ScyllaDB vs Cassandra: towards a new myth?
Disclaimer : all the tests described in this article were performed on ScyllaDB 0.10 and might not be relevant for recent versions. For a more up-to-date description, go to the official website http://www.scylladb.com/
On September 22th 2015, a community of developers announced having designed and released a new database management system described as the fastest in the world. This system, named ScyllaDB is part of the NoSQL world whose ambitions are:
- Design scalable systems by distributing the workload and the storage over multiple machines.
- Design fault tolerant systems
- Provide higher throughputs, larger storage with lower latencies
In this very competitive environment, ScyllaDB presents an interesting characteristic: all its structures and mechanics are copied from the very popular database: Cassandra. Main difference announced: ScyllaDB is written in C ++ when Cassandra is in Java.
Using the same structures allows for the users to use any of those two managers indifferently in their cluster. Cassandra developers don’t need to rethink their data structures and can apply them directly to ScyllaDB. The learning curve is reduced to a minimum for regular Cassandra users.
The first tests made by the ScyllaDB team report rates from 10 up to 20 times higher than Cassandra. Thus, they present themselves as a direct competitor.
All this just moving from Java to C++ ?
Not only. The advantage of having an application written in C ++ is actually to reduce CPU usage by avoiding the program to be loaded into a JVM. Scylla also provides a custom network management that minimizes resource by bypassing the Linux kernel. No system call is required to complete a network request. Everything happens in the userspace, limiting the number of expensive switches with the kernel space.
Another advantage with C++ is the ability of having a finer but more complex memory management. Indeed, in Java, the garbage collector takes care of regularly browsing the allocated memory to release the unused space. This step is extremely costly in terms of processor cycles and it can stop the application up to several seconds on large memories, it is also known as “stop the world”.
Although these times of garbage collection tend to decrease with new, more efficient algorithms, it is now recommended not to allocate more than 8GB of memory to the JVM when running Cassandra, even if your machine has over 100 GB of memory (something more and more common with the decrease in the cost of RAM). ScyllaDB boasts to fully use the hardware resources of your machines. In particular, when Cassandra is primarily based on caching offered by the operating system, a new cache system specific to Scylla was set up to compress and store recently read data in memory.
Our tests
Following these attracting statements on paper, we wanted to get to the bottom and check by ourselves, to see if the facts would finally concur with the theory. Scylla's ambitions maysound too great to be true: having a 10 fold faster database without having to change anything in hardware and code, as claimed by the homepage of the site scylladb.com (see image below).
scylladb.com : according to their website, it would be possible to stop Cassandra and to start Scylla without any problem on any machine of the cluster, and then multiply our throuhput by 10
We ran some tests on Amazon Web Services EC2 following the guidance we found on ScyllaDB website. It provides an image (AMI) to be loaded on an EC2 instance, on which Scylla is already fully installed on Fedora 22 OS.
First test
We set up three clusters :
- A 3 nodes ScyllaDB cluster
- A 3 nodes Cassandra cluster
- 12 shooter nodes that stress the two clusters sending requests for a short period of time
All Scylla and Cassandra nodes use the same type of instance the same machines: m3.xlarge.
All Shooters nodes are also the same: c3.8xlarge.
The ScyllaDB cassandra-stress tool is used to benchmark the clusters. We got the following results, more detailed in the table below:
- 215,000 writes/second on ScyllaDB
- 113,000 writes/second on Cassandra
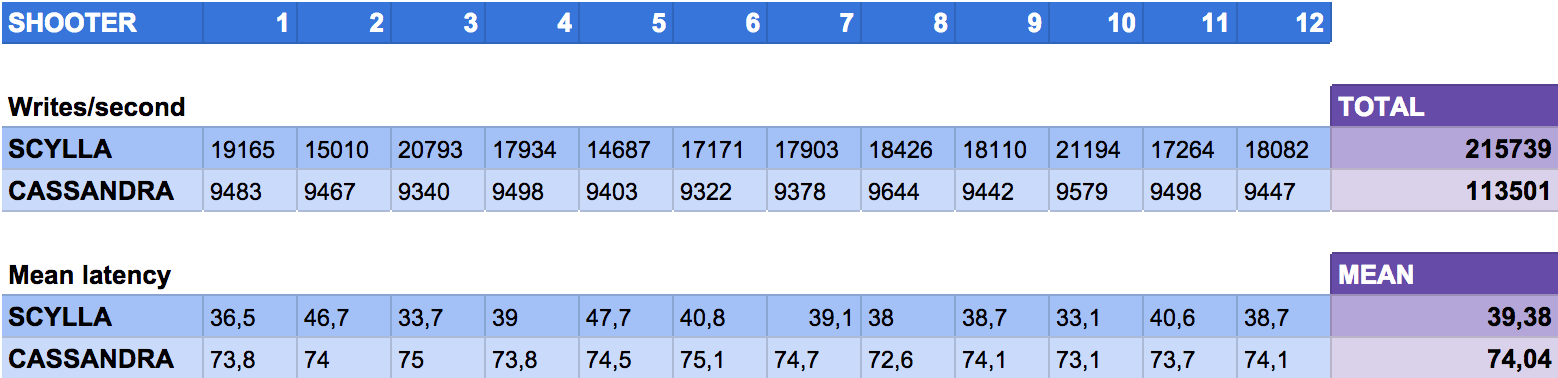
First comment: Scylla is sharply better than Cassandra at write throughput and write latency.
Some cautions, however:
- Scylla runs on Fedora and Cassandra runs on Ubuntu
- We used pre-configured AWS AMIs without modifying them
Second test
We decided to leave these results besides and realize new tests. This time:
- Scylla and Cassandra run on the same machines, on Fedora and with a 10Gbit network.
- We have now 17 shooters
- We used default configurations
The goal of this second test is to push Scylla to its limit to check the maximum throughput it can handle.
And the result was surprising: Scylla can’t handle the throughput and only returns timeouts to the shooters, this means that the load is not absorbed. When reducing the number of shooters, we actually get back a great throughput without any timeout. Indeed, Scylla can’t handle the load whereas Cassandra doesn’t have any problem under high loads: when Cassandra is overloaded, the shooter’s throughput automatically decreases (because queries are synchronous) without any timeout. This means that Cassandra successfully pulls up the pressure to clients. In Scylla’s case, we’re exposed to tuples loss when we query it at a throughput that is over its limit.
In retrospect, when having a closer look at the results of the first test (see table above), we also note higher performance disparities on Scylla than on Cassandra:
- On write latency, there is a 11% standard deviation on Scylla, against 1% on Cassandra
- On write throughput, there is again a 11% standard deviation on Scylla, against 1% on Cassandra
The standard deviation allows us to characterize the database management systems’ stability. In our case, Scylla seems really less stable than Cassandra. This means that besides the doubts on its capability to adapt to high loads, it can be tricky to precisely predict a Scylla’s cluster performances.
We should obviously investigate further on these instabilities to establish their causes. Moreover, the tests should be run several times on correctly configured machines to be worthly benchmarks. Nevertheless, they allow us to have a preview on Scylla’s potential and status.
Beyond those experimental notes, we can notice several things about Scylla:
- Scylla uses CQL 3.0 (against CQL 3.2 for Cassandra 2.1 and CQL 3.3 for Cassandra 2.2) as query language. The CQL ALTER function is currently not supported, like counters that have not been implemented yet. Because of this, Scylla’s cassandra-stress is slightly different from Cassandra cassandra-stress. The Cassandra version of this tool doesn’t work with Scylla.
- Scylla uses its own gossip protocol between nodes, that makes impossible to run a cluster containing both Cassandra and Scylla nodes.
- Scylla doesn’t support SSL secured communication yet (node to node and node to client).
Conclusion
The results we draw from these experiences are that it is possible to improve Cassandra’s performances with a finer memory management and by saving some processor cycles. Scylla seems to handle a throughput at least 2 times higher than Cassandra can (let’s recall that Scylla’s team announces a 10 factor). However, the program is far from Cassandra’s state of maturity and Scylla currently misses many essential features. Today, Scylla is in beta version and further tests should be made after its first stable release that is planned in January 2016, so we can assess this new competitor’s seriousness.
Will Scylla preserve its advance in terms of latency when it will be more stable and it will have implemented all of the missing features? Moreover, Cassandra is a proven technology, running on clusters containing more than 1000 nodes (see this presentation). Will Scylla be able to reach such a level of maturity?
Thank you OCTO guys for having contributed to this article.