Smart Building : créer des conditions d'interopérabilité avec le framework Haystack
Dans notre précédent article sur le Smart Building, nous avions introduit les principaux enjeux de l’immobilier d’entreprise, en se concentrant sur la qualité de vie au travail. Nous y avons décrit des cas d’usages à partir de l’IoT, qui contribuent directement au confort et à la sécurité des usagers d’un Smart Building. Abordons à présent l’enjeu de la collecte de données du terrain. Celui-ci peut constituer un axe prioritaire pour les entreprises qui cherchent à exploiter les données pour en tirer des bénéfices, comme la réduction de leurs coûts d’exploitation ainsi que de la consommation énergétique de leurs bâtiments.
Découvrez sans plus attendre, à travers le contexte d’une entreprise, les solutions proposées en matière de choix technologique et de méthodes d’implémentation.
Un contexte qui ne facilite pas la collecte de données
L’entreprise possède un parc immobilier important en France et chaque site dispose d’un réseau d’équipements CVC (chauffage, ventilation, climatisation). Ces équipements assurent aux usagers de bonnes conditions de confort, d’hygiène et de sécurité au sein des bâtiments, et cela dans les divers espaces mis à disposition (couloirs, ateliers, bureaux, magasins, ...). Le réseau d’équipements CVC contient des capteurs relevant des données du terrain et d’actionneurs agissant sur ces équipements. Mais ces équipements proviennent de différents fournisseurs, et les capteurs communiquent les informations via des protocoles divers et variés.
Ces données sont exploitées par les BMS (Building Management System) de chaque site. Ces logiciels permettent de réguler les équipements ainsi que de suivre en temps réel leur état à l’aide d’indicateurs et d’alertes. Les BMS manipulent souvent les mêmes concepts pour le domaine CVC : pays ; ville ; site ; étage ; espace ; équipement ; capteur. Cependant, il peut y avoir des concepts et des données spécifiques à chaque BMS et par conséquent, ces derniers sont instanciés avec des modèles de données hétérogènes.
Pour réduire les coûts d’exploitation du CVC, l’entreprise veut mettre en place une plateforme digitale de maintenance prédictive qui sera dédiée à l’ensemble des sites. Celle-ci aura pour vocation de prédire l’usure des équipements et donc les anomalies associées. Ces prédictions seront remontées sous forme d’alertes vers les BMS concernés. Pour ce faire, la plateforme devra se connecter à chaque BMS pour récupérer les données du terrain.
Illustration de l'architecture applicative :
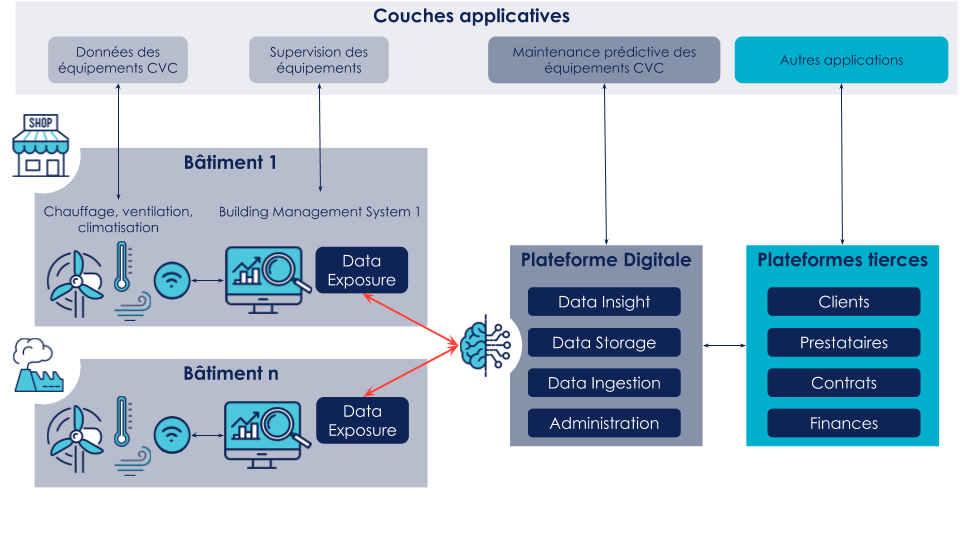
Dans ce contexte, un premier obstacle à l’implémentation se dessine :
Comment simplifier la collecte, par la Plateforme Digitale, de données hétérogènes provenant de BMS différents et potentiellement directement depuis les équipements ou capteurs ?
Cet obstacle se décline en deux problématiques :
- La première est d’ordre syntaxique. En effet, chaque BMS utilise son propre modèle de communication. Il utilise sa propre grammaire et agence les informations selon ses propres règles. Ce modèle de communication peut être facile d’accès (par exemple à l’aide d’API de type REST sur HTTPS, bénéficiant d’une description précise) ou au contraire plus difficile d’accès (par exemple en nécessitant un accès direct à une base de données non documentée). Dans tous les cas, dans la plateforme digitale, il faut adapter au cas par cas les connecteurs destinés à collecter les données générées par les différents BMS ou tout autre équipement (par exemple, l’API exposée par les BMS tels que Siemens Desigo ou Johnson Controls Metasys, ou plus généralement des protocoles de communication de type Modbus, BacNet ou encore OPC-UA).
- La seconde est d’ordre sémantique. En effet, les BMS et les équipements communicants traduisent le monde physique en un monde numérique. Toutefois, pour un même objet ou une même dimension physique, des noms ou mots différents peuvent être transmis par les BMS et les équipements. Par exemple, les BMS peuvent traduire à l’aide de différents mots le même concept d’étage (un premier le traduit par “étage”, un autre l’appelle “niveau” et encore un autre, “floor”). Autre aspect, les BMS et les équipements sont amenés à fournir des valeurs (par exemple une température), mais potentiellement sous différentes unités (par exemple en °C ou en °F), et cela sans obligatoirement les préciser.
L’élaboration d’une définition formelle du domaine CVC
Pour pouvoir solutionner la situation, l’entreprise qui souhaite exploiter les données provenant du monde physique doit s’appuyer sur une représentation partagée et consensuelle entre ses différents gestionnaires. Cette représentation peut prendre la forme d’une “Digital Twin” sur laquelle peut venir s’appuyer la plateforme digitale (mais aussi les différentes solutions logicielles en lien avec le bâtiment).
Pour construire cette représentation, nous déconseillons l'élaboration d’un modèle de données générique, pensée indépendamment des équipements de terrain. En effet, chaque bâtiment dispose de ses spécificités et de ses propres équipements. Et chaque domaine d’activité (climatisation, éclairage, sécurité, conciergerie …) utilise son propre vocabulaire et ses notions métier. Pour faciliter la modélisation du bâtiment (et de ses équipements) et favoriser l’adoption de ce modèle par le plus grand nombre, nous conseillons l’élaboration d’une définition formelle du domaine CVC, en utilisant Haystack. Celle-ci sera plus à même d’apporter toute la souplesse nécessaire à un contexte en forte évolution. Une fois le domaine spécifié, l’entreprise sera à même de faire le choix technologique et le modèle d’implémentation associé.
Remarque : il existe différentes alternatives au projet Haystack. Par exemple, Industry Foundation Classes (IFC), qui est un standard ISO (ISO 16739-1:2018), mais qui se focalise à la dimension “vocabulaire” des échanges et qui ne favorise pas la modification du modèle de données initial. Ou encore Brick, qui est un schéma de métadonnées uniforme pour les bâtiments, mais qui, à ce jour, est principalement adoptée par l’entreprise Johnson Controls.
Brève introduction à Haystack
La quête d’une plus grande interopérabilité entre les systèmes, ce qui est l’un des piliers des plateformes digitales, incite les différents acteurs d’un domaine (opérateurs, fournisseurs, intégrateurs, …) à se réunir pour définir les conditions d’interopérabilité. Le domaine industriel s’est lancé dans cette démarche, et plus particulièrement les experts qui œuvrent sur les équipements déployés dans les bâtiments. Il y a déjà 9 ans de cela, le fruit de leur travail a donné vie au projet Haystack.

Le projet Haystack est une initiative open source visant à rationaliser le travail avec les données de l'IoT (Internet of Things). Lancé en 2011, il est administré par des acteurs industriels tels que J2 Innovations, SkyFoundry, mais aussi Legrand, Siemens ou encore Intel. Leur travail consiste à décrire les données collectées par les différentes solutions matérielles et logicielles déployées dans les bâtiments. En cela, ils développent des conventions de taggage et des modèles de données sémantiques, dans le but de faciliter l'extraction de la valeur de la vaste quantité de données générées par les dispositifs intelligents. Ainsi la communauté Haystack, issue majoritairement de la gestion des bâtiments, s’est focalisée sur la gestion de l'automatisation, du contrôle, de l'énergie, du chauffage, de la ventilation, de la climatisation, de l'éclairage et d'autres systèmes environnementaux.
Les composants de Haystack
Haystack dispose d’une panoplie de composants, qui permet de créer les conditions d’interopérabilité :
1. Une convention de taggage : Haystack propose en premier lieu une librairie de tags. Les tags sont utilisés pour structurer les données des équipements en fonction de la réalité du monde physique. Vous trouverez la liste des tags ainsi que leur définition sur le site de Haystack. Un premier avantage est la simplification de la définition formelle du domaine CVC. En effet, l’entreprise peut s’appuyer sur la convention existante, sans quoi l’exercice peut être long et fastidieux. Le deuxième avantage est qu’une convention assure la cohérence de la terminologie des tags utilisés. Enfin, une convention est d’autant plus importante puisque les tags ne remplacent pas les données traitées. Ils sont en quelque sorte les données des données, ou “Meta data”. Ainsi, les BMS n’ont nul besoin d’adapter leurs modèles de données déjà en place.
2. Un modèle de tags : la structure principale du modèle Haystack est basée sur une hiérarchie de trois entités :
[site] : immeuble unique avec sa propre adresse
[equip] : équipement physique ou logique au sein d'un site
[point] : capteur, actionneur ou valeur de consigne pour un équipement
À l'intérieur de ces trois entités, les tags de différente nature sont utilisés pour décrire le domaine, ce qui permet d’obtenir un modèle standardisé que chaque BMS adoptera. Voici un exemple de structure des tags provenant du site Haystack (source : https://project-haystack.org/doc/Structure) :
Prenons un exemple concret où Haystack structure et donne du sens. L’accès à des registres de données non structurées est une situation fréquente que tout développeur rencontre et souhaiterait éviter :
“En tant que développeur d'une plateforme digitale, j'ai accès au registre "sn4-zqgf4e" exposé par un BMS, la valeur obtenue est 25,1. Voici les questions que je me pose et qu'à ce jour, seul le gestionnaire en charge du BMS saurait me répondre." Mais avec Haystack, il en est tout autre chose :
| Développeur | Gestionnair__e__ | __Tags associés à la vale__ur |
|---|---|---|
| Quelle est la temporalité de cette valeur ? | C’est la valeur actuelle (temps réel). | curVal |
| A quel point de mesure cette valeur correspond-t-elle ? | C'est une information transmise par un capteur de température. | id: @tempsensor1dis: ”capteur de température-1” point sensor |
| Quelle est l'unité de mesure utilisée pour ce point (°C ou en °F) ? | C'est une température en °C. | kind: “Number”unit: “C° |
| Quelle est la mesure réalisée (température ambiante, de sortie, ...) ? | C'est la température de l'air en sortie. | discharge air temp |
| Par quel composant est-elle fournie ? | Elle est transmise par le ventilateur de soufflage. | equipRef: @ventilateur_de_soufflage |
| Se composant appartient à quel équipement ? | À la centrale de traitement d’air “cta1”. | hvac |
| Dans quel secteur du bâtiment cette boite est-elle localisée ? | Au premier étage, secteur 3. | siteLevel: “Etage 1” spaceRef: @secteur3 |
Au-delà de la maîtrise d’information, l’entreprise peut se passer du mapping manuel interminable en utilisant des applications qui leur simplifie l’exercice. Des templates sont conçus pour appliquer automatiquement des tags aux données. Ces derniers peuvent aussi bien générer un certain nombre d’outils sans avoir à effectuer une configuration manuelle (graphiques, tableaux, statistiques, alertes, …).
3. Solution open-source : pour traiter ces différents aspects, Haystack reste souple quant à son implémentation. L’entreprise peut y trouver un gain économique car elle est libre d’exploiter toutes les ressources offertes par Haystack sans le moindre coût ni obligation. Le développeur peut ainsi télécharger le code source et enrichir la structure de tags en fonction des besoins de l’entreprise, qui adoptera le mode de gouvernance correspondant le mieux à son contexte. C’est le cas de GE Current, spécialisée dans l’éclairage intelligent, qui s’appuie sur la structure suivante :
Source : https://developer.gecurrent.com/intelligent-enterprises-api/#entities
Voici un autre exemple de structure sous forme de graph interactif, proposé par Patrick Coffey, Chief Technology Officer de WideSky, éditeur de solution EMS (Energy Management System).
4. Le format de données : pour échanger les données, l’entreprise peut utiliser le format GRID représenté sous-forme de tableaux pour faciliter la lecture et l’interprétation des données. L’entreprise peut aussi faire le choix entre le format ZINC, spécialement conçu pour optimiser la consommation de bande passante, utile dans le traitement d’un grand volume de données issus des équipements de l’IoT. Un autre format, JSON, est une bonne alternative car il est largement utilisé par les développeurs et adapté aux échanges entre applications.
5. Haystack API : l’interopérabilité avec Haystack est atteinte par l’utilisation de son web service. Une fois le domaine formellement défini, Haystack permet l’échange des données taguées entre deux solutions matérielles ou logicielles à l’aide de l’API standardisée. Les solutions devront cependant implémenter le web service dans leurs systèmes, être autorisées et s’authentifier pour pouvoir consommer les données.
6. Un langage de requête : Haystack dispose aussi de son propre langage de requête nommé “Filters”, qui simplifie l’accès aux données. Par exemple, si un utilisateur souhaite obtenir la liste de tous les points de mesure sur l’ensemble des équipements, il réalise une requête GET via l’API Haystack : http://host/haystack/read?filter=point. L’API lui renvoie la liste sous un format ZINC ou JSON :
| ver:"3.0" | |||||||||
| id | dis | point | his | kind | unit | tz | temp | sensor | power |
| @temp | "Temp Sensor" | M | M | "Number" | "°F" | "New_York" | M | M | |
| @kw | "Demand" | M | M | "Number" | "kW" | "New_York" | M | N |
Grâce à ces composants, Haystack permet à l’entreprise de s’appuyer sur une architecture de données dite émergente pour offrir toute l’agilité nécessaire à une discipline aussi innovante et dynamique que le Smart Building. Qu’en est-il de la gestion des besoins qui ne seraient pas couvert par les tags Haystack ?
Un choix de gouvernance à faire
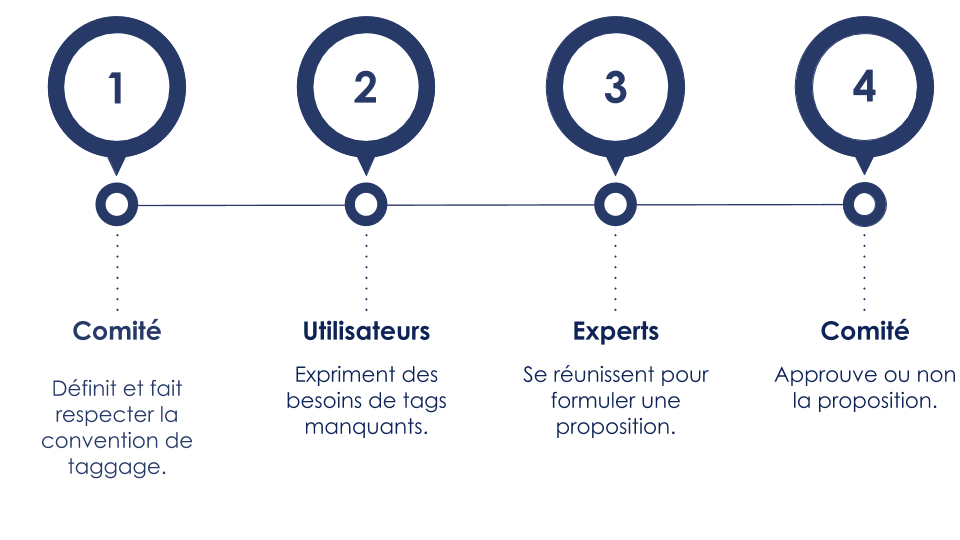
Haystack est organisé selon une gouvernance participative. Il rassemble une communauté d’utilisateurs qui contribuent au développement de la convention de taggage. Tout individu peut disposer d’un compte “user” pour accéder au forum de discussions et poser des questions à la communauté des “members”. Ce statut est soumis à la validation du comité décisionnel. Les membres ont pour fonction de former des groupes de travail pour instruire des demandes d’évolution de la convention de taggage. Si suffisamment de membres y participent, la proposition est soumise au comité décisionnel de Haystack qui valide, ou non, la proposition.
Si l’entreprise peut s’affranchir des éventuelles contraintes organisationnelles de Haystack, elle doit tout de même faire un choix en matière de gouvernance :
- Dans un contexte où le périmètre d’intervention est réduit et maîtrisé, le mode de gouvernance en “top-down” est à privilégier. En effet, la définition formelle du domaine par une instance, et l’intégration du domaine par un petit groupe d’acteurs abouti à une implémentation plus rapide :
- Si la situation implique un plus grand nombre d’acteurs dans un périmètre difficilement maîtrisable, il vaut mieux adopter un mode de gouvernance en “bottom-up”. Pour y parvenir, les experts de chaque domaine (climatisation, chauffage, éclairage …) seront plus à même de définir les tags et leurs relations de la manière la plus pertinente qui soit. Une certaine flexibilité est à envisager pour éviter des ralentissements dans la validation et l’implémentation de nouveaux tags si l’occasion se présente :

Remarque : Dans une approche “bottom-up”, lorsque le référentiel de tags est centralisé, il est possible d’identifier les tags ayant une syntaxe différente (candélabre, lampadaire …) pour une sémantique identique (dispositif d’éclairage pour la voie de circulation). En effet, il est possible d’identifier, pour un point physique, le nom de tag le plus pertinent, par exemple à l’aide d’une analyse statistique des tags employés par les différentes entités utilisatrices et éventuellement un travail de rapprochement de ces différents noms de tag. En faisant émerger un nom de tag unique pour chaque point, il devient possible de le promouvoir à destination de toutes les entités. Cela afin de viser une cohérence dans l’utilisation des tags et ainsi optimiser le partage et donc la valorisation des données collectées. Par exemple, les données collectées initialement pour la seule maintenance prédictive, peuvent potentiellement être utilisées par le service de conciergerie du bâtiment.
Haystack n’a pas dit son dernier mot
Pour conclure, l'entreprise fait face à des choix technologiques et méthodologiques pour pouvoir créer des conditions interopérabilité entre les BMS et la nouvelle plateforme de maintenance prédictive. En fonction de son contexte et de sa stratégie de déploiement, l’utilisation de Haystack comporte bien des avantages. Haystack a acquis une certaine notoriété et est de plus en plus populaire comme système de taggage des points et autres équipements d'un bâtiment. Sa richesse réside dans la capacité à remplacer des libellés informels par des tags semi-structurés. Toutefois, cette approche semi-structurée présente quelques limitations lorsque qu'une entreprise veut disposer d'un modèle de relations plus formel entre les entités (équipement, bâtiments, mais aussi contrats, intervenants ...).
De fait, dans sa future version (Haystack 4.0), Haystack embrasse une nouvelle dimension. En effet, elle ne lui manque plus qu’un moteur d’inférence pour devenir une ontologie. Ce concept apporte encore plus de solutions aux problématiques de collecte et d’analyse de données non structurées. Ainsi, Haystack disposerait de toutes les qualités pour devenir la référence sur le marché en matière de solution d’interopérabilisation dans les contextes variés du Smart Building. Mais que peut bien être une ontologie ? Quels bénéfices supplémentaires par rapport à ce que Haystack propose déjà ? Affaire à suivre dans un prochain article !