Sécurité dans les pods : Isolation et RuntimeClass
Cet article s’appuie sur la notion d’extensions de Kubernetes déjà abordée ici, et détaillera plus particulièrement la Container Runtime Interfaces (CRI). Il s'adresse à une population familière avec Kubernetes.
Vous le savez sans doute déjà : Kubernetes permet l’orchestration de milliers d’applications dispersées sur des dizaines de serveurs. Et lorsque vient la question de la sécurisation on doit en plus considérer un nombre croissant de niveaux : depuis la machine jusqu’à l’API exposée sur Internet, en passant par le cluster. Je vous propose une manière d’isoler nos applications en utilisant conjointement la capacité d’extension de Kubernetes et la notion de RuntimeClass.
On commencera par rappeler les problématiques d’isolation de processus - et pourquoi on veut les isoler - puis nous ferons un tour de table de quelques unes des implémentations majeures des Container Runtime Interfaces, et enfin nous irons plus en avant dans l’exploitation de ces runtimes de conteneurs, et leur capacité à mixer des contextes d’exécution différents via la Custom Resource (CR) RuntimeClass.
Seul au monde ?
L’isolation des applications dans un cluster Kubernetes a notamment pour objectif de contenir la propagation d’une compromission d’une des applications.
Vous n’êtes pas sans savoir que début 2019 une CVE a touché runc. Tout acteur malveillant pouvant exploiter une telle faille critique peut devenir maître de l’hôte. Et si l’hôte est compromis c’est tout le cluster Kubernetes qui est compromis. Vous perdez alors le contrôle de votre cluster… Effrayant n’est-ce pas ?
Peut-être me diriez-vous que de toute façon vous n’utilisez pas runc mais docker ?
Vous verrez par la suite que toute la magie des conteneurs est entre les mains de runc, et que quasiment tous les acteurs de l'écosystème de la conteneurisation, Docker y compris, reposent sur runc.
Une bonne stratégie d’isolation vous permettra donc de mieux contenir une éventuelle faille et de limiter les dégâts.
Dans cet article nous aborderons une stratégie spécifique qui consiste à ajouter une couche de virtualisation.
Notre conteneur s’exécutera alors au sein d’une machine virtuelle - la plus légère possible - de manière à limiter la propagation lors d’une brèche éventuelle.
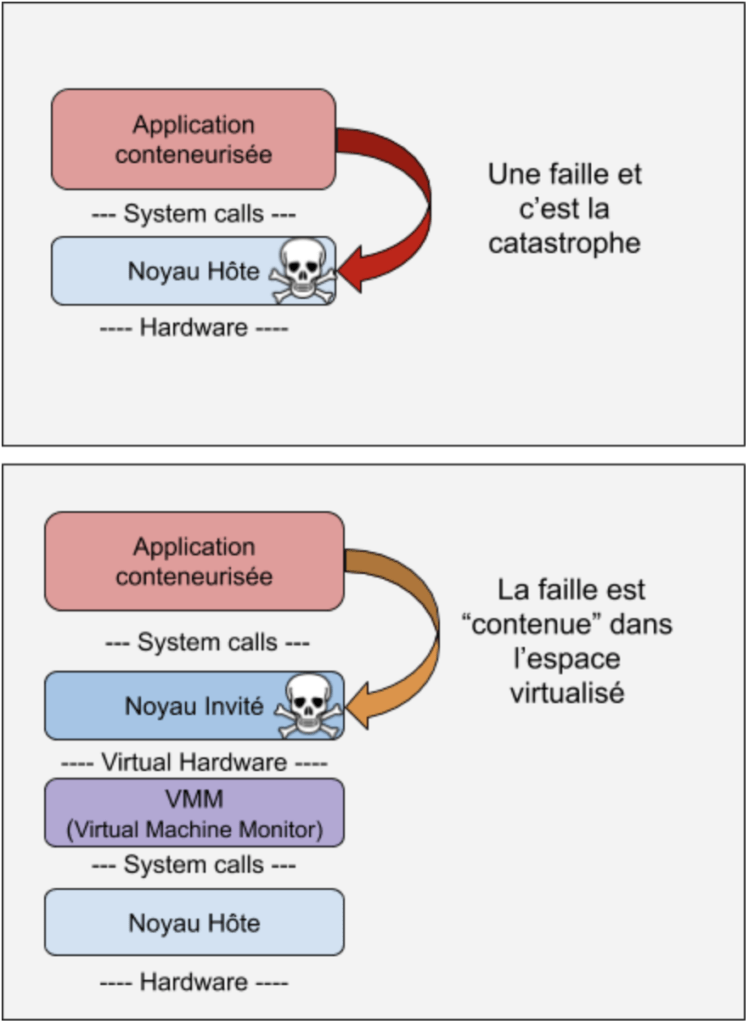
Ainsi les applications exposées sur Internet, les conteneurs basés sur des images d’auteurs inconnus, les applications sensibles (chiffrement, blockchain, contraintes métier,...), ou encore les environnements multi-tenants méritent une attention et une isolation particulière.
L’extension Kubernetes par laquelle la magie opère : Container Runtime Interface
C’est une couche d’abstraction qui fournit à Kubelet la capacité d’utiliser différents runtimes de conteneurs compatibles avec l’OCI (Open Container Initiative).
Avoir plusieurs runtimes de conteneurs n’est pas une nouveauté dans Kubernetes. Initialement conçu pour ne fonctionner qu’avec Docker, la Kubelet a une première fois été modifiée pour pouvoir utiliser Docker ou rkt. Ces runtimes étant directement intégrés dans le code de la Kubelet, il fallait alors s’armer d’une belle quantité de if-then-else et recompiler le tout. Pas facile à maintenir.
La CRI ajoute donc un mécanisme de plugin sous la forme d’une API en gRPC, et permet - depuis Kubernetes 1.5 - de s’interfacer avec de nombreux runtime de conteneurs sans avoir à tout recompiler.
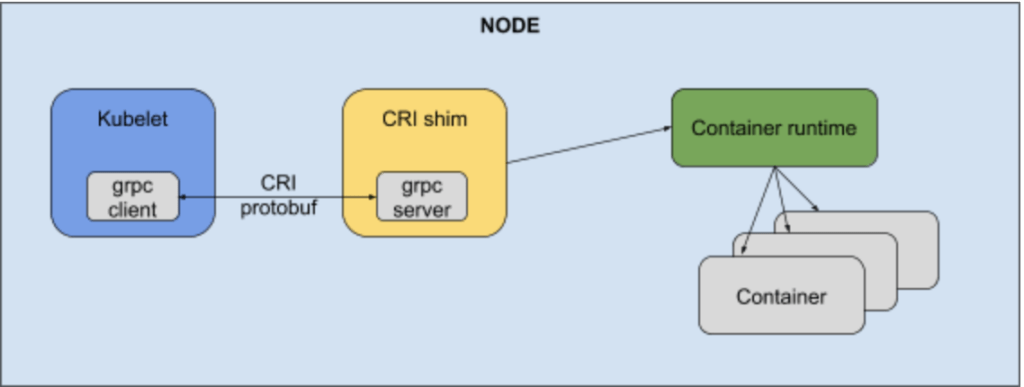
Le runtime de conteneurs a pour responsabilité entre autres :
- Gérer le cycle de vie des conteneurs
rpc CreateContainer (...) returns (...) {} rpc ListContainers (...) returns (...) {} rpc RemoveContainer (...) returns (...) {} rpc StartContainer (...) returns (...) {} rpc StopContainer (...) returns (...) {} …
- Gérer le cycle de vie de la sandbox dans lesquels les conteneurs vont vivre (pods)
rpc RunPodSandbox (...) returns (...) {} rpc StopPodSandbox (...) returns (...) {} rpc RemovePodSandbox(...) returns (...) {} rpc ListPodSandbox (...) returns (...) {}
- Piloter les conteneurs et interagir avec eux
rpc ExecSync (...) returns (...) {} rpc Exec (...) returns (...) {} rpc Attach (...) returns (...) {} rpc PortForward (...) returns (...) {}
Plus de détails sont disponibles dans le protobuf de l’API.
Les acteurs majeurs
La famille des runtimes de conteneurs s’agrandit de jour en jour.
La multiplication de ces runtimes de conteneurs, ainsi que l’extension de leur couverture fonctionnelle font qu’il est souvent difficile de s’y retrouver. De plus il est commun de voir dans la littérature la réutilisation de la notion de runtime de conteneurs pour des outils très différents.
Afin de vous aider à y voir plus clair, je vous propose d’utiliser la notion de runtime de conteneur de haut niveau et runtime de conteneur de bas niveau.
Et par la suite dans cet article on appellera les runtimes de conteneurs de haut niveau des manager de conteneurs, et on conservera l'appellation de runtimes de conteneurs pour ceux de bas niveau.
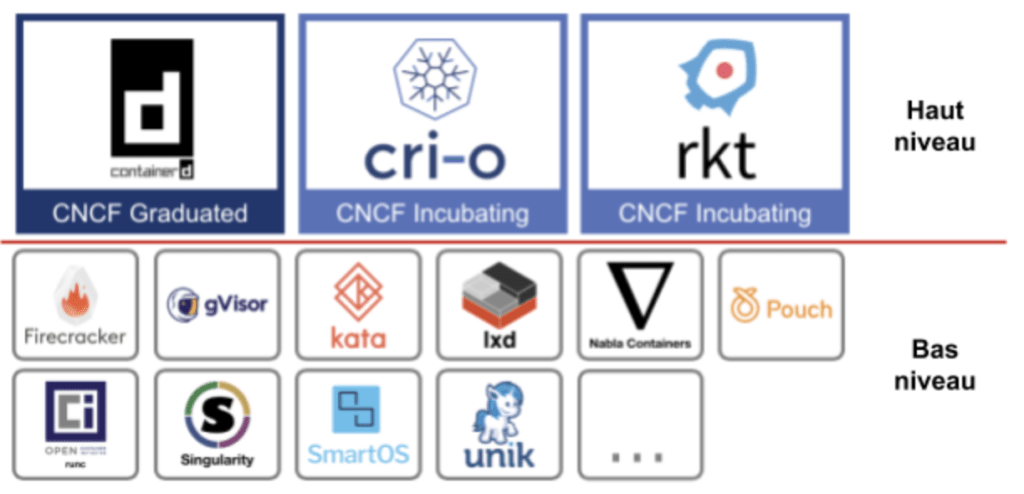
Runtimes de conteneurs
L’OCI a défini des spécification de runtimes et d’images. Les runtimes de conteneurs vont tout simplement s’occuper d’implémenter ces spécifications.
Pour simplifier, un runtime de conteneurs bas niveau va lire un répertoire qui contient le rootfs et la configuration du conteneur attendu (point de montage, limites de ressources, processus à démarrer, etc…). Avec toutes ces informations le runtime va produire le conteneur en manipulant les différents outils offerts par le noyau (namespace, cgroups,...). Il existe beaucoup de runtime de conteneurs, et la famille grandit de jour en jour, je vous présente les 3 qui me semblent pertinents.
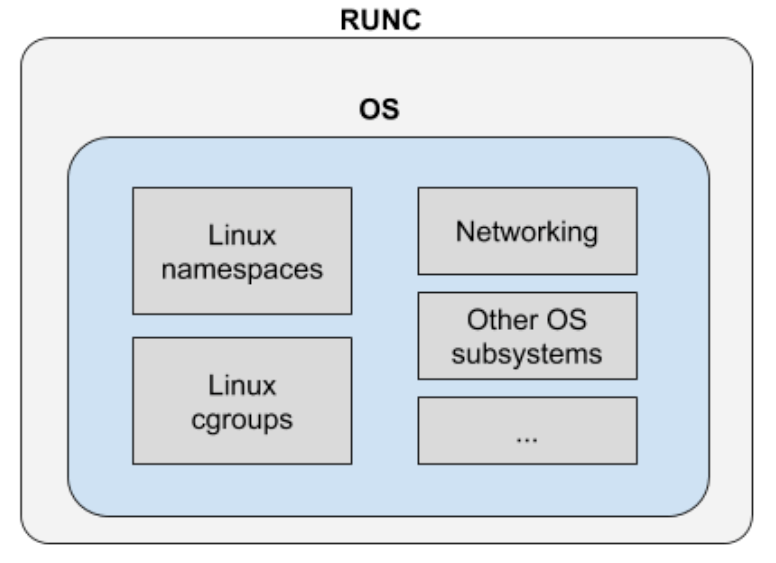
runc
C’est un projet qui était initialement un composant de Docker puis qui a été extrait et transformé en un CLI (Command Line Interface).
C’est un composant central quand vient la question des conteneurs - d’ailleurs runc est l’implémentation de référence des spécifications OCI.
Cet exécutable va donc interagir directement avec le noyaux Linux pour permettre la création d’un conteneur.
Par conséquent, lorsque l’on parle de conteneurs sous le capot il y a bien souvent runc.
gVisor
C’est un projet développé par Google qui est au coeur de leur technologie Cloud Run, Cloud Functions, ou encore GKE avec GKE Sandbox.
Comme l’indique si bien la documentation de gVisor, exécuter un processus non fiable ou potentiellement malveillant sans isolation est souvent une mauvaise idée !
Comme nous l’avons vu précédemment, la promesse de performance qu’apporte l’utilisation d’un noyau partagé implique qu’une seule faille de sécurité suffit pour sortir du conteneur et compromettre l’isolation.
C’est une technologie qui mériterait un article à part entière: gVisor émule un noyau Linux au sein de l’espace utilisateur et cherche à obtenir le même niveau d’isolation qu’une couche de virtualisation tout en conservant la promesse de performance des conteneurs.
Kata Container
Ce runtime de conteneur, compatible OCI donc, permet l’exécution de conteneurs au sein de VM légère (encore appelées micro-VMs).
Cela permet d’obtenir une isolation additionnelle par rapport à l’hôte afin de minimiser la surface d’attaque et d’atténuer les conséquences d’une sortie d’un conteneur par un acteur malveillant.
Kata Container offre une possibilité de configuration extensive qui sort très largement des considérations de cet article. On peut notamment utiliser QEMU mais aussi Firecracker.
Nous verrons plus loin comment utiliser Kata Container avec QEMU pour exécuter une classe de conteneur untrusted.
Manager de conteneurs
Utiliser une commande telle que runc nous permet de démarrer autant de conteneurs que nécessaire. Mais que se passe-t-il lorsque l’on souhaite automatiser un peu les choses ?
Dans un contexte où il y a plusieurs dizaines, voir centaines de conteneurs, comment gérer le redémarrage en cas d’erreur, la gestion des ressources, les images de conteneurs, et ainsi de suite ?
C’est le rôle des manager de conteneurs, qui sont un peu plus haut niveau, et permettent de simplifier grandement toutes ces problématiques.
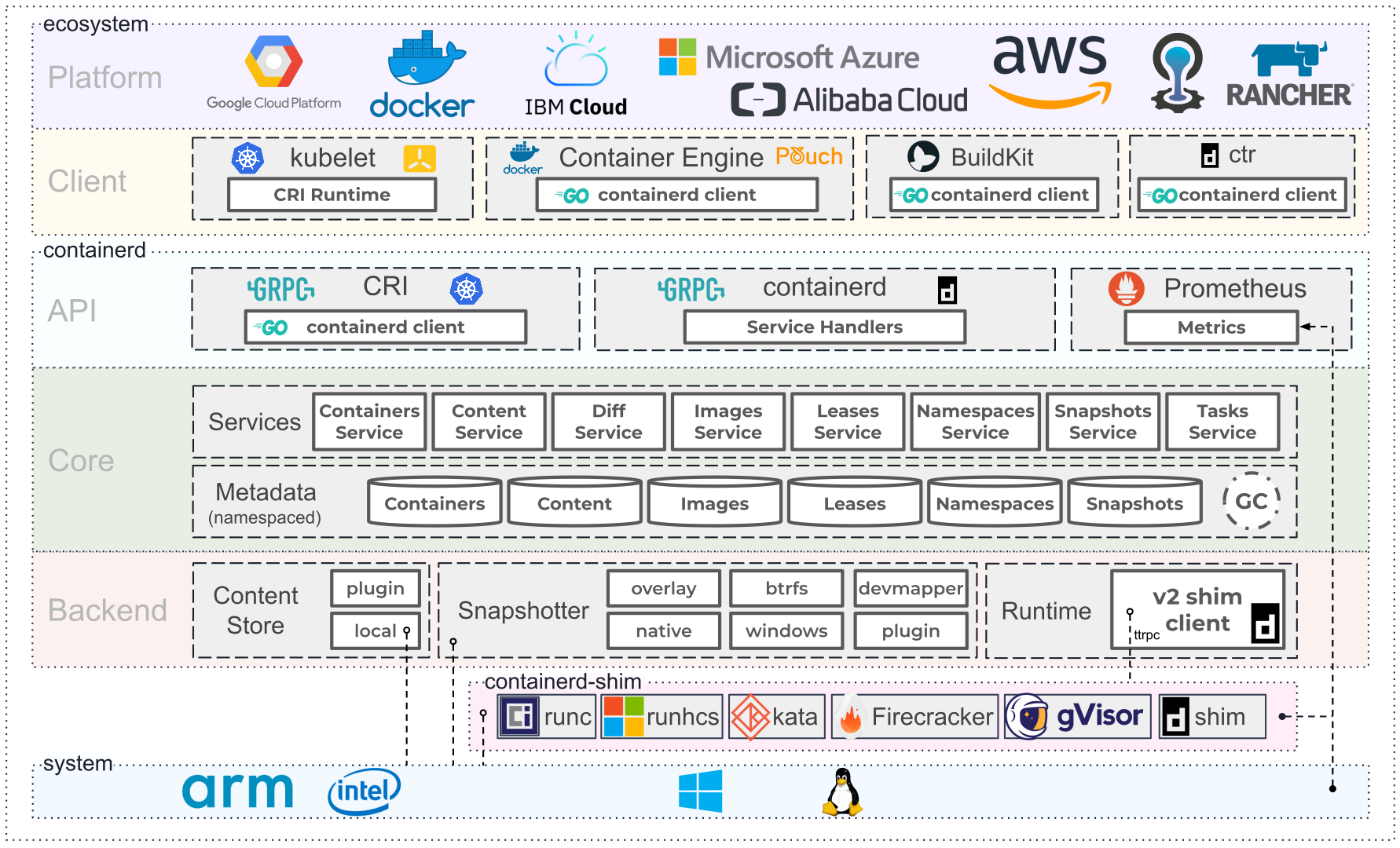
Containerd
Tout comme runc, c’est un héritage de Docker: containerd est initialement un des composants de Docker.
Dorénavant c’est un projet à part entière qui se place dans la catégorie des runtimes de conteneurs, mais pas exactement au même sens qu’un runc.
Concrètement containerd est démarré en tant que daemon et tandis qu’une instance de runc va se coupler avec un conteneur, containerd va agir en tant que serveur capable de démarrer, stopper ou mettre à disposition le statut d’un ou plusieurs conteneurs.
Mais containerd est bien plus qu’un gestionnaire de cycle de vie de conteneurs, il est aussi responsable de la gestion des images de conteneurs (pull & push depuis un registry, stockage des images, …), l’établissement d’un réseau entre plusieurs conteneurs, et encore bien d’autres fonctionnalités.
{kind=link}
C’est un projet qui est intégrable directement dans Kubernetes car il respecte la CRI, mais containerd est pensé dans une optique plus généraliste que Kubernetes.
CRI-O
CRI-O provient de l’univers Kubernetes: c’est une implémentation de la CRI effectuée par RedHat.
Son nom est le fruit de la contraction de CRI et OCI, et son objectif unique est de remplir la spécification de la CRI. Ainsi le versionning de CRI-O suit celui de Kubernetes. Par défaut il s’appuie sur runc, mais est tout à fait capable d'interagir avec tout runtime de conteneur compatible OCI.
Et docker dans tout cela ?
Comme on a pu le voir Docker est à l’origine de deux technologies fondamentales: containerd et runc.
La communauté Kubernetes a travaillé à définir des interfaces de manière à se décorréler du daemon Docker et permettre l’utilisation d’autres runtimes.
Le runtime Docker est maintenant une implémentation de CRI parmi d’autres.
Docker est ainsi passé du statut de first class citizen à une option d'implémentation.
Allocation de runtime dans Kubernetes
La capacité de ces manager de conteneurs à s’interfacer avec tout runtime de conteneurs respectant la spécification OCI ouvre la possibilité d’allouer différent runtimes de conteneur selon le workload.
Chaque manager de conteneurs a initialement proposé sa propre gamme d’annotation pour configurer son comportement. Voici quelques exemples d’annotations:
| CRI Runtime | Pod Annotation |
| CRI-O | io.kubernetes.cri-o.TrustedSandbox: "false" |
| containerd | io.kubernetes.cri.untrusted-workload: "true" |
| frakti | runtime.frakti.alpha.kubernetes.io/OSContainer: "true"<br><br>runtime.frakti.alpha.kubernetes.io/Unikernel: "true" |
| windows | experimental.windows.kubernetes.io/isolation-type: "hyperv" |
De manière à rationaliser ces annotations, la communauté Kubernetes a donc mis en place la RuntimeClass qui permet de déclarer des classes de runtime d’exécution à destination du manager de conteneurs :
apiVersion: node.k8s.io/v1alpha1 # La RuntimeClass est définie dans le groupe d'API node.k8s.io kind: RuntimeClass metadata: name: myclass # Le nom avec lequel la RuntimeClass sera référencée # La RuntimeClass est une ressource non cantonnées à un namespace spec: runtimeHandler: myconfiguration # Le nom de la configuration CRI correspondante
À l’usage il s’agira d’indiquer quel RuntimeClass le pod devra utiliser :
apiVersion: v1 kind: Pod metadata: name: mypod spec: runtimeClassName: myclass # ...
Toute la magie s’opère alors au niveau de la configuration du runtime de conteneurs, qui saura faire intervenir le bon runtime d’exécution au moment de démarrer le pod.
Il est intéressant de voir que les annotations initiales, propres aux premières CRI, offraient généralement une option "isolé" et "non isolé", ou encore trusted versus untrusted. Pour autant la communauté Kubernetes a ouvert le concept de manière à utiliser autant de runtime d’exécution que nécessaire et ainsi gérer plus finement le contexte d'exécution.
> Attention lors de l'utilisation de runtimes d'exécution basés sur de la virtualisation.
Dans un cluster Kubernetes, chaque pod va consommer - en plus de ses propres besoins - un certain nombre de ressources supplémentaire: Kubelet (control loops), la CRI, kernel (plusieurs ressources), fluentd (logs), ...
La stratégie par défaut de Kubernetes est d’allouer une quantité fixe de ressources - mémoire et CPU - pour les composants système qui permettent à un pod de s’exécuter convenablement.
Cette fraction de ressource est déterminée en dur et est prise en compte par le scheduler lors de l’assignation du pod, on pense notamment au pause container de Kubernetes. Ce modèle ne scale pas idéalement et surtout est beaucoup moins adapté à des runtimes de conteneur basés notamment sur la virtualisation : je ne vous apprend pas qu’une VM consomme bien plus de ressources qu’un conteneur, même si c’est une micro-VM. Kubernetes propose ainsi la notion de PodOverhead permettant d’aider le scheduler à prendre en compte cette diversité. Cependant cette feature est encore en alpha dans la version 1.16.
Si vous êtes curieux concernant les impacts sur les ressources et performances du changement de runtime de conteneur, je vous invite à consulter l’étude d’impact de performance de gVisor.
Un cas d’école pour illustrer
Afin de mieux comprendre les impacts de l’usage des RuntimeClass, je vous propose de démontrer l’utilisation conjointe du runtime de conteneurs Kata Container (avec QEMU) et runc, et ceci par le biais du manager de conteneur CRI-O.
Le tutoriel qui suit nécessite minikube 1.7.2 et a été réalisé avec le driver VirtualBox 6.1.
Un peu de setup pour commencer
Si vous êtes comme moi sur MacOS il vous faudra sur votre poste minikube 1.7.2, VirtualBox 6.1 et la dernière version de kubectl.
Démarrer minikube avec CRI-O : $ minikube start --memory 6144 --network-plugin=cni --enable-default-cni --bootstrapper=kubeadm --disk-size=5GB --container-runtime=cri-o
Vérifiez que minikube est bien opérationnel : $ kubectl get nodes NAME STATUS ROLES AGE VERSION minikube Ready master 1h v1.17.2
et que CRI-O est bien le runtime par défaut : $ kubectl get node minikube -o jsonpath='{.status.nodeInfo.containerRuntimeVersion}' | awk -F '[:]' '{print $1}'
Cette commande devrait vous répondre cri-o.
Comme on va chercher à déployer des pods qui seront exécutés dans des sandbox virtualisées, vérifiez que votre minikube est bien capable de gérer la nested virtualisation : $ minikube ssh "egrep -c 'vmx|svm' /proc/cpuinfo"
> Si cette commande vous retourne 0, il vous faut activer la nested virtualisation au sein de la technologie exploitée par minikube.
Par exemple si vous utilisez comme moi VirtualBox, il vous faut arrêter minikube, puis activer la nested virtualisation avant de redémarrer minikube (cf. commande start avec CRI-O): VBoxManage modifyvm minikube --nested-hw-virt on
Au tour des déploiements
Maintenant que vous avez un minikube qui tourne avec CRI-O, vous pouvez installer le runtime d’exécution Kata Container.
Pour cela il vous faudra déployer un DaemonSet qui va s’occuper d’installer les binaires Kata Container sur chacun de vos workers (ici il ne devrait y en avoir qu’un seul : minikube).
Ce DaemonSet a besoin d’un ServiceAccount et d’un ClusterRoleBinding lui permettant d'interagir avec les workers :
--- apiVersion: v1 kind: ServiceAccount metadata: name: kata-label-node # Le nom du service account namespace: kube-system
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: node-labeler rules:
- apiGroups: [""] resources: ["nodes"] # On définit un rôle sur les nodes verbs: ["get", "patch"]
kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kata-label-node-rb roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: node-labeler subjects:
- kind: ServiceAccount name: kata-label-node # On bind le service account avec le rôle sur les nodes namespace: kube-system
La définition de ce RBAC est activable via cette commande: $ kubectl apply -f https://raw.githubusercontent.com/kata-containers/packaging/master/kata-deploy/kata-rbac/base/kata-rbac.yaml
Et ensuite on va déployer le DaemonSet : $ kubectl apply -f https://raw.githubusercontent.com/kata-containers/packaging/master/kata-deploy/kata-deploy/base/kata-deploy.yaml
> Ce DaemonSet peut prendre un certain temps à se mettre en place.
Pour vérifier que le DaemonSet est bien pris en compte par minikube, vous pouvez lister le répertoire /opt/kata sur votre VM minikube, et vous devriez avoir quelque chose de similaire à cela : drwxr-xr-x 5 root root 100 Feb 13 15:49 . drwxr-xr-x 4 root root 80 Feb 13 15:46 .. drwxr-xr-x 2 root root 300 Jan 16 01:59 bin drwxr-xr-x 3 root root 60 Jan 16 01:52 libexec drwxr-xr-x 6 root root 120 Jan 16 01:58 share
On peut désormais ajouter la RuntimeClass nous permettant de démarrer des workloads avec QEMU :
kind: RuntimeClass apiVersion: node.k8s.io/v1beta1 metadata: name: my-runtime-class # Le nom de cette RuntimeClass handler: kata-qemu-virtiofs # On indique quel handler Kata va exécuter le workload
Pour l’appliquer, il vous suffit de copier/coller les lignes suivantes :
$ cat <<EOF | kubectl apply -f - kind: RuntimeClass apiVersion: node.k8s.io/v1beta1 metadata: name: untrusted handler: kata-qemu-virtiofs EOF
Déployons mes bons !
C’est le moment de vérité, nous allons déployer deux pods : un classique qui va utiliser la RuntimeClass par défaut, l’autre avec notre RuntimeClass ‘untrusted’.
Nous allons nous appuyer sur une image busybox dans les deux cas.
Voici la commande pour le runtime d’exécution par défaut :
$ cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: busybox-trusted labels: app: busybox-trusted spec: containers:
- image: busybox command:
- sleep
- "7200" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always EOF
Et celui s’appuyant sur Kata Container et QEMU :
$ cat <<EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: busybox-untrusted labels: app: busybox-untrusted spec: runtimeClassName: untrusted containers:
- image: busybox command:
- sleep
- "7200" imagePullPolicy: IfNotPresent name: busybox-untrusted restartPolicy: Always EOF
On constate que la seule différence réside dans l’utilisation de la spécification runtimeClassName.
Après quelques secondes, vous devriez voir apparaître deux pods :
NAME READY STATUS RESTARTS busybox-trusted 1/1 Running 0 busybox-untrusted 1/1 Running 0
Prenons le temps de vérifier que nos pods ne sont pas exécutés de la même manière.
En tout état de cause on devrait avoir le même noyau entre minikube et le container dans le pod busybox-trusted, et un noyau potentiellement différent pour le container dans le pod busybox-untrusted.
Shell 1: $ minikube ssh $ uname -r → 4.19.88
Shell 2: $ kubectl exec -it busybox-trusted -- /bin/sh $ uname -r → 4.19.88
Ces deux commandes devraient renvoyer la même version du noyau, car le conteneur partage le même noyau que son hôte.
Shell 3: $ kubectl exec -it busybox-untrusted -- /bin/sh $ uname -r → 5.3.0-rc3
Cette commande - dans ma configuration - retourne une version de noyau différente de l’hôte (minikube) car la VM ne fait pas tourner le même noyau que l’hôte.
Vous pouvez aussi confirmer qu’au sein de la VM minikube il n’y a bien qu’une seule instance de Kata Container QEMU: $ minikube ssh $ ps -ef | grep /opt/kata/bin/qemu-virtiofs root 11898 11881 0 00:06:16 /opt/kata/bin/qemu-virtiofs-system-x86_64 -name sandbox...
Le mot de la fin
Il est temps de refaire surface, et de reprendre un peu de hauteur sur ce que l’on a pu voir ensemble.
Notre petit détour dans l’océan des CRI nous permet de constater qu’il n’existe pas qu’une solution pour isoler plus fortement nos applications.
Comme il n’est possible d’interfacer qu’un seul CRI par Kubelet, on a vu qu’on pouvait mixer les niveaux d’isolation au sein d’un même cluster grâce à certains CRI dédiés au management de runtime de conteneurs.
Toutes les implémentations de CRI ne prennent pas en compte une isolation forte, mais le caractère configurable et extensible de Kubernetes nous offre la possibilité de composer selon nos besoins.
Ainsi chacun peut choisir sa stratégie d’isolation:
- Quel niveau d'isolation souhaitons nous atteindre ?
- Doit-on appliquer le même niveau d’isolation pour toutes les applications en utilisant par exemple gVisor ?
- Isolons-nous seulement certaines applications choisies avec, par exemple, le couple CRI-O/Kata Containers ?
C’est à vous de voir, en tous les cas je vous recommande de ne pas ignorer ces questions d’isolation lorsque vient le moment de passer en production, et de mesurer les impacts tant en termes de performance que de consommation de ressources.
Si vous souhaitez aller encore un peu plus loin sur ce qu'offre la RuntimeClass, je vous propose de consulter cet article sur le blog Kubernetes mettant en avant un très bel exemple de mise en place d'une accélération matérielle de la terminaison TLS.