Scaling Kaizen : réduction du volume d'incidents à l'échelle
Scaling Kaizen : la démarche
Dans un précédent article nous avons expliqué la démarche innovante Scaling Kaizen mise en œuvre chez un de nos clients, pour pouvoir déployer cette démarche d’amélioration continue, inspirée de Toyota, au sein d’une DSI de plus de 300 personnes.
Nous y avons décrit les éléments clés de cette démarche : l’utilisation du A3 comme support ; la notion de cercle Kaizen qui permet à des binômes représentant des équipes de réfléchir régulièrement ensemble et de partager leurs enseignements, alors qu’ils travaillent sur une problématique analogue ; et enfin la notion de saison qui permet de faire avancer l’ensemble de l’organisation dans l’amélioration sur un même rythme.
Cette démarche nous a permis de passer de quatre ou cinq équipes accompagnées par an à une cinquantaine, avec, dans une grande majorité des cas, des résultats significatifs sur la performance opérationnelle, qu’il s’agisse des délais, de la qualité, du delivery (livraison de correctifs ou de nouvelles fonctionnalités, ou encore de la satisfaction client). Ces sujets d’amélioration sont en lien avec les OKR de la DSI, OKR déclinés ensuite au niveau de chaque domaine.
Sur les quatre saisons de cette première année, 50 équipes ont été accompagnées dans la démarche Kaizen et 20 d’entre elles étaient concernées par ce sujet de réduction du volume entrant d’incidents (sujet de qualité, donc). L’objectif de cet article est de montrer dans le détail comment cette démarche nous a permis d’avancer pour obtenir des résultats significatifs.
Une introduction est proposée pour rappeler l’organisation du Support, introduction que les personnes connaissant le sujet peuvent passer.
Il n’y a pas de silver bullet : aussi la lecture de ce texte peut sembler un peu laborieuse alors que nous détaillons avec précision les causes identifiées et les contre-mesures expérimentées sur le terrain. Aussi, pour chacun des sujets traités, vous trouverez une synthèse du problème de ses causes, des contre-mesures et des résultats.
TL;DR
En déployant le Kaizen dans une DSI d’environ 300 personnes, nous sommes parvenus à une réduction de 24,7% du volume entrant d’incidents sur les cinq premiers mois de l’année 2025 par rapport à l’année précédente.
20 binômes, représentant 20 équipes, ont été engagés dans cette démarche parmi les 50 concernées par ce déploiement Kaizen en 2024. Le dispositif étant structuré autour d’ateliers récurrents de 1h30 sur 8 semaines, cela représente un investissement total de 60 j/h : (8x1h30 x 2 personnes x 20 équipes = 480h), auxquels il faut ajouter l’investissement de l’équipe Lean : 3 ETP sur l’année x 2/5 (20 équipes / 50 sur ce thème) de la charge. Ce qui nous donne approximativement un total de 1.5 ETP par an pour ce qui est de l’investissement pour ce seul sujet de réduction du volume entrant.
Une estimation théorique et approximative du gain correspondant nous amène aux environs de 105K€/mois, soit un peu plus de 1 M€ par an (en prenant en compte les mois d'août et décembre qui ont une volumétrie moindre). Cette estimation mensuelle est basée sur :
- la distribution du volume de ticket, le ratio de tickets traités par le N1 et le N2/N3
- le coût fixe unitaire des tickets N1 et une estimation rapide (1j/h) de la charge de correction des incidents au niveau N2 ou N3.
A cela, il faut bien évidemment ajouter une amélioration de la satisfaction client grâce à la réduction significative de ces incidents ou la capacité de traiter en autonomie un problème (eg. mis à jour mot de passe).
Organisation du support : rappel
Le fait que le support arrive tout au bout de la chaîne de valeur lui fait souvent être déconsidéré par les directions tech et parfois expédié par ce que Edgar Schein appelle la culture de l’ingénierie (“On va le remplacer par une IA”) . D’un point de vue Lean, cette situation unique dans la chaîne de valeur (tout au bout du processus et au contact direct avec le client) lui donne au contraire beaucoup de valeur car il s’agit là du meilleur endroit pour évaluer la performance du processus.
Les sollicitations au support peuvent prendre deux formes : des demandes (ex : activer un compte, répondre à une question applicative ou un traitement particulier etc …) et des incidents. Dans le cadre de ce sujet nous ne nous concentrerons que sur les seconds.
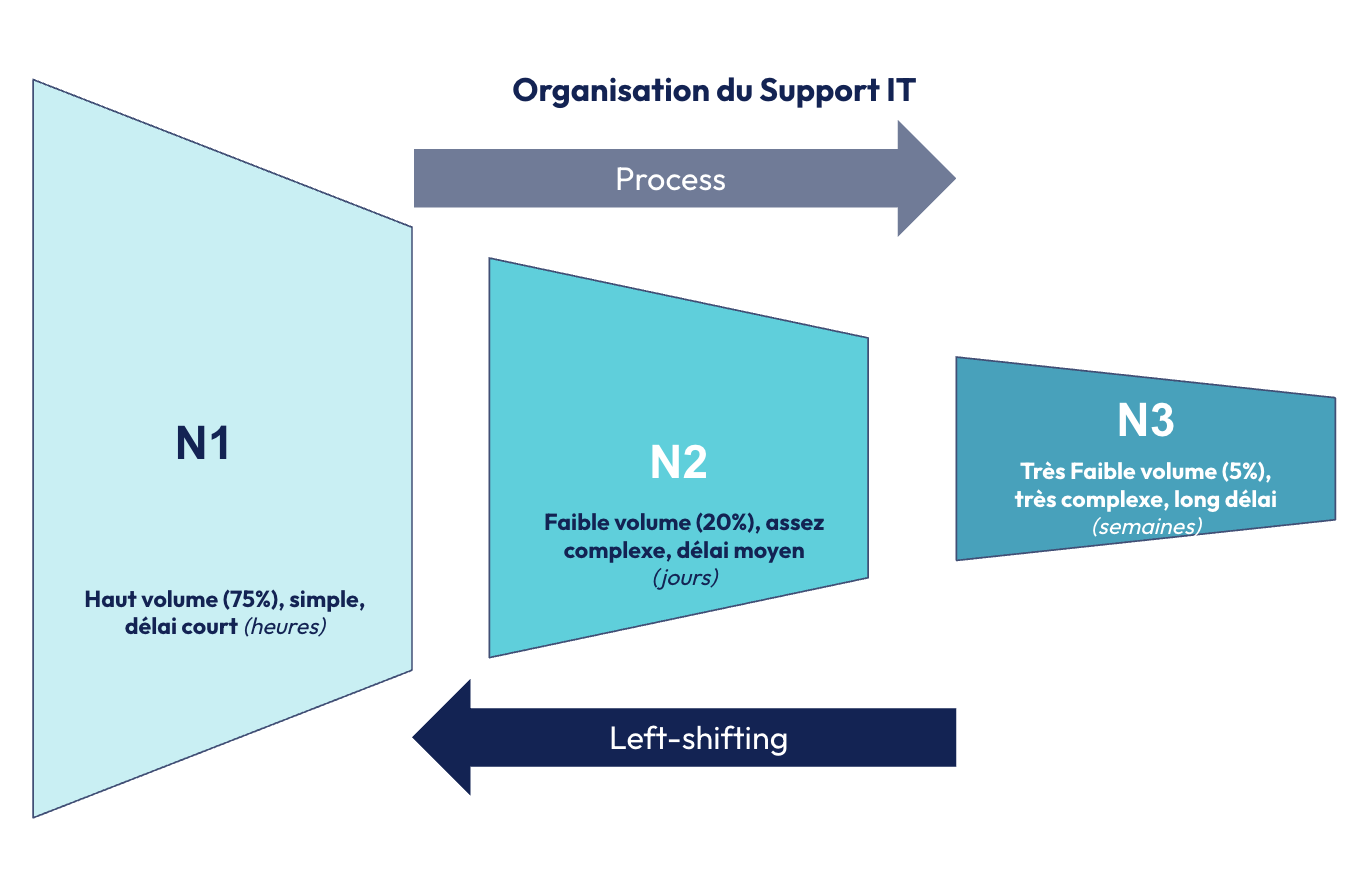
Pour gérer ces incidents, les directions du Numérique structurent souvent l’activité du support dans une forme d’entonnoir, avec dans la plupart des cas, trois niveaux :
· Le niveau 1 (N1) : résolution rapide (de 5 à 7 minutes) du plus gros volume de problèmes (aux alentours de 80%), dans la plupart des cas liés à la bureautique : accès au compte Microsoft (Active Directory) ou compte Google ; sujet lié aux systèmes d’impression ; support lié au téléphone mobile professionnel, etc … Sur ce niveau, il n’y a pas besoin d’expert : des techniciens de support peuvent, dans la plupart des cas, traiter rapidement (quelques minutes si ouvert au téléphone, quelques heures si ouvertes sur le portail par l’utilisateur) le problème.
· Le niveau 2 (N2) : il s’agit en général de sujets liés aux applications métier, qui doivent être traités par des experts fonctionnels. Ces incidents, moins fréquents (environ 20% du volume), souvent complexes, prennent davantage de temps de résolution (quelques jours) et ont un impact métier significatif. Le niveau N1, qui n’a pas les compétences pour le traiter, doit s’assurer que toutes les informations nécessaires à une résolution rapide sont bien renseignées par l’utilisateur. Le support N2 peut aussi gérer des problèmes plus simples mais qui nécessitent un niveau d’habilitation élevé que ne peut pas avoir le N1, souvent externalisé. A titre d’exemple, on peut évoquer des sujets liés à la sécurité (tels que la configuration d’outil comme Keycloack) ou encore aux réseaux (bastions, etc…).
· Le niveau 3 (N3) : ces problèmes sont passés par le N1 puis le N2 et nécessitent une correction d’anomalie ou une nouvelle évolution. Ils sont donc pris en charge par une équipe de développement et requièrent un temps de résolution qui peut se compter en semaines (à moins d’un niveau d’impact et d’urgence élevé qui peut lui requérir une résolution en quelques jours).
Je ne saurais trop recommander la lecture du brillant ouvrage « L’obsession du service client » de Jonathan Lefèvre pour vous donner une vision drôle et très concrète de ce qu’est l’excellence dans ce métier du support dans une entreprise de la tech, leader sur le sujet. Voir l’entretien avec Jonathan dans Culture Kaizen ou sur ce lien.
Le left shifting
Dans leur ouvrage « The Best Service Is No Service » David Jaffe and Bill Price (premier Customer Service VP chez Amazon) expliquent que le meilleur support est celui dont le client n’a pas besoin. Une phrase reformulée par Jeff Bezos « The best customer support is none. ». Dans cet ouvrage, les auteurs rappellent « qu’il est important de voir le client comme nous nous voyons nous-mêmes, pas comme des numéros » (ou comme des personas pourrions-nous compléter).
Dans cet entonnoir qui va du client au N1, puis au N2, puis au N3, la stratégie pour mettre en œuvre cette vision du no support est celle du left-shifting. Cela correspond à donner plus d’autonomie au niveau en amont (le N1 pour le N2 ; le client pour le N1) pour traiter sa demande.
Réduire le volume d’incidents : stratégie mise en oeuvre
La toute première chose que nous recherchons avec le Lean est de satisfaire le client. Et dans cette démarche nous souhaitons commencer par réduire son insatisfaction. Qu’importe aux utilisatrices et utilisateurs que l’on propose telle nouvelle fonctionnalité “innovante”, si pour les fonctionnalités les plus utilisées, il demeure des problèmes rendant leur expérience pénible. C’est pour cette raison que nous décidons de démarrer avec le N2 : il répond à des incidents liés aux applications métier, avec un impact direct dans les activités opérationnelles des collaborateurs des métiers.
Nous lançons donc dans le cadre de notre déploiement Kaizen plusieurs cercles liés à cette thématique de réduction du volume entrant d’incidents. Chaque cercle comprenant 3 ou 4 équipes, représentées chacune par un binôme au sein du cercle, cela nous permet de traiter ce sujet avec 19 équipes pendant les quatre saisons de la première année.
Organisation d’un Cercle Kaizen
Nous vous proposons dans un premier temps quelques thématiques communes de Kaizen menées pour réduire le volume au N2. Dans un second temps, nous verrons comment nous avons pu mener ce type de sujet au N1.
Réduire le volume d’incidents N2
Réduire le nombre de régressions dues à la durée des branches de développement
La première stratégie consiste à travailler sur la cause racine et d’éliminer l’incident.
Contexte
Exemple avec cette équipe de développement d’une solution de présentation de données métier. Le problème de cette équipe est un taux élevé de régressions. Avant le Kaizen, l’équipe a mis en place un système de revue de code plus approfondi pour résorber ces régressions. Cela lui a permis de réduire le ratio d’incidents par livraison mensuelle de 100% (une par projet intégré dans la livraison) à 86% (18 pour 20 projets).
Causes
Comme de nombreuses équipes de développement, celle-ci utilise des “branches” : chaque développeur va ainsi créer une branche de développement à partir du référentiel commun (le “tronc”) pour pouvoir travailler sur un référentiel immuable, puis une fois son développement terminé, va le réintégrer au tronc et à tous les développements qui y ont été reportés depuis qu’il a fait sa branche. Vu depuis la perspective Lean, il s’agit d’un gaspillage de type Transport : on transporte le produit - du code - sans le transformer ni lui apporter de la valeur.
Plus la durée de vie de sa branche sera longue, plus il devra réintégrer un volume important de nouveaux codes. Cette augmentation de complexité de réintégration n’est pas linéaire avec le temps mais exponentielle comme le montre cet article référence de Martin Fowler sur le sujet. Aussi réduire le temps de ces branches devient un sujet clé.
Jusqu’alors l’équipe a aussi avancé sur ce sujet en passant de 150 jours à 50 jours, ce qui est déjà remarquable. L’équipe est persuadée qu’elle ne peut pas descendre en-deçà. Nous regardons donc l’en-cours des tickets pour voir les branches les plus longues (i.e. supérieure à 20 jours). Et en faisant cet exercice sur une dizaine de tickets, l’équipe réalise que 80% des tickets les plus anciens (et donc les branches les plus longues) ne sont pas sur des tickets de développement mais sur des tickets de corrections d’anomalies.
En regardant les dernières régressions, elle constate aussi que celles-ci ont été introduites pas des commits (des réintégrations sur le tronc) de corrections d’anomalies. Nous creusons alors encore pour comprendre les causes et l’équipe se rend vite compte que si ces tickets de corrections d’anomalies sont si long ce n’est pas en raison du développement (une ou deux journées), mais en raison des tests. Nous trouvons ainsi 5 tickets sur 8 qui ont attendu 15 jours en test. Nous demandons alors aux testeurs pour quelle raison, et ils nous expliquent que c’est pour donner la priorité aux tests sur le développement. Nous demandons enfin si ces corrections d’anomalies sont longues à tester, et ils répondent qu’elles sont en général bien plus courtes que celles des développements.
Contremesures
L’équipe décide donc de tester les corrections d’anomalies faciles en premier afin de réduire la durée des branches.
Résultats
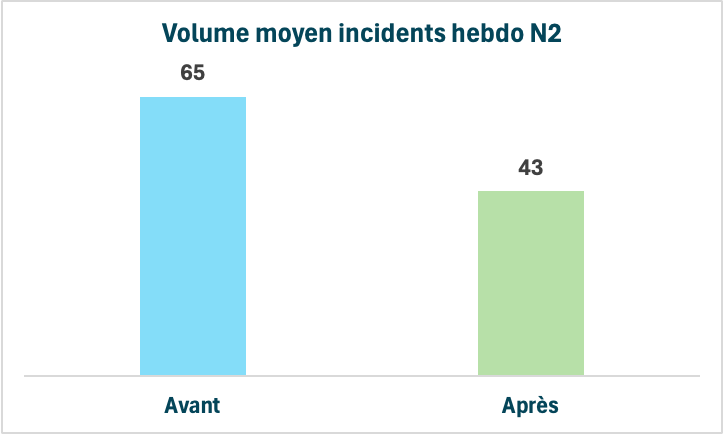
L’équipe passe ainsi de 50 à 25 jours en moyenne sur la durée des branches et de 86% à 44% sur le pourcentage d’incidents par projet intégré dans la release. Et le volume d’incidents par semaine passe lui de 65 en moyenne à 43 (une réduction de 28% de la non-qualité).
Il reste encore du chemin à parcourir, mais l’équipe a déjà fait un premier pas en comprenant mieux à quelle étape de son processus elle créait des attentes qui causaient des problèmes de qualité.
Synthèse du sujet :
- Problème : 65 incidents ouverts sur le N2 par semaine
- Cause principale : durée des branches sur les corrections d’anomalies car les tickets attendent entre 10 et 20 jours pour être testés
- Contre-mesure : tester les tickets de corrections d’anomalies au plus vite pour réduire la durée des branches et la complexité de réintégration sur le tronc
- Résultat : réduction de 50 à 25 jours de durée de vie moyenne des branches et de 27.7% des incidents hebdos, de 65 à 43.
Réduire le volume d’incidents grâce à une meilleure intégration applicative
Dans cette entreprise Energy & Utilities, la complexité des processus métiers implique une complexité dans l’intégration d’applications. Nous avons ainsi mené plusieurs sujets de réduction du volume d’incidents en travaillant sur cette meilleure intégration applicative.
Contexte et problème
Dans notre premier cas, nous travaillons sur une application mobile qui permet aux agents terrains de gérer les statuts et compte-rendus des interventions qu’ils doivent effectuer. Ces interventions sont planifiées dans un autre outil par les managers locaux, outil qui vient d’être migré d’une application mainframe à une autre, à l’architecture plus ouverte et plus récente. Le problème est qu’il peut arriver que le statut de l’intervention soit différent dans le système central de planification et dans l’application mobile. La semaine de lancement du Kaizen, ce problème s’est produit sur 279 interventions sur 43977 interventions (soit à 0,6% en écart). Il s’agit d’un irritant pour les agents avec un impact métier (opération et facturation) significatif.
Causes
L’analyse sur les échantillons en erreur de la semaine montre les causes suivantes :
- Un code agent incorrect dans l’application centrale (défini sur plus de 6 caractères), dans deux régions spécifiques;
- Mauvais code envoyé par l’application mobile à l’application centrale dans le web service de changement de statut ;
- Certains agents n’ont pas mis à jour leur application mobile et utilisent une version obsolète ;
- Le batch de nuit de recyclage des interventions dans l’application mobile a recyclé des interventions clôturées
En faisant des entretiens auprès des managers locaux des régions concernées, qui ont déclaré des agents avec un mauvais code, on se rend compte que ceux-ci ont fait ainsi pour identifier facilement les agents qui travaillent sur un secteur très spécifique. L’information sur le caractère obligatoire de la nomenclature du code agent ne leur avait pas été correctement donnée. On réalise aussi que certains agents qui sont des prestataires externes à durée déterminée pour aider ponctuellement sur des périodes de forte charge ont vu leur compte désactivé dans l’application centrale après la planification de l’intervention.
Contremesures
Pour traiter ces causes, plusieurs contre-mesures sont mises en place :
- Mise à jour des comptes dont le code agent est supérieur à 6 caractères ;
- Ajout d’un règle explicite dans le formulaire de création de nouvel agent dans l’application (ce qui n’était pas nécessaire avant la migration) ;
- Correction de l’anomalie sur le mauvais code envoyé dans le web service ;
- Ajout d’une pop-up dans l’application mobile pour s’assurer que l’agent télécharge la bonne version de l’application.
Résultats
Après huit semaines et au terme de ce Kaizen, nous sommes passés de 279/43799 à 203/44022 soit une réduction de 23% en absolu et un passage de 0,6% à 0,46% en relatif. Surtout, l’équipe a pu voir le Kaizen en action : plutôt que des grandes et risquées ré-architectures des applications mobile et centrale (coûteuse pour résoudre tous les problèmes), l’équipe a vu l’intérêt de procéder par petits pas sur des petits sujets spécifiques et se sent davantage en capacité de traiter ce sujet métier avec cette stratégie.
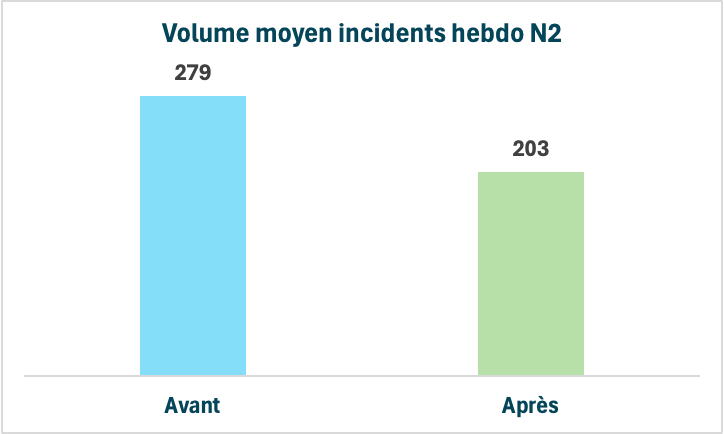
Synthèse du sujet :
- Problème : 279 interventions en écart
- Causes principales : des codes agents non compatibles entre les deux systèmes ; code incorrect envoyé dans un web service ; version obsolète sur une application mobile.
- Contre-mesure : correction des codes agents et ajout d’une vérification dans le formulaire permettant d’ajouter un nouveau code agent ; correction d’un code action dans un web service ; pop-up dans application mobile pour mise à jour avec une version compatible.
- Résultat : réduction de 23% du nombre d'interventions en erreurs (de 279 à 203).
Left-shifting au niveau en amont
Contexte
Troisième cas de réduction d’incidents au N2 est celui du left shifting à savoir d’aider le processus amont (en l'occurrence le N1) à être autonome pour régler le sujet sans avoir à solliciter le N2. Cette approche revêt plusieurs avantages. Tout d’abord cela permet de répondre plus rapidement à la demande client et parfois même en temps réel alors que le N1 discute par téléphone avec l’utilisatrice ou l’utilisateur. Dans un second temps, ce traitement est alors à un coût moindre.
Problème et causes
Dans notre cas, une des applications mobiles peut avoir des problèmes d’authentification, de synchronisation avec l’application centrale ou avec une autre application mobile utilisée par les agents. Il s’agit de problèmes qui entrent dans un de ces deux cas :
- Le problème n’a pas pu être reproduit par les équipes de développement pour le traiter (les agents pouvant se trouver momentanément dans un espace sans réseau à un instant du processus).
- Le problème nécessite une correction complexe qui va prendre du temps à être mise en œuvre.
Contremesures
Pour ces deux cas, l’équipe niveau 2 a mis à disposition au mode opératoire qui permet au N1 de :
- Bien caractériser le cas d’erreur en questionnant au téléphone l’utilisateur qui a le problème ;
- Accompagner ce dernier dans un parcours assez rapide pour résoudre le problème, apprendre à l’identifier à l’avenir et à devenir autonome pour le traiter.
Ce travail nécessite non seulement la rédaction du mode opératoire mais aussi l’accompagnement du N1 : échanges pour le présenter et éventuellement l’améliorer puis le développer avec l’ensemble des personnes de ce niveau 1. Ce travail prendra du temps ce qui implique qu’au terme du Kaizen il n’y aura pas de résultat sensible.
Résultats
Deux mois plus tard (au terme de la saison suivante) :
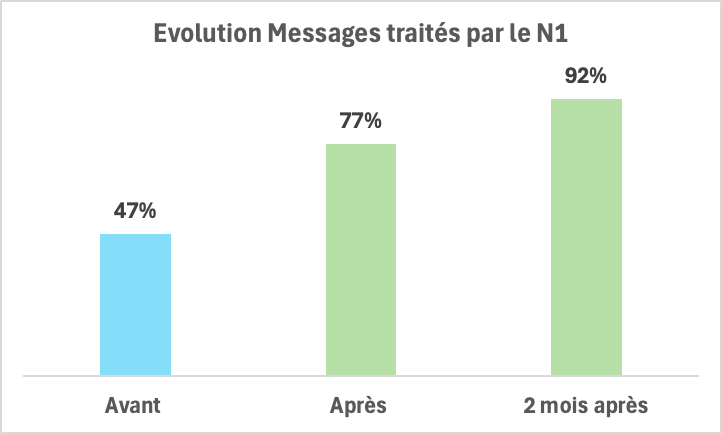
- Le taux d’incidents traités par le N1 sur cette application est passée de 47% à 77% puis à 92% encore deux mois plus tard ;
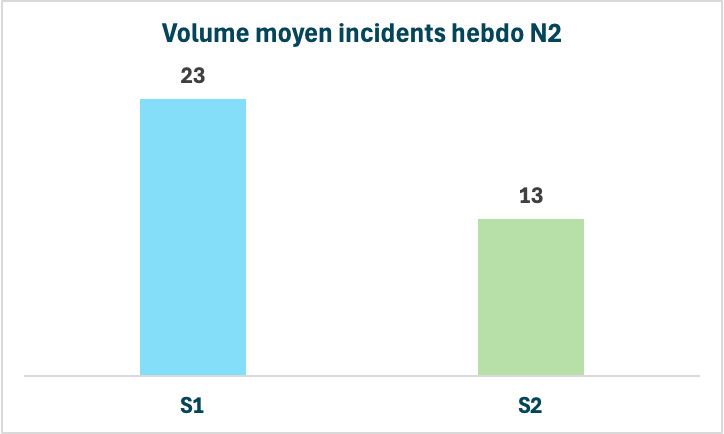
- Le volume hebdomadaire moyen d’incidents remontés au N2 est passé de 23 sur le premier semestre (le Kaizen a eu lieu en mars/avril) à 13 sur le deuxième semestre, soit une réduction de 43% d’un semestre à l’autre. Ce qui permet de libérer de la disponibilité des experts métier pour les projets, car moins sollicités par le support.
Synthèse du sujet :
- Problème : seulement 47% des incidents ouverts sont traités par le N1
- Causes principales : des incidents liés à des problèmes de connexions et d’authentification que le N1 ne sait pas traiter.
- Contre-mesure : définition d’un mode opératoire et accompagnement du N1 dans leur montée en compétence pour accompagner les utilisateurs dans la résolution de ce problème.
- Résultats : passage de 47% à 92% d’incidents traités par le N1 (gain de 45 points). Réduction de 43% d’incidents arrivant au N2 de 23/semaine à 13/semaine.
Réduire le volume entrant au N1
Contexte
Si traiter le sujet du volume d’incidents N2 est celui qui a le plus d’impact en termes de satisfaction client (bloquant sur le métier, peut prendre quelques jours à être résolu) et de coûts (le coût de traitement d’un incident au N2 est entre 5 et dix fois plus onéreux qu’un traitement au N1, l’attente du client en plus), traiter les incidents qui surviennent au seul niveau N1 est celui qui a le plus d’impact sur la volumétrie.
Pour démarrer sur ce sujet, nous faisons une première analyse rapide des volumes des tickets traités par le niveau 1, avant une nouvelle saison kaizen, ce afin d’embarquer les 1 ou 2 sujets clés qui auront le plus d’impact.
Problème
Comme très souvent nous retrouvons le sujet des mots de passe et leurs déclinaisons : réinitialisation, activation de la double authentification (aka 2FA), ou encore l’obtention d’un code de secours.
Sur les 53.000 incidents ouverts l’année précédente, 8% sont liés au sujet de la réinitialisation de mot de passe. Sur les dix dernières semaines avant le début du Kaizen, cela représente un volume hebdomadaire de 55 incidents. Ce qui étonne l’équipe chargée de ce sujet car elle a mis en place une procédure pour rendre les utilisateurs autonomes dans ce protocole.
Nous travaillons sur ce Kaizen avec un binôme constitué de l’ingénieur N2 en charge de ce sujet (appelons le Jérôme) ainsi que de la responsable du N1 (appelons là Kenza).
Causes
Nous faisons donc un statut sur les utilisateurs qui ont configuré cette fonctionnalité avec un mot de passe de récupération. Sur 16.000 comptes nominatifs, 15800 ont configuré la 2FA mais seulement 5104 ont une adresse mail de récupération (30%). Une analyse détaillée sur un échantillon des 18 derniers tickets traités montre que 15/18 n’ont pas la 2FA configurée suite au traitement du ticket.
En y regardant de plus près, nous constatons que si la procédure standard qui a été donnée au N1 précise bien de s’assurer de la configuration de la 2FA, elle ne précise pas le besoin de profiter de la résolution des incidents de mot de passe pour configurer l’e-mail de récupération de compte. Et que le template de réponse à ce genre d’incident dans le système de support ne comporte pas cette demande sur l’adresse de récupération. Et, enfin, qu’une partie des techniciens support n’utilisent pas nécessairement ce template de réponse car ils n’en ont pas vraiment compris l’utilité. De la même manière, un test sur le portail nous montre que lorsque les utilisateurs vont directement sur le portail pour récupérer leur mot de passe, ce formulaire ne demande pas de façon explicite l’adresse mail de récupération. C’est la même chose pour le template de réponse d’incident : les agents du N1 ne sont donc pas mis en situation de réussir.
Enfin nous constatons qu’il y a des “top scorers” parmi les personnes ouvrant ce type de tickets, et que les personnes en charge de l’administration IT des centres de relation client (CRC) : ainsi un des prestataires a deux fois plus de collaborateurs sans 2FA configurée qu’un autre fournisseur. Là encore en regardant de plus près on se rend compte que le fournisseur #2 s’assure que les nouveaux chargés de clientèle configurent bien cette adresse de récupération.
Contremesures
Une fois ces causes bien identifiées, nous pouvons avancer avec des contre-mesures ciblées et très concrètes.
Dans un premier temps, la dynamique Kenza s’attache à rappeler à l’ensemble des techniciens de support l’importance de la configuration de la 2FA lors des appels sur les mots de passe. Les éléments chiffrés apportés contribuent à convaincre les équipes de cette nécessité.
Ensuite, l’équipe N2 met à jour la procédure standard de sécurisation de compte en précisant le besoin de demander le mail de récupération.
L’équipe organise dans la continuité un point avec les deux correspondants des CRC pour qu’ils puissent échanger leur pratique et que la personne en charge du CRC avec plus de sujets (Emilie) comprenne l’importance de configurer le mail de récupération des agents de relation client.
Enfin, les templates de réponse à incidents de mot de passe (réinitialisation, code de secours, 2FA) sont mis à jour afin de s’assurer que l’on pose la question du mail de récupération. De la même façon, les formulaires du portail sont eux aussi mis à jour pour insister sur l’importance de cette configuration.
Résultats
Le volume d’incident liés au mot de passe est passé de 47 par semaine (trimestre avant) à 27 par semaine (trimestre suivant) soit une réduction de 45%. Le trimestre suivant le volume moyen hebdo est passé à 18/semaine soit une réduction totale de 61% du volume d’incidents, en 6 mois. Pour nous assurer qu’il ne s’agit pas d’une réduction liée à la seule saisonnalité, nous avons comparé le même trimestre de l’année au trimestre de l’année précédente et nous sommes passés d’une moyenne de 35/semaine à une moyenne de 18/semaine soit une réduction de 51%. Ce sujet représentant 8% de l’ensemble des incidents ouverts, nous avons donc obtenu une réduction de 4% du volume total annuel d’incidents avec ce Kaizen.
Sur un échantillon de 25 tickets traités, nous sommes passés de 52% à 100% ayant la 2FA configurée.
En revanche, sur la partie mot de passe de récupération, sur un échantillon analysé de 10, seuls 3 (30% donc) ont ce mot de passe bien configuré. Kenza décide de reprendre une nouvelle campagne de communication auprès de ses techniciens de support.
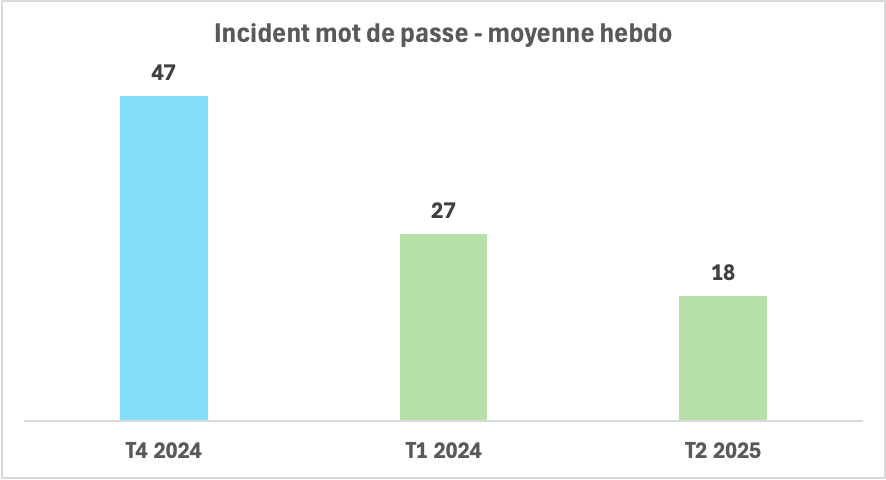
Enseignements
Durant ce Kaizen, Vincent le technicien a découvert que la gestion des mots de passe par les centres de relation client n’étaient pas standardisés d’un prestataire à l’autre. Et que ce qu’il pensait implicite en termes de configuration de compte ne l’était pas.
De son côté, Kenza a appris que les techniciens support n’utilisaient pas nécessairement les template de réponse d’incident car ils ne comprenaient pas vraiment leur utilité et les impacts à ne pas les utiliser.
Synthèse du sujet :
- Problème : 47 incidents liés au mot de passe ouvert par semaine.
- Causes principales : les utilisateurs n’ont pas configuré leur mail de configuration et celui-ci n’est pas configuré après appel du N1 pour réinitialiser le mot de passe. Les centres de relation client n’ont pas le même processus pour la création de compte : certains configurent le mail de récupération, d’autres non. Les templates du N1 pour la correction de ces incidents ne sont ni suivis ni mis à jour avec le mail de récupération.
- Contre-mesure : modification du template N1 pour intégrer la configuration du mail de récupération ; accompagnement des équipes N1 pour bien intégrer la demande du mail de récupération ; accompagnement des CRC pour la configuration en masse de nouveaux comptes.
- Résultats : passage de 47 à 27 puis 14 incidents liés au mot de passe par semaine, soit une réduction de 70% en 6 mois.
Deuxième Kaizen mot de passe
Nous avons mené un kaizen semblable sur un autre sujet de mot de passe bureautique.
Synthèse du sujet :
- Problème : 57 incidents liés au mot de passe ouvert par semaine
- Résultats : passage de 57 à 26,6 soit une réduction de 53% là encore
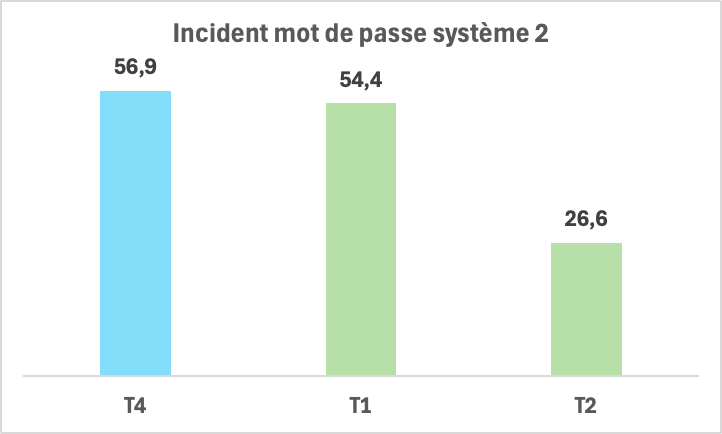
Ce sujet représentant 4,7% du volume total d’incidents ouverts chaque année, nous obtenons donc ici une réduction supplémentaire de 2,3% du volume global d’incidents annuels avec ce Kaizen. On voit là encore l’intérêt de distribuer l’amélioration et d’avoir chaque équipe qui apporte sa contribution à un sujet clé de l’entreprise.
Résultats en fin d’année
Après un an de Kaizen, nous regardons donc l’évolution du nombre d’incidents ouverts d’une année sur l’autre sur ce sujet.
Nous observons une réduction de 24,7% entre ces 5 premiers mois de 2024 et ceux de 2025 (un total de 21708 en 2024 contre 16330 en 2025).
Le quatrième et dernier Kaizen de l’année 2024 impliquant les sujets N1 et se terminant fin janvier, une comparaison plus précise serait donc entre les quatre mois de février à mai et montre une réduction de 28,6% (16978 en 2024 Vs. 12114 en 2025).
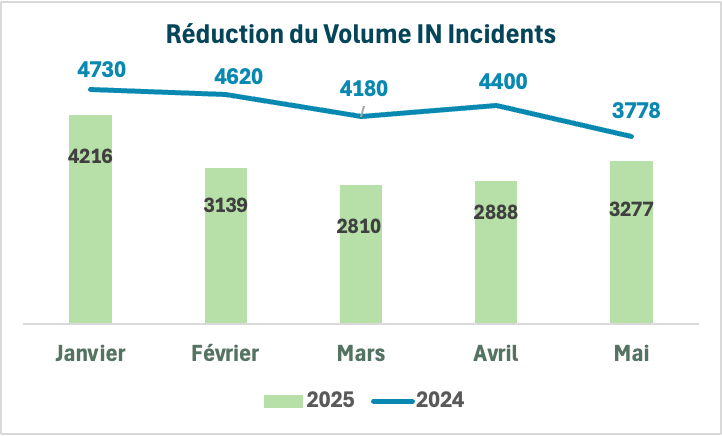
Grâce au dispositif de déploiement du Kaizen, l’ensemble de la DSI s’est mobilisé sur de nombreux petits sujets ce qui a permis ces résultats cumulés. Ces derniers ont un impact direct sur la satisfaction des clients bien sûr (ouvrant moins d’incidents et étant moins longtemps bloqués) mais aussi sur celle des collaborateurs. Au niveau N1, parce qu’avec le left-shifting ils sont capables d’aider les clients sur des sujets plus complexes ; au niveau N2 parce qu’ils ont appris des éléments très spécifiques sur leur contexte technique et sur le métier qu’ils servent. Par ailleurs, les équipes sont moins interrompues par des interruptions en raison de ces problèmes de qualité. Enfin au niveau de l’entreprise cela permet de réduire le coût du support et de libérer de la capacité pour les projets : la promesse du Lean dans l’IT.
(Un grand merci à Alexandre et Caroline de Veolia Eau France DB&T pour leurs relectures attentives).