SAP Analytics Cloud - épisode 2 : booster SAC avec Python
Cet article est le deuxième article de la série Booster SAP Analytics Cloud. Il fait suite au premier article sur la partie Visualisation innovantes D3JS.
1. Contexte et périmètre :
- Dans le cadre du Hackathon SAP Analytics Cloud (SAC) du 30 avril au 7 mai 2020, la tribu LIQSA (Liquid SAP Analytics) a réalisé un tableau de bord incorporant :
- un algorithme de Machine Learning en Python,
- des visualisations innovantes grâce à des librairies D3JS.
- Sachant que cet article fait référence à un PoC réalisé dans le cadre d’un hackathon très court, nous n’aborderons donc pas ici les problématiques de sécurité et d’authentification, qui sont inhérentes à tout projet informatique.
2. SAC et ses fonctionnalités d'AutoML pour l'analyste/utilisateur SAP
SAP Analytics Cloud (SAC) est la plateforme Analytique de SAP et se compose de différents modules :
- Business Intelligence (BI),
- Analytique augmentée,
- Analyse prédictive et
- Planification d'entreprise.
Comme toute plateforme analytique de dernière génération, elle permet d'utiliser des approches de machine learning automatisées sans avoir un background en data science.
En voici quelques unes disponibles en natif:
- Search to Insight : Technologie NLP (Natural Language Processing) de traitement du langage naturel. Trouvez rapidement des informations présentées de la manière la plus compréhensible possible.
- Smart Insights : Expliquer un point de données ou un graphique.
- Smart Discovery : Expliquer la relation entre une colonne cible et les dimensions et mesures d'un jeu de données.
- Smart Grouping : Regrouper mes transactions (cluster).
- Predictive forecasting : Générer une prévision à partir des données de séries chronologiques pour les intervalles de temps futurs.
- Smart Predict: Approche du « Citizen Data Scientist » pour générer de nouvelles données et faciliter la compréhension du business et la prédiction des résultats futurs.
Par exemple, la technologie Smart Discovery permet de mettre le doigt sur les éléments pertinents du jeu de données. Il suffit de fixer quelques indicateurs et paramètres, et le moteur d’Intelligence Artificielle va opérer les corrélations et croisements puis générer directement un rapport. Une fois l’ébauche de rapport livrée, il sera possible de basculer en mode manuel pour creuser les pistes suggérées par le moteur d’IA. En cliquant sur une mesure (ici Net Revenue) on a 3 possibilités d’analyse:
La découverte des influenceurs clés de Net Revenue (Orange with Pulp dans les Produits, Kiran Raj dans les Commerciaux et Reno pour la Localisation...)
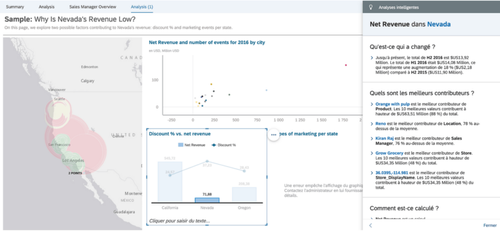
L’exploration des valeurs inattendues de Net Revenue
La simulation de Net Revenue à partir des influenceurs clés
Ces fonctionnalités “Smart” de ML automatisées ont l’avantage de rendre accessible des fonctions de contribution, de classification et de régression. Ces fonctionnalités aident les utilisateurs à découvrir des modèles cachés et des relations complexes dans leurs informations, même sans aucune connaissance ou expérience en data-science.
3. Pourquoi intégrer des algorithmes de Machine Learning Python sous SAC ?
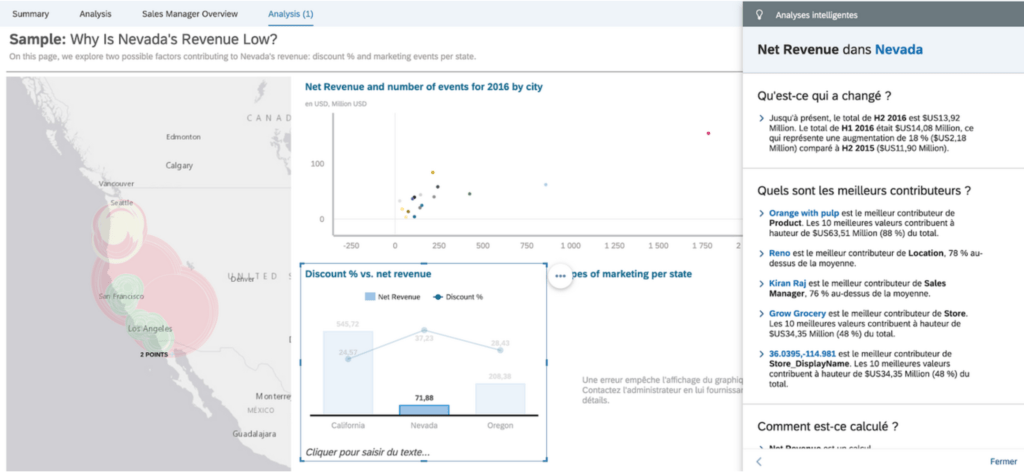
Pour les utilisateurs plus aguerris en data-science, il est possible de rajouter dans les applications SAC des visualisations R nativement, soit via son propre serveur R, soit via un serveur pré-configuré disponible sur SAC. Le code R est interprété par le serveur R et SAC s’occupe de la partie graphique. On peut par exemple utiliser des librairies R telle que ggplot2.
SAC permet d’intégrer du code R, mais il est impossible de faire tourner des algorithmes Python en natif.
Pour y remédier, nous allons vous montrer ci-dessous la démarche pour faire tourner un serveur Python comprenant des algorithmes de ML, et comment créer des applications SAC faisant appel à ce serveur Python.
4. Comment intégrer des algorithmes Python sous SAC ?
Puisque SAC n’intègre pas en natif d'algorithmes Python, il va falloir :
dans un premier temps envoyer les paramètres de SAC vers un serveur Python,
puis faire en sorte que ce serveur applique le modèle sur ces données,
et enfin que le serveur renvoie le calcul à SAC.
Afin de simplifier la démarche, nous allons utiliser un algorithme Python avec passage de paramètres pour rendre dynamique les échanges entre SAC et le serveur Python.
L’algorithme python choisi : le K-means
Pour notre exemple, nous avons sélectionné un algorithme Python paramétrable, le K-means. Il s’agit d’une méthode de classification non supervisée. Cet algorithme permet de regrouper l’ensemble des données dans K classes (également appelées clusters).
La création du serveur Python, l’installation du nodeJS et du tunnel Ngrok
Voici le schéma de macro-architecture retenu pour représenter les flux simplifiés (se basant sur un jeu de données en provenance de kaggle.com):
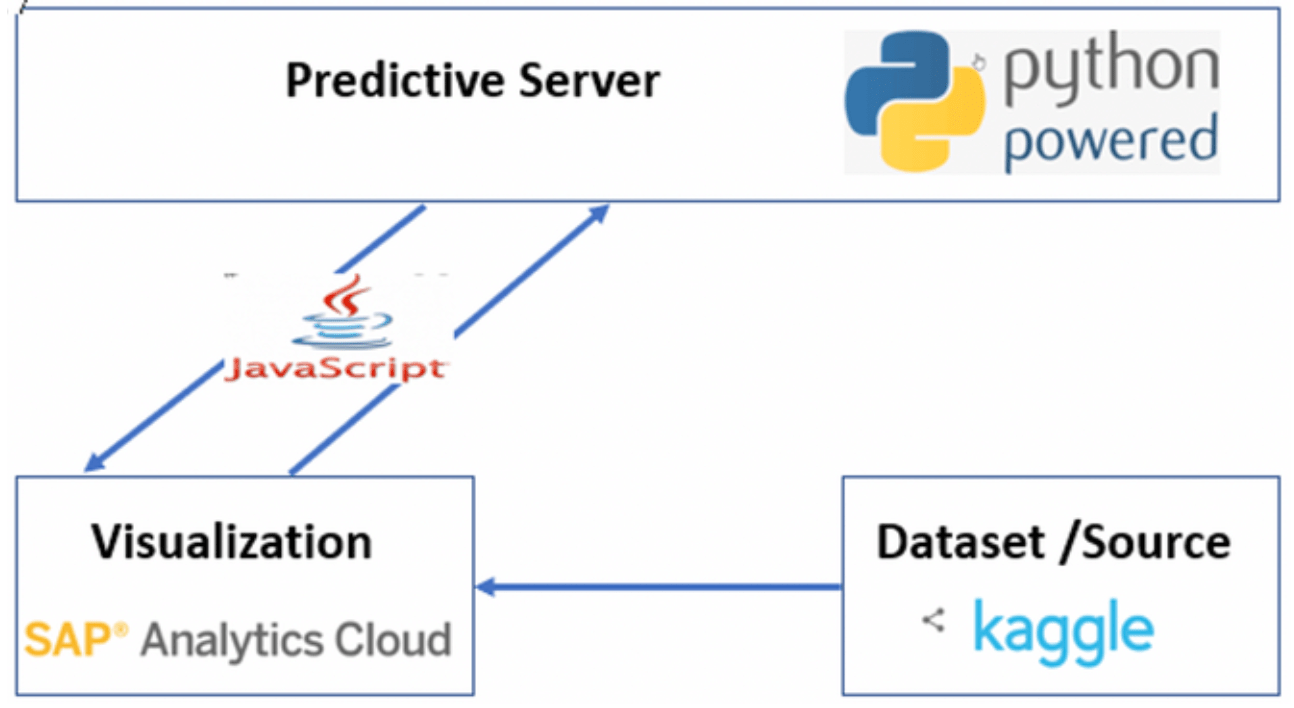
Le dataset utilisé dans notre exemple se compose de données de ventes immobilières récupérées sur kaggle.com (jeu de données de bonne qualité mais avec peu de volumétrie). C’est sur ces données que l’algorithme K-means est appliqué au travers d’un paramètre dynamique, envoyé par SAC (valeur renseignée par un slider).
Voici un schéma représentant les échanges entre les différents composants:
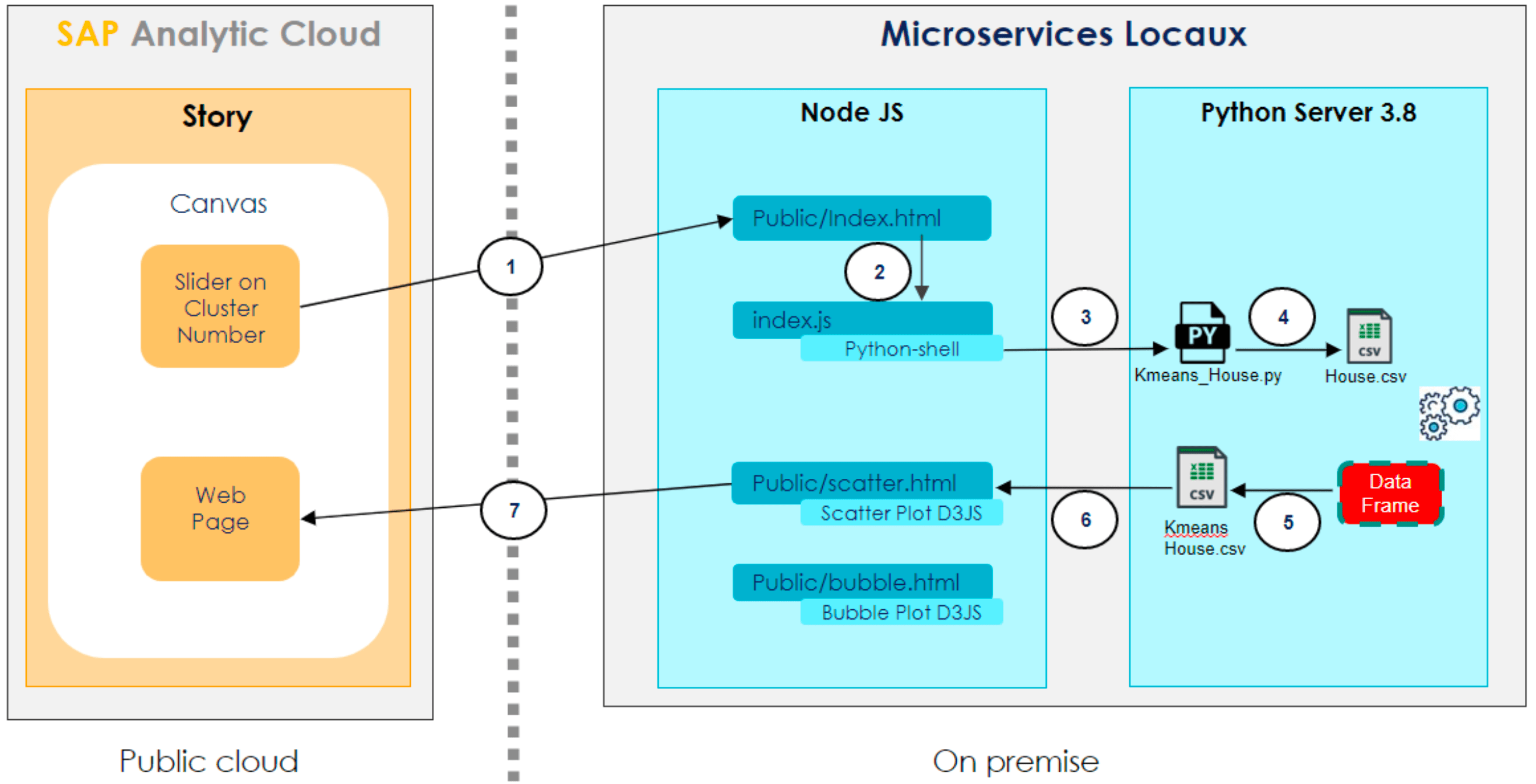
L’un des challenges du Hackathon est de mettre en place une architecture cohérente avec le cas d’usage. En effet, l’objectif était de pouvoir exécuter un script Python permettant de faire des regroupements de ventes immobilières (au travers de l’algorithme de Machine Learning K-Means) et à partir de variables comme le prix et la superficie de la vente.
Au préalable, il vous faut installer un serveur NodeJS et configurer le fichier index.js pour recevoir des requêtes HTTP sur le port TCP 8443. SAC ne peut communiquer avec un serveur externe que si ce dernier est sécurisé.
Pour sécuriser le serveur Node JS, il pourra être générer un certificat auto-signé via la commande suivante:

Une fois les certificats créés, ils sont utilisés pour la création de notre serveur HTTPS:

Et ensuite ce serveur peut être démarré et écoutera les requêtes entrantes sur le port 8443 via la commande suivante:

Mais le serveur n’est pas encore interrogeable depuis SAC, car c’est un serveur local, avec un certificat qui ne dépend pas d’une autorité de certification. Ainsi un tunnel (NGROK) entre ce serveur et le serveur SAC est nécessaire pour exposer le serveur local au cloud public.
Voici la liste des pré-requis à l’installation d’un serveur Python sur le même poste pour simplifier la configuration:
Afin d’exécuter du code python à partir de SAC, il sera nécessaire :
de créer une application SAC intégrant un slider pour choisir le nombre de regroupement à calculer (il s’agit de notre paramètre K).
de transmettre ce nombre au travers d’un appel à une page web (index.html) hébergée sur un serveur NodeJS installé localement sur le même poste.
d’utiliser un script JS (index.js) pour lancer l’exécution du script python grâce à une librairie “python-shell” (sous licence MIT). Note: Cette librairie est installée via une ligne de commande NPM.
d’exporter le dataframe issu du K-means sous un format CSV.
de présenter les données à une page web intégrant des visuels de la librairie D3JS,
d’afficher ce composant WebPage dans SAC.
Afin de pouvoir lancer plusieurs requêtes d’exécution auprès du serveur Python, il a également été testé l’intégration de la bibliothèque javascript socket.io permettant des échanges bi-directionnels en temps réel entre le client web et le serveur Python.
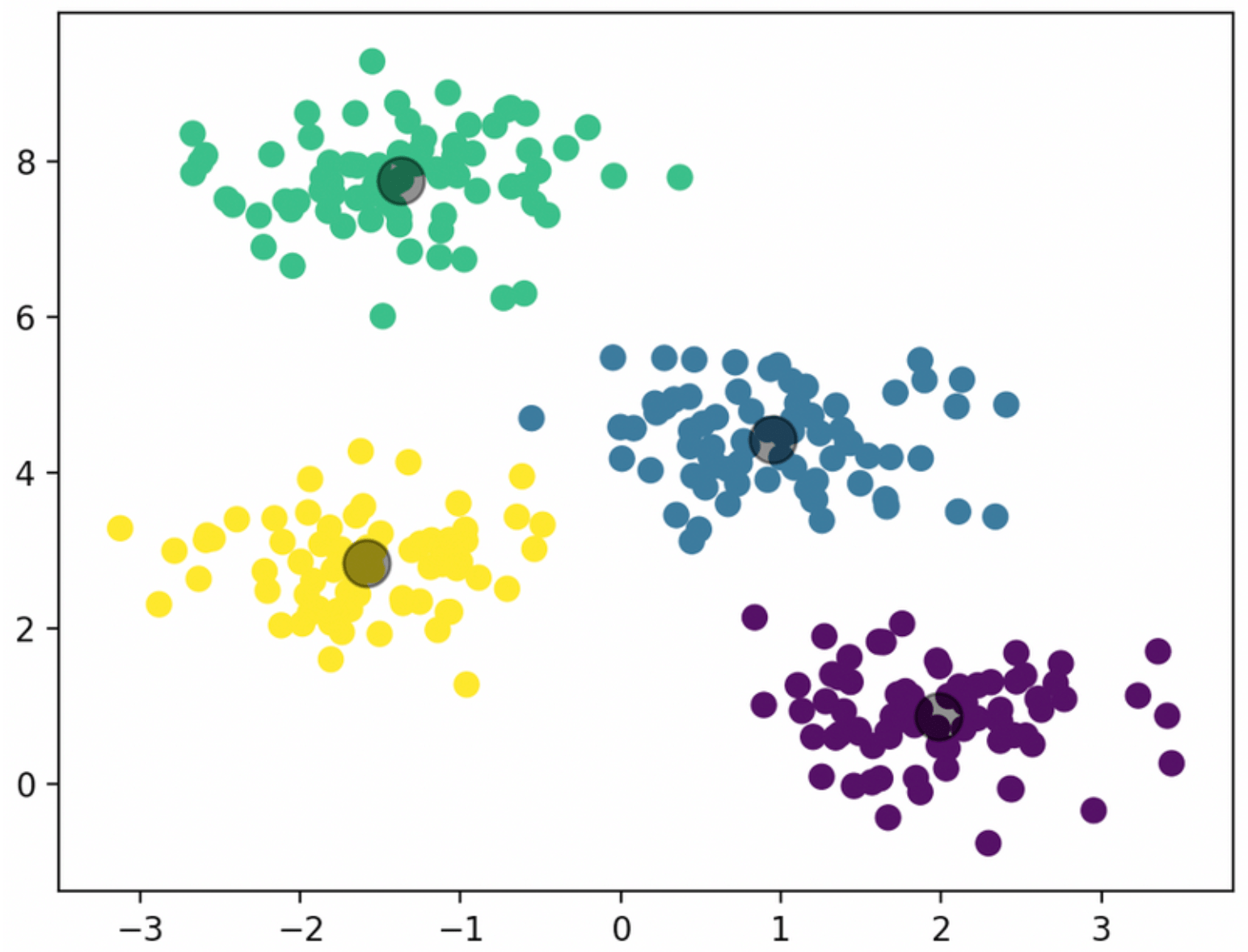
Voici un exemple de regroupement K-means avec K = 4 où les données sont représentées graphiquement sous 2 axes, mais il peut y avoir des dizaines de variables en réalité derrière.
La création de l’application dans SAC via Application Designer
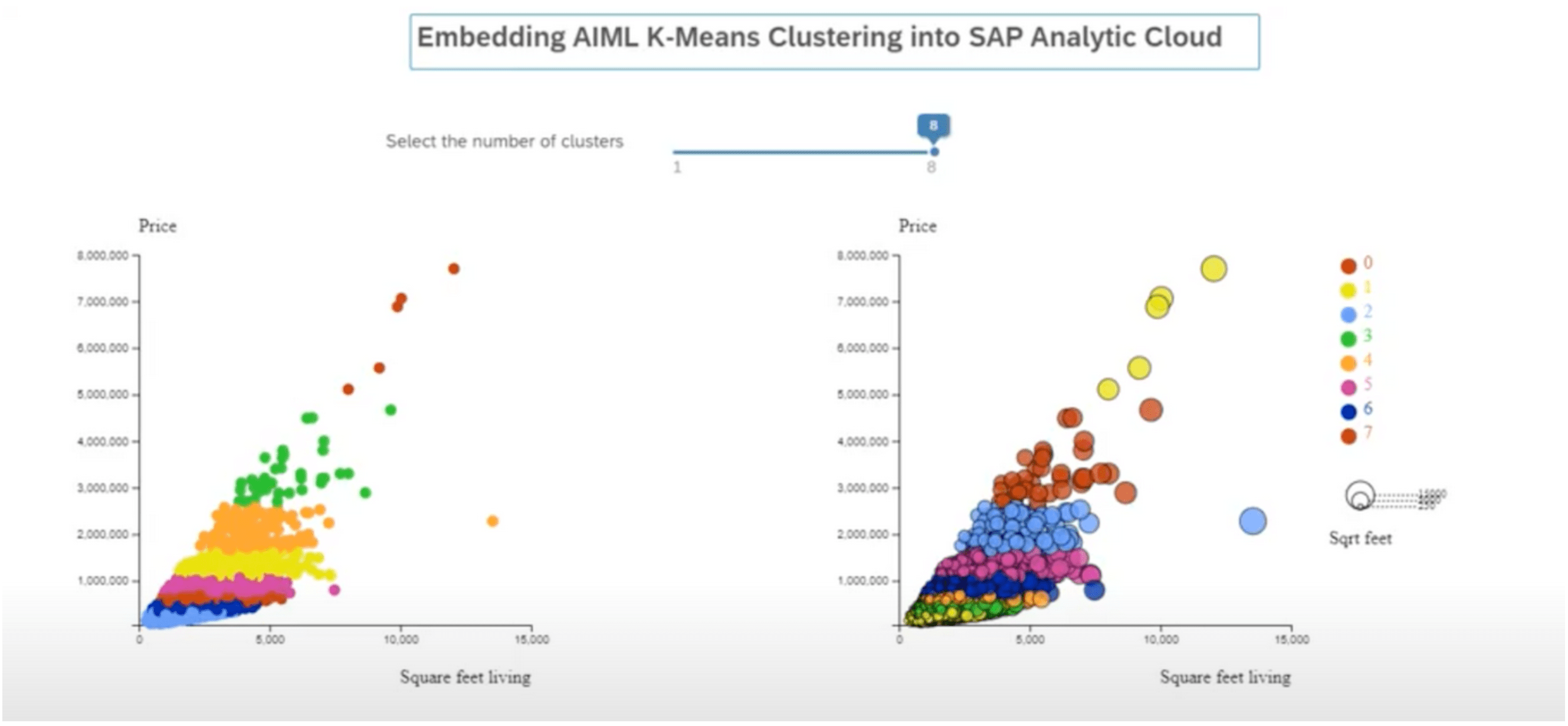
Voici le rendu d’une première visualisation faisant appel au serveur python avec k-means = 8 (configurable via la barre de slider) pour tester l’algorithme :
Voici le rendu de l’application dans SAC avec 4 clusters en paramètre (via le slider dynamique) :
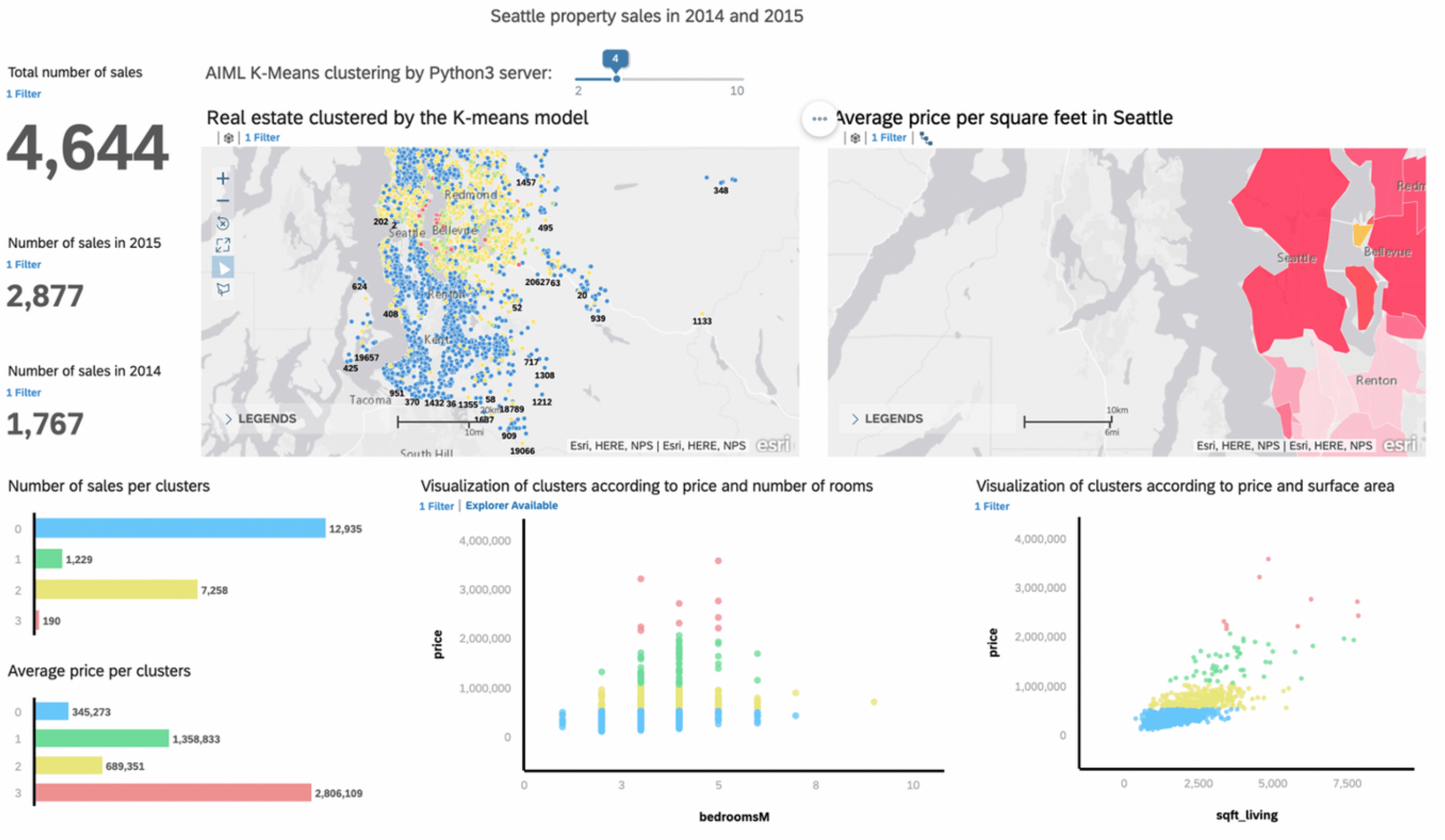
On peut voir que les données des ventes immobilières ont été regroupées en 4 catégories allant :
- du bleu pour les biens immobiliers les moins chers (345 K$ en moyenne) représentant le plus grand nombre de ventes (12 935 ventes).
- au rouge pour les biens les plus luxueux (2,8 M$ en moyenne) représentant seulement 190 ventes.
On peut aussi remarquer dans le graphique du bas que les appartements les plus luxueux (points en rouge) ont moins de 5 chambres.
5. Take Away
L’architecture proposée pour la solution est une architecture de cloud “hybride” mêlant d’un côté une application SaaS qui peut être hébergée chez Amazon Web Services ou dans les Datacenter de SAP et de l’autre des serveurs privés “on premise”.
Les bénéfices de booster SAC avec du Python et des visualisations D3JS:
- Une meilleure compréhension et prédictibilité pour les data-scientistes expérimentés. Ils peuvent utiliser leurs propres fonctions et modèles Python
- Une utilisation de code open-source plutôt que des fonctionnalités SMART de SAP (de type boîte noire), même si celles-ci sont tout de même très utiles pour des Citizen data-scientistes.
- Une amélioration visuelle de SAC (même si déjà pas mal loti) avec des graphiques D3JS innovants comme Sequences Sunburst.
Les difficultés mineures rencontrées:
- Il y a besoin de compétences javascript assez poussées pour la communication entre SAC et le serveur Python;
- Il y a besoin de compétences serveur / NodeJS (et ne pas avoir peur de taper des lignes de commandes CMD / Terminal pour Mac).
Notre préconisation:
- Ce type d’archi est bien pour faire du prototypage, du PoC avec une volumétrie modérée.
- Pour une industrialisation avec des volumétries plus conséquentes ou avec des SLA (temps de réponse) très courts, il faudrait plutôt s’orienter vers des modèles à faire tourner côté backend. Dans notre cas, il s’agirait d’exécuter l’algorithme K-means python sur les données présentes dans le même tenant HANA connecté à SAC.
Cet article est le second de notre mini série d'articles sur SAC.