SLO : exploitez la puissance des métriques pour fiabiliser vos systèmes
Lorsque l’on exploite un produit ou que l’on monte une infrastructure, il est normal de se poser la question “Est-ce que mon application fonctionne bien ?”
En général, il est commun d’avoir deux réponses dans ce genre de cas :
- Mettre en place du monitoring illustrant le fonctionnement de mon application
- Mettre en place un système d’alerting pour être prévenu en cas de dysfonctionnement
Cependant, rares sont les fois où l'on va se demander si les alertes positionnées sont pertinentes dans mon contexte (ex : redémarrage d’un conteneur) ou si les métriques remontées par mon dashboard préfabriqué me remontent les informations qui me seront vraiment utiles pour identifier un dysfonctionnement.
Cet article a pour vocation de vous présenter la façon dont les Site Reliability Engineers ou SRE (terme défini dans la série de livres de Google Site Reliability Engineering) approchent les métriques de leurs applications. On y verra comment ils positionnent des objectifs factuels sur celles-ci afin de déterminer si l’application présente réellement la qualité de service attendue et comment ils font pour aller plus loin que la simple visualisation de celle-ci.
Ces principes seront ensuite mis en lumière en vous présentant Keptn, une solution assez jeune sur le marché, mais qui illustre bien certaines des possibilités ouvertes par cette façon de faire.
SLI,SLO,SLA… SLQuoi ?
Les premières questions que l’on va se poser seront bien souvent : Par où commencer ? Quels sont les symptômes d’un dysfonctionnement de mon application ? Comment identifier que mon application fonctionne correctement ?
L’approche des SRE explique qu’il est impossible de gérer un service correctement sans comprendre les comportements qui importent pour le service. Cela passe par une capacité à les mesurer et les évaluer. Et c’est ce qui nous permettra, à la fin, de délivrer un niveau de qualité qui répond aux attentes des utilisateurs finaux. Pour ce faire, ils définissent 3 concepts :
Les Service Level Indicators (SLI) sont tout simplement des métriques qui peuvent être suivies. Celles-ci peuvent être applicatives, venir de l’infrastructure ou de sources externes. L’important est de choisir des indicateurs qui correspondent à l’état de santé de l’application.
Un exemple que l’on pourrait donner est le temps de réponse. Celui-ci impacte l’expérience utilisateur d’un site et peut rendre celle-ci intenable si trop longue.
Les Service Level Objectives (SLOs) correspondent à un objectif sur le niveau d’admissibilité d’une application en fonction de SLI spécifiques. Ils n’ont aucune valeur contractuelle et vont permettre de définir une qualité de service attendue en interne (et qui ne sera pas exposée aux utilisateurs finaux).
En reprenant l’exemple précédent, un SLO lié au temps de réponse de ma page serait un temps de réponse inférieur à 2 secondes 90% du temps.
Le SLO est la clé de voûte de la gestion du changement chez les SRE de Google. Un dépassement de celui-ci serait considéré comme un incident et des actions de remédiation sur le long terme seraient mises en place pour y remédier.
Pour ce faire, on retrouve la notion d’Error Budget qui va permettre de définir un niveau de “souplesse à l’erreur” afin de permettre de financer des opérations non liées à l’équipe produit. En suivant toujours l’exemple précédent, si mon objectif est d’avoir moins de 2 secondes de temps de latence 90% du temps, mon error budget correspondra au 10% du temps restant.Il est donc important de surveiller également sa consommation (Burn Rate) car cela va entraîner la mise en place d’action s’il diminue trop rapidement.
Enfin le Service Level Agreement (SLAs) qui correspond à un niveau d’attente contractuelle avec l’utilisateur final. Ceux-ci sont assez présents aujourd’hui notamment avec l'essor des services managés proposés par les clouds providers.
En général, le SLA est une représentation contractuelle du SLO (mon service doit être disponible n% du temps sinon je suis soumis à des pénalités). Cependant, au vu de sa valeur contractuelle et du caractère “d’objectif” porté par le SLO, il est recommandé de mettre un SLA plus bas que le SLO.
Définir ses priorités
Pour définir correctement les SLI propres à une application, il est important de se demander ce qui est important pour soi et les utilisateurs qui vont consommer le service. On va ainsi se poser des questions comme : Est-ce que mon service est capable de répondre aux requêtes ? Combien de temps met-il à répondre ? Est-ce qu’il répond correctement ?
Pour un système de stockage, on va plus se poser des questions sur : Est-ce que mon système est capable de tenir suffisamment la charge de lecture et d’écriture ? Est-ce qu’il est accessible à la demande ?
Autour de la gestion des données, on va pouvoir s’objectiver autour de la fraîcheur (freshness) de la donnée, le pourcentage du jeu de donnée qui est couvert par les pipelines ou de leur degré de validité par exemple.
De ces questions vont découler des métriques spécifiques qui vont nous servir d’indicateur que l’on va suivre pour vérifier si l’application fonctionne correctement. Ces métriques sont souvent centralisées dans un document qui est construit avec l’équipe et validé par le PO.
L’art de récupérer ses métriques
Une fois les indicateurs identifiés, on va vouloir les récupérer. Pour ce faire, il existe plusieurs stratégies :
- Intégrer au sein de l’application avec des bibliothèques dédiées comme les clients applicatifs Prometheus qui permettent d’exposer des métriques métier personnalisées au format OpenMetric
- Utiliser un agent directement au sein des services/applications afin de récupérer les logs, les métriques, le contexte ou les traces. Cette approche est aujourd’hui majoritairement utilisée par des solutions tels que Dynatrace, Datadog ou Sentry par exemple
- Récupérer les métriques d’utilisation à l'aide d'une brique positionnée en proxy devant l’application. C’est quelque chose que l’on retrouve avec des outils comme les services mesh (ex : Istio) ou les solutions d’API Management (ex : plugin Kong)
- Utiliser les informations exposées par l’infrastructure ou les services managés
- Compter les logs applicatifs avec une surcouche sur ElasticSearch
Ces informations sont ensuite généralement stockées dans une Time Series Database (TSDB) comme Prometheus (puis exposé via un Grafana) ou via des solutions all-in de grands acteurs du marché comme Dynatrace, Datadog, AppDynamics ou Splunk par exemple.
Définir la normalité
Une fois les métriques récupérées, on va pouvoir y ajouter ce qui fait la magie de l’observabilité : la transformation de la métrique brute en une métrique exploitable qui va nous servir de SLO. Pour ce faire, on va rajouter des paliers (threshold) pour un groupe de la métrique afin de présenter les zones de danger à ne pas dépasser. Ces paliers sont orientés métier et correspondent au niveau de qualité attendue par les utilisateurs. Ils doivent donc être définis en collaboration avec les products owners pour avoir des indices au plus près des attentes clients.
ex : 99% des appels sur 1 minute mettent moins de 100ms.
Quelques bonnes pratiques pour le choix des SLO (venues tout droit du livre Site Reliability Engineering) :
- Pensez aux objectifs comme ce qu'ils devraient être et pas comme ce qu’ils sont actuellement
- Garder les SLO simples (1 SLO pour 1 SLI)
- En avoir le moins possible
- Prendre en compte le fait que le système ne peut pas “scaler” indéfiniment (même sur le cloud)
- Y aller progressivement sur les paliers (on peut monter les exigences au fur et à mesure)
Maintenant que nous avons introduit la notion de SLO, voyons comment nous pouvons l’exploiter.
Comportements et réactions autour du SLO
L’usage le plus classique autour des SLO et les SLI associés est la mise en valeur des indicateurs à l’aide d’un système d’alerting. Quand la métrique associée va dépasser un palier spécifique défini par une de ces règles, une alerte va être levée et va envoyer un mail, une notification sur un Slack/pager…

Un outil qui va rappeler pas mal de souvenirs à ceux qui l’ont eu entre leurs mains
Une fois l’alerte levée, un opérateur va prendre en main le problème avec les étapes de recherche et la mise en place d’une solution pour remédier le plus rapidement possible au problème.
Jusqu’ici, rien de bien différent d’habitude. Cependant, sortons de notre zone de confort et allons dans des contrées encore peu connues.
Aller plus loin : faire mieux pour moins d’effort
Revenons au Site Reliability Engineering. Dans celui-ci, on apprend que les ingénieurs de Google ont pour motto de réduire au maximum le nombre d’actions manuelles effectuées sur le système. Pour ce faire, ils vont chercher à tendre au maximum vers l’autonomisation (cad: faire en sorte que l’application soit capable de tourner seule et de gérer son propre processus de réparation sans action manuelle de l’opérateur) des applications afin de permettre :
- une réduction du nombre d’opérations manuelles sur le système (et du temps consacré à celui-ci)
- une focalisation maximum sur le développement de logiciels permettant de faciliter le run
Ainsi, un des usages que l’on va pouvoir imaginer est l’automatisation des processus de réparation de la plateforme (dans la mesure du possible bien entendu) aussi appelés auto remédiation. Prenons le cas nominal :
Un SLO est dépassé suite à un événement. Cela va déclencher une alerte qui va prévenir un opérateur qu’il y a un problème. Une fois analysée, l’équipe va prendre en charge le problème.
Pour aller plus loin, pourquoi ne pas rajouter une étape qui va analyser l’alerte et identifier les procédures de réparation en fonction de celle-ci ? Si une procédure n’est pas connue, un ingénieur est prévenu et peut prendre en main la mise en place de la procédure automatique après remédiation.
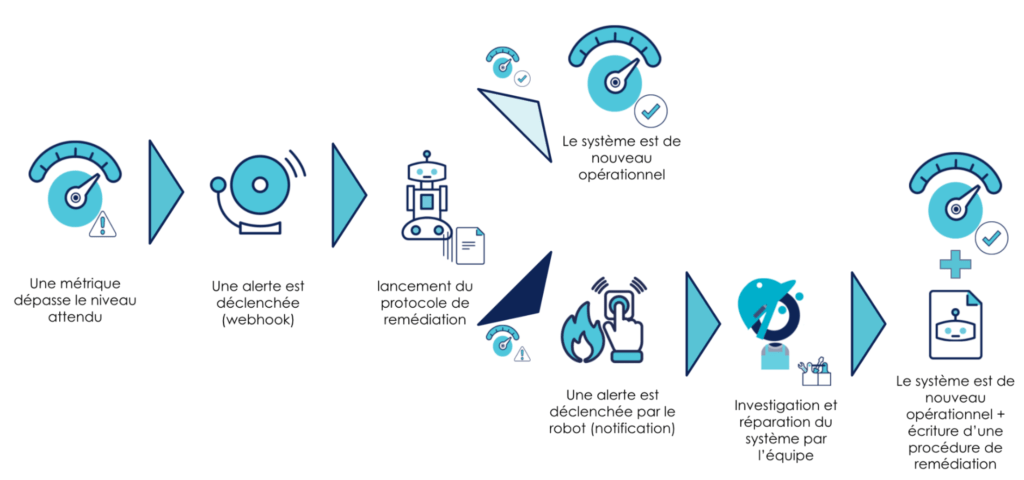
On la retrouve généralement à petite échelle en général très lié à l’infrastructure :
- via des règles d'auto scaling en fonction de la consommation de ressource
- à travers les mécanismes de probes (health/readiness checks) et leurs effets respectifs sur le système
Avec l’ajout de métriques métiers, l’étude des SLO dans leur globalité nous ouvre de nouvelles possibilités.
Ce pattern, qui utilise un alerting venant d’une solution externe (Alertmanager…) est l’un des trois patterns d'auto remédiation (avec le pattern opérateur et la détection interne). Les deux autres seront trouvables dans de futurs articles et ne seront pas décrits dans cet article.
Un autre usage qui est beaucoup plus atypique est l’utilisation des SLO comme des quality/performance gates supplémentaires sur les pipelines CI/CD. Ainsi, en plus des traditionnels tests d’intégration, de performance ou autre, on va également être capable d’analyser automatiquement les comportements qui ont été provoqués par l’exécution de ces tests sur le système. Cela nous permettra d’identifier si, lors d’une stimulation, l’application répond aux bonnes conditions de fonctionnement définies.
Cet usage existe lui aussi, cependant, il va souvent dépendre d’une interprétation de la personne qui lance le test ainsi que d’une action manuelle pour faire avancer le pipeline si tout est OK.
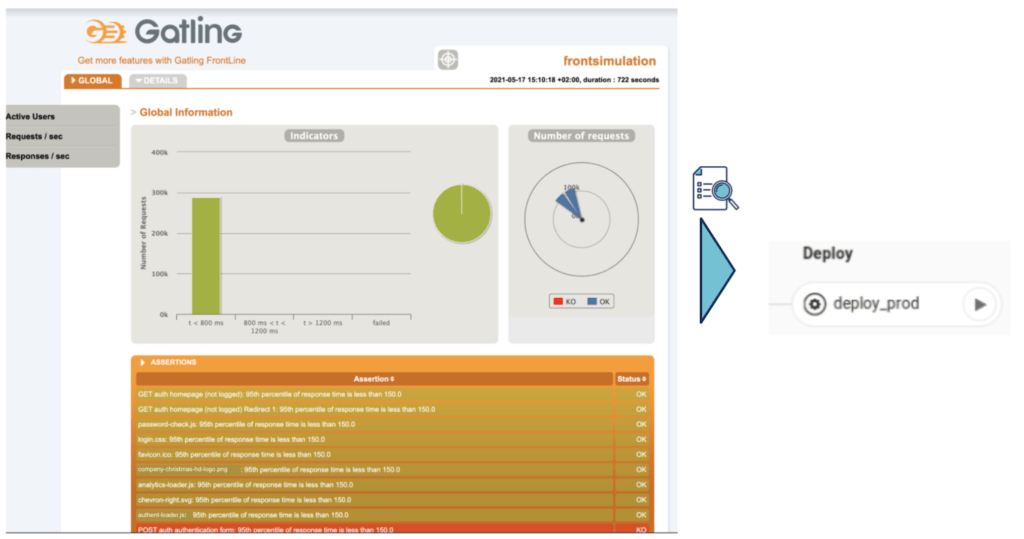
Pourquoi ne pas automatiser cette interprétation ? Après tout, l’environnement sur lequel le test est joué dispose également d’une solution permettant de surveiller les métriques. Il doit donc être capable de faire le lien entre le test et les métriques surveillées si celles-ci sont importantes pour nous. En analysant ces métriques de manière automatique, il devient possible d’automatiser ce blocage.
Coup de projecteur : Keptn

Pour illustrer ces concepts, j’aimerais vous présenter Keptn. Un outil qui a été initialement développé par les équipes de Dynatrace et qui est maintenant un projet open-source au sein de la CNCF. Il qui se définit comme :
- un moyen de mettre en lumière des SLOs et les SLIs
- un outil d’orchestration basé sur les SLOs
- un moyen de gérer le lancement de procédure d'auto remédiation et de valider le bon fonctionnement de celle-ci
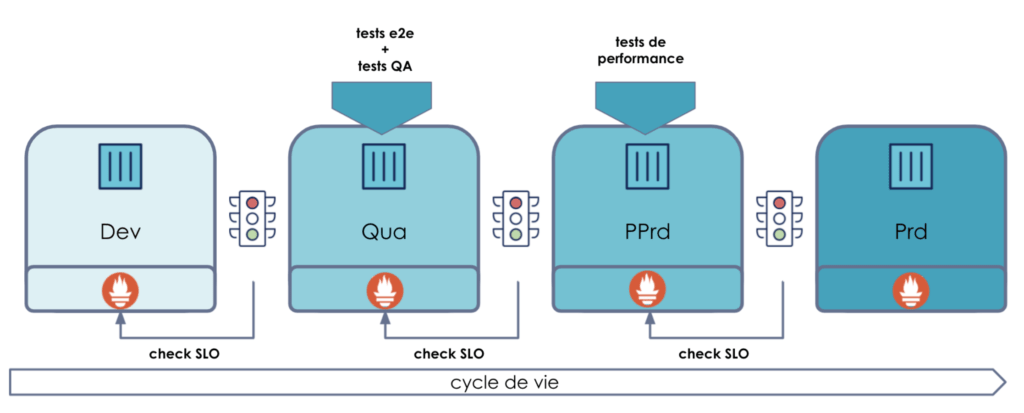
Celui-ci se déploie sur un cluster Kubernetes et va s’interfacer avec différents composants du SI comme les outils de monitoring, de performances etc...
L’objectif de cet outil est d’accompagner les applications durant toutes les étapes de leur cycle de vie. Que ce soit pendant la phase de développement/promotion ou durant la phase de run, il va exploiter les métriques de l’application pour mettre en place des “SLO-based quality gates” (que je raccourcirai dans cette article en “SLO Gate”) sur les environnements afin de gérer les promotions ou de l’auto remédiation sur les environnements finaux.
Il est possible de n'employer que la partie auto remédiation mais ce serait dommage de ne pas utiliser l’intégralité du potentiel de cet outil.
Faisons maintenant une visite pour illustrer le fonctionnement de cet outil. Si vous désirez manipuler l’outil, vous trouverez plusieurs tutoriels ici. (Le tutoriel utilisé pour le test présenté dans cet article se trouve ici)
Illustration par la pratique : SLO Gates
Pour cette expérience, nous avons utilisé un cluster GKE avec le service mesh Istio et Prometheus installé dessus (Keptn supporte plusieurs providers et dans cet exemple, nous allons utiliser Prometheus pour la récupération des SLIs).
L’idée ici va être de déployer en blue-green une application sur deux environnements (hardening et prod) et de la faire évoluer pour montrer le fonctionnement de la SLO Gate.
La première chose à faire est de déclarer une application dans Keptn afin qu’il puisse établir le workflow de déploiement ainsi que les différentes étapes associées à la validation. Comme la plupart des outils modernes, il s’agit ici d’une déclaration sous forme de code (le yaml en est aussi oui oui !).
Le fichier à la forme suivante :
---
apiVersion: "spec.keptn.sh/0.2.0"
kind: "Shipyard"
metadata:
name: "shipyard-sockshop"
spec:
stages:
- name: "hardening" #<- l’environnement
sequences: #<- les étapes
- name: "delivery"
tasks:
- name: "deployment" #<- la stratégie de déploiement
properties:
deploymentstrategy: "blue_green_service"
- name: "test" #<- les tests à lancer
properties:
teststrategy: "performance"
- name: "evaluation" #<- l’évaluation du SLO
- name: "release" #<- la promotion sur l’environnement
- name: "production"
sequences:
- name: "delivery"
triggeredOn:
- event: "hardening.delivery.finished" #<- la condition de promotion
tasks:
- name: "deployment"
properties:
deploymentstrategy: "blue_green_service"
- name: "release"
Ce qu’il faut savoir, c’est que quand Keptn est attaché à un projet, il crée un pseudo Gitflow dans le dépôt Git qui va comprendre les branches associées à nos environnements.

Dans chacune de ces branches, on va pouvoir y retrouver nos tests et nos quality gates (SLOs) et les SLIs associés à chaque environnement.
Une fois nos environnements déclarés pour notre service, nous allons lancer un premier pipeline CD sans tests.
Point assez intéressant, lors de l’expérimentation, on constate que les environnements ne nécessitent qu’un seul cluster car ils utilisent la séparation logique présente dans les namespaces kubernetes. Cependant, Keptn offre également la possibilité de faire du support multi-cluster.
podtato-head/delivery/keptn main
> kubectl get ns | grep pod-tato
pod-tato-head-hardening Active 40m
pod-tato-head-production Active 39m
Une fois déployé, on va voir que la plateforme va run l’ensemble des tasks dans l’ordre pour arriver à un résultat.
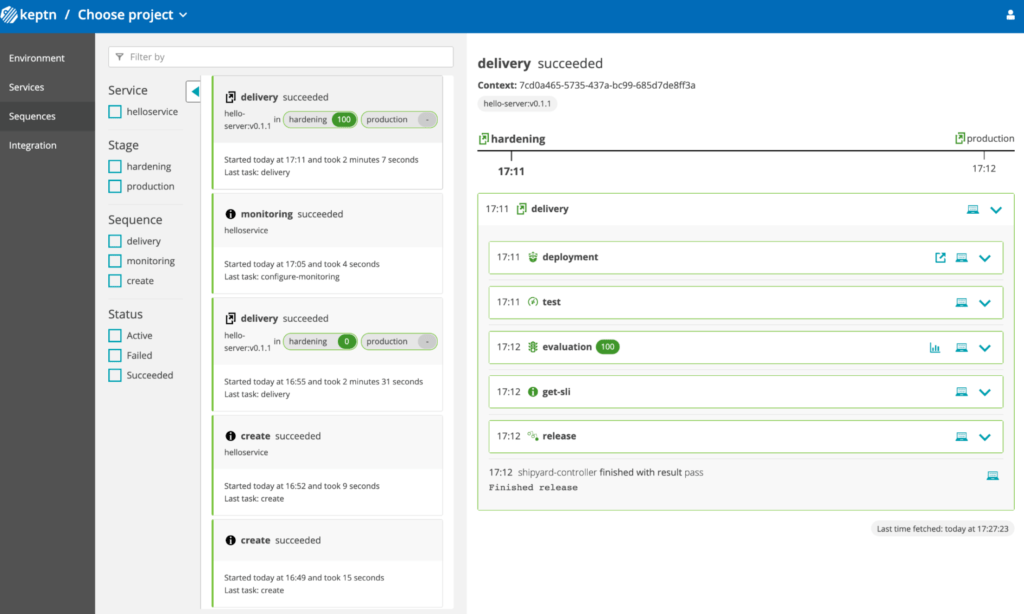
Nous avons ensuite la possibilité d’ajouter des tests et un check de SLO. Pour les tests de performance, nous utiliserons ici Jmeter car l’outil dispose d’un plugin compatible (la liste est disponible ici et les plugins en développement actifs peuvent être trouvés ici).
On peut faire le lien en ajoutant la stratégie compatible :
---
spec_version: '0.1.0'
workloads:
- teststrategy: performance
vuser: 50
loopcount: 10
script: jmeter/load.jmx
acceptederrorrate: 1.0
Enfin, on peut définir les SLO qui vont permettre d’identifier si l’application répond à nos critères de bon fonctionnement :
---
spec_version: '0.1.0'
comparison:
compare_with: "single_result"
include_result_with_score: "pass"
aggregate_function: avg
objectives: #<- définition des SLO
- sli: http_response_time_seconds_main_page_sum
pass:
- criteria:
- "<=1"
warning:
- criteria:
- "<=0.5"
- sli: request_throughput
pass:
- criteria:
- "<=+100%"
- ">=-80%"
- sli: go_routines
pass:
- criteria:
- "<=100"
total_score:
pass: "90%"
warning: "75%"
Essayons de faire une montée de version vers une image qui ne répond volontairement pas aux exigences de promotion (temps de réponse trop long…) :
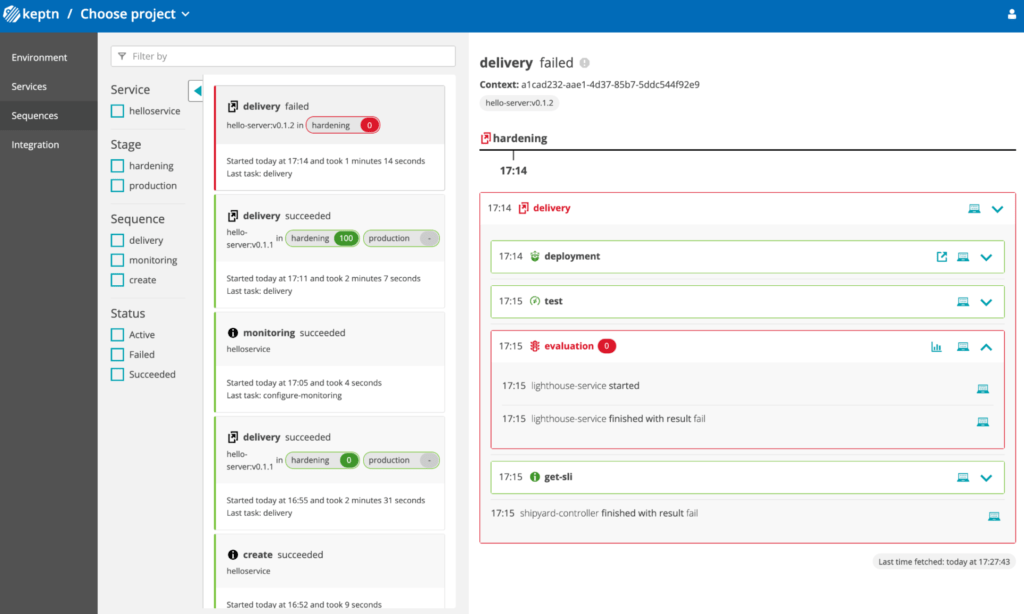
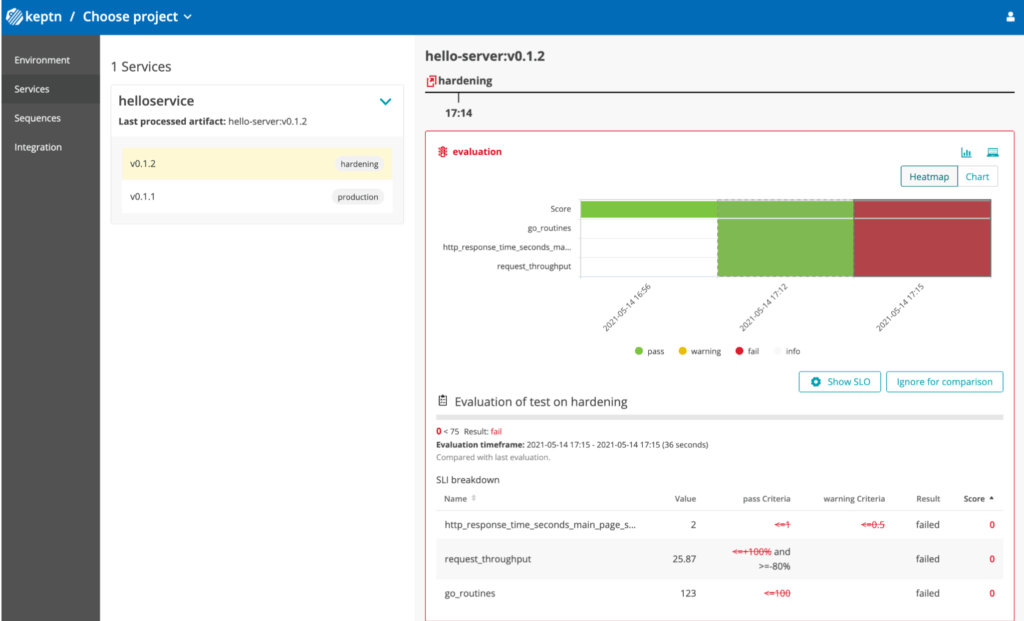
Quand on regarde le résultat plus en détail, on constate bien les Gates qui ne passent pas sur la nouvelle version :
Point intéressant, on constate que le déploiement au sein du cluster se fait en blue/green au sein du cluster et qu’il est géré directement par Keptn :
podtato-head/delivery/keptn main
> kubectl get pod -n pod-tato-head-hardening -o custom-columns=”NAME:.metadata.name,IMAGE:.spec.containers[0].image”
NAME IMAGE
helloservice-8966877c7-c8gs8 gabrieltanner/hello-server:v0.1.2
helloservice-primary-5f779966f9-5cgm7 gabrieltanner/hello-server:v0.1.1
Présentation de l'auto-remédiation par Keptn
Comme pour la définition de la séquence de déploiement, la boucle d’auto remédiation est également présente dans le fichier Shipyard.yaml. Celle-ci fonctionne suivant une suite d'étapes déclenchée par la réception d'un événement qui va se charger d'exécuter l’action de remédiation et de valider le fonctionnement de l’application sur l’environnement ciblé (ici la production).
---
apiVersion: "spec.keptn.sh/0.2.2"
kind: "Shipyard"
metadata:
name: "shipyard-sockshop"
spec:
stages:
- name: "production"
sequences:
- name: "remediation" #<- séquence de remédiation
triggeredOn:
- event: "production.remediation.finished"
selector:
match:
evaluation.result: "fail"
tasks:
- name: "get-action"
- name: "action"
- name: "evaluation"
triggeredAfter: "10m"
properties:
timeframe: "10m"
Ici, si un événement est détecté par Keptn, celui-ci va être résolu pendant la boucle de remédiation. On va ainsi avoir l’étape d’évaluation qui va échouer et mettre en place des actions dans un buffer qui sera récupéré et exécuté dans les steps “get-action” et “action”. Une nouvelle évaluation va ensuite être effectuée pour vérifier si le problème est résolu.

Les actions prennent la forme suivante :
---
apiVersion: spec.keptn.sh/0.1.4
kind: Remediation
metadata:
name: serviceName-remediation #<- Le service Keptn
spec:
remediations:
- problemType: Response time degradation #<- titre de l’alerte
actionsOnOpen: #<- La liste des actions
- action: scaling
name: Scaling ReplicaSet by 1
description: Scaling the ReplicaSet of a Kubernetes Deployment by 1
value: "1"
A la fin, Keptn va lister dans l’interface une trace de l’action de remédiation :
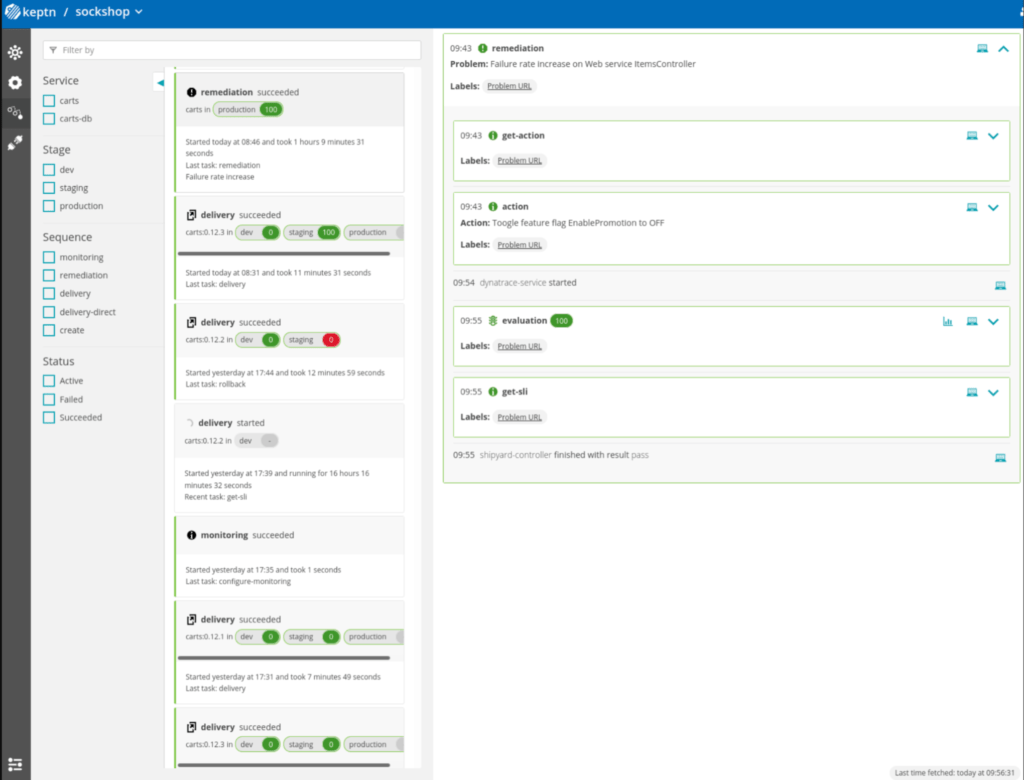
Pour le moment, on retrouve deux actions possibles (qui sont implémentées à travers d’ActionProviders prédéfini) :
- scale (pour modifier le nombre de pod)
- featuretoogle (pour activer des flags spécifiques)
Ces actions peuvent être étendues en développant ses propres ActionProviders.
Le mot de la fin
Comme vous avez pu le constater, les métriques sont bien souvent sous-estimées du fait que dans “l’inconscient collectif”, celles-ci sont difficilement exploitables autrement que sous forme de dashboard ou d’alerte. Cependant, quand on commence à définir des objectifs et à chercher programmatiquement un moyen de les exploiter, nos pratiques s’en trouvent décuplées. Cela nous ouvre la porte à de nombreux sujets et méthodologies : tout ce qui tourne autour du SRE, le chaos engineering et tous ces sujets qui reposent sur ce principe de “bon fonctionnement factuel et mesurable”.
Il faut avoir en tête que Keptn n’est qu’un outil parmi d’autres et je pense qu’à l’avenir, un très grand nombre d'outils de ce type vont apparaître dans notre paysage afin de faire évoluer notre rapport à la profession d’OPS.
Pour récapituler :
Pour tout savoir sur les enjeux Cloud, DevOps et Plateformes, cliquez ici.