Retour sur le FOSDEM 2019
Nouvelle année, nouvelle édition du FOSDEM (Free and Open Source Developers’ European Meeting). Après une édition 2018 bien fournie le cru 2019 s'est également révélé de bonne qualité. Impossible de lister tout ce que nous avons pu voir sur ces deux jours... Comme l'an dernier nous reviendrons donc sur certaines tendances qui nous ont marqué.
Kubernetes au delà des conteneurs
Kubernetes était à nouveau très présent durant ce week-end, avec pas moins de 45 présentations en parlant. Reflet d'un engouement qui ne se dément pas, le FOSDEM est une excellente occasion de voir les doers qui font évoluer la plateforme présenter leurs avancées, et un bon endroit pour entrevoir les tendances du futur.
Un grand axe de cette édition était l'adaptation de Kubernetes pour en faire une plateforme de virtualisation. Le projet KubeVirt monte visiblement en maturité, et plusieurs talks exploraient les conséquences d'ajouter des VMs à côté des conteneurs. Les modèles de virtualisation étant plus complexes que celui des conteneurs, la communauté s'active de tous les côtés pour enrichir le modèle Kubernetes.
Côté réseau, nous avons pu voir la présentation de kubernetes-nmstate[1], qui permet de configurer les interfaces réseau (SR-IOV, VLANs, …) des noeud depuis l'API Kubernetes, et permet de tirer partie de fonctionnalités dont les VMs sont friandes directement depuis le cluster. Côté monitoring, nous avons pu voir l'approche mise en place pour remonter les métriques des VMs dans Prometheus[2], ainsi qu'une GUI pour explorer graphiquement le riche modèle de KubeVirt[3].
[caption id="attachment_81737" align="aligncenter" width="700"] 
Pour avoir une place dans les salles convoitées comme Kubernetes, Go, ou containers, il vaut mieux se lever tôt. Github a intelligemment placé sa marque. © Thomas Wickham, CC BY-SA 4.0
[/caption]
De manière plus transverse, la communauté travaille pour enrichir les Persistent Volumes avec notamment de la migration, initialisation, duplication et resizing de PVs[4]. La possibilité d'initialiser automatiquement un PV en le liant à un dépôt Git semble particulièrement prometteuse pour simplifier les déploiements stateful, et sera à surveiller de près.
Les sujets de sécurité avancent également avec des travaux encore expérimentaux pour importer dans les conteneurs les modèles de sécurité Linux et permettre d'en déployer plusieurs sur un même noeud[5]. Cette capacité permettra à terme de gérer de manière différenciée la sécurité de l'hôte et de ses conteneurs, par exemple en durcissant le noeud par SELinux, tout en proposant AppArmor dans les conteneurs.
Fait intéressant, une large majorité des sujets ci-dessus étaient présentés par des ingénieurs d'IBM-RedHat. Cela prouve qu'au delà de son implication dans le leadership de la CNCF, ce nouveau poids lourd de l'industrie investit très fortement dans Kubernetes.
[1] Apply complex network configuration to your Kubernetes cluster hosts by declaring it - Petr Horáček [2] Monitoring Kubernetes and Virtualization - Yanir Quinn [3] Managing VMs and Containers in a Deeply Integrated UI - Marek Libra [4] Upcoming Kubernetes Storage features - John Griffith [5] Containers with Different Security Modules - John Johansen
"Encrypt everything", c'est maintenant
On le prédisait déjà dans le volume 2 de Culture DevOps : les flux chiffrés vont s'imposer partout. La tendance de la communauté est clairement à ne plus faire confiance aux réseaux des fournisseurs d'accès et des entreprises, et plusieurs talks réseau se sont penchés sur cette évolution de mentalité.
Sur les core internet protocols tout d'abord. Côté DNS, Daniel Stenberg a rempli à craquer le grand amphi du FOSDEM avec sa présentation de DNS over HTTPS[1]. Refonte majeure, ce nouveau protocole rend invisible le trafic DNS (il se retrouve indistinguable du trafic HTTPS) et empêche donc de le lire ou modifier. Autre rupture, Firefox implémente DoH directement dans le navigateur : les resolvers DNS du système sont ignorés, et leur choix est laissé à l'utilisateur. Or, intercepter le trafic DNS est au coeur de nombreux schémas réseau d'entreprise (portail captif, filtrage de sites internet, etc.) qui vont donc devenir inopérants ! Différents scénarios et mitigations ont été explorés dans un autre talk en track DNS[2].
[caption id="attachment_81722" align="aligncenter" width="700"] 
Le grand amphi de 1500 places est plein pour la session sur DoH, signe de l'intérêt pour ce sujet pourtant austère. © Mathieu Garstecki, CC BY-SA 4.0
[/caption]
On retrouve ce souci de confidentialité plus haut dans la pile réseau. Si HTTP/2 est déjà entièrement chiffré, HTTP/3 promet de protéger encore plus les flux en remplaçant carrément TCP (et ses en-têtes en clair) par le protocole QUIC[3] qui chiffre quasiment tout ce qui peut l'être. Côté recherche, certains continuent par ailleurs la traque au tracking[4] via les protocoles bas niveau, gageons donc que leur évolution ne va pas ralentir.
Cette défiance vis-à-vis des réseaux se retrouve aussi au niveau applicatif. Dans l'architecture réseau de Kubernetes (oui, encore), tous les composants s'authentifient mutuellement à coups de certificats TLS et chiffrent tous leurs flux, comme l'a montré une bonne introduction à la philosophie réseau de Kube[5]. Cette approche a été théorisée sous le nom de Zero Trust Networking, et va très certainement devenir de plus en plus visible dans les prochaines années tant elle a du sens dans le contexte sécuritaire actuel.
[1] DNS over HTTPS - the good, the bad and the ugly - Daniel Stenberg [2] DNS and the Internet's architecture: the DoH dilemma - Vittorio Bertola [3] HTTP/3 - Daniel Stenberg [4] Tracking users with core Internet protocols - Tobias Mueller [5] Kubernetes Network Security Demystified - Andrew Martin
Le poids du passé
Un FOSDEM ne serait pas entier sans les retours d'expérience des projets anciens, quasi-mythologiques, que nous utilisons au quotidien et dont la question de la maintenance ne se pose plus : MySQL, BIND9, PostgreSQL...
Ces projets honorables nous racontent comment ils ont traversé des périodes difficiles : difficile d'attirer des contributeurs et de les garder (MySQL[1]), difficile de faire évoluer le projet (BIND9[2]), difficile de s'assurer des non-régressions et de la correcte attribution des bugs (pf[3], pour packet filter, le firewall logiciel de FreeBSD), ou bien tout simplement une incompréhension de l'api de l'OS qui a sédimenté pendant 20 ans dans la base de code (PostgreSQL[4]).
Dans ces retours d'expérience, nous avons pu voir différentes approches selon les états des projets. Tous sont solides, matures, documentés, entreprise-ready, mais l'ouverture du capot montre une situation plus contrastée. On peut avoir d'un côté PostgreSQL, un projet très sain, très bien testé, et à l'autre extrême BIND9 (la neuvième ré-écriture du Buggy Internet Name Daemon) dont toute la résolution DNS était comprise dans une fonction de 2500 lignes en C à la complexité cyclomatique de 4.000[2].
[caption id="attachment_81734" align="aligncenter" width="700"] 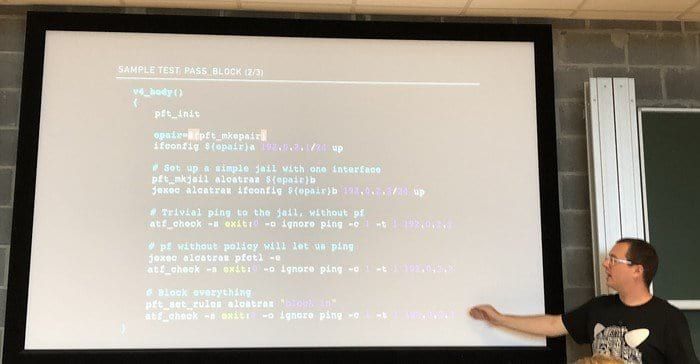
Dans la track FreeBSD, on rentre dans les détails des tests d'intégration de pf. © Thomas Wickham, CC BY-SA 4.0
[/caption]
Côté réseau encore, l'introduction des nouveaux protocoles cités plus haut est rendue très difficile par la variété des équipements réseau déployés dans le monde. Nombre d'entre eux ont été conçus pour traiter uniquement du HTTP 1 au-dessus de TCP, et vont bloquer ou corrompre le trafic s'il a la moindre différence par rapport à ce qu'ils attendent. Contourner ce phénomène (appelé ossification, puisqu'il fige les protocoles dans le marbre) est un enjeu majeur pour le succès des nouveaux protocoles, comme vu dans la présentation de HTTP/3[5] déjà citée. C'est une raison supplémentaire de chiffrer tous les flux : le côté illisible du flux chiffré empêche les équipements réseau de se figer sur ces nouveaux protocoles, et permettra donc de les faire évoluer plus facilement dans le futur.
Nul besoin d'ailleurs d'avoir un historique aussi ancien que les réseaux ou Bind pour subir le passé. Kubernetes n'a que cinq ans, et pourtant certains choix de design initiaux rendent plus difficile que nécessaire sa maintenance[6].
[1] Lessons from MySQL AB, the MariaDB Foundation, and others - Zak Greant [2] Stories from BIND9 refactoring - Witold Kręcicki [3] Automated firewall testing - Kristof Provost [4] How is it possible that PostgreSQL used fsync incorrectly for 20 years, and what we'll do about it. - Tomas Vondra [5] HTTP/3 - Daniel Stenberg [6] The clusterfuck hidden in the Kubernetes code base - Kris Nova
Reconquérir notre vie privée par la décentralisation ?
Ces dernières années, le terme "vie privée" est dans toutes les bouches, et le FOSDEM n’y échappe pas. L’année dernière déjà, un track Décentralisation et vie privée était dédié sur la journée du samedi. Cette année le track est passé d'une petite salle à un grand amphithéâtre, reflet de l’engouement sur le sujet. Nous voulions revenir sur un talk qui nous a particulièrement marqué et qui pourrait peut-être changer la face d’internet telle que nous la connaissons aujourd’hui.
Nous sommes aujourd’hui dans un pattern de données sur-centralisées. Nous avons plusieurs acteurs qui se battent afin d’avoir la plus grosse quantité de données personnelles entre leurs mains. On peut sortir deux problèmes de ce pattern :
- “J’ai mes données sur le service toto comment je fais pour les transférer vers le service tutu"
- “Je veux rentrer sur le marché avec mon tout nouveau réseau social mais les données sont déjà détenu par les majeurs du secteurs”
Pour résoudre ce problème, Solid (Social linked data)[1] est un ensemble d’outils et de conventions permettant d'agréger les données utilisateurs venant de pods de données hébergés directement par les utilisateurs eux mêmes. Ils peuvent également être hébergés par une entité à but non lucratif, entraînant alors uniquement des coûts d’infrastructure et réseaux pour l'utilisateur. L'utilisateur reste alors maître de ses données.
[1] Solid: taking back the Web through decentralization- Ruben Verborgh
Savoir se préparer pour le FOSDEM
Une visite au FOSDEM commence en général une bonne semaine avant : avec 27 salles en parallèle et 755 présentations référencées il faut un certain temps pour faire son choix dans le programme.
[caption id="attachment_81725" align="aligncenter" width="700"] 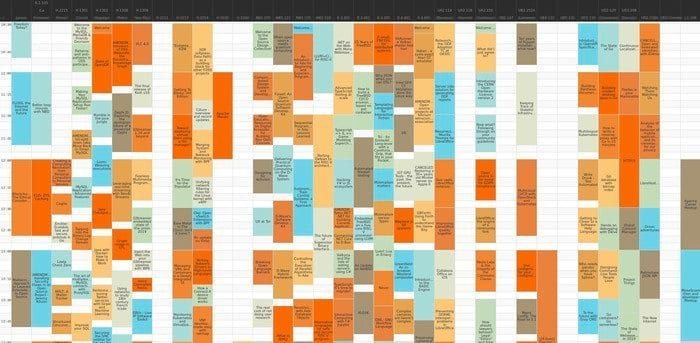
Le planning du samedi matin. Chaque colonne représente une salle. Bon courage. ©FOSDEM, CC BY 2.0 BE
[/caption]
Après une première passe, on se retrouve en général avec 5-6 conférences en parallèle, et souvent une incapacité à faire un choix entre tous ces sujets passionnants. Pas grave, la foule fait souvent le choix pour nous… Mieux vaut en effet avoir des choix de repli tant les conférences populaires se remplissent vite. Heureusement toutes les sessions sont filmées et très rapidement disponibles en rediffusion sur internet.
[caption id="attachment_81728" align="aligncenter" width="700"] 
Bon, on regardera la rediffusion… Y'a quoi dans la salle d'à côté ? © Mathieu Garstecki, CC BY-SA 4.0
[/caption]
Cette année encore, certains tracks étaient plus courus que d'autres. La salle Go (photo ci-dessus) était généralement pleine tout comme tout sujet lié de près ou de loin à Kubernetes. Le FOSDEM n'échappe par ailleurs pas aux buzzwords du moment : cette année a vu l'apparition d'une salle Blockchain and Cryptocurrencies, et le track Monitoring and Cloud de l'an dernier s'est vu renommé en Monitoring and Observability.
Licences
Le logo et le planning du FOSDEM sont publiés par les organisateurs de la conférence sous licence CC BY 2.0 BE.
Les autres photos de cet article ont été réalisées par les auteurs, et sont publiées sous licence CC BY-SA 4.0.