Réussir ses projets de data science en 2021
Pour cette nouvelle année 2021, nous souhaitons vous proposer 10 convictions qui vous permettront de mieux réussir vos projets de Data Science. Ces convictions sont inspirées de notre quotidien, de nos lectures et des évolutions du marché de la Data Science que nous observons chez OCTO.
- Livrer continuellement un petit incrément de valeur en production
- La Data Science, c’est aussi (et surtout) une matière informatique
- Appliquer les principes d’Accelerate aux projets Data Science
- Maîtriser la complexité des systèmes de Data Science
- Constituer des équipes autonomes et responsables sur tous les pans du projet
- Centraliser ? oui, mais pour mieux diffuser !
- Progresser ensemble
- L’UX au service de la Data Science qui marche
- Construisez ce que vous voulez maîtriser
- Métier et Data Scientist ont les mêmes objectifs
1. Livrer continuellement un petit incrément de valeur en production
“Notre plus haute priorité est de satisfaire le client en livrant rapidement et régulièrement des fonctionnalités à grande valeur ajoutée.” - Premier principe du manifeste agile.
Tout d’abord, nous souhaitons préciser que la production n’est pas l'environnement qui s’appelle production, mais l’endroit où les utilisateurs peuvent accéder à la solution avec une qualité de service sur laquelle nous nous sommes alignés avec eux au préalable.
Ainsi, en commençant le développement d’un projet, l'objectif est de produire le plus rapidement possible (en quelques semaines, idéalement en quelques jours) une solution minimaliste. Puis donner à quelques utilisateurs pilotes accès à celle-ci.
Cette solution minimaliste peut inclure un certain nombre de tâches manuelles (par exemple une capture d’écran pour envoyer le résultat par email à l’utilisateur). Dans la suite du projet, l’automatisation se fera par petits lots que l’on découpera, estimera et priorisera au même titre que les autres fonctionnalités. Une façon de prioriser est d’identifier la tâche la plus douloureuse ou celle qui prend le plus de temps.
Une des tâches à automatiser est le déploiement d’une nouvelle version de la solution. Cela peut se faire avec un pipeline de Continuous Integration / Continuous Deployment. Ce pipeline, qui lui aussi doit être construit itérativement, permet de faciliter la livraison de petits incréments en production.
Nous cherchons à livrer rapidement et régulièrement en production pour avoir une boucle de feedback rapide. La boucle de feedback et la nécessité de très vite l’établir est sans doute encore plus importante dans un projet de Data Science. En effet, on implémentera ni plus ni moins qu’une tâche cognitive dans un tel projet. S’assurer qu’il apporte réellement de la valeur à nos clients, nos collaborateurs, qu’il n’automatise pas ou qu’il ne diffuse pas nos biais inconscients, etc. tout cela mérite de très rapidement mettre en place ces boucles de feedbacks.
Les anti patterns que l’on croise couramment sont :
- Le sprint 0 où les Ops travaillent d'arrache-pied pour mettre en place toute l’infrastructure et toute l’Usine De Développement (UDD). Au même titre que le code applicatif, l’infrastructure et l’UDD doivent être construites itérativement pour répondre aux besoins réels du projet.
- Faire des phases longues de POCs, puis d’industrialisation, puis de mise en production. Il convient d’éviter les sprints uniquement d'exploration, et privilégier des cycles plus rapides. Par exemple : implémenter une petite idée en quelques heures / jours, l’exposer à quelques utilisateurs (en faisant de l’A/B testing par exemple), et si l’expérimentation est concluante, l’intégrer dans la base de code.
2. La Data Science****, c’est aussi (et surtout) une matière informatique
La plupart des entreprises traditionnelles ont découvert la Data Science au cours de la dernière décennie. Pour ces entreprises, la Data Science a surtout été une histoire de Proof of Concepts (POCs) et le mandat des Data Scientists a été d’identifier les bons cas d’usages et de prouver que la Data Science avait du potentiel par rapport aux méthodes traditionnelles. Dans ce contexte, le Data Scientist a alors été surtout perçu comme un mathématicien dont le code était un outil parmi d’autres, mais pas une réelle expertise.
L’enjeu pour la Data Science d’aujourd’hui est d’être enfin utile pour ces entreprises, c’est-à-dire d’être en production avec de vrais utilisateurs. Assez naturellement, la Data Science (re)devient avant tout une matière informatique. Il serait contreproductif d’y voir une dichotomie entre des Data Scientists qui maîtrisent le machine learning et des informaticiens chargés d’implémenter les POCs des Data Scientists, pour les mêmes raisons que la dichotomie entre MOA et MOE* n’a pas permis de tirer pleinement parti de l’informatique dans les organisations. D’ailleurs, on ne retrouve pas ce genre de pattern organisationnel au sein des entreprises dans lesquelles la Data Science est critique dans la chaîne de création de valeur.
Ainsi, il convient de diversifier son recrutement et la formation continue : les Data Scientists au background teinté science fondamentale devront passer plus de temps sur l’apprentissage du développement informatique. Les Data Scientists venant de l’informatique passeront plus de temps à continuer à se former sur les matières scientifiques. La cible est la même pour tous les profils : des professionnels capables de maîtriser la théorie mathématique derrière la Data Science et capables d’implémenter leurs idées.
Afin de réduire la distance et favoriser le dialogue entre Data Scientists et les autres IT Doers, il convient aussi de démystifier la Data Science pour ces derniers. Fini le temps où les uns regardent les autres comme des dieux ou comme des exécutants, c’est le temps de la collaboration et la compréhension mutuelle des contraintes.
*MOA : Maîtrise d’ouvrage, MOE : Maîtrise d’Oeuvre
3. Appliquer les principes d’****Accelerate aux projets Data Science
La Data Science est une branche du développement logiciel (cf la conviction précédente), et un peu plus. Notre expérience nous a amené à identifier quelques spécificités aux projets Data Science :
- Davantage d’incertitudes : En plus des expérimentations classiques du développement logiciel, il y a celles liées à la question “Est-ce qu’il y a du signal dans les données ?”.
- De nouveaux artefacts à manipuler : des annotations, des modèles, …
- Des comportements atypiques : Des règles de gestion inférées des données au lieu d’être le résultat d’instructions impératives.
- Des nouvelles tâches : Entraînement de modèles, annotations de données, etc. à intégrer dans le flux de valeur, à tester, à monitorer.
- Des problématiques de déploiement différentes : Automatisation de l’entraînement de modèles, exposition de modèles.
- Des nouvelles compétences : Data Science, Data Engineering, MLOps, etc. qui se silotent et qui mélangent des cultures (chercheurs et ingénieurs, mathématiciens et développeurs).
- Un changement du rapport à la donnée : En data science la description des données n’est pas suffisante, il faut l’intégralité de celles-ci. Par exemple, pour développer un projet sans Data Science, savoir que dans les données il y a une variable “Moyen de transport” contenant les valeurs “Vélo”, “Voiture”, “Bus” est souvent suffisant, là où en Data Science il faut connaître la distribution et les interactions avec les autres variables. Cela fait qu'une partie du comportement du logiciel embarquant de la Data Science est dépendante des données et n’est pas directement contrôlable par le développeur. Cela a également un impact sur la gestion des données pour le développement et pour les tests.
En tant que matière informatique, la Data Science doit s’inspirer des bonnes pratiques du développement logiciel, que ce soit l’agilité, le devops, et maintenant Accelerate.
Accelerate est le titre d’un livre paru en Avril 2018 qui démontre, chiffres à l’appui, que la performance logicielle est déterminée par la faculté à livrer le plus souvent possible. Faire mieux, plus vite et à l’échelle, c’est une réalité accessible : pour y arriver, ce livre donne 24 capacités concrètes à mettre en œuvre dans votre organisation, des tests automatisés à la réduction de la taille des projets ou tâches en passant par la transparence de l’information et le découplage de l’architecture. Ce livre est une des sources d’inspirations importantes d’OCTO depuis 1 an.

Pour "accélérer" vos delivery de Data Science vous pouvez commencer par mesurer les quatres métriques proposées :
- Fréquence de déploiement,
- Délai de livraison d’une fonctionnalité développée,
- Délai de réparation d’un défaut,
- Taux d’échec sur changement.
La deuxième étape consiste à identifier où est-ce que vous devez vous améliorer en premier, pour cela, nous suggérons de répondre, en équipe, à l’accelerate quick survey. Afin d’identifier les capacités où vous pouvez vous améliorer le plus.
La troisième étape consiste à choisir une ou deux capacités, de préférence technique pour commencer (car plus simple à mettre en place), afin de commencer à accélérer vos projets.
Même si le livre est principalement tourné autour du développement logiciel, et malgré les spécificités présentées ci-dessus, nous avons trouvé qu'il s’applique également très bien au projet de Data Science. Nous vous proposons de discuter avec votre équipe de comment les capacités que vous avez sélectionnées se déclinent sur votre projet.
4. Maîtriser la complexité des systèmes de Data Science
La Data Science est un domaine complexe, ne le compliquons pas inutilement.
Les Data Scientists ont parfois tendance à aller chercher des algorithmes élégants, complexes, à l’état de l’art en oubliant d’essayer des choses simples. Souvent une règle métier codée en dur permet d’avoir une performance suffisante ou peut au moins servir de référence. Nous ne sommes pas tous un géant du web, nous n’avons pas tous besoins de solutions hyper pointues pour résoudre nos problèmes. D’ailleurs, dans cet article, Google recommande de commencer par des solutions sans Machine Learning.
Un exemple de règle métier simple pour commencer en prédiction météo est de prédire pour demain la météo du jour. Cela s’appelle la méthode de persistance. Elle est performante à 70%.
Pour faciliter la mise en production, pour augmenter la maintenabilité, l’auditabilité et l’explicabilité du système, il faut s’assurer que l’on a le niveau minimum de complexité nécessaire pour atteindre les objectifs. Cela rappellera sans doute au lecteur le rasoir d’Ockham, ou le lean qui vise une production sans déchet. Cependant, faire des choses simples et minimalistes est un exercice long et difficile. Blaise Pascal disait “Je vous écris une longue lettre parce que je n'ai pas le temps d'en écrire une courte.”
Une méthodologie pour maîtriser la complexité du système pourrait être de :
- Mettre en place une règle métier simple que l’on identifie lors d’ateliers avec les experts métiers
- Mesurer la performance, et si elle n’est pas suffisante :
- Ajouter un peu de complexité (règle métier plus complexe, nouvelle donnée, nouvel algorithme, nouvelle fonctionnalité, etc.)
- Recommencer le 2.
Pour mesurer la performance, il est souvent nécessaire de faire interagir le système avec des utilisateurs. Nous vous encourageons à le faire dans la conviction “L’UX au service de la Data Science qui marche”. Cependant, pour éviter de mettre à disposition de milliers d’utilisateurs une solution non fonctionnelle ou pas assez performante, il est possible de mettre en production le système auprès de quelques utilisateurs pilotes. Veillez, dans ce cas, à définir une performance minimale nécessaire à atteindre pour déployer la solution auprès de tous les utilisateurs.
En ayant eu cette démarche, l’équipe est capable de tracer un graphique de performance du modèle au fil des expérimentations. Le graphique ci-dessous, certes un peu idéalisé, représente sur l’axe des abscisses le temps, sur l’axe des ordonnées la performance du modèle, en bleu la performance du système, en orange la performance minimale pour déployer à tous les utilisateurs.
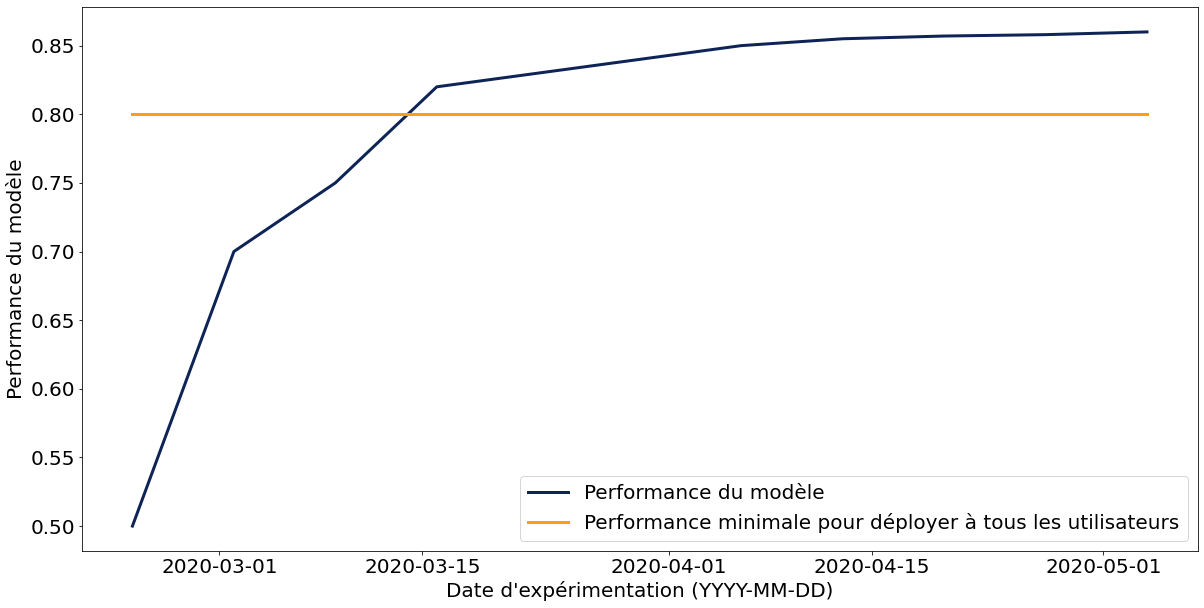
Lorsque la performance minimale est atteinte, le système est mis à disposition de la totalité des utilisateurs (et non plus uniquement des utilisateurs pilotes). Une fois cela fait, il est possible de continuer à expérimenter pour améliorer le système. Finalement, lorsque les nouvelles expérimentations n’apportent plus de gains significatifs, l’effort de développement se concentre sur le maintien de la performance dans le temps (monitoring, réentrainement) et sur d’autres projets.
Partager le graphique proposé ci-dessus permet d’établir une transparence entre l’équipe de développement et le métier et peut permettre un arbitrage entre l’investissement dans une nouvelle expérimentation et le développement de nouvelles fonctionnalités.
5. Constituer des équipes autonomes et responsables sur tous les pans du projet
Combien de temps avez-vous passé au cours de votre carrière à vous aligner avec des dizaines d’interlocuteurs pour essayer de faire avancer un projet ? Combien de projets avez-vous connus où tous les interlocuteurs avaient des enjeux différents, des roadmaps différentes ?
Une façon de faire pour favoriser l’alignement est de rassembler tous les faiseurs dans une seule équipe, que l’on pourra appeler squad par exemple. En fonction du sujet à traiter, la squad intègre un ou plusieurs Data Scientist, Data Engineer, Ops, Product Owner, UX, développeur full stack, etc.
En cas d’équipe distribuée géographiquement ou forcée de télétravailler, les pratiques suivantes peuvent permettre de simuler la colocalisation : deux daily plutôt qu’un seul, avoir un salon vidéo où les membres de l’équipe peuvent se retrouver à tout moment, digitaliser la totalité des outils, … Une équipe d’Octo a fait un retour d’expérience approfondi sur ce sujet dans cet article de blog.
Pour permettre à l’équipe d’avancer, il convient de lui donner de l’autonomie sur son périmètre, quitte à le réduire et à limiter les dépendances. L’autonomie doit également porter sur les outils (ex : compte administrateur, accès à des bacs à sable, des serveurs de calcul, accès aux données, etc.)
Une des tâches des leaders est alors de s’assurer, voire d’augmenter l’autonomie des équipes.
6. Centraliser ? oui, mais pour mieux diffuser !
Vu le rôle de plus en plus prépondérant et critique (pour ne pas dire politique) que prend la Data Science dans les entreprises, il n’est pas rare d’assister à des débats passionnés sur le positionnement dans l’organisation de la Data Science. Côté Métier ? Côté IT ? Dans une organisation transverse dédiée ? Dans un incubateur ?
Il n’y a pas de réponse absolue à cette question tant cela dépend du contexte et des ambitions de chaque organisation. À l’extrême, pour les quelques entreprises possédant déjà une très forte culture data, chez qui la Data Science fait partie intégrante de la chaîne de production, centraliser les compétences Data Science au sein d’une équipe va sembler farfelu. Alors que pour toutes les autres, une réponse souvent observée dans les entreprises françaises est précisément la création d’une équipe dédiée en central : le fameux Datalab.
Il convient alors de bien identifier les opportunités et les risques qu’offre une centralisation des compétences dans une équipe dédiée de ce type.
Il faudra notamment être très vigilant au syndrome “Tour d’Ivoire” qui sera le destin naturel d’une équipe de “Data Scientists col-blancs” si aucune énergie n’est déployée pour la contrer.
On peut y voir un précédent pas si ancien avec les cellules d’architectures transverses mis en place il y a une quinzaine d’années. “L’architecte, c’est rare, c’est important et c’est différent de ce qu’on a l’habitude de faire”. Pas besoin d’en dire plus pour créer une toute-puissante cellule d’architectes transverses qui passe la plupart de son temps à réfléchir à des normes souvent perçues par les projets comme hors-sol ou tout du moins contraignantes. On en oublie vite les rôles fondamentaux de ces cellules transverses, à savoir à court terme, communiquer, diffuser, aider les projets ; à plus long terme, transformer.
S’il convient dans nombre de contextes de centraliser les Data Scientists au sein d’un Datalab, il faudra prendre des mesures énergiques pour éviter ce syndrome. Comme évoqué plus haut, communiquer, diffuser, aider les projets à aller jusqu’en production ou encore animer une communauté doivent faire partie intégrante de la mission du datalab; transformer l’organisation encore plus.
Une autre façon de lutter contre ce syndrome pourrait être d’intégrer des Data Scientists dans des projets informatiques classiques où ils auront le rôle d’identifier des poches de valeur ajoutée ou de résoudre certains problèmes avec de la Data Science et les implémenter.
Dans tous les cas, le sens même d’une équipe Data Science en central doit régulièrement être questionné. Il serait même sain de donner au Datalab l’objectif de s’auto-disrupter, signe de sa contribution réelle à la transformation globale de l’entreprise.
7. Progresser ensemble
Actuellement, il est difficile de recruter des profils expérimentés en Data Science, Data Engineer, etc. car le marché est très tendu : beaucoup de demandes et peu de profils. Des formations se sont développées à partir de 2014 - 2015 il y a donc un principalement des profils débutants sur le marché.
Les défis “ressources humaines” des organisations sont alors de conserver les talents, de faciliter la transmission du savoir entre les profils expérimentés et les profils jeunes ou en reconversion. Ces deux défis peuvent être adressés en leur permettant de former et de se former.

- Pratiquer le compagnonnage : travailler au quotidien avec des pairs pour se former en faisant. Pour cela, il est possible de pratiquer le pair programming ou le mob programming qui consiste à coder à plusieurs en partageant un seul écran et un seul clavier pour développer une fonctionnalité.
- Partager ce qui nous passionne : par exemple sous la forme d’une petite conférence d’une heure le midi (nous appelons cela un Brown Bag Lunch - BBL) pour parler de nos sujets d’intérêts. Chez Octo, nous avons tous les midis un ou deux BBL proposés par les Octos pour parler d’Ops, de Data, d’écologie, de cuisine, de code…
- Prendre du recul sur les façons de faire afin de les améliorer : Pour cela, nous avons deux pratiques. La première est la rétrospective (rituel proposé par SCRUM) qui consiste à prendre une à deux heures régulièrement pour se demander ce qui marche bien, moins bien et comment on peut s’améliorer. Le deuxième est le shadowing, il consiste à aller dans une autre équipe en immersion pendant quelques jours pour découvrir ses façons de faire et s’en inspirer.
- Faire de la veille collective : en partageant nos lectures (articles de blog, papiers scientifiques, conférences…,), en organisant des conversations sur celles qui nous ont le plus marqué.
Ces pratiques, qui nous permettent de progresser, d’avoir des consultants toujours plus compétents, de fidéliser les salariés, peuvent aussi s’appliquer dans votre organisation. Prenez le temps de réfléchir à vos façons de progresser, et comment vous pourrez les améliorer.
8. L’UX au service de la Data Science qui marche
“Les utilisateurs ou leurs représentants et les développeurs doivent travailler ensemble quotidiennement tout au long du projet.” - 4ème principe du manifeste agile
Le marché de la Data Science a eu plusieurs phases : la découverte, les POCs pour prouver la valeur, l’industrialisation pour rendre reproductibles nos processus, et en ce moment les problématiques de mise en production pour les rendre accessibles aux utilisateurs. Le prochain sujet : l’utilisabilité et l’utilisation de nos solutions.
Pour garantir que nos projets soient utiles, utilisables et utilisés, la meilleure façon de faire est d’embarquer les utilisateurs (les vrais, pas des proxys) tout au long du projet, notamment en leur proposant d'interagir avec le système en construction. Les objectifs sont d’obtenir rapidement du feedback sur la solution produite et d’identifier les transformations que cela va impliquer sur leur quotidien.
Pour impliquer les utilisateurs, il vaut mieux mettre entre leurs mains la solution (même si elle n’est pas parfaite) plutôt que de se contenter de leur faire des démonstrations ou de faire des hypothèses non vérifiées sur leurs comportements. Cette façon de faire est complètement liée avec la conviction “livrer continuellement un petit incrément de valeur en production”.
Ainsi, les équipes de Data Science doivent être centrées utilisateurs et interagir régulièrement avec eux afin de développer l'empathie et répondre de manière appropriée en lien avec le besoin réel et applicable. L’UX (la personne) avec son expertise en psychologie cognitive et en design d'interactions peut apporter beaucoup de recul et de connaissance utilisateurs.

Le changement apporté par des solutions de Data Science dans le quotidien des utilisateurs peut être inquiétant. Embarquer les utilisateurs dès le début du projet permet de réduire ces inquiétudes en les rendant acteurs de leur disruption.
9. Construisez ce que vous voulez maîtriser
Le débat build vs buy a fait couler beaucoup d’encre : vaut-il mieux développer son propre logiciel/service en custom ou choisir un progiciel pré-packagé ?
Pour diverses (et souvent mauvaises ...) raisons, beaucoup d’organisations ont plutôt fait le choix de penser progiciel-first à chaque fois qu’un besoin est exprimé.
On retrouve ce vieux réflexe dans le domaine de la data et de la Data Science. L’effet combiné de la complexité du sujet et de la pression marketing permanente pousse beaucoup à abandonner très vite la piste développement custom. On part alors sur un autre combat et non des moindres : faire son choix dans l’offre pléthorique des acteurs data/IA.
Souhaiter bénéficier de la capitalisation et la R&D d’un acteur qui semble maîtriser le sujet est un argument de poids. Il convient toutefois de rappeler 2 points, notamment pour ceux qui comptent sur la data pour être un nouveau relais de croissance et pour qui celle-ci devient un asset stratégique :
- Pour être vendue, une solution du marché se doit de constituer le plus petit commun multiple des besoins traditionnellement observés, autrement dit, conçue pour satisfaire le plus grand nombre d'entreprises. Dur dans ce cas de réellement trouver un avantage compétitif en se basant uniquement sur cette solution. Il faudra de toute façon trouver autre chose.
- Le monde de la data/IA évolue vite et en permanence. La capacité à s’adapter et à innover est rendue bien plus complexe quand sa propre roadmap est dépendante d’un acteur tiers.
À l’inverse, on peut être tenté de développer plus de choses par soi-même pour se différencier de la concurrence. Là encore, on essayera de trouver le juste équilibre : on ne va pas en 2021, à moins de le justifier comme il se doit, développer sa propre librairie de manipulation de data frame ou son framework de deep learning.
Pour trouver cet équilibre, on pourra par exemple regarder du côté de l’open source l'émergence de standards. Bien que l’open source ait souvent été vu comme le chevalier blanc face aux méchants éditeurs logiciels, il convient là aussi de faire attention. L'écosystème est encore en pleine structuration, des nouveaux outils/frameworks apparaissent (et disparaissent !) tous les jours. Il suffit de voir le destin d’Hadoop qui était le porte-drapeau de l’innovation data il y a peu et qui aujourd'hui est lentement en train de rejoindre le cimetière des éléphants.
Choisir un outil open source qui sera central pour le datalab peut relever ainsi du pari. On peut maximiser ses chances d’avoir misé sur le bon cheval en :
- Étant à l’écoute des équipes de développement,
- Étudiant les tendances de la communauté open source,
- Contribuant au développement de l’outil choisi !
Peu importe le choix que vous ferez, il restera toujours le risque de devoir, un jour, changer de framework. Miser en premier lieu sur les compétences de l’équipe est le meilleur moyen pour apporter une forme de résilience par rapport aux choix technologiques.
10. Métier et Data Scientist ont les mêmes objectifs
De l’idée jusqu’à l’utilisation en production des prédictions permettant des gains pour l’entreprise, les Data Scientists et le métier doivent travailler main dans la main.
Dès la phase amont, ne serait-ce que pour trouver les bonnes idées pour innover, Data Scientists et métier doivent trouver un terrain fertile et une compréhension mutuelle suffisante pour éviter deux écueils :
- Le Data Scientist qui implémente la fausse bonne idée qui finalement ne sera pas utilisée
- Le métier qui réclame ce qui relève parfois de l’impossibilité (comme par exemple imposer la précision souhaitée ET l’horizon de temps)
Chacun doit faire preuve de la pédagogie nécessaire pour appréhender le métier de l’autre. Le Data Scientist doit comprendre le déroulement concret des processus métier dans lequel s'insère son futur développement. Le métier doit comprendre les possibilités concrètes d’une démarche Data Science ainsi que ses limites.
Finalement, il existe énormément d'étapes qui nécessitent un réel travail d’équipe entre Data Scientist et métier (à tel point que le travail isolé de chaque partie est un symptôme très fort de dysfonctionnement) :
- L’identification de l’idée ou du besoin,
- La réalisation du cadrage,
- La définition de la façon de consommer les prédictions du modèle,
- L’identification des actions faites par le métier suite à une prédiction,
- La conception des voies de remontée de feedback utilisateurs et leur analyse,
- Le choix de la métrique ou la fonction de coût qui doit refléter réellement la logique métier.
Sur ce dernier point, rappelons qu’on ne doit pas choisir uniquement une fonction de coût maîtrisée par l’équipe, mais bien celle qui optimise le processus métier. Une fois que le métier a défini ses objectifs, on s’assurera de choisir, développer s’il le faut, la fonction de coût qui nous assurera que chaque optimisation correspond réellement à un gain opérationnel.
Enfin, on n’oubliera pas que la somme des optima locaux n’est pas l’optimum global. On peut facilement trouver des cas où optimiser localement une étape de processus peut dégrader considérablement la chaîne de valeur (ex. en marketing, cibler trop fréquemment par des communications/publicités son client peut accroître temporairement les ventes, mais dégrader la satisfaction et donc l’optimum global).
Là encore, métier et Data Scientists travaillent ensemble pour s’assurer que la Data Science sert de la façon la plus efficiente possible les objectifs stratégiques de l’entreprise.
CONCLUSION
Chez OCTO, nous sommes ravis de constater qu’au fil des années, le champ lexical et les préoccupations du Data Scientist s'enrichissent. Depuis la recherche absolue de performance algorithmique dans son coin, le Data Scientist a bien évolué : il travaille maintenant en équipe, il discute avec ses utilisateurs, fait du vrai code qui va en production et sait de plus en plus expliquer ce qu’il fait.
2021 sera sans doute une année bien occupée à digérer tous ces nouveaux concepts. Et encore, pour ne pas alourdir ce menu déjà bien complet, nous vous avons épargné cette onzième conviction qui pour le moment tiendrait plus du choc : il est grand temps de s’intéresser à l’empreinte carbone du Machine Learning. Nous en reparlerons bientôt.