Scribe : a way to aggregate data and why not, to directly fill the HDFS?
HDFS is a distributed file system and quickly raise an issue : how to fill this file system with all my data? There are several options that go from batch import to Straight Through Processing.
- Bulk load style. The first one is to keep collecting data on local file system and importing them by vacation. The second one is to use an ETL. Pentaho has announced support of Hadoop for Data Integration product. The first tests we conducted lead us to think this works much better to extract data from Hadoop (using Hive) than to import data. Yet this is just a matter of time before Pentaho fixes the few issues we encountered. The third one is to use solution like Sqoop. Sqoop extracts (or imports) data from your RDBMS using Map/Reduce algorithm. I hope we will be able to talk about that solution very soon.
- Straight Through Processing style. In that domain, you can look at solutions like Flume, Chukwa (which is part of Apache Hadoop distribution) or Scribe. In brief, you collect and agregate data in a more STP style, from different sources, different applications, different machines. They globally work the same way than Scribe but solutions like Flume or Chukwa provide more connectors than Scribe in a sense you can, for instance, “tail” a log file etc etc...Chukwa is also much easily integrated with the “Hadoop stack” than what Scribe could be.
Scribe : a kind of distributed collector
Scribe has been developed and “open sourced” (as many other projects) by Facebook. The installation is not that simple (should I say tricky?) but Scribe is massively used at Facebook : a proof it works and it is worth fighting with compilation problems or the miss of RPM packages (in the meantime, maybe there is one but I have not noticed it).
Scribe collects messages, not in a reliable way but is designed for failure
Scribe has a simple way of logging information. A scribe server collects data represented as a category and a message. As an example.
LogEntry entry = new LogEntry(“crash", “app has a crash|userid|input parameters|....”);
Scribe can be viewed as a collection of processes, running on different machines and listening to a specified port, in which you can push data (so a category and a message) using Thrift API. For each category, you then define Stores which are the way the data will be stored or broadcasted to different and remote Scribe processes. There are different available stores but the most common are file - writes to a file - or network - sends messages to another scribe server -. You can thus define different Stores for different categories and then route your messages based on that category.
Scribe is resilient in the way you can define primary and secondary stores : the secondary stores will be used to fail-over the first one and retries (ie. resending the messages from the secondary store to the primary store) are automatically managed by Scribe.
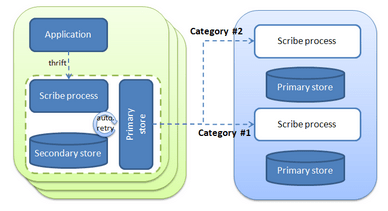
There is yet a couple of things for which Scribe is not reliable. If the Scribe process on the client machine (in green in the above schema) is down, messages will be lost (and your code should be resilient). Moreover Scribe process can buffer, in memory, messages for a time interval. Thus, in case of failure, all these buffered messages will be lost.
So Scribe is maybe not the tool you need depending on the message reliability you must guarantee.
Scribe configuration sample : different (backuped) stores for different categories
Here is an example of the Scribe configuration (.conf file) :
# This file configures Scribe to listen for messages on port 1464 and
# attempt to forward all messages to another Scribe instance on port 1463.
# If Scribe is unable to forward the messages to port 1463, it will buffer
# them on disk and keep retrying.
port=1464
max_msg_per_second=2000000
check_interval=3
# DEFAULT - forward all messages to Scribe on port 1463
<store>
category=default
type=buffer
target_write_size=20480
max_write_interval=1
buffer_send_rate=1
retry_interval=30
retry_interval_range=10
<primary>
type=network
remote_host=localhost
remote_port=1463
</primary>
<secondary>
type=file
fs_type=std
file_path=/tmp/scribetest2
base_filename=thisisoverwritten
max_size=3000000
</secondary>
</store>
More details concerning Scribe configuration is available here. Yet, Interesting elements are : - the port the Scribe process is listening to (1464 in our example) - the primary and secondary defined stores. The primary store broadcast messages to another Scribe process (listening on port 1463). The secondary one stores messages on the local file system (in case the former is unavailable).
Starting Scribe agents on the client machines
Starting a Scribe process is quite simple once Scribe is set up
scribed -c path_to_conf_file.conf
You must so define a configuration file on the different Scribe agents you will start. The above configuration starts a scribe server on port 1464 and forwards all the messages to the primary store (another Scribe process listening on the same host but on port 1463). In case the primary store is not available, to the secondary defined store (a local file system) will be used.
When you launch Scribe (on the client machine), you get the following logs (I know there is only on configured store logged but it works) : 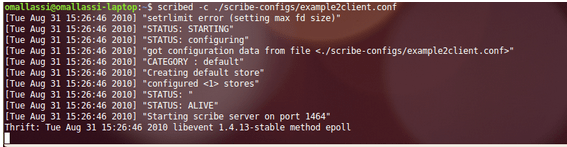
Starting Scribe as a central service
On the central Scribe Server, you run the same process but with different configuration file. In this sample, you simply write the messages to the local file system in /tmp/scribetest
port=1463
max_msg_per_second=2000000
check_interval=3
<store>
category=default
type=buffer
target_write_size=20480
max_write_interval=1
buffer_send_rate=2
retry_interval=30
retry_interval_range=10
<primary>
type=file
fs_type=std
file_path=/tmp/scribetest
base_filename=thisisoverwritten
max_size=1000000
</primary>
</store>
Play with the beast...
Of course the idea is to use Scribe from your application code. In that case, you must generate code based on the thrift interface. Yet, a simplest way to test your configuration is to use the provided python script (in the example folder of your distribution) named scribe_cat (You need to define the constant export PYTHONPATH=/usr/lib/python2.6/site-packages/). This script opens a connection to a Scribe server and publishes the message in stdin on the specified category (here it is default) echo “my message” | ./scribe_cat default
Go and check your log files to see if it works...
Using Scribe to log in HDFS
The default Scribe compilation does not enable direct logging to HDFS : the mystery of the compilation...So you need to (re)compile Scribe with the --enable-hdfs option. Once done, you can use Scribe to directly push data into HDFS :
port=1464
max_msg_per_second=2000000
check_interval=1
max_queue_size=100000000
num_thrift_server_threads=2
# DEFAULT - write all messages to hadoop hdfs
<store>
category=default
type=buffer
target_write_size=20480
max_write_interval=1
buffer_send_rate=1
retry_interval=30
retry_interval_range=10
<primary>
type=file
fs_type=hdfs
file_path=hdfs://localhost:9000/scribedata
create_symlink=no
use_hostname_sub_directory=yes
base_filename=thisisoverwritten
max_size=1000000000
rotate_period=daily
rotate_hour=0
rotate_minute=5
add_newlines=1
</primary>
<secondary>
type=file
fs_type=std
file_path=/tmp/scribe-central-hdfs
base_filename=thisisoverwritten
max_size=3000000
</secondary>
</store>
The main differences, in the configuration file, are the fs_type (which is not set to std but to hdfs) and so the file_path (which is set to the hdfs file). Before running your Scribed process and logging data to HDFS, you need to set up your CLASSPATH variable with some Hadoop jars (as described here ). Then you can start Scribe and broadcast messages : 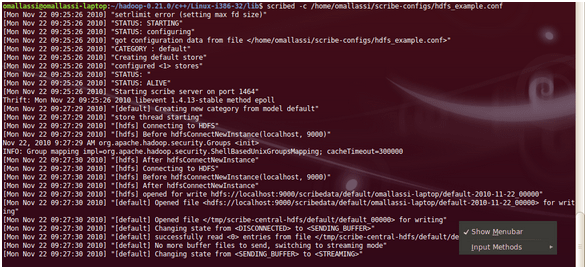
And if you look at your HDFS, you will see the broadcasted messages :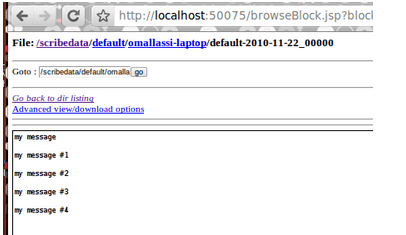
Data seems to be buffered by the Scribe process in a way messages are not displayed in the HDFS web console until either you kill the scribed process or you change the configuration to roll out files more frequently. For instance you can decrease the max_size parameter (take car HDFS is not reliable with small files) to get the following screen shot : 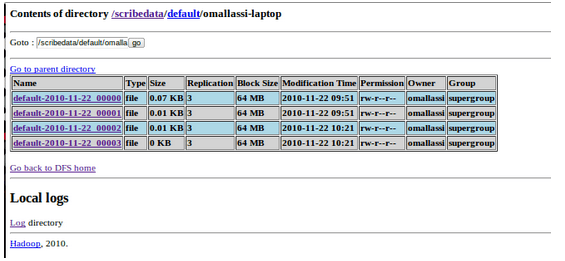
To conclude
Thus, Scribe is just a way to aggregate and collect data (as syslogNG could do) from several machines, several sources into a central repository that can be HDFS. This can moreover be interesting if you add, upon HDFS, Hadoop to be able to analyze all these data. Then and with all the previous articles, you have set up the following stack :
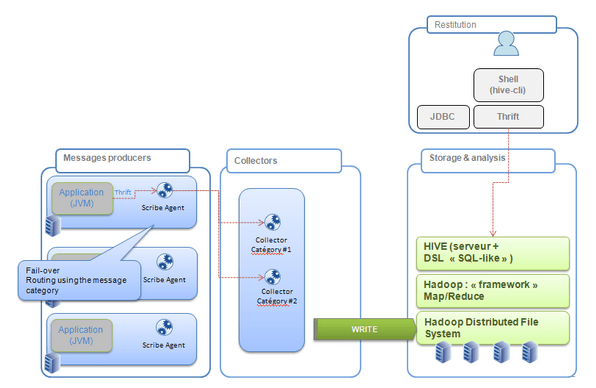
Moreover, there are still a couple of things we should have the opportunity to talk about. The first one is to integrate Scribe to the Java world (and for instance generate the Thrift client API for Java and, why not use a log4j appender. The second one is to integrate the data you have logged into Hive ...