REX : Refactoring d’un modèle de Machine Learning
L'industrialisation de l'IA s'impose aujourd'hui comme l'un des enjeux majeurs pour les entreprises qui souhaitent l'intégrer dans leurs écosystèmes : en effet, seulement 13% des projets IA make it to production ! Et qui dit industrialisation dit mise en production !
Pourtant, à une époque pas si lointaine, parler d'algorithme de ML était souvent synonyme d'obscures explorations de data scientists et d'artefacts incompréhensibles à ne surtout pas toucher une fois livrés en production. Heureusement, les choses ont changé et des pratiques pour mettre en production des systèmes intelligents de manière répétable et maitrisée commencent à émerger voire se démocratiser (on parle même de Continuous Delivery for Machine Learning).
Dans cet article, nous cherchons à partager un retour d'expérience sur la manière que nous avons adoptée dans un contexte de data science pour améliorer un code de Machine Learning qui tourne en production. Nous parlons aussi des moyens que nous avons mis en oeuvre pour garantir la non-dégradation du service actuel (que ce soit au niveau des prédictions en tant que telles, des performances du système, du routage des données, etc) et la validation continue des modifications apportées au système.
Ce retour d'expérience comportera donc une présentation du contexte, plus particulièrement du code de ML que l'on cherche à traiter et de ses spécificités, suivie des trois étapes structurantes dans la mise en production de ce modèle :
- l'étape incontournable de la validation des hypothèses de départ,
- l'étape de refactoring avec un zoom sur les solutions techniques que nous avons choisies pour garantir l'intégrité et la stabilité du système en production pendant le chantier
- l'étape "finale" d'adoption du nouveau code qui implique se couper du legacy et s'assurer que le nouveau modèle ne devienne pas lui-même un legacy impossible à maintenir.
Un contexte un peu particulier
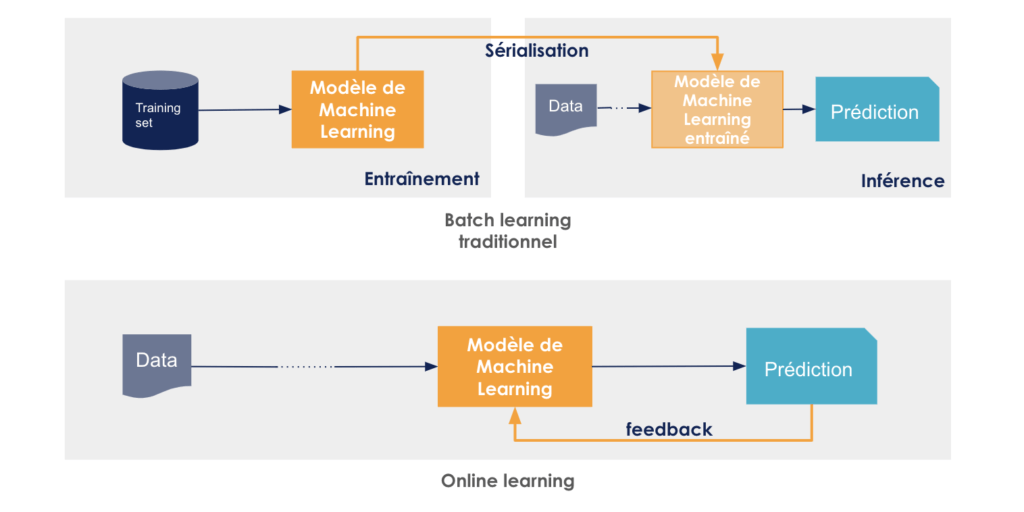
L'un des patterns les plus populaires en ce qui concerne le déploiement d'un modèle d'IA consiste en un modèle de Machine Learning ou de Deep Learning, supervisé, que l'on sérialise (c'est-à-dire que l’on prend un cliché du modèle dans son état actuel qui sera transformé en une suite d'informations plus petites, propice à l'échange ou à la persistance comme un flux d'octets ou byte stream, par exemple), que l'on monitore, et que l'on ré-entraîne ou améliore régulièrement. Ce pattern-là est notamment expliqué dans cet article de Google qui préconise l'automatisation de déploiement de modèle certes, mais aussi l'automatisation des étapes du réentraînement.
Mais que faire lorsque le modèle est un modèle homemade qui ne provient d'aucune librairie externe de type Scikit-learn ? Qui fait de l'online learning (par opposition au batch learning) ou de l'apprentissage en ligne c'est-à-dire qui se met à jour au fil de l'eau avec l'arrivée de nouvelles données ? Qui, finalement, n'est pas un modèle sérialisé "classique" mais "simplement" du code dockerisé qui tourne en production en ingérant en continu les données mises à sa disposition ? Dans ce cas-là, l'idée d'un ré-entraînement/amélioration du modèle dont le cycle de vie serait différent du cycle de vie de l'application n'a plus beaucoup de sens puisque la validité du modèle dépend du contexte de production et ne saurait en être découplée.
Cet article présente une manière d'améliorer un algorithme de ML dans ce contexte particulier, au travers d'outils et de méthodes pour sécuriser le refactoring et intégrer les changements le plus rapidement possible à la chaîne de production
Le use-case
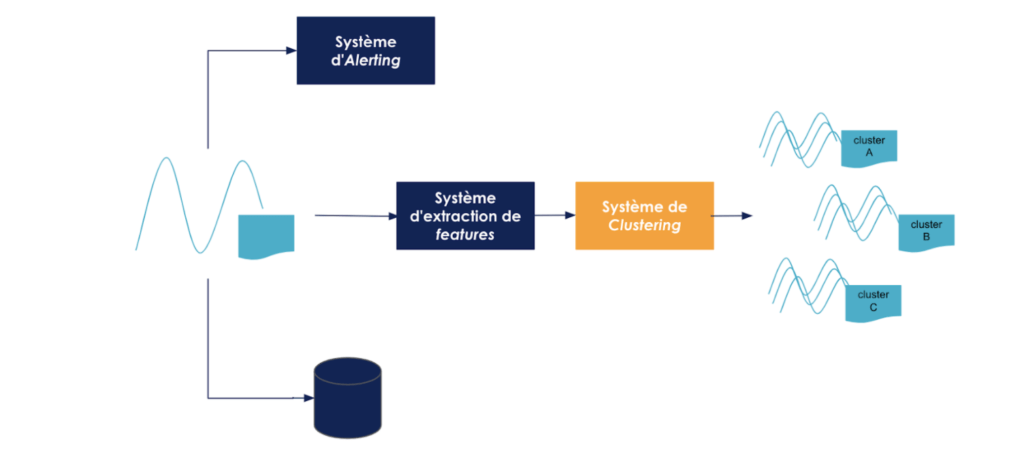
Le système dont il est question ici est un système de détection de défaut à partir de séries temporelles qui utilise une technique de clustering. Le système prend en entrée des signaux (Voltage/temps) accompagnés de metadata (pour des raisons de confidentialité, il est impossible de donner plus d'éléments de contexte). Le clustering permet de catégoriser les signaux afin de mieux détecter de potentiels problèmes au niveau de leur génération. Un worker analyse d'abord les signaux et génère des informations - ou features - fondées sur des règles définies par le métier et notre modèle de ML ingère les données ainsi obtenues et les regroupe en clusters.
Étape 1 : DO IT FAST ou valider les hypothèses de départ
Il est bon de se rappeler que le modèle de clustering est home-made dans le sens où ce n'est pas un modèle standard importé de Scikit-learn mais un modèle créé avec un processus de preprocessing et des métriques de mesure de similarité qui correspondent au besoin métier défini par l'équipe. Quelques exemples d'hypothèses émises : une tumbling window de taille arbitraire pour lisser les signaux, une métrique de similarité basée sur des déviations analogues par rapport à un signal de référence lequel serait le dernier signal reçu défini comme "normal", etc. De plus, le modèle est créé de telle sorte à faire de l'online learning : au fur et à mesure que le modèle rencontre de nouvelles données, il génère de nouveaux clusters.
De ce fait, il devient nécessaire de valider rapidement ces hypothèses-là en partant d'un principe simple :
DO IT FAST -> DO THE THING RIGHT -> DO THE RIGHT THING !
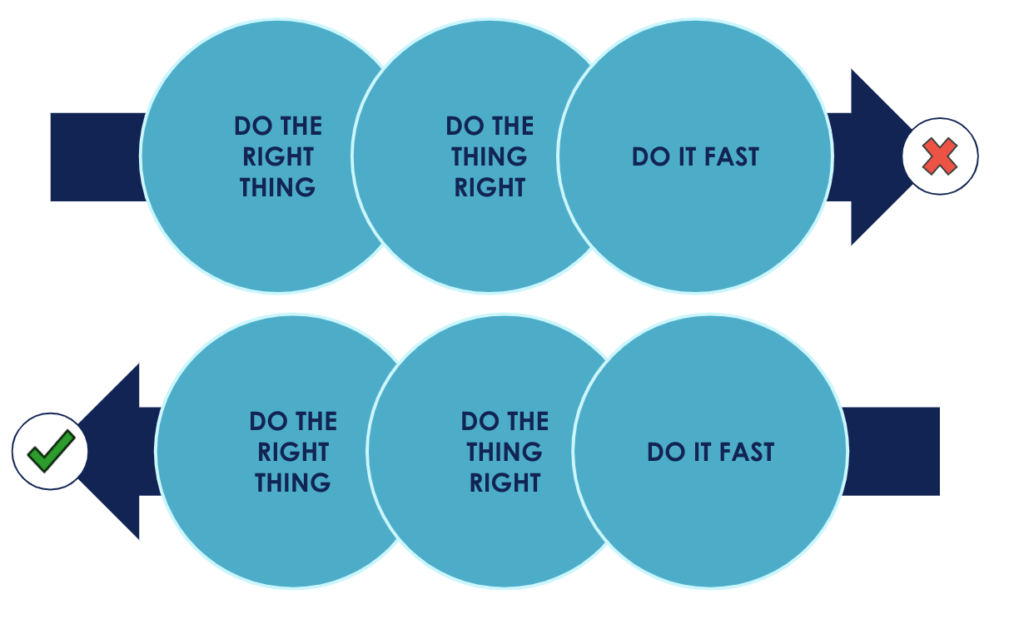
Pourquoi ? En livrant rapidement une version simpliste de la solution choisie, DO IT FAST, on est capable de récolter un feedback utilisateur le plus tôt possible et surtout avant de s'investir dans l'élaboration d'une solution optimale qui serait potentiellement caduque. Ceci étant fait et pour s'adapter efficacement aux changements fréquents présentés par l'utilisateur, on est forcément obligés de déployer en production d'une manière récurrente sans casser l'application : DO THE THING RIGHT ! Finalement, on devrait aboutir sur DO THE RIGHT THING qui découlerait naturellement d'un besoin utilisateur validé et d'une bonne qualité de développement !
Booking.com parlent notamment de l'importance du feedback dans cette publication et expliquent surtout que la performance du modèle et la performance business sont deux notions différentes, le premier ne conditionnant pas systématiquement le second. Ça ne sert donc pas à grand chose de s'acharner à optimiser la performance du modèle tant que la business value qui en résulte n'a pas été vérifiée !
De ce fait, la stratégie de l'équipe a été de mettre en production la première solution développée par le data scientist en l'intégrant dans la chaîne end-to-end de processing de signaux.
Ceci a permis de répondre à des questions fondamentales : le clustering était-il une bonne idée pour la détection des signaux anormaux ? Les paramètres choisis sont-ils efficaces ? La mesure de similitude regroupait-elle réellement les bons signaux entre eux ?
À noter que même si l'algorithme n'est pas custom ou même si, plus généralement, la solution semble triviale, la validation des hypothèses émises est une étape essentielle à tout projet afin d'éviter l'effet tunnel et la disjonction métier/technique ! Ceci est d'autant plus vrai dans le cadre de la conception d'un système de ML, lequel présente généralement de nombreux risques au delà de l'optimisation du modèle en tant que tel qu’il est nécessaire d'appréhender le plus tôt possible.
Étape 2 : DO THE THING RIGHT ou refacto du modèle en production
Après la validation du modèle mis en place, en d'autres termes, l'obtention du feedback métier relatif à l'utilisation de l'application et l'identification des points d'amélioration ou des solutions qu'il faut garder, il s'agit d'implémenter ces modifications-là et ce sans apporter de régressions au code qui tourne déjà en production ! Pour ce faire, nous cherchons à construire un écosystème où le feedback est obtenu le plus rapidement possible afin de modifier sereinement et de manière sécurisée le code livré.
La difficulté réside dans le non-déterminisme d'un algorithme de ML : le nouveau modèle va-t-il produire les résultats attendus par les utilisateurs ? Le pre-processing conviendra-t-il aux données de production ? (par exemple, le sous-échantillonnage des signaux est-il toujours nécessaire ? Faut-il ignorer les signaux avec un voltage négatif ou supprimer les points compromettants ? Comment définir le représentant d'un cluster ou centroid ?) D'autre part, si le modèle qui a été industrialisé est un modèle minimaliste difficile à maintenir, comment le refactorer et garantir la disponibilité en continu du système utilisé par des utilisateurs finaux ? En résumé, comment refactorer en continu l'existant sans casser la production ?
Cette interrogation s'inscrit avant tout dans un souci de maintenabilité et de robustesse de l'application si l'on veut qu'elle s'inscrive dans la durée.
La solution que nous avons choisie : adapter le concept du Blue/Green deployment à un algorithme de ML pour ne pas subir les aléas du non-déterminisme. Cette technique assez pérenne et plutôt connue est généralement utilisée pour minimiser le downtime de mise en production d'une nouvelle version de l'application. En mettant en production deux environnements et en les soumettant donc aux même contraintes les développeurs s'assurent de la stabilité de la nouvelle version. Cette approche peut être utile dans un contexte de machine learning afin de tacler le sujet de non-déterminisme : en effet, il s'agit non seulement de tester la stabilité du modèle d'un point de vue technique mais aussi de le soumettre aux données réelles de production pour mesurer sa précision.
Une technique relativement connue dans le monde du ML s'apparente au Blue/Green deployment : le concept du Shadow Model. Toutefois, nous avons choisi de parler de Blue/Green deployment ici pour insister sur le fait que l'objectif n'est pas uniquement de tester les performances du modèle en termes de prédictions. Nous cherchons à valider une implémentation complètement différente du worker et des considérations software "classiques" entrent en jeu aussi (des problématiques de performances, d'intégration, de scalabilité, etc).
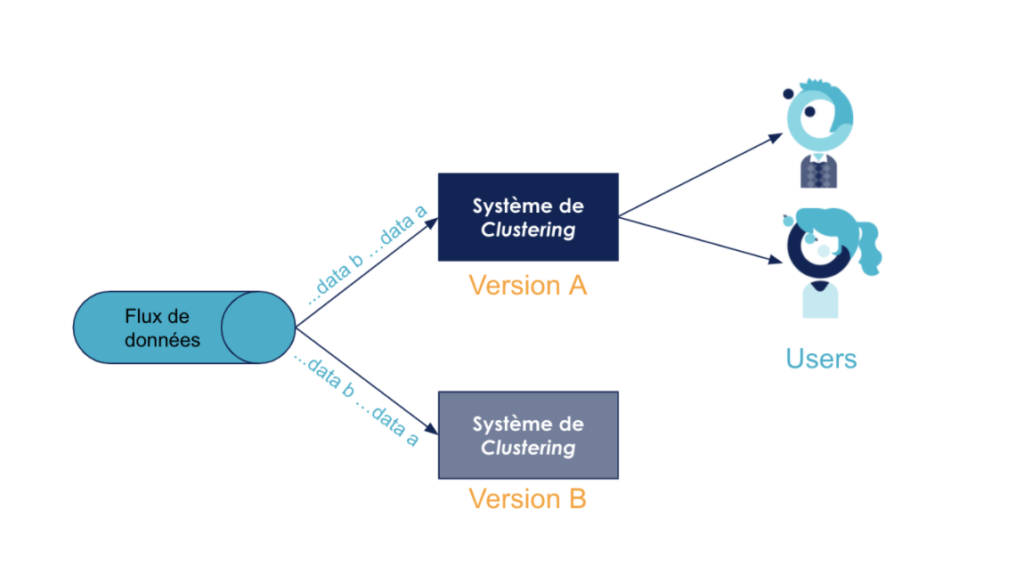
En pratique, deux workers ont été déployés en parallèle : le worker d'origine sur lequel tourne l'algorithme de production que l'on cherche à refactorer et un worker additionnel portant le nouvel algorithme lequel sera construit d'une manière incrémentale (en ajoutant progressivement des étapes dans le pipeline de preprocessing par exemple ou en modifiant les features initialement choisies, etc ). Cette technique entraîne un certain nombre de difficultés et contraintes supplémentaires. Nous avons identifié trois volets qui nous ont semblé essentiels à traiter pour réussir les déploiement en parallèle :
- La première contrainte à envisager lorsqu'on fait un Blue/Green deployment est le routage. Afin de tester efficacement le nouvel algorithme et de prouver sa supériorité par rapport à l'ancien algorithme en production, il faut comparer les sorties des deux workers ayant ingéré les même données en entrée. La solution relativement simple que nous avons adoptée est un mécanisme de communication de type publish/subscribe, le modèle étant un listener qui récupère les signaux à partir du message broker (dans notre cas Redis). Ainsi suffisait-il d'ajouter un nouveau listener abonné au même channel ou topic de messages.
- Le deuxième volet à ne pas négliger est le monitoring. Les deux applications doivent être observées, les prédictions comparées et les bugs détectés ! Une bonne stratégie de logging est essentielle pour monitorer les résultats de l'algorithme à tester : en particulier, logger le signal d'entrée (pour vérifier le bon fonctionnement du routage) et la prédiction de sortie ! Plus encore, d'autres outils tels que Sentry permettent de faire de l'exception management c'est-à-dire, principalement, capturer les erreurs (ou warnings si besoin). C'est une composante utile du monitoring mais qui ne remplace pas le logging !
- Finalement, le Blue/Green implique un déploiement rapide et en continu sur le nouvel environnement à tester. Cette mise en production rapide d'un nouvel algorithme a été surtout possible grâce à l'Infrastructure as Code. C'est du code descriptif qui permet de décrire l'état de l'infrastructure souhaitée et donc de facilement configurer des serveurs, lancer des containers Docker, etc. Dans notre projet, nous avons opté pour Ansible. En gérant ainsi notre déploiement, il est plus facile de le rendre scalable et flexible quant à l'ajout ou la suppression de services.
Au-delà du B/G Deploy et de ses implications, notamment côté Ops, le refactoring en tant que tel a son propre lot de difficultés à résoudre et de mécanismes à adopter afin que ça réussisse.
- Le premier facteur de réussite est la définition de cas de tests métier : on sait pertinemment que ML rime avec non-déterminisme mais certains use cases métier restent critiques et définissent ce qui fait qu'un modèle est valide ou pas. Les tests sur ces use cases indispensables ont un nom : il s'agit des Threshold tests. Dans le cas du clustering, on veut par exemple que tel et tel signaux critiques soient regroupés ensemble ou pour le cas d'une classification classique, on voudrait que telle donnée limite aie impérativement tel label… D'autres types de threshold tests consistent à définir un recall minimal ou peut-être une précision minimale (deux mesures standards de performance en ML). Dans notre cas, nous avions identifié des signaux-types que le métier avait désignés comme appartenant aux même clusters. A l'instar de tous les types de tests connus dans le monde du logiciel, ceux-ci apportent un feedback rapide sur la qualité du modèle et bloquent la mise en production d'un modèle non satisfaisant au travers de la pipeline de CI (Continuous Integration).
- Pour revenir à la notion de feedback, le refactoring est d'autant plus efficace qu'on est capable de valider rapidement un changement. L'IDE, par exemple, est la source de feedback la plus rapide. Une autre source de feedback est le typage. Python qui est utilisé dans beaucoup de projets de ML (notamment celui dont on parle ici) n'est pas typé. Cependant le type hinting - introduit à partir de python 3.5 - est une alternative utile au "vrai" typage puisque ça souligne les incohérences ou erreurs qui peuvent apparaître en codant et facilite la compréhension du code et de l'intention du développeur. On peut même aller plus loin avec les type checkers.
- Un autre élément qui nous a servi de ligne directrice durant le processus de refacto est la clean architecture. La clean architecture prône la séparation du code en plusieurs couches permettant d'isoler le coeur métier des choix d'infrastructure. Ci-dessous un bout de code représentant un use case dans le sens clean architecture, c'est-à-dire un cas d'usage métier traité par notre application : on peut clairement voir l'enchaînement des étapes (entre la récupération des anciens clusters et la publication du résultat du clustering). D'un côté, cette séparation en couches permet de tester en isolation les différentes fonctions qui existent et donc de sécuriser le refactoring. En séparant le modèle du préprocesseur, de l'agent de stockage, etc. on peut définir des cas différents de tests unitaires nous permettant de valider chacune des implémentations. D'un autre côté, s'affranchir de l'infrastructure permet de remplacer une technologie par une autre très facilement : typiquement, publier les résultats sur un Redis au début du refactoring puis passer à une base de données relationnelle en changeant de publisher ! Dans une architecture qui se veut évolutive, il est nécessaire d'avoir la possibilité de modifier ses choix techniques selon ce qui est le plus adapté au produit plutôt que de subir ces choix et les traîner tout au long du projet.
class ClusterSignal:
def __init__(self, signal_cluster_publisher: SignalClusteredPublisher, signal_clustering: SignalClustering, cluster_repo: ClusterRepository):
self.publisher = signal_cluster_publisher
self.signal_clustering = signal_clustering
self.cluster_repo = cluster_repo
self.number_generator = ClusterIdGenerator()
def handle(self, signal_received: SignalReceived):
past_clusters = self.cluster_repo.get_clusters(signal_received)
optional_cluster = signal_clustering.allocate_cluster(signal_received, past_clusters)
if optional_cluster:
if not optional_cluster.is_default():
self.cluster_repo.save_cluster(signal_received.get_meta_information(), optional_cluster)
signal_clustered = SignalClustered(signal_received.signal_data, optional_cluster)
self.publisher.publish(signal_clustered)
- On ne le répètera jamais assez mais travailler en petits incréments est essentiel pour réduire drastiquement la complexité de la tâche à effectuer. En l'occurrence, le refactoring dans le cas présent. Ce qui a fonctionné pour nous : commencer, par exemple, par le preprocessing en déployant un premier jet de l'application et s'assurer - au travers des logs - que tout fonctionne comme prévu, puis gérer le clustering dans un second temps, et finir par la publication des résultats dans le storage prévu à cet effet.
Étape 3 : DO THE RIGHT THING ou kill the legacy
Le refactoring est maintenant terminé et deux Clustering Workers tournent en production. La stabilité technique du nouveau modèle - et plus généralement de toute la pipeline de traitement de données - a été établie. En d'autres termes, les logs de la nouvelle composante sont normaux, Sentry ne signale pas d'exceptions graves, le modèle de clustering tourne rapidement… D'un autre côté, celui-ci semble répondre aux exigences du métier au vue des prédictions sauvegardées dans Redis. Bref, il est temps de se débarrasser de l'ancienne pipeline.
Premièrement, il faut "débrancher" l'ancien modèle, c'est-à-dire ne plus se servir de ses prédictions dans les autres briques de l'application et ne plus lui fournir des données en entrée. En parallèle, la nouvelle composante, laquelle est déjà pratiquement intégrée dans l'application principale, n'a plus qu'à publier ses prédictions dans le bon channel Redis !
Nous avons également mis en place une autre maille de sécurité : un environnement de qualification ou preprod sur lequel va être déployée la nouvelle application pour pouvoir tester en end-to-end l'intégration des différentes briques de l'application avec ce "nouvel" élément.
Kill the legacy ne revient pas seulement à supprimer le code "ancien" ! Nous cherchons surtout à ne pas reproduire un legacy impossible à maintenir en offrant plus de possibilité d'évolutivité et de maintenabilité.
Le modèle étant custom et faisant de l'online learning, il ne s'agit pas de faire des ré-entraînements isolés et de pluger les nouveaux changements dans l'application mais plutôt de trouver un moyen de permettre l'évolution du modèle de manière simple sans devoir passer par du Blue/Green deployment à chaque fois.
Etant conscient du caractère volatile de la matière que nous travaillons, nous voulons nous donner les moyens techniques de ne pas être gênés par cette volatilité. Certains hyperparamètres ont donc été identifiés comme potentiellement modifiables. Le choix qui a été fait pour apporter de la flexibilité est d'extraire ces paramètres-là en variables d'environnement pour permettre ainsi aux data scientists de modifier aisément ces éléments sans forcément rentrer dans le code.
Ainsi est-il intéressant d'essayer d'identifier et d'isoler à l'avance les sources fréquentes de changement, et ce surtout quand le modèle n'est pas "figé". L'idée est, plus généralement, de se rendre compte que le machine learning comporte des phases récurrentes d'exploration et qu'on doit se préparer à cette évolution continue et rapide.
La dernière étape consiste à supprimer le code legacy. Le code étant versionné, il est toujours possible de retrouver les anciennes versions si nécessaire.
Conclusion
L'objectif de ce REX n'était pas de présenter une autre architecture pour faire tourner une application de ML en production (surtout que le cas d'usage dont il est question ici est très particulier) mais plutôt d'introduire une nouvelle manière d'appréhender une application de ML.
En d'autres termes, nous préconisons d'envisager la mise en place d'une brique de ML comme un processus d'amélioration continue et de s'éloigner de la vieille méthode : exploration/POC pendant 6 mois puis mise en production du résultat de ladite exploration.
L'alternative que nous proposons est d’aller rapidement en production avec une intégration de la brique ML dans la chaîne applicative le plus tôt possible.
Ceci implique forcément l'adoption de bonnes pratiques de devops, notamment le monitoring, les tests ou une CI/CD. Nous cherchons donc à donner quelques pointeurs utiles pour y parvenir : le Blue/Green deployment, l'exception management, l'Infrastructure As Code, la Clean Architecture…
Finalement, le feedback récolté rapidement permet de s'adapter et de choisir la solution qui apporte le plus de valeur. L'équipe doit alors se donner les moyens de maintenir le code produit en identifiant les points de variabilité du ML et en trouvant des solutions pour gérer cette variabilité. Ceci fait, reste plus qu'à killer le legacy...