Rook.io, du stockage “cloud native” dans votre Kubernetes !
Les conteneurs, de par leur aspect volatile, n'ont pas bonne réputation en ce qui concerne le stockage. Souvent, les applications sont déployées en tant que service “stateless” sur l’orchestrateur (c’est d’ailleurs le 6e principes des 12-factors apps) et persistent dans des bases de données, des stockages objets (AWS S3, Azure Blob Storage…) ou des NAS externes.
Aujourd’hui, le stockage est donc une réelle problématique lorsque nous voulons déployer un cluster Kubernetes sur une infrastructure qui n’offre pas déjà un accès à un stockage adapté.
C’est pourquoi je vous propose de découvrir Rook.io, un projet passé “graduate” c’est à dire mature, au sein de la CNCF.
Disclaimer
Cet article est une introduction à un outil que je trouve prometteur, mais que je n’ai pas eu l’occasion d’implémenter en production.
Important.
Rook.io est plustot simple à installer dans le cadre d’un POC ou d’un simple test, la plupart des étapes sont automatiques et on arrive vite vers une instance fonctionnelle.
Cependant, pour un maintien opérationnel, il est nécessaire d’avoir de solides compétences sur Kubernetes, les operator stateful et sur les fonctions d’administrations avancées de CEPH.
Fonctions
Rook répond à la problématique du stockage en implémentant un cluster CEPH “production-ready” dans un cluster Kubernetes. CEPH est aujourd’hui la solution Open Source la plus mature sur le marché pour implémenter du stockage distribué.
Il est possible de stocker des Pétaoctets de données et les exposer de plusieurs manières :
- Block
- Le stockage block agit comme un disque dur accessible par le réseau et qui peut être attaché à une seule machine à la fois.
- Objet
- Shared file system
- Un stockage pouvant être monté sur plusieurs pods ou containers simultanément.
Pour rappel, S3 est le volume objet d’Amazon Web Services qui fait aujourd’hui référence, les concurrents s’alignent sur cette compatibilité.
Rook permet néanmoins de faire plus !
- Cassandra
- CockroachDB
- EdgeFS
- NFS
- YugabyteDB
Mais ces derniers sont à l’heure où j’écris ces lignes en Alpha. A surveiller de près donc.
Sous le capot
Les explications techniques ci-dessous sont tirées de la documentation, pour plus de détails, vous pouvez vous référer au lien ci-dessous.
https://rook.io/docs/rook/v1.5/ceph-storage.html
Rook est un opérateur qui manipule CEPH en utilisant les primitives de Kubernetes.
Les objets Kubernetes manipulés par l’opérateur Rook
- Deployments
- DaemonSets
- Pods
- Services
- StorageClass / PV / PVC
- ClusterRole
- NameSpace
- Config Maps
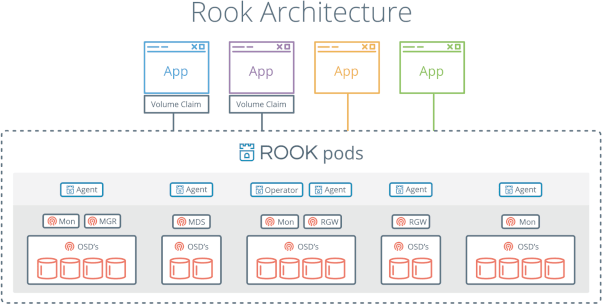
Le schéma ci-dessous illustre la façon dont Rook s’intègre avec Kubernetes.
- L’opérateur Rook se matérialise sous la forme d’un conteneur qui initialise et surveille le cluster de stockage CEPH.
- L’opérateur démarre le démon CEPH OSD afin de provisionner le stockage.
- Les pods via le client CEPH vont monter les volumes via le driver CSI.
- Le driver flex est disponible mais pas activé par défaut et sera bientôt déprécié au profit du driver CSI.
- Rook configure automatiquement le pilote CEPH-CSI afin de monter les volumes dans les pods.
L’opérateur monte dans chaque worker Kubernetes un système de fichiers XFS dans le répertoire /var/lib/rook qui contiendra un agrégat du volume total.
Les fonctions de l’opérateur :
- Automatise la configuration des composants de stockage et surveille le cluster afin de s’assurer de la santé du stockage.
- Démarre et surveille le démon OSD CEPH de façon à fournir le stockage
- Gère le stockage objet (S3/SWIFT) et le système de fichiers en initialisant les pods.
- Initialise les agents nécessaires à la consommation du stockage.
CSI est une API standard Open Source qui permet à des systèmes de stockage de s’intégrer à Kubernetes et de mettre à disposition des volumes aux pods qui en demandent.
Lorsque l’on déploie un pilote de stockage compatible avec CSI sur un cluster Kubernetes, celui-ci peut se connecter directement au volume local du worker type /dev/xda.
Installation
L’installation s'effectue simplement via le chart Helm ou comme nous l’avons fait ci-dessous, via kubectl, les yaml nécessaires à l’installation étant disponibles sur le github du projet.
Installation des dépendances
cd cluster/examples/kubernetes/ceph
<br>kubectl create --filename crds.yaml --filename common.yaml --filename operator.yaml<br>
Vérifiez que l'opérateur ROOK-CEPH est dans l'état «en cours d'exécution» avant de procéder
<br>kubectl -n rook-ceph get pod<br>
Création du cluster
<br>kubectl create --filename cluster.yaml<br>
L’installation peut prendre du temps selon votre bande passante, vous pouvez suivre l’état de l’installation via cette commande :
<br>kubectl --namespace rook-ceph get pod --watch<br>
Tableau de bord
Un tableau de bord est fourni afin de suivre l'état du cluster et des volumes disponibles (pour le désactiver, c’est ici).
Récupérer le mot de passe
<br>kubectl --namespace rook-ceph get secret rook-ceph-dashboard-password --output yaml | grep "password:" | awk '{print $2}' | base64 --decode<br>
Accéder au tableau de bord
<br>https://<ip>:<port>/#/login<br>
L’ip étant celle du cluster Kubernetes
Le port étant celui du service rook-dashboard.
Il est aussi possible d’utiliser la fonction port-forward de kubernetes ou de placer un ingress en entrée afin de gagner en portabilité.
Outils d’administration
L’image rook/ceph inclut les outils nécessaires à la gestion du cluster.
La plupart des fonctions avancées d'administration de CEPH sont automatiquement gérées, il n’est donc pas nécessaire de les prendre en considération.
Néanmoins, il est possible de prendre en main ces fonctions avancées via les commandes CEPH fournies.
Attention toutefois sur l’utilisation de Rook en production, un expert en administration CEPH est indispensable.
Vérifier l’état du cluster
<br>ceph status<br>
<br>cluster:<br>
<br>id: a0452c76-30d9-4c1a-a948-5d8405f19a7c<br>
<br>health: HEALTH_OK<br>
Retourne la taille utilisée et la capacité du cluster
<br>ceph df<br>
Créer un nouveau pool de stockage
<br>ceph osd pool create<br>
Liste les pools de stockage
<br>ceph osd lspools<br>
Réparation des groupes
Dans le cas où ceph status retourne un HEALTH_ERR
<br>ceph pg repair <group number><br>
Afin d’accéder aux outils d’administration CEPH
<br>kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash<br>
Cette commande va retrouver le pod sur lequel l’image “rook-ceph-tools” est installée et s’y connecte en mode console (bash).
Monitoring
Rook s’intègre “out-of-the-box” à Prometheus et Grafana.
Ici nous voyons les métriques liées à l’utilisation des volumes.
Un test concret
Maintenant que nous avons un stockage distribué tout neuf, essayons d’aller un peu plus loin avec un test concret. Déployons un serveur Mysql qui va persister ses données sur notre cluster CEPH le tout sur Kubernetes.
Vous trouverez ici le fichier de description de ce déploiement
https://github.com/rook/rook/blob/master/cluster/examples/kubernetes/mysql.yaml
Dans ce fichier, nous trouvons :
- Un ”service” mysql qui écoute sur le port 3306
- Un “persistentVolumeClaim” qui prend en “storageClassName” “rook-ceph-block”
- Un “deployment” qui prend en paramètres une image mysql 5.6 standard et le “persistentVolumeClaim” cité ci-dessus
Dans le cas de la perte ou d’ajout d’un nœud, il suffit de redémarrer l’opérateur Rook afin qu’il re dispatche les données sur le nouveau nœud grâce au Rook Discover qui détecte les volumes attachés au nœud de stockage.
Via les commandes suivantes qui ne font que supprimer et recréer l’instance.
<br>kubectl scale deployment rook-ceph-operator --replicas=0 -n rook-ceph-system<br>
<br>kubectl scale deployment rook-ceph-operator --replicas=1 -n rook-ceph-system<br>
ou
<br>kubectl rollout restart deployment/rook-ceph-operator<br>
Le fait de redémarrer l’opérateur recrée automatiquement le cluster et prend en compte automatiquement les différents nœuds.
Conclusion
Quel est l'intérêt de Rook couplé avec CEPH ?
- Vous disposez d’un cluster Kubernetes et vous avez besoin de stockage ?
- Vous disposez d’un cluster on-premise et/ou ne disposez pas de solution de stockage adaptée (souvent très onéreuse) ?
- Vous ne voulez pas utiliser votre NAS en environnement de développement ?
- Vous voulez disposer d’un stockage objet compatible S3 ?
- Vous voulez persister vos bases de données déployées sur Kubernetes ?
Rook et CEPH répondent à ces besoins.
Lors d’un POC ou un MVP, Rook peut répondre à un besoin de persistance pour une base de données via un stockage block.
Malgré une majorité de modules en Alpha, CEPH est lui bien en version stable. Rook.io constitue une alternative sérieuse aux solutions de stockage du marché du développement à la production.
Références