Shift Right : Pourquoi valider des hypothèses en production au plus tôt ?
Nous parlons souvent dans nos pratiques ingénierie de shift right and left. Je vous propose ici d’explorer l’intérêt de faire du “Shift Right”
Le concept de "Shift Right" est apparu dans le contexte du développement logiciel et des pratiques DevOps au début des années 2010. Il s'inscrit dans une évolution plus large des méthodologies agiles et DevOps, qui visent à améliorer la collaboration entre les équipes de développement, de test et d'exploitation. Le shift right fait écho au shift left testing . Dans ce chapitre nous aborderons les points suivants :
- L’origine du concept
- En quoi les pratiques de Shift Right permettent de valider vos hypothèses en production ?
- Quelles sont les techniques classiques pour faire du shift right ?
- Que cherche t-on à tester en Shift Left et Right ?
Origine du Concept
Définition : “Shift Right a pour but de surveiller des indicateurs du comportement des utilisateurs, de l'utilisation, des performances et de la sécurité lors de la production afin de vérifier l'opérabilité du logiciel” - (la définition provient de l'article suivant : Les approches Shift Left et Shift Right - Red Hat)
Le “Shift Right” a été introduit comme une réponse pour capter ce que le Shift Left ne permettait pas d’obtenir. En Shift Left on se fonde sur l'ensemble des informations et compétences déjà à disponibles par l'équipe de delivery avant la mise en production. L'objectif c'est de tester des hypothèses en production pour les transformer en connaissances validées. Il s'agit de capter les retours terrains pour orienter les futures évolutions/corrections.
Nous pouvons parler des inconnues connues. En Shift Right, nous allons chercher des inconnues inconnues dans un contexte difficile à reproduire. Les inconnus connus sont des problèmes que l’on sait possibles, mais dont on ne connaît pas exactement le moment, la forme ou l’impact précis.
Exemples :
- Pics de charge : on sait que le système peut saturer lors de fortes sollicitations, sans savoir exactement quand ni à quel seuil.
- Dégradations de performance : on anticipe des lenteurs possibles, mais sans identifier précisément les composants concernés.
- Erreurs réseau intermittentes : on sait que des pertes de connectivité peuvent survenir, sans pouvoir les reproduire facilement.
- Problèmes de montée en version : on sait qu’une mise à jour peut provoquer des effets de bord, sans connaître lesquels à l’avance.
- Limites de configuration : on sait que certains paramètres peuvent devenir bloquants à grande échelle, sans en mesurer l’impact réel en amont.
Lorsque nous mentionnons de raccourcir la boucle de feedback dans le cadre du Shift Right il s’agit de toutes les opérations à droite du schéma en bleu foncé :
- Release
- Déploiement
- Opérations
- Monitoring
L’idée est de fluidifier l’ensemble de ces étapes, de déployer le plus rapidement en production et de monitorer son système afin de répondre plus facilement aux défaillances.
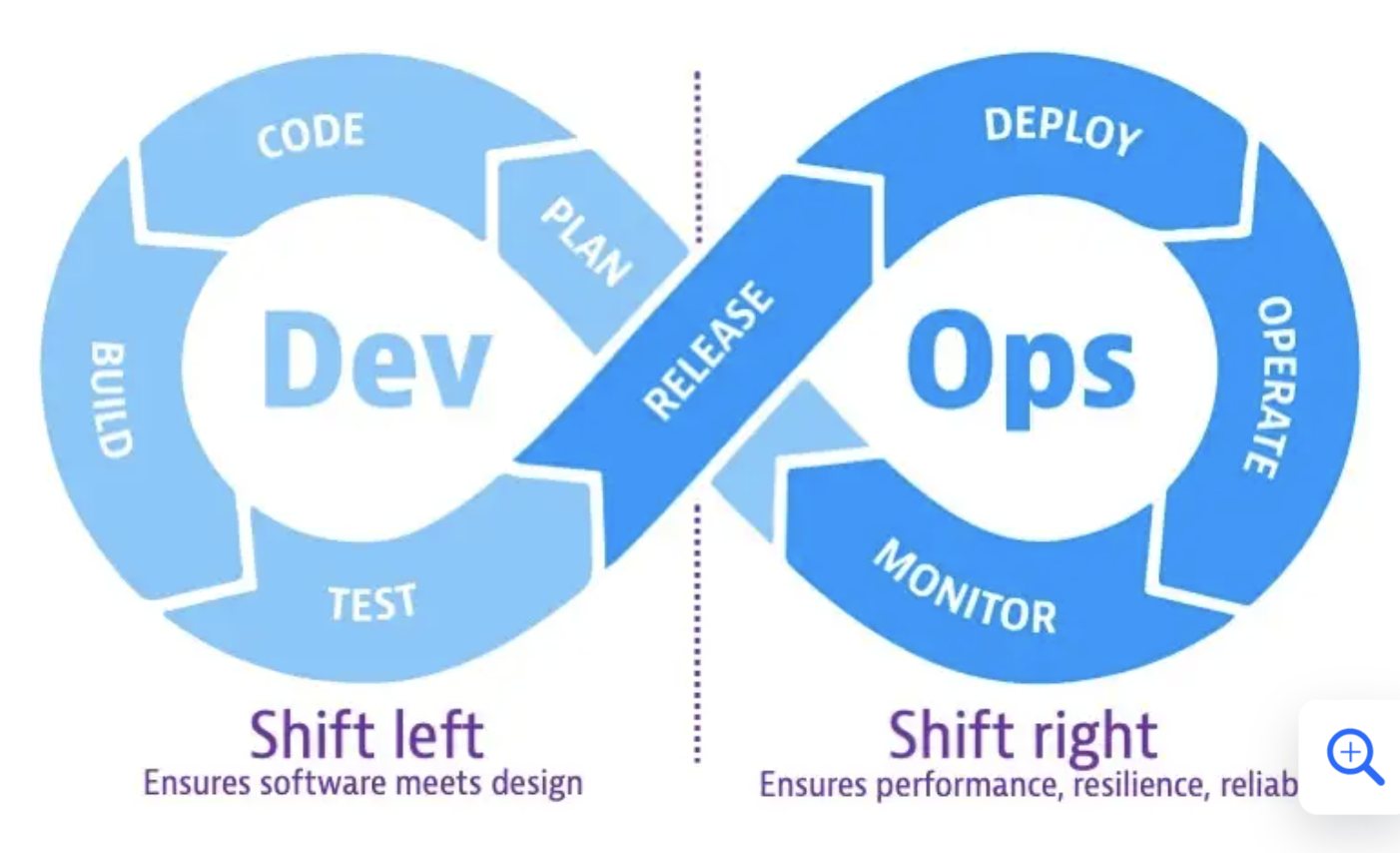
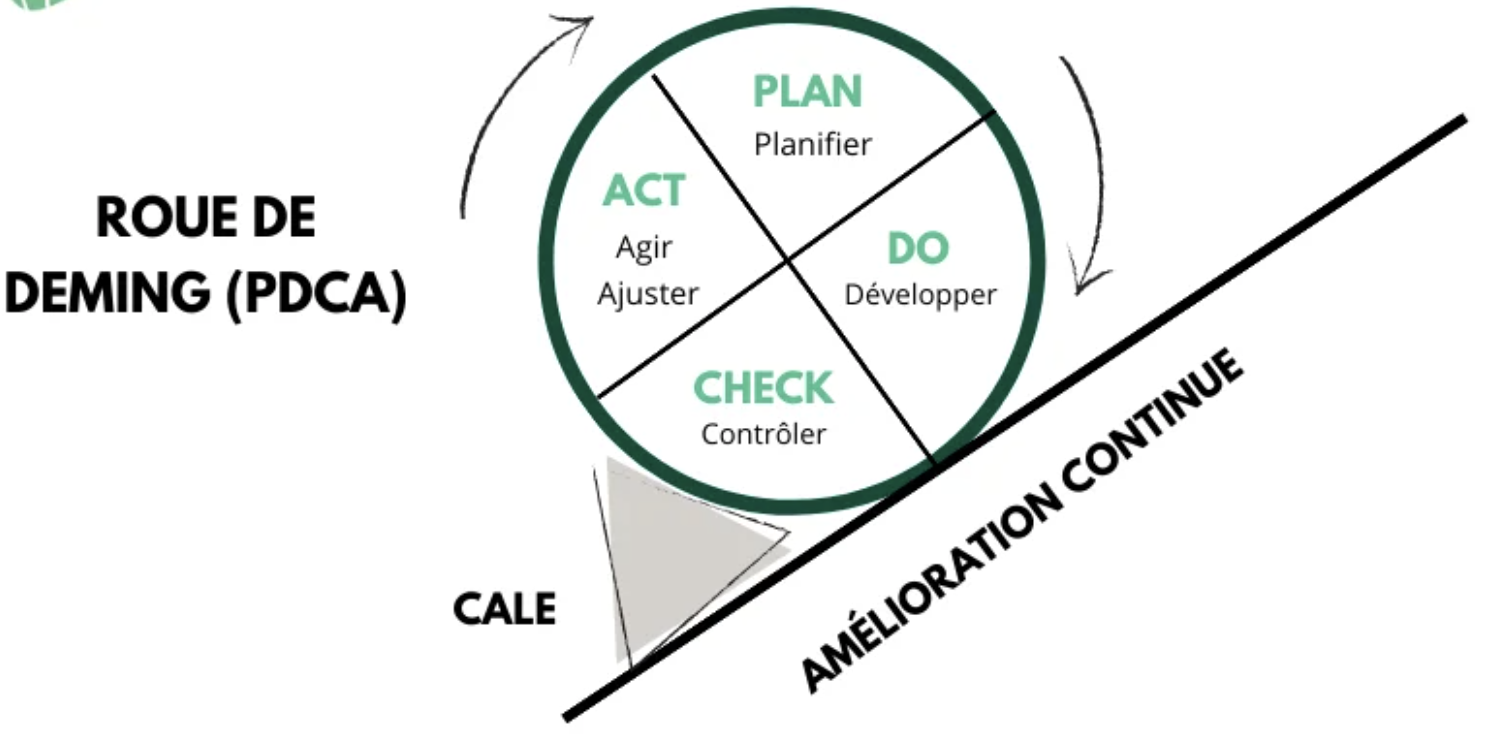
Le schéma a pour vocation de délimiter la partie Shift Left et Shift Right. Dans le quotidien de nos activités ce n’est pas aussi marqué. Il est important de lier cette représentation à toutes les actions qui vont améliorer les phases de développement et les opérations de mise en production sans oublier le monitoring et l’observabilité. Nous sommes plus dans une approche matérialisée par la roue de Deming avec son PDCA (Plan, Do, Check, Act). Une amélioration pas à pas afin de s’assurer que les actions mises en place ont eu l’impact escompté.
L’objectif est d’effacer les frontières entre les développeurs et les ops dans la mouvance devops.
Avec la montée en puissance des pratiques DevOps, le "Shift Right" a gagné en popularité comme un moyen de tester des hypothèses métiers et techniques rapidement en production et d'assurer une meilleure qualité logicielle et une réactivité accrue aux besoins des utilisateurs.
Amazon a été un précurseur dans l’adoption des pratiques DevOps en mettant en œuvre des tests directement en production, tels que des déploiements progressifs, des tests A/B, des tests de résilience et l’observation des performances réelles. L’analyse continue des métriques et des feedbacks utilisateurs a permis d’affiner les services après leur mise en production et de renforcer les pratiques de développement continu et itératif. Amazon à mis en place des tests de performance en conditions réelles. Plutôt que de se limiter à des environnements de test :
- Observation des temps de réponse en production.
- Surveillance de la montée en charge réelle.
- Détection de goulets d’étranglement impossibles à reproduire hors production.
En résumé, bien que les principes sous-jacents du "Shift Right" soient présents depuis un certain temps, le terme et sa popularité se sont développés principalement au cours de la dernière décennie, en parallèle avec l'évolution des méthodologies agiles et DevOps.
En quoi les pratiques de Shift Right permettent de valider nos hypothèses de production ?
Déployer en production et tester au plus proche des utilisateurs permet de valider des comportements qu’il est difficile de reproduire dans des environnements hors production.
| Sujets | Avant la production | En production |
|---|---|---|
| Les comportements réels des utilisateurs | Scénarios utilisateurs hypothétiques Données artificielles Parcours idéalisés | Usages imprévus Détournements de fonctionnalités Abandons, clics, hésitations réelles |
| La charge et la variabilité réelles | Impossible à simuler fidèlement avant : - pics soudains de trafic - effets de saisonnalité - concurrence réelle des utilisateurs | Tests de montée en charge réels Observation des seuils de saturation |
| Les défaillances réelles du système | En préproduction : - pannes simulées - scénarios limités et contrôlés | Pannes réseau réelles : - indisponibilités partielles - Latences imprévisibles |
| Les interactions avec l’écosystème réel | Services mockés Versions figées Dépendances simplifiées | Comportements réels des APIs partenaires Évolutions non maîtrisées |
| Les performances perçues par l’utilisateur | Métriques techniques Benchmarks théoriques | Temps de réponse ressentis Dégradations partielles |
undefined
Quelles sont les techniques pour faire du shift right ?
Voici quelques exemples de techniques pour sécuriser vos mises en production dans le cadre du shift right. Ces techniques ne sont pas exhaustives.
- Canary Releases : Déploiement de nouvelles fonctionnalités auprès d'un petit sous-ensemble d'utilisateurs avant le déploiement complet, ce qui permet aux développeurs de surveiller les performances et recevoir du feedback dans le monde réel.
Dans le cadre d’un grand programme public de refonte d’un système legacy touchant des milliers d’agents et des dizaines de millions d’utilisateurs finaux, l’équipe OCTO a opté pour une variante de canary release.
Il s'agissait de déployer des fonctionnalités de façon itérative à un sous-ensemble d’utilisateurs métiers sur une période donnée. Cela permettait à l’équipe d’ajouter des utilisateurs pas à pas et d’enrichir les fonctionnalités sans impacter la production. L’équipe n’utilisait qu’une version applicative. La gestion de ce sous-ensemble a été faite par configuration. Pour chaque fonctionnalité, il était indiqué si la fonction est activé où non (feature flag) et qui y accédait. La librairie utilisée était la suivante : https://ff4j.github.io/ (Role-based Toggling).
Une autre façon aurait été de créer une version applicative N et N+1 et de rediriger une partie de la population sur une courte période avant de basculer la totalité de la population.
- Features Flag : Activation ou désactivation de certaines fonctionnalités en production afin de les tester sans impact sur l'ensemble des utilisateurs. Cela demande de la rigueur par la suite car il faut pouvoir retirer ces éléments d’activation et de désactivation quand ce n’est plus utile dans le code. Cette technique est souvent utilisée quand votre projet grandit rapidement avec des déploiements fréquents. Les Features flags permettent de mieux isoler les fonctionnalités de vos applications, et ainsi d’en avoir une meilleure maîtrise même en production, ce qui a pour avantage de fluidifier les processus de déploiement dans un contexte agile.
Au sein de la plateforme de smart city nous avions des équipes distribuées, chacune d’elles travaillaient sur un périmètre fonctionnel. Comme nous avions du mal à nous synchroniser, la première équipe qui livrait en production était la première servie. Sachant que nous ne faisions pas de distinction entre production et ouverture de service. Ce qui était déployé était visible des utilisateurs finaux. L’impact était fort car certaines équipes ne pouvaient pas déployer leurs features et attendaient dans certains cas plusieurs mois avant de pouvoir le faire. Nous accumulions des développements que nous ne pouvions présenter aux utilisateurs finaux afin de prendre en compte leur feedback. En intégrant les features flag, les équipes avaient moins cette contrainte d’être synchronisées en permanence et nous pouvions livrer en production régulièrement et décider ensemble du moment le plus opportun d’ouvrir le service pour offrir une expérience.
- A/B Testing : Lancement de différentes versions d'une application pour voir comment les utilisateurs réagissent, souvent pour optimiser l'interface utilisateur/UX ou pour tester de nouvelles fonctionnalités.
Au sein d’un opérateur de transport national, une équipe de 4 personnes avait pour objectif d’implémenter des scénarios co-construits avec les métiers et de tester plusieurs variantes du site web afin de fournir des métriques aux équipes produits. Il est possible par exemple de faire les tests suivants :
- Le call-to-action d’une page Internet pour identifier le bouton qui génère le plus de clics.
- Le design d’une landing page pour déterminer la mise en page qui génère le meilleur taux de conversion.
- L'image d’un produit d’une page e-commerce pour analyser ce qui vend le plus.
- L’objet d’un email pour sélectionner celui qui génère le taux d’ouverture le plus élevé.
- Surveillance en temps réel: Des outils comme Prometheus, Grafana ou Datadog pour surveiller les applications et alerter sur les défaillances ou les problèmes de performance.
Au sein de la plateforme de smart city nous n’avions aucun outil de monitoring pour diagnostiquer les problèmes que nous rencontrions. Il était difficile de savoir s’il s’agissait d’un problème lié à l'infrastructure où à l’applicatif. La mise en œuvre de Grafana à permis de surveiller en temps réel l’application et de déterminer avec plus d'efficacité l’origine du problème notamment sous forme de tableaux de bord.
Dans le cadre d’un grand programme dans le secteur public Prometheus à donné aux équipes DevOps les moyens de surveiller et de contrôler le système. Il fournit une surveillance en temps réel, collecte des métriques sur les performances et la disponibilité des applications, et alerte les équipes en cas de défaillances ou de problèmes.
Bien que limitée dans la visualisation des metrics, en combinant l’outil avec Grafana, les développeurs peuvent collecter, analyser et visualiser les métriques de leurs systèmes et services de manière efficace et intuitive.
undefined
Que cherche t’on à tester en left et right ?
En shift Left
Le shift left permet de mettre en place toutes les bonnes pratiques de test en amont et pendant les développements. Le test ne doit plus se pratiquer à la fin du projet mais à toutes les étapes de la vie du projet. Dans les faits un shift left testing bien implémenté peut permettre de :
- Réduire les coûts : avec une détection plus précoce des anomalies
- Améliorer l’efficacité : en limitant les allers-retours entre les différents intervenants et les fonctionnalités ne correspondant pas à ce qui est souhaité
- Améliorer la qualité : le fait de faire des tests dès le début du projet diminue les chances d’erreurs humaines.
Les limites du Shift Left s'arrêtent à la production. Pour y pallier, le Shift Right ne se cantonne donc plus à se référer au build mais va au-delà pour atteindre le run et plus généralement le cycle de vie du produit.
En shift right
Les tests sont effectués plus tard dans le processus de développement, plus près du moment du déploiement ou même après le déploiement. Il y a des comportements que vous ne verrez qu’en prod. Donc outillez vous pour facilement partir en prod et apprendre de ce que vous voyez. Cf le paragraphe “En quoi les pratiques de Shift Right permettent de valider nos hypothèses de production ?”
L'objectif des tests Shift Right est de comprendre l'utilisabilité, la stabilité et les problèmes de production émergents, ce qui conduit finalement à des logiciels de meilleure qualité et, in fine, à une mise sur le marché plus rapide.
- Dans l’approche Shift Right on se rapproche de la mise en service, de la maintenance en condition opérationnelle, de corriger des anomalies de production. Les équipes vont prendre en compte plusieurs éléments
- Monitorer le comportement de l’application, travailler sur l’observabilité
- Récupérer et analyser les logs pour comprendre les dysfonctionnements de l’application
- Analyser les anomalies de production pour définir des posts mortems et améliorer les procédures
- Connaître et comprendre au fur et à mesure que la demande de production évolue dans le temps.
En substance, Shift Right consiste à rendre les systèmes plus résistants et à veiller à ce que la qualité ne soit pas seulement vérifiée à la fin du développement, mais qu'elle soit continuellement améliorée dans la phase de mise en production.
Conclusion
Les tests Shift Right permettent d'obtenir des retours d'expérience d'utilisateurs en temps réel et en continu, et d'analyser les problèmes qui n'auraient pas été anticipés. En permettant à vos équipes d'exécuter des tests de bout en bout à toutes les étapes du cycle de développement logiciel, vous renforcer votre approche du continuous delivery.
Avantages de Shift Right :
- Détection plus rapide des problèmes: Les problèmes sont détectés plus rapidement et il est plus facile de reproduire les problèmes réels lorsqu'ils sont observés en production.
- Meilleur retour d'information de la part des utilisateurs: En testant dans le monde réel, vous obtenez des données plus précises sur la manière dont le logiciel se comporte avec de vrais utilisateurs.
- Amélioration de la qualité: Grâce à la surveillance continue et à l'itération rapide, les anomalies sont identifiées et corrigées plus rapidement, ce qui permet d'obtenir un logiciel de meilleure qualité.
- Efficacité accrue: Les équipes peuvent détecter les problèmes en production sans perturber les utilisateurs finaux, ce qui permet d'effectuer des déploiements plus fréquents avant ouverture de service.
En favorisant la mise en production au plus tôt, vous permettez de tester l’application en condition réelle pour l’adapter au regard des retours utilisateurs et de ce que vous constatez. Le shift right ne permet pas à lui tout seul de fiabiliser un système ou une application, il est souvent associé au shift left. Réduire la boucle de feedback demande un travail permanent sur l’amélioration continue, l’implication des équipes et cela sur toute la chaîne de delivery voir en amont de celle-ci.
undefined
Références
Livres
The DevOps Handbook par Gene Kim, Patrick Debois, John Willis et Jez Humble - Ce livre aborde des pratiques DevOps, y compris des stratégies de test et de déploiement qui incluent le "shift right".
Accelerate: The Science Behind Devops: Building and Scaling High Performing Technology Organizations par Nicole Forsgren, Jez Humble et Gene Kim - Ce livre présente des recherches sur les pratiques qui améliorent la performance des équipes de développement, incluant des éléments du "shift right".
Quelques capabilities autour de la notion de shift right (liste non exhaustive) :
Site Reliability Engineering par Niall Richard Murphy, Betsy Beyer, Chris Jones et Jennifer Petoff - Bien qu'il se concentre sur l'ingénierie de fiabilité des sites, il traite également des pratiques de mise en production et d'observation qui font partie du "shift right".
Testing in DevOps par Eoin Woods et Mary Thorn - Ce livre traite spécifiquement des tests dans un environnement DevOps, ce qui inclut le passage à des tests plus tardifs dans le cycle de développement.
Chaos Engineering par Casey Rosenthal & Nora Jones - Ce livre présente l'ingénierie du chaos qui consiste à provoquer de façon volontaire et contrôlée des défaillances dans l'environnement de production ou de préproduction afin d'en évaluer l'impact, de planifier une meilleure défense et d'affiner la stratégie de maintenance en cas d'incident.
Observability Engineering par Charity majors, Liz Fong-Jones & George Miranda - Ce livre pratique explique la valeur des systèmes observables et vous montre comment pratiquer un développement axé sur l'observabilité.
Articles
Shift Right: The New Testing Paradigm - Cet article explore les concepts et les avantages du "shift right" dans les tests, en soulignant l'importance des tests en production.
Shift Left testing : Cet article vous explique l’intérêt de faire du Shift Left et aide notamment à mieux comprendre le Shift Right et les prérequis de la collaboration.
Du Continuous Delivery pour de la Continuous Value : Cet article revient sur l’origine du continuous delivery et son impact de la chaîne de développement à la production