REX - Tout ce que vous avez voulu savoir sur la migration d'une exploitation sans jamais oser le demander
Un peu de contexte
Le client est une banque privative que nous appellerons “A” de taille moyenne qui est notre client. Elle est constituée d’environ 600 personnes au sein du siège hors délégation. Une délégation est l’équivalent d’une agence qui a la particularité de travailler exclusivement pour les fonctionnaires.
La banque a son propre SI. Aujourd’hui, comme toutes les banques elle est confrontée à une forte réglementation “DORA” et des normes sécuritaires bancaires accrues. Elle a en effet subi plusieurs incidents majeurs qui ont paralysées ses activités.
La banque “A” souhaite un accompagnement opérationnel pour migrer son exploitation au sein des équipes d’une banque “B” dont elle fait partie via un groupement.
La migration d’un ensemble d’applications et à fortiori d’un SI complet n’est jamais un long fleuve tranquille. Chaque cas présente des particularités mais au travers de ce REX, nous souhaitons avec mon collègue Yannig Perré vous présentez les éléments suivants :
- Comment a commencé cette aventure
- Les problèmes auxquels nous avons été confrontés
- Les réussites collectives
- Les leçons que nous avons retenues ?
Comment commence l’aventure ?
Dans le cadre du projet il y a trois temps forts :
- Lancement de l’étude pour vérifier la faisabilité et l’intérêt de migrer l’exploitation de la banque “A” vers la banque “B” en 2024,
- La migration d’une partie des équipes d’exploitation de la banque “A” vers la banque “B” est mis en oeuvre en avril 2025,
- Le lancement des chantiers hors volet RH à partir d’avril 2025.
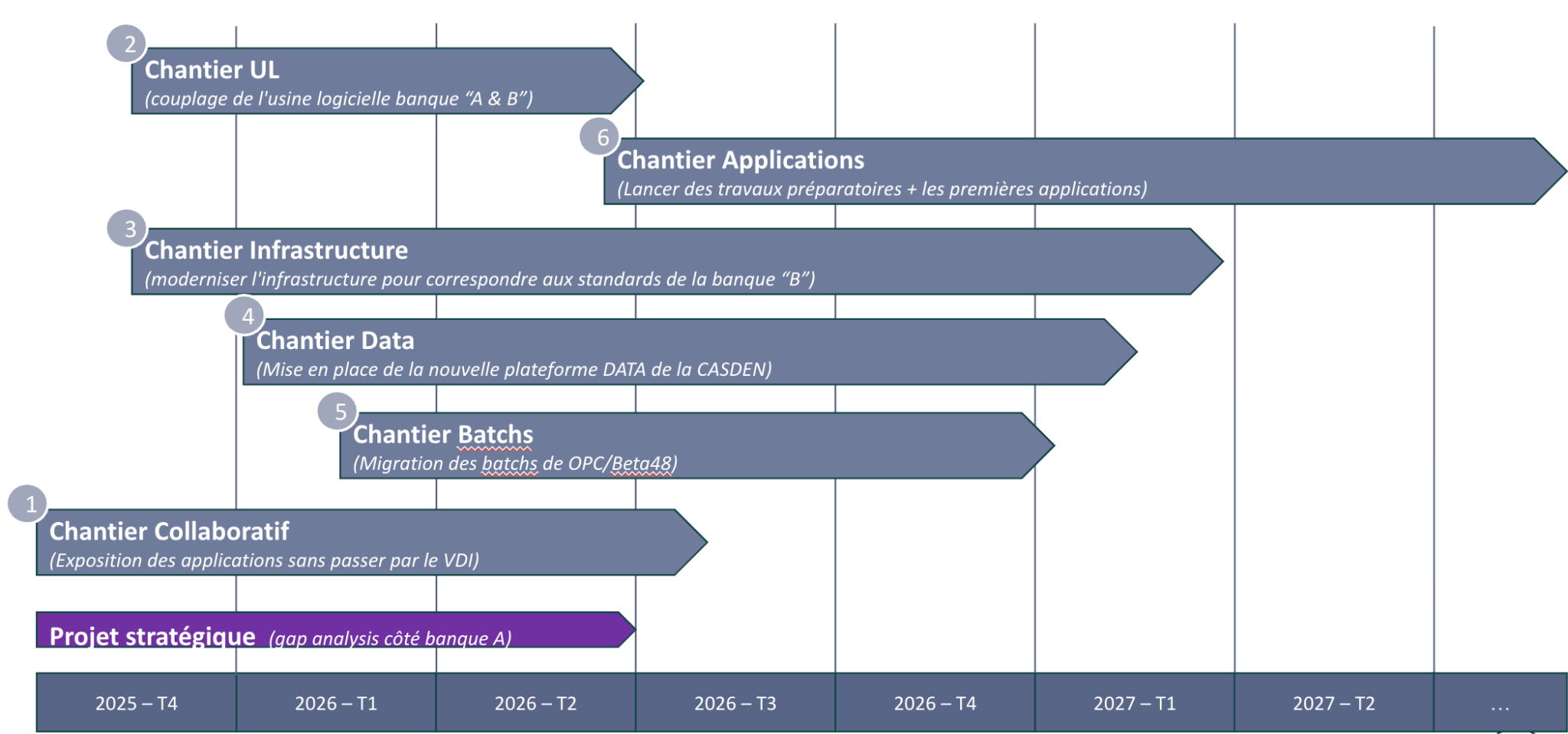
Voici ci-dessous le planning qui reprend les jalons importants du projet et qui se poursuit en 2026.
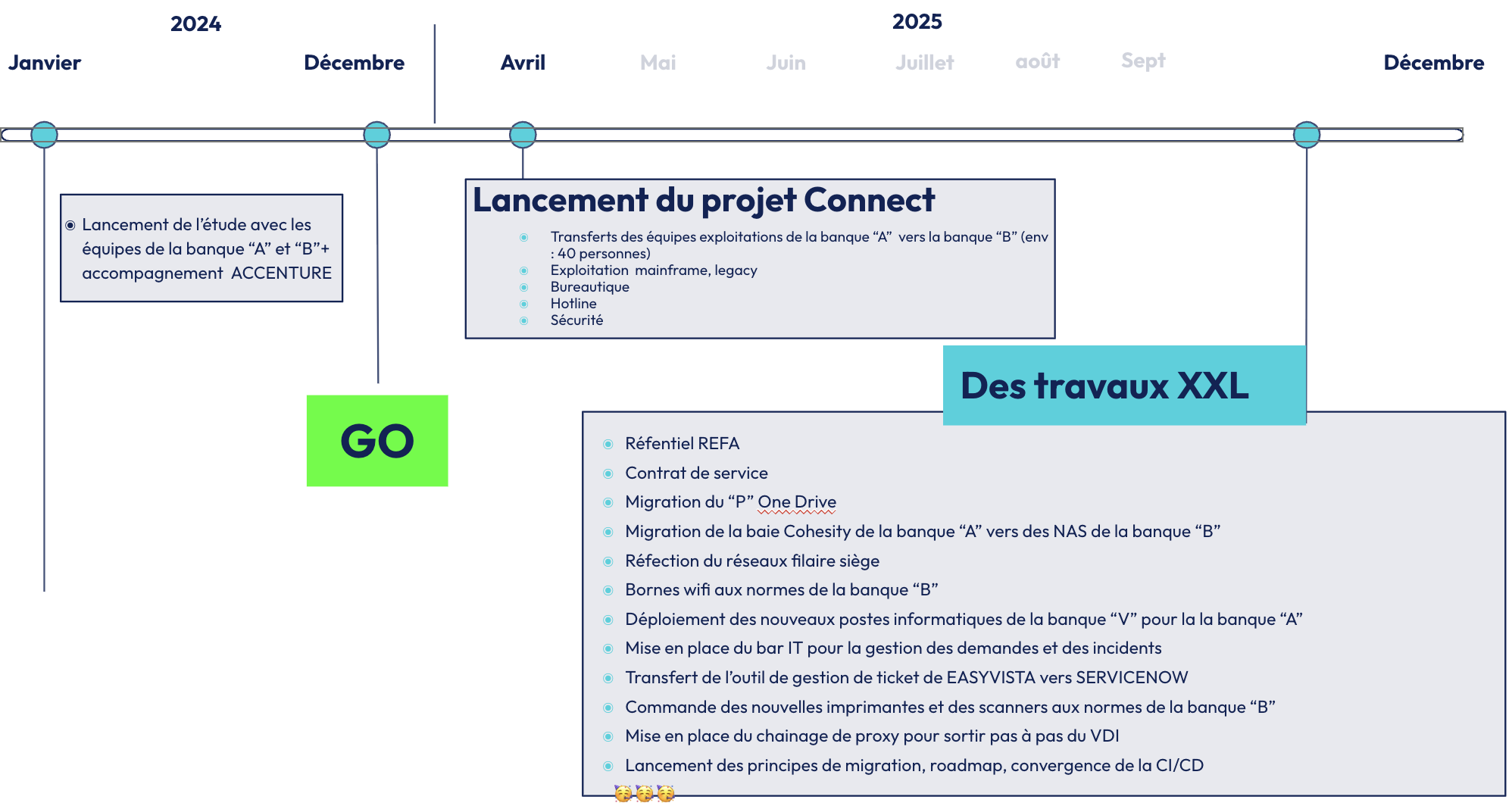
Notre intervention a commencé à partir du début du mois de mai 2025.
Il s’agit d’un programme d’ampleur qui comprend six chantiers. OCTO intervient de façon plus ou moins prononcée sur la quasi-totalité des chantiers hors people et accompagnement.
Il ne s’agit pas uniquement de migrer des applications, cela touche différents chantiers de notre client :
- Infrastructure
- Réseaux
- Stockage
- Remplacement des ordinateurs
- Imprimantes
- Process qualité pour piloter l'exploitation
- Prise en charge des incidents
- Applicatifs.
Vous l’aurez compris une partie de l’équipe d’exploitation de la banque “A” à migrer vers la banque “B” mais les applications sont toujours dans les infrastructures de la banque “A” avec leurs machines dans un hébergement de la banque “B”. Les accès aux machines, aux applicatifs restent les mêmes.
Les problèmes rencontrées
Dans ce qui suit, chacun des sujets vous sera présenté de façon séquencée.
N°1 : Le référentiel des applications de la banque A
A la demande de la banque “B”, nous devons intégrer les applications de la banque “A” qui doivent être migrées dans leur référentiel qui se nomme REFA. C’est la colonne vertébrale de la banque “B” car elle va peupler de nombreux autres référentiels:
- Ressources Humaines (RPG)
- Organisation (North Star)
- Habilitation (Sigma)
- ….
Dans un premier temps, nous pensons naïvement avec mon collègue que la fourniture de cette liste sera triviale. Mais après échanges avec les métiers, nous nous apercevons qu’il n’existe pas une liste unique, connue et partagée par tous ...
Il existe bien des référencements dans différents outils mais ces derniers ne sont pas toujours à jour et/ou les informations sont partielles. Nous découvrons également que plusieurs initiatives/chantiers sont lancés afin de définir un référentiel commun.
Il nous faudra trois mois entre ateliers, recoupement d’information sur plusieurs outils et surtout sur le travail réalisé via le PCA (Plan de Continuité d’Activité) afin de disposer d’une liste exploitable.
Avons-nous tous le scope ? Avons-nous oublié certaines briques ? Le périmètre est-il entièrement couvert ? Nous n’en avons aucune certitude. Néanmoins, cette liste nous permet d’initier le processus au sein de la banque “B”. C’est une première victoire pour l’ensemble des équipes.
N°2 : Les principes de migration
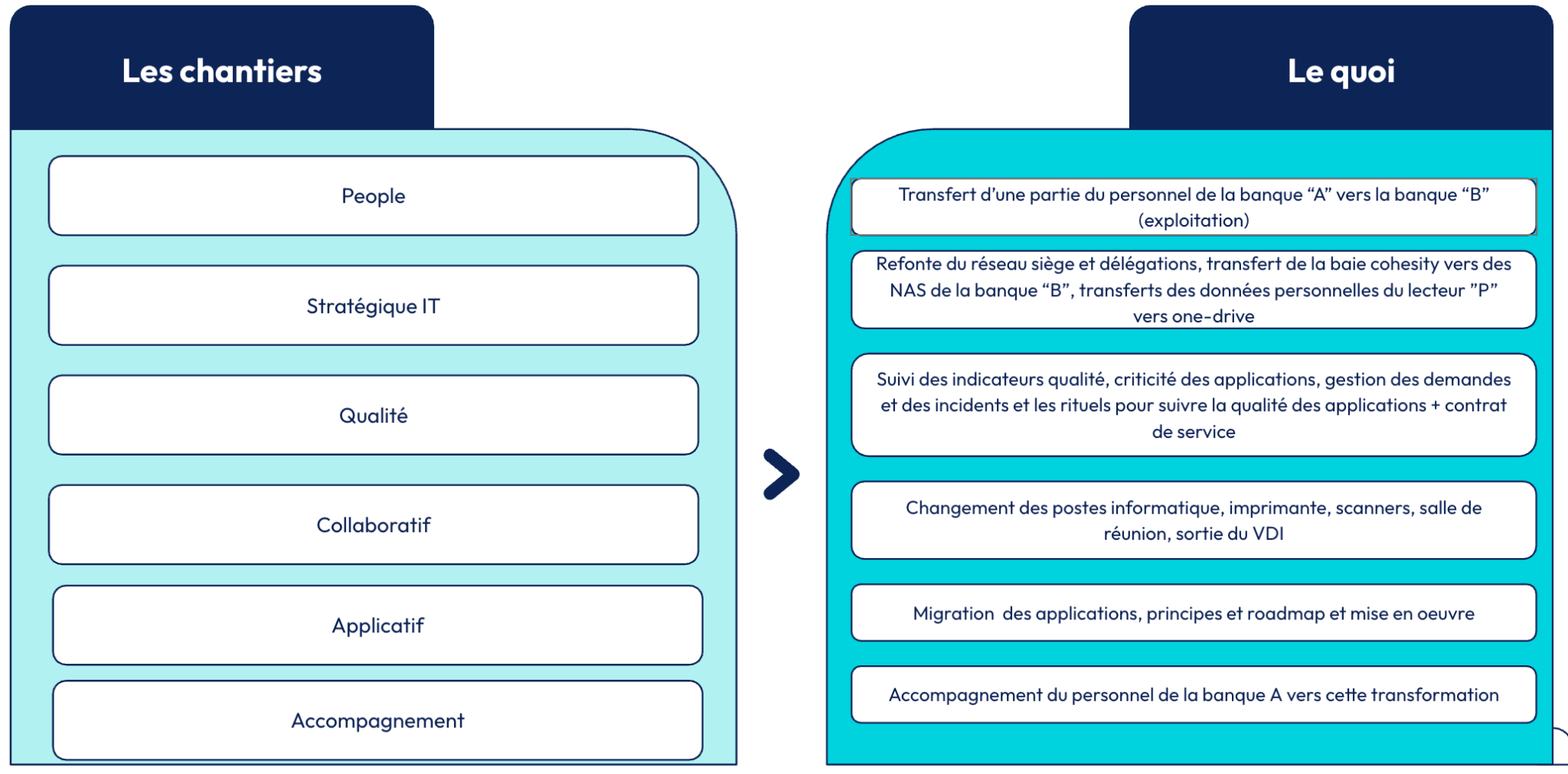
Que ce soit pendant l’étude en 2024 où au lancement du projet “CONNECT” toutes les équipes se sont mobilisés sur les quatre chantiers suivants :
- People
- Stratégique IT
- Qualité
- Collaboratif.
Il faut garder en tête que les équipes étaient auparavant autonomes et avaient la maîtrise de leur scope. Par ailleurs, certains chantiers préalables sont indispensables afin de permettre la migration au sein de la banque “B” afin de résorber une partie des problèmes techniques. On y retrouve notamment la modernisation du réseau ainsi que la sécurisation des baies de stockage des données de la banque “A” .
Même si ces chantiers étaient particulièrement importants pour la banque “A”, d’autres chantiers tout aussi prioritaires ont été planifiés ultérieurement dans la roadmap de notre client. C’est notamment le cas de la migration des applications de la banque “A” dans le contexte de la banque “B”. En effet, le chantier de reprise de l’exploitation du SI existant au sein du groupe va réclamer un effort particulièrement important.
D’autre part, personne n’avait défini les principes de migration et la stratégie à appliquer. C’est ainsi que nous nous sommes lancés dans la définition de ces principes ainsi que d’études plus détaillées afin de pouvoir discuter avec nos interlocuteurs de la banque “A” et “B” des conséquences du déplacement des applications d’un contexte à un autre.
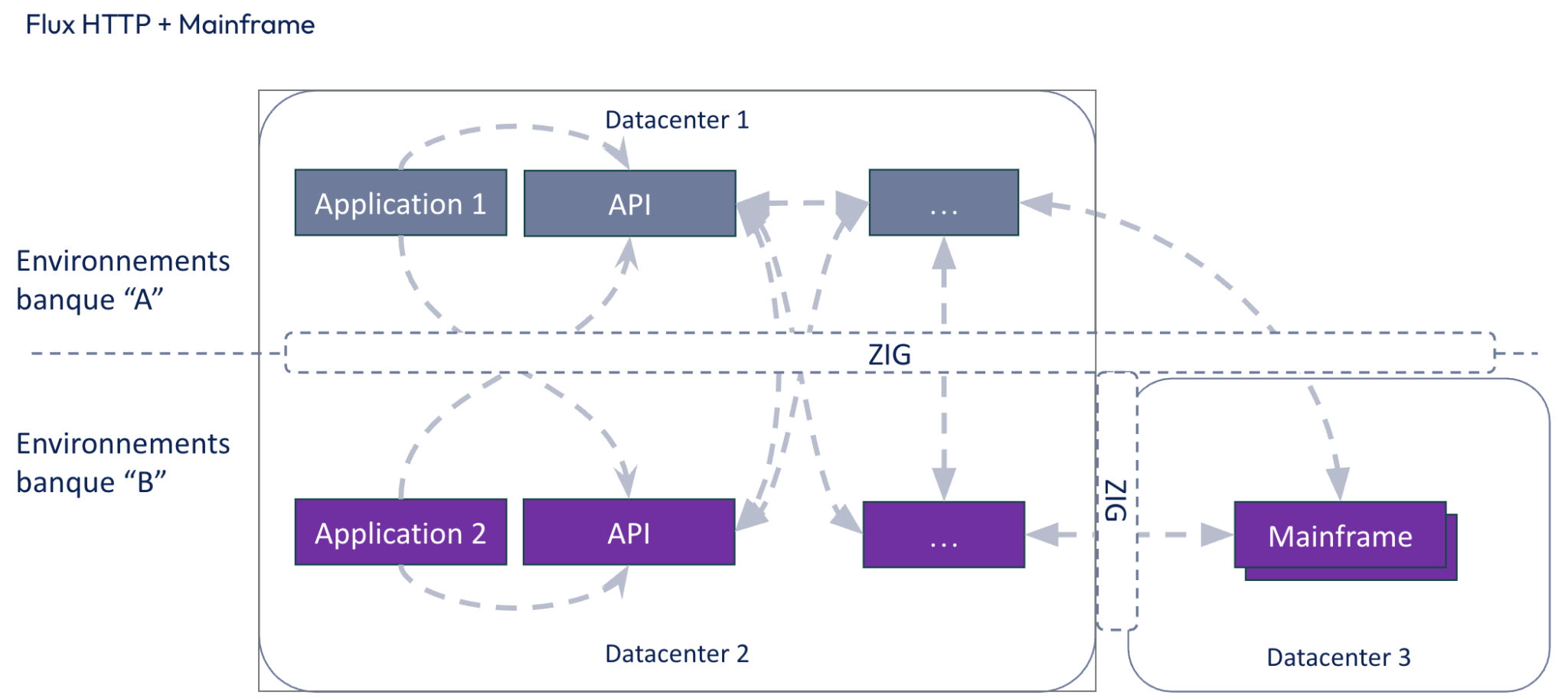
Exemple de schéma de principe permettant de définir les flux entre applications migrées et non migrées.
Stratégie de migration
Nous proposons tout d’abord à la banque “B” de réaliser un lift & shift : c’est la stratégie qui nous semble la plus appropriée au regard du contexte. Très rapidement la banque “B” refuse en indiquant qu’elle doit respecter les préconisations de la BCE à savoir moins de 10% de dettes sur les applications notamment celle stratégique.
La banque “B” nous propose alors de migrer les applications sur leur environnement de développement et de les moderniser avant d’aller sur MY CLOUD (l’infra OnPremise de la banque “B”).
Nous comprenons la demande mais nous pensons là encore que nous perdons de vue l'objectif initial qui est d'opérer le SI de la banque “A” dans une infrastructure de la banque “B”. Il est toujours intéressant pour l'infogérant de reprendre des applications à l’état de l’art qui correspond à son catalogue de service mais ici, ce n’était malheureusement pas le cas.
L’impact d’une telle décision n’est pas neutre car migrer plus de 80 applications peut prendre plusieurs années. Cela représente un coût financier et psychologique pour les équipes qui vont devoir gérer une partie d'un parc informatique côté banque “A” et une partie qui sera migrer pas à pas dans le contexte de la banque “B”.
N°3 : Le couplage de l’usine logicielle de la banque “A” vers la banque “B”
Pour migrer les applications il faut des chaînes d’intégration et de déploiement continue opérationnelles. C’est le cas au sein de la banque “A” et ”B”. Encore faut-il qu’elles soient compatibles ce qui n’est malheureusement pas le cas.
En effet, chacun opère des outils très différents :
- La banque “A” utilise du Gitlab, du Ansible, de l’ArgoCD et du Kubernetes
- La banque “B” quant à elle utilise du Jenkins, du Bitbucket, la stack XLDeploy et XLRelease et enfin le déploiement se fait sur OpenShift
Nous sommes face à deux mondes distincts !
En l’état; il est donc impossible de migrer une application de la banque “A” vers la banque “B”. Si les équipes de la banque “A” de développement doivent se conformer aux standards de la banque “B” cela implique de les former à leurs outils et d'utiliser deux usines logiciels. Ces contraintes nous apparaissent rapidement comme irréaliste et non viable en l’état.
Une autre difficulté que nous avons rencontré sur ce chantier était l’absence de sachants lors des échanges ainsi que l’indisponibilité des équipes finales. Leur implication aurait évité sûrement beaucoup d’incompréhension.
In fine, nous avons préconisé une approche hybride :
- Dans un premier temps, Gitlab génère les artefacts avec double publication lors du build. Le déploiement est géré côté banque “A”.
- Durant la phase de migration, les correctifs à chaud se feront sur l’ancienne UL de la banque “A” et devront être déployés du côté de la banque “B”.
- Le déclenchement de XL Deploy se fait depuis Gitlab pour aller au plus simple.
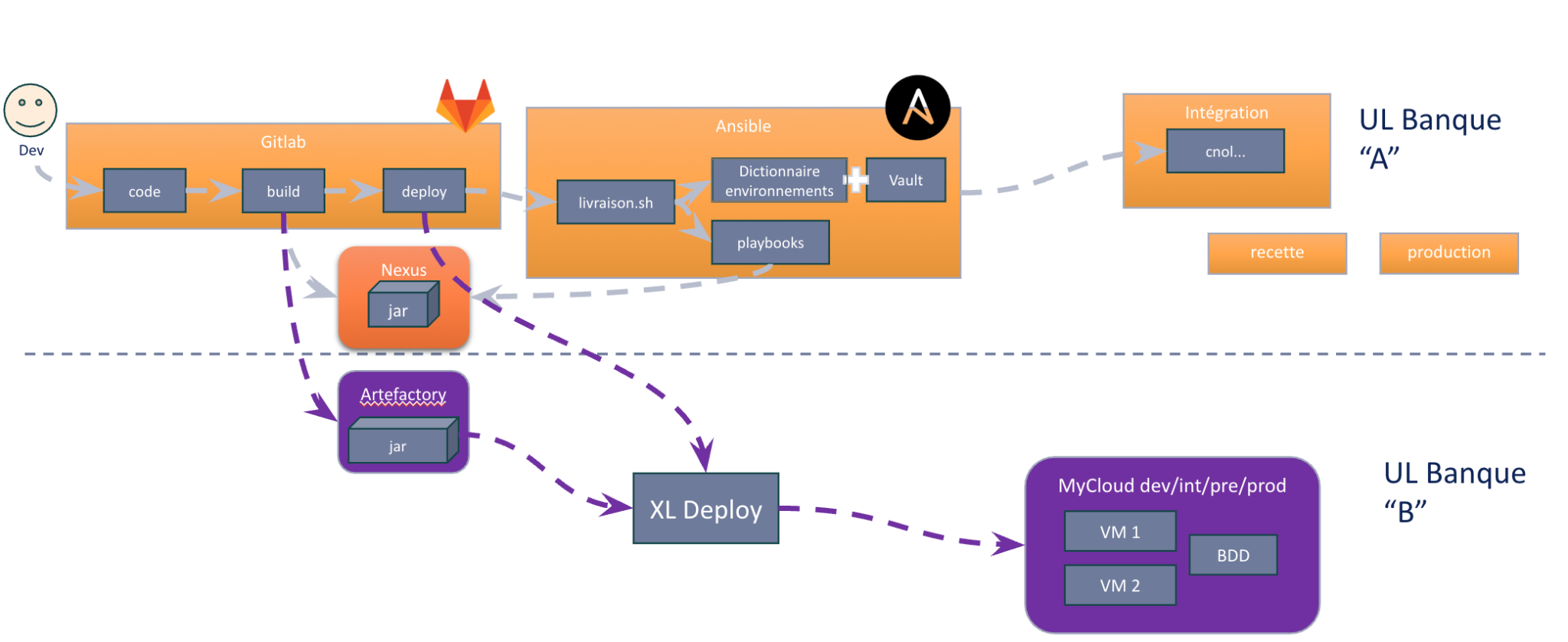
Schéma de principe de l’usine logicielle.
N°4 : Le socle d'infrastructure
En travaillant sur la CMDB (qui rappelons-le n’est pas exhaustive) nous constatons que le parc d'infrastructure de la banque “A” est obsolète et que certaines de leurs applications datent de plusieurs années (voir plus de dix ans). En effet, dans le déroulé de notre étude, nous partons de l’hypothèse qu’un OS obsolète héberge forcément une application obsolète.
Tout ceci vient complexifier la migration car il devient urgent d’upgrader les machines avant de pouvoir lancer la migration.
 |  |
|---|---|
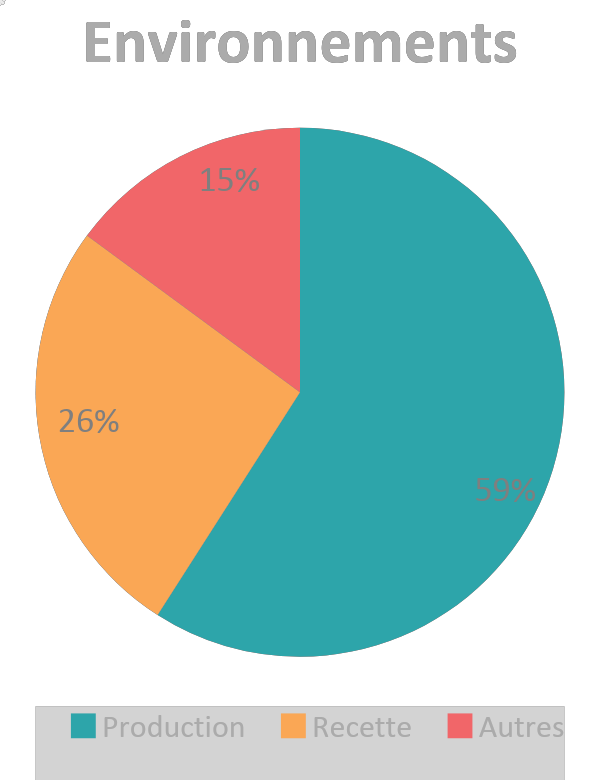 |  |
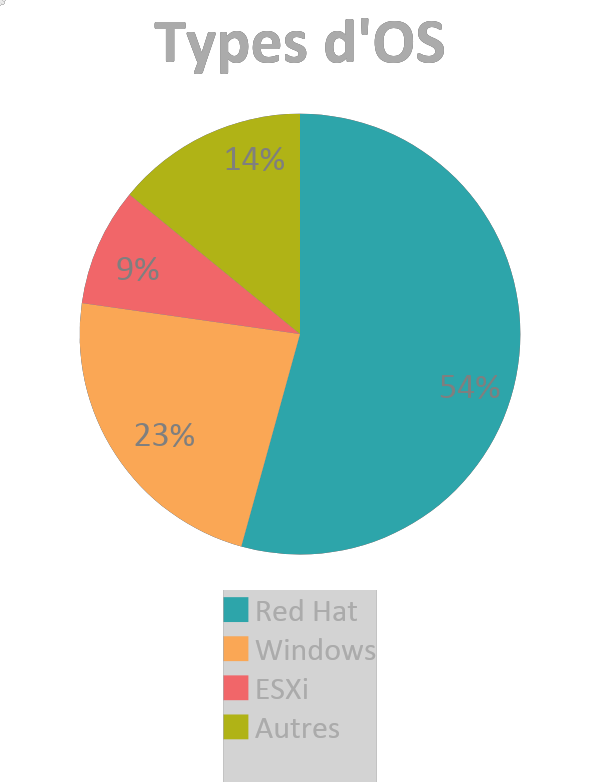
Quelques constats qui ressortent de nos travaux :
- 47 % des OS Linux et 66 % des OS Windows sont obsolètes
- 14% sont des OS non répertoriés (appliances, OS alternatifs, etc)
Dans le même temps, nous constatons qu’il est possible d’avoir un impact rapidement en appliquant quelques actions stratégiques :
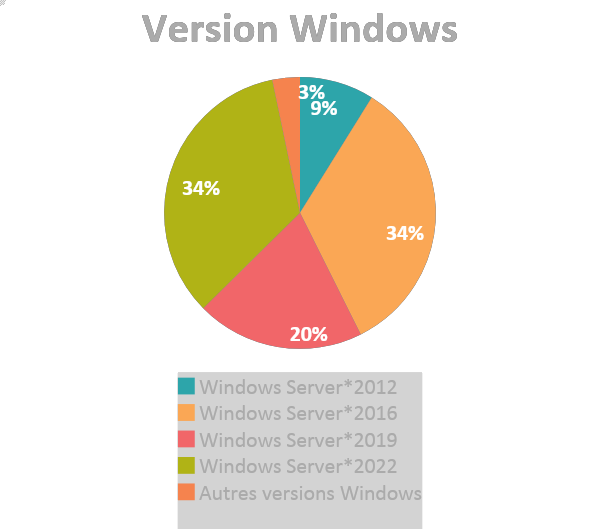
- Migration Windows 2016 & 2019 vers 2022 : passage de 66 % d’OS obsolète à 12 %
- Migration de la RHEL 7 vers RHEL 8 : passage de 47 % de Linux obsolètes à 18 %
- Pour les OS supportées, campagne de patchs afin de revenir à une situation plus tenable
N°5 : La roadmap de migration
Définir une roadmap sur plusieurs années est toujours un exercice périlleux surtout quand on ne lance pas la migration. En effet, le meilleur moyen de savoir faire quelque chose est de se confronter à la réalité.
Le premier point c’est que les avis divergent sur la stratégie à adopter. Faut-il commencer par :
- Certains pans fonctionnels ?
- En fonction des usages ?
- Utilisation d’applications critiques ou simples ?
- Privilégier les choses simples ou complexes ?
- Client lourd vs le reste ?
- ….
Le second point c’est que les principaux acteurs ne convergent pas sur la temporalité. Quelle est la durée pour finaliser la migration ?
Mon collègue Yannig et moi-même avons proposés plusieurs choses :
- Construire une grille et des abaques
- Proposé une roadmap 2026 (des chantiers activables)
- Réalisé un atelier pour classifier les principales applications en taille de t-shirt
Nos abaques de migration en prenant en compte 4 ans de migrations nous donne la conclusion suivante :
La cadence de migration pour respecter une durée de 4 ans suivra les contraintes suivantes :
- Livrer environ 19 applications par an
- Réaliser des migrations en parallèle
Les vacances et gels réglementaires imposent une cadence de 7 équipes en parallèle pour migrer 76 applications sur 4 ans (une année comprend donc 42 semaines)
Les chiffres restent challengeables comme tout prévisionnel, ce qui est important à nos yeux s’est l’expérimentation pour confronter les données à la réalité du terrain et d’ajuster tous les 6 mois ces abaques.
L’impact est fort car cela demande de mobiliser la quasi-totalité des équipes de la DSI sur cette transformation.
Et comme toute entreprise, elle est confrontée à des enjeux métiers forts et un projet stratégique qui impacte fortement les équipes de la banque “A”. Il n’y a pas de solution miracle, tout est une question de priorité et de dosage entre toutes ses initiatives.
Ce que nous tenons à souligner, c’est que plus une migration dure longtemps, plus cela coûte d’argent, plus il est difficile de mobiliser les équipes. Autre risque : les sachants sont susceptibles de partir en cours de route réduisant la connaissance globale du système.
Exemple de roadmap
N°6 : La criticité des applications de la banque “A” dans le monde de la banque “B”
Dans le cadre du chantier qualité l’ensemble des processus sont adaptés, revus pour s’intégrer aux processus de la banque “B”. Parmis de nombreux sujets que recouvrent le chantier qualité, il y a la notion de criticité et le temps de remise à niveau des applications lorsque celle-çi sont impactées.
La banque “A” et “B” ont deux approches différentes :
- Banque “A” : Vitale, critique et secondaire tiré d’un PCA avec une notion de retour de service “durée”
- Banque “B” : Classe de service A, B, C, D et Best effort. Toutes les classes ont un socle commun de caractéristiques à fournir (ex : DAT, DEX, Dossier de sécurité, schéma applicatifs,....) et des exigences variables en fonction de la classe. A étant la classe la plus exigeante et D et best effort la plus souple
La banque “B” propose d’intégrer les applications en classe D voir best effort au regard de leur matrice. De notre côté, nous proposons de garder le système de criticité existant : en réalité, les applications n’ont pas été encore migrées au sein des infrastructures de la banque “B” et les processus n’ont pas évolué. Les accès aux applications, les modes opératoires n’ont pas changé. Seules les équipes concernées ont été transférées de la banque “A” vers la banque “B”.
À la suite de cette discussion, il a été décidé de garder la notion de criticité de la banque “A” et de ne revoir la criticité de quelques applications.
N°7 : La gestion des demandes et des incidents
Point qui n’avait pas été forcément anticipé, la gestion des demandes et des incidents. Les processus, les workflows et les outils sont différents entre la banque “A” et “B”.
- Banque “A” : OASIS => Outil EASYVISTA.
- Banque “B” : SUN => Outil SERVICE NOW.
Un travail important a été fait pour :
- Identifier l’ensemble des processus et des workflows,
- Comparer les modes opératoires,
- Harmoniser si possible les processus entre les deux entités.
L’enjeu est crucial car les demandes ou les incidents auraient pu être attribués à des équipes spécialisées au sein de la banque “B” qui en réalité n’ont pas la “main” pour résoudre les tickets dans la mesure où elles ne connaissent pas les applications, les accès, l'infrastructure et les spécificités de la banque “A”.
Il a été convenu de trouver un moyen pour rooter les tickets aux anciennes équipes d’exploitation de la banque “A”.
En plus de ces difficultés, il a fallu également réaliser les actions suivantes :
- Nettoyer le backlog de la banque “A”.
- Communiquer sur le nouvel outil.
- Former les équipes.
- Préparer la bascule.
Des réussites collectives
Malgré les difficultés rencontrées, l’équipe a réussi à atteindre ses objectifs avec de belles réussites.
Voici ci-dessous une liste non exhaustive du travail accompli avec les équipes de la banque “A” et “B”
Référentiel de la banque “A” intégré au REFA de la banque “B”

Lancement des principes de migration, roadmap, convergence de la CI/CD

Lancement de l’atelier roadmap (en cours)
POC sur le couplage de l’usine logicielle (en cours)
Migration du “P” One Drive ⇒ Données personnelles des collaborateurs de la banque “A”

Migration de la baie Cohesity vers des NAS de la banque “B”

Réfection du réseaux filaire siège

Bornes wifi aux normes de la banque “B”

Déploiement des nouveaux postes informatiques pour le siège pour la banque “A” aux normes de la banque “A”

Mise en place du bar IT pour la gestion des demandes et des incidents

Contrat de service entre la banque “A” et “B” (en cours)
Transfert de l’outil de gestion de ticket de EASYVISTA vers SERVICENOW

Commande des nouvelles imprimantes et des scanners aux normes de la banque “B” (en cours)
Mise en place du chainage de proxy pour sortir pas à pas du VDI











Il reste a traiter le sujet qui pour nous est le cœur du projet “Connect” : la migration des applications de la banque “A”. Objectif final hébergé et infogéré les applications de la banque “A” par la la banque “B”.
Conclusions
Aucune migration ne se ressemble, elle dépend du contexte de votre client de sa maturité à gérer ce type de projet, de sa capacité à mobiliser des équipes qui pourront travailler sur le sujet de façon dédiés ou pas et de ses spécificités :
- Si des études en amont ont été menées, demandez les accès et surtout faites remonter à votre hiérarchie les incohérences et les points d’attention. C’est essentiel et vous évitera beaucoup d'écueils dans la préparation du lancement du projet.
- Obtenez un sponsorship fort. Un sujet de de transformation demande de l’implication et de pouvoir prendre des décisions parfois difficiles, d’orienter les équipes et de donner une trajectoire.
- Une organisation dédiée. Ce type de projet demande une organisation millimétrée et d’avoir des personnes dont l’implication est clairement identifiée : soit à 100% sur le projet soit un % bien défini. Vous n’avez pas forcément besoin de toute l’équipe au départ, vous pouvez très bien imaginer une montée en charge progressive. Si vous n’avez pas cela, le projet a peu de chance d’aboutir.
- Assurez-vous que des principes ont été posés et qu’une roadmap a été définie. Sans trajectoire vous risquez de perdre beaucoup de temps à aligner les équipes et les différentes parties prenantes.
- Vérifiez que des études ont été menées. Si c’est le cas, vous pourrez vous appuyer sur celle-ci et éventuellement remonter des alertes.
- Est-ce que votre direction est prête à lancer des expérimentations ? C’est le meilleur moyen de récolter du feedback et de vous projeter sur les transformations à prévoir.
- Quel est l’état du parc informatique que vous devez migrer (que ce soit au niveau applicatif ou sur l’infrastructure) ? C’est un bon moyen d’évaluer la complexité à laquelle vous allez être confronté (même si bien sûr ça ne sera pas la seule).
- Les usines logiciels : les pratiques sont-elles les mêmes entre les entités concernées ? Y’a t’il possibilité de trouver un pivot entre les deux ?
- L’outil de gestion de ticket est t-il le même ? Est-ce que les deux entités possèdent les mêmes pratiques ? comment contacter les équipes ? Comment déclarer une demande ou un incident ? Qui traite les tickets ?
- La notion de criticité est-elle la même entre les 2 entités ?
- La gestion des habilitations a-t-elle été prise en compte ?
Avec mon collègue Yannig Perré, nous n'avons pas envisagé cette migration sous l'ère de l’IA pendant notre mission. Nous avions peu de recul à l’époque et peu de REX chez nos collègues pour communiquer une trajectoire claire à notre client. Aujourd’hui nous pensons, qu’il serait intéressant d’intégrer l’IA pour accélérer cette transition ou en tout cas d’expérimenter.