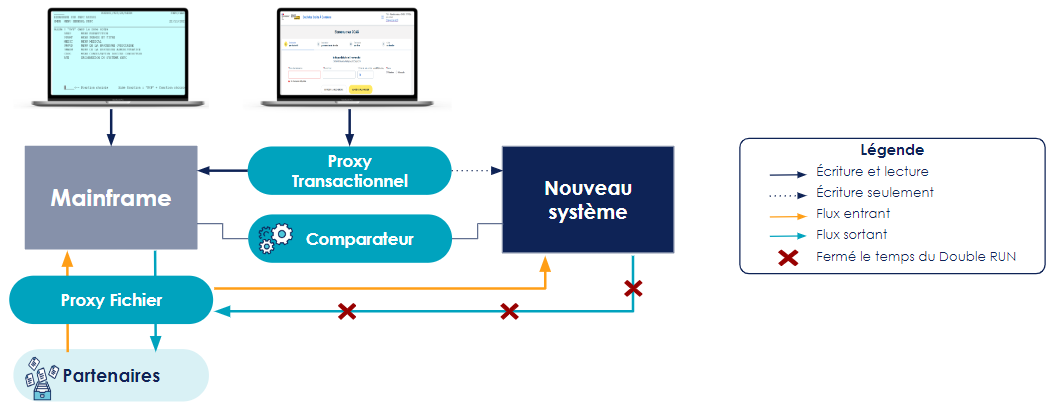
2. Mise en place du double run et bascule progressive des fonctionnalités : Au fur et à mesure du développement des fonctionnalités, les écritures de la nouvelle IHM sont envoyées simultanément sur le mainframe et le nouveau système grâce au “Proxy Transactionnel”, tout en maintenant le mainframe comme système maître (source de vérité avec les droits de lecture après écriture). Concrètement sur la nouvelle IHM, bien que les modifications soient envoyées aux deux systèmes, l'utilisateur voit les mises à jour apportées sur le système maître (mainframe). Le comparateur joue tout son rôle pour identifier les écarts entre les deux systèmes. Les équipes fonctionnelles avec le métier peuvent ainsi réaliser des analyses approfondies et résoudre les écarts qui peuvent être dus à un problème soit dans la reprise de données, soit un bug dans les développements de la nouvelle fonctionnalité, soit des écarts de l’activité générée sur le mainframe (qui ne sait pas écrire sur le nouveau).
Au fur et à mesure que les développements des fonctionnalités avancent, les utilisateurs ont accès à une IHM plus complète où ils peuvent réaliser l’ensemble des opérations qu’il doit traiter au quotidien.
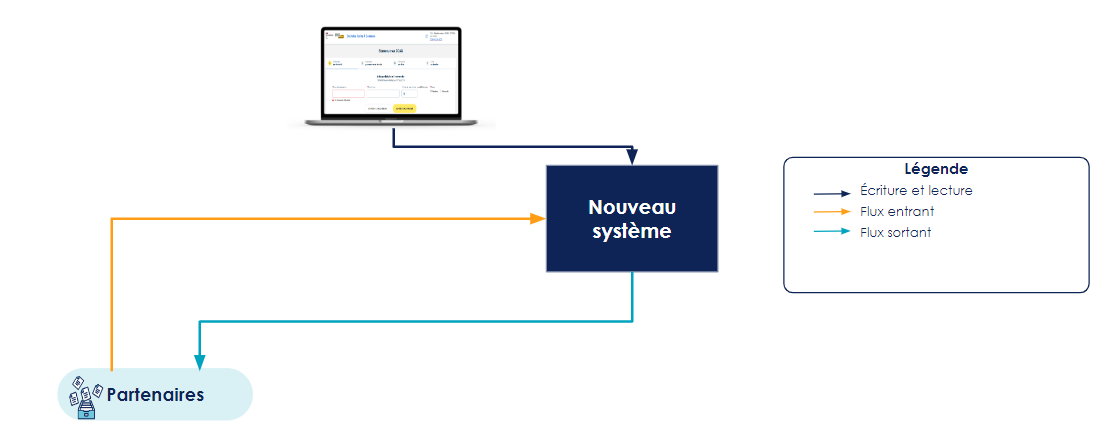
3. Décommissionnement : Finalement, une fois la fiabilité du nouveau système confirmée, le mainframe et les proxys (transactionnels et de fichiers) peuvent être décommissionnés, et le nouveau système devient le maître unique.
Ayant adopté une approche Agile avec des mises en production régulières, le double run a d'abord été partiel. Toutes les fonctionnalités n'étaient pas encore développées dans le nouveau système et étaient intégrées progressivement. Une reprise de données fréquente (à la demande, environ deux fois par mois) était nécessaire pour supprimer les écarts dus aux activités sur l'IHM de l'ancien système. À chaque reprise de données, une nouvelle fonctionnalité pouvait être comparée sur une période et un périmètre restreints.
Par la suite, le double run est devenu complet, permettant une comparaison de l'ensemble du système.
L’autre défi du PoC : assurer la reprise de donnée
La capacité à reprendre les données du mainframe constitue l’autre risque majeur de ce projet. Lors de la phase de cadrage, une stratégie de reprise efficace a été définie, visant à trouver un équilibre optimal entre la minimisation des impacts sur l'écosystème, la réduction des risques et l'optimisation des coûts. Pour élaborer cette stratégie, plusieurs questions clés doivent être posées :
- Qualité des données : Dans quelle mesure devons-nous garantir la qualité des données ? Est-il acceptable de ne pas avoir l’exhaustivité des données ? La réponse à ces questions dépend du système concerné. Par exemple, pour un CRM, il peut être acceptable de ne pas récupérer des vieilles données sans impact significatif. Cependant, pour notre SI, il est crucial de récupérer des données exactes et exhaustives en raison de leur impact sur l'état actuel calculé.
- Impact sur les utilisateurs : Quels impacts sur les utilisateurs sont acceptables ? Est-il possible d’avoir une interruption de service pour nos utilisateurs ? Qu'en est-il de nos partenaires ? Quelle serait la durée acceptable de cette interruption ?
Concernant notre programme, nous avons pu négocier une durée d’indisponibilité du service de 3 jours (lors d’un WE prolongé) pour limiter les impacts tout en permettant la lecture pour certains partenaires, leur donnant accès à l’état d’un dossier à la date du début de la reprise des données. En revanche, dans d’autres secteurs, comme un centre d’appel d’urgence, une telle interruption serait inacceptable. - Ressources disponibles : Quelles sont les forces vives disponibles ? Avons-nous l’ensemble des expertises nécessaires pour réaliser la reprise des données ? Serons-nous capables de gérer tous les obstacles techniques et organisationnels qui peuvent survenir ?
- Coûts de la reprise : Quels sont les coûts associés à la reprise des données ? Comment peut-on les limiter et les optimiser ?
En répondant à ces questions, nous pouvons concevoir une stratégie de reprise de données qui garantit la qualité requise tout en étant efficace et efficiente, minimisant ainsi les risques et les impacts sur notre écosystème. L'utilisation d'un comparateur a permis de valider la qualité de la reprise des données.
Les Piliers de la réussite
Suite à l'arrêt définitif du mainframe, nous avons dégagé 5 facteurs qui ont été clés dans ce succès et qui ont permis de moderniser le SI.
La priorisation par le risque
Dans cette refonte, la quasi-totalité des fonctionnalités étaient des "must-have", rendant difficile la priorisation par la valeur. Comme évoqué précédemment, l'objectif a donc été de réduire les risques associés aux sujets les plus complexes le plus rapidement possible. L’approche initiale a consisté à cartographier l’ensemble des fonctionnalités du mainframe afin de prioriser les sujets les plus épineux techniquement et les plus chronophages (reprise de données, moteur de calcul, gestion des événements, ordonnanceur de batchs, etc.).
Pour nous aider dans cette tâche, nous avons créé une représentation graphique à deux axes : la difficulté de réalisation (de 1 à 5) sur l'axe vertical et le temps de développement estimé de bout en bout (de 1 à 5) sur l'axe horizontal. Cette estimation prenait en compte les délais importants tels que les phases de recette avec les partenaires et la comparaison des écarts issus du double run.
Cet outil, conçu pour être évolutif, était réévalué en continu, permettant ainsi une priorisation ajustée en fonction de l’évolution des développements. Grâce à cette méthode, nous avons pu nous concentrer d'abord sur les éléments les plus complexes et les plus risqués, assurant ainsi une progression efficace et sécurisée du projet.
Rester concentré sur le décommissionnement malgré toutes les demandes et les tentations
Dans cette refonte à la fois risquée et complexe, il était crucial de rester concentré sur notre objectif principal : le décommissionnement du mainframe.
Cela signifie, avant tout, que nous devions assurer que toutes les fonctionnalités existantes du mainframe soient répliquées de manière fiable dans le nouveau système avant d'envisager toute nouvelle fonctionnalité structurante.
Cela implique également de maintenir stables les contrats d'interface avec nos partenaires tout au long de la transition. En évitant toute modification de ces interfaces, nous réduisons les risques de complications, d'erreurs et de retards, d'autant plus que toute modification de contrat d'interface avec un partenaire est une opération chronophage sur laquelle nous n'avons pas une totale autonomie. Cette stabilité facilite l'adoption du nouveau système et assure une transition plus fluide.
L’objectif était de limiter au strict minimum les évolutions sur le mainframe, en tenant compte des impacts potentiels. Cela a contribué à éviter des retards dans le processus de décommissionnement et à maintenir notre calendrier.
Éprouver le double run le plus rapidement possible
Le double run, bien qu'efficace pour gagner la confiance des parties prenantes, est complexe et coûteux. Il est impératif d'éviter l'effet tunnel et de tester les fonctionnalités développées au fil de l’eau. Nous avons mis en place un système très efficace de canary release, nous permettant d’activer une fonctionnalité en production pour certains utilisateurs experts. Ceux-ci certifient le bon fonctionnement avant de l’activer pour l’ensemble des utilisateurs habilités pour ensuite faire une comparaison sur une volumétrie plus conséquente.
Notre stratégie de test & learn était bien rodée. Le comparateur, qui nécessitait une maintenance régulière en fonction des fonctionnalités développées, aidait les équipes à analyser et à corriger. Le plus difficile était de toujours chercher à détecter l'exhaustivité des écarts, au risque de rallonger les délais dans la boucle de test & learn (analyse, correction, attente de quelques jours d’activité en production pour une nouvelle analyse).
Même avec une fréquence de mise en production très réduite - deux fois par semaine, puis toutes les semaines, la boucle de feedback peut être très longue et fatigante pour les équipes.
Savoir quand mettre fin au double run
Maintenir cette architecture de double run est complexe et coûteuse. Il est essentiel de savoir quand mettre fin à cette phase et pour pouvoir le plus rapidement possible déclarer le nouveau système comme étant désormais le système maître. Voici quelques points clés à considérer :
- Accepter les imperfections et avoir une approche bénéfice / risque. Mettre fin à la double architecture réduit les coûts liés à la maintenance et à l'exploitation de deux systèmes. Une architecture simplifiée permet une gestion plus efficace des ressources et des opérations.
- Identifier les fonctionnalités de confort, celles dont on peut se passer (surtout en cas de retard !). C'est-à-dire celles n'empêchant pas le décommissionnement du mainframe et qui peuvent être développées ultérieurement (comme l’analyse de données froides). Si nécessaire, il ne faut pas hésiter à négocier avec les parties prenantes.
Le jour J, le jour de la migration de données et du décommissionnement du mainframe, il est primordial de mobiliser une équipe d’experts techniques et métiers capables d’attester de la bonne exécution des principales fonctionnalités. Cette équipe doit être prête à valider le nouveau système en réunion de GO / NO GO.
Pour les plans de migration à risque et à fort impact business, prévoyez un plan de rollback (retour arrière) pour ne pas pénaliser les utilisateurs en cas de problème lors de la migration de données.
Définir une stratégie robuste de bascule et de reprise de données
La migration de données d’un mainframe est complexe et demande de la répétition pour être bien exécutée le jour J, celui de la bascule finale. Dans notre cas, nous avons répété l’opération plus de 70 fois. Chaque répétition a permis d'améliorer itérativement les performances, les automatisations et le monitoring. Le chronogramme des opérations a évolué avec chaque répétition, se stabilisant à 144 étapes étalées sur 3 semaines (coupure des flux, coupure des IHM, migration des données, réactivation des flux, etc.).
Le succès de cette migration est aussi lié à la communauté d’experts polyvalents (PM, PO, SAE, DEV, OPS) qui se sont engagés dans la durée (3 années concernant le programme Alpha).
Aussi, nous avons programmé deux bascules à blanc en conditions réelles, avec une surveillance continue H24 pour nous assurer que tout se déroulait comme prévu. Il est important également sur ce type d’opération de ne pas oublier de gérer l'administratif pour les travaux le week-end et les astreintes (accès au bâtiment, droit du travail, etc.)
Après la bascule, nous avons mis en place une Task Force dédiée pour disposer des compétences nécessaires afin de traiter rapidement les éventuels bugs non identifiés et prioriser les sujets. Par chance, cette Task Force n’a pas in-fine eu à intervenir, mais la prévoir permet d’avoir une assurance et de rassurer l’ensemble des parties prenantes.
Ce que nous aurions pu mieux faire
Apprendre plus rapidement des utilisateurs
Après quelques semaines de développement, le support nous a indiqué qu’il n’y avait aucune demande des utilisateurs. Alors que nous pensions que tout fonctionnait parfaitement et qu’il n’y avait aucun bug dans le nouveau système, nous avons réalisé que ce n'était pas le cas en s’interrogeant sur l’adoption de ce nouveau système. Nous n’avions aucun moyen de la mesurer. Après avoir analysé l’activité, nous avons constaté qu’elle était très faible. En y réfléchissant, il n’est pas surprenant qu'après trois décennies de routines, les utilisateurs rencontraient des difficultés à adopter cette nouvelle solution qui ne proposait pas encore l’exhaustivité des fonctionnalités. Cette difficulté était en plus amplifiée par le fait qu’ils pouvaient effectuer l’ensemble des opérations sur le mainframe, mais seulement une partie sur la nouvelle interface utilisateur.
Lors de la refonte d’un système, l’adoption reste un défi majeur. Il faut prévoir un réel plan d’accompagnement. Il est crucial que les sponsors et toutes les personnes influentes du projet s’impliquent activement pour promouvoir et évangéliser la nouvelle solution le plus tôt possible.
Investir dans le monitoring et l’alerting plus tôt
Nous nous sommes retrouvés, en particulier au début du projet, dans une situation délicate où, en cas d’erreurs en production, nous étions informés par les équipes de support, elles-mêmes prévenues par les utilisateurs. Cela aurait pû entrainer une perte de confiance et mettre en danger l’adoption du système.
L’autre impact d’un monitoring pas suffisamment robuste est la création d’écarts difficilement identifiables dans l’outil de comparaison : le système, censé écrire sur les deux systèmes en parallèle, peut n’écrire que sur un seul, compliquant ainsi les analyses de comparaison. Nous ne savions pas si les écarts observés étaient dus à un bug ou à une erreur 500 sur cette branche.
De plus, nous étions submergés par de fausses alertes en raison d'un système d'alerting mal configuré, ce qui nous faisait manquer les véritables problèmes. Par conséquent, un travail de nettoyage a été entrepris.
Ne rien oublier pour pouvoir décommissionner l’ancien système
Comme évoqué ci-dessus, nous avions cartographié l’ensemble des besoins et des applications pour ne pas oublier l’application utilisée par 0,8% des utilisateurs mais obligatoire pour décommissionner le mainframe…
Il est également crucial de cartographier avec précision tous les flux interconnectés avec le mainframe pour éviter qu’un partenaire ne vous informe quelques jours ou semaines plus tard qu’il ne reçoit plus de fichiers…
L'une des clés essentielles est de disposer des points de contact fonctionnels et techniques des partenaires pour valider avec eux que le nouveau système est identique à l’ancien de bout en bout, aussi de leur point de vue. Nous avions réalisé une cartographie de ces personnes clés.
Anticiper l'inattendu
Les imprévus surviendront toujours, qu'il s'agisse de changements réglementaires, de demandes qu’il faut honorer ou encore de migration d'infrastructure. De notre côté, nous avons dû réaliser une migration vers un nouveau cloud en parallèle qui n’était pas prévu initialement. Il est donc crucial d’adapter la roadmap (feuille de route), les jalons et les dispositifs en place pour y faire face de la meilleure façon possible. Il est également important d'explorer les possibilités d’avoir du budget supplémentaire pour adresser les travaux qui n’étaient pas initialement prévus.
Conclusion
La transition d’un mainframe complexe à un SI urbanisé et déployé sur le Cloud constitue une transformation technologique ambitieuse et essentielle pour pouvoir répondre aux besoins évolutifs et aux attentes fortes des utilisateurs. Avec la mise en place d’un PoC pour dérisquer les sujets les plus épineux et d’un double run, nous avons pu, dès les premiers mois, créer la confiance en garantissant au fil de l’eau le bon fonctionnement des fonctionnalités développées.
Le succès de cette transition repose sur plusieurs piliers fondamentaux : une priorisation rigoureuse par le risque, un focus constant sur l’objectif de décommissionnement, une stratégie robuste de migration de données et une approche itérative de Test & Learn.Ces éléments ont permis de gérer efficacement les complexités du projet tout en minimisant les impacts sur les utilisateurs.
Cette expérience souligne également l'importance d'un accompagnement au changement bien orchestré et d'une communication claire pour favoriser l'adoption de la nouvelle solution. Elle rappelle aussi l'importance de disposer d'outils de monitoring et de mesure de l'activité pour anticiper et réagir rapidement aux imprévus et ne pas perdre leur confiance.
En conclusion, cette transformation est bien plus qu'une simple mise à jour technologique : elle marque une étape clé vers un système plus agile, capable de s'adapter aux besoins futurs et de continuer à offrir une expérience utilisateur optimisée, tout en minimisant les coûts et les risques associés.