Retour sur la 5ème édition de la KubeCon
KubeCon North America 2017
Il y a deux ans, nous avions pu participer à la KubeCon Europe à Londres. Cette année la cinquième édition se tenait les 6, 7 et 8 décembre 2017 à Austin, aux États-Unis. Nous y étions et pour la première fois nous avons eu l’occasion d’y donner un talk ! Retour sur cette édition qui se voulait encore plus impressionnante et plus grande que les précédentes puisque le compteur affichait cette année plus de 4000 participants pouvant assister à plus de 225 sessions, sans compter les workshops et autres tables rondes.
C’est l’occasion de découvrir :
- La vision et les nouveautés de Kubernetes
- L’ensemble des solutions gravitant autour de l’écosystème Kubernetes
- Les retours d’expériences et différents cas d’usages
Cette KubeCon n’avait rien à voir avec celle qui s’était déroulée à Londres en 2015. On perçoit une réelle maturité autour de Kubernetes qui a clairement changé de ligue, passant d’une technologie prometteuse à un composant d’infrastructure standard à part entière. Kelsey Hightower, Staff Developer Advocate chez Google, l’affirme très bien à travers cette phrase prononcée lors de sa keynote “Kubernetes is the linux of the cloud and kubectl is the equivalent of ssh !”. Le temps des talks autour de l’installation de clusters, du déploiement de quelques pods ou encore de early adopters osant faire tourner une production sur Kubernetes est révolu. Déployer un cluster Kubernetes est devenu banal, faire tourner des milliers de conteneurs n’est plus un sujet et les productions sont assumées sur cette stack technologique avec des exemples comme GitHub, HBO ou le géant du e-commerce chinois Alibaba, capable de monter 10 000 conteneurs en 10 minutes lors du black friday.
Mais de quoi a-t-on parlé alors ? L’exploitabilité en production d’un cluster Kubernetes était au coeur de cette édition. Nous avons choisi de vous parler des sujets qui nous ont marqué et qui sont, pour nous, ceux qu’il faut retenir de cette KubeCon 2017 :
- Maîtriser son réseau et les communications entre les conteneurs à l’aide des service mesh
- Sécuriser mon cluster et ses composants
- Étendre l’API de Kubernetes pour l’adapter à mes besoins
La Cloud Native Computing Foundation fête ses 2 ans
La CNCF (Cloud Native Computing Foundation) a pour objectif de soutenir et promouvoir l’adoption des technologies de la conteneurisation, les architectures distribuées de type microservice, et l’automatisation de leur gestion. Son tout premier projet n’est autre que Kubernetes, projet offert par Google afin d’en assurer sa gestion et son développement. Après seulement deux ans d'existence la CNCF héberge aujourd’hui dans son giron 14 projets.

En 2018, ces derniers promettent plus de stabilité avec beaucoup de version 1.0 à l’horizon (CNI, Fluentd, CoreDNS…). Côté faits marquants, on notera le remplacement de kube-dns par CoreDNS en alpha dans Kubernetes 1.9 et l'apparition de Conduit, fork plus léger et dédié à Kubernetes de Linkerd.
Plus que des outils, la CNCF c’est avant tout des personnes d’horizons différents et travaillant pour des entreprises diverses qui partagent une vision commune. La multiplication des projets s’accompagne par l’explosion du nombre de membres de la communauté. En seulement deux ans, le nombre d’entreprises, d’experts et de développeurs a considérablement augmenté. Cette année, c’est le géant chinois Alibaba Cloud, branche cloud computing de Alibaba Group qui rejoint la CNCF en tant que Gold member afin de promouvoir les projets open source et la standardisation des services de la fondation dans l’écosystème Cloud asiatique. Dans ce sens une KubeCon + CloudNativeCon aura lieu à Shanghai en Chine en 2018.
L'intérêt pour les projets de la CNCF et leurs integrations croît d’année en année, en témoigne le nombre de participants, qui a quadruplé depuis la première édition , passant de 500 à 4000.
Les grandes tendances de la KubeCon
Les service mesh
Cette année, la majorité des déploiements Kubernetes présentés intégraient ce que l’on appelle un “service mesh”. Un service mesh permet de contrôler et gérer les communications applicative (HTTP, HTTPS, gRPC…) entre les différents services du cluster, tout en y apportant des fonctionnalités et des mécanismes de contrôle intéressants:
- Authentification entre les services
- Chiffrement des communications entre services
- Monitoring du trafic applicatif (couche 7 du modèle OSI)
- Séparation du trafic (75% vers la version 1 et 25% vers la version 2 par exemple)
- Processus de release avancé notamment du “canary release”
- Chaos testing (insertion de latence, pannes…)
- …
Comment ça fonctionne ? Un conteneur est ajouté dans chaque pod déployé sur le cluster et fait office de proxy. Il est en charge d’intercepter toutes les requêtes entrantes et sortantes de l’application présente dans le pod. Afin de gérer ces proxy, un controller est installé sur les noeuds masters du cluster Kubernetes. Son rôle est de configurer et surveiller l’état du proxy de chaque pod.
Pour le choix technique, la tendance dans les rues d’Austin était Istio comme controller et Envoy pour le proxy. Istio intègre notamment une autorité de certification permettant de délivrer des certificats aux proxy Envoy afin de permettre le chiffrement et l’authentification des communications entre les différents services.

Est ce que cela vaut le coup ? Oui. Est ce que cela est indispensable ? Non. La nécessité de mettre en place un service mesh dépend de la taille de votre cluster et du nombre de services différents qu’il supporte. Si vous avez un nombre élevé de services pour lesquels vous rencontrez des difficultés de contrôle (qui parle avec qui) ou si vous avez du mal à gérer les problèmes de communication entre vos services, un service mesh pourra vous permettre de sortir la tête de l’eau et de reprendre le contrôle de votre cluster.
La mise en place d’un service mesh dépend aussi des enjeux et des contraintes que vous avez sur votre cluster. Si vos communications doivent être chiffrées ou si vos releases suivent un pattern complexe pour assurer une disponibilité élevée, un service mesh est une bonne solution.
En plus d’un service mesh composé de Envoy et Istio, certains ajoutent un troisième composant: jaegger. Cet outil implémente le standard Opentracing de la CNCF. Il vous permet de compléter les fonctionnalités offertes par le service mesh en vous donnant la possibilité de tracer les requêtes et de visualiser les différents services traversés lors d’une communication. Il est alors facile de localiser les services en erreur ou les dégradations de performance (latence, temps de traitement long…). Istio et Envoy complété par Jaegger forme une stack complète pour gérer les communications entre vos services.
| En savoir plus |
| Istio: Weaving the Service Mesh <br><br> Shriram Rajagopalan, IBM & Louis Ryan, Google |
Sécuriser mon cluster et ses composants
Kubernetes est aujourd’hui un produit mature et stable. De nombreuses entreprises ont mis en place des clusters afin d’y déployer leurs environnements de production. Il est alors naturel qu'aujourd'hui, une fois passé le cap de la stabilité, ce soit les enjeux de sécurité qui soient au premier plan pour les administrateurs. Un track entier était dédié à ce sujet pendant les trois jours de conférence.
Plusieurs implémentations et fonctionnalités existent dans kubernetes pour réduire les risques de propagation lors de la compromission d’un pod ou d’un node de votre cluster :
Au niveau Kubernetes :
- Désactiver ABAC (Attribute-Based Access Control) et activer RBAC (Role-Based Access Control)
- Utiliser les namespaces pour séparer vos environnements et vos clusters
- Utiliser des Network Policies pour filtrer vos flux
- Utiliser les anti-affinités et les “taints” (permet à un node de refuser le déploiement de certains pods) pour séparer les workloads sensibles
- Placer un système de firewall entre vos workers et vos masters
- Garder à jour son cluster (version 1.9 à ce jour)
Au niveau du Node :
- Mettre en place de l’authentification au niveau du Kubelet
- Rotation du certificat pour le client Kubelet
- Appliquer le principe du moindre privilège
- Possibilité de dédier des noeuds à des services spécifiques
Au niveau du Pod :
- Privilégier les OS minimaux pour réduire les commandes et donc les actions disponibles
- Éviter de faire tourner les conteneurs en tant que root
- Limiter l’utilisation des HostPath (volumes montés directement depuis le node)
Kubernetes est simple à mettre en place, tout du moins lorsqu’il s'agit d’implémenter ses fonctionnalités de base. Mais le déploiement d’un cluster destiné à la production n’échappe pas aux règles et aux obligations de sécurité d’un Système d’Information classique. Bien que les mesures de sécurité soient différentes dans le monde Kubernetes, elles existent à travers des fonctionnalitées avancées. Kubernetes et les architectures microservices ne vous garantissent pas une sécurité “out-of-the-box”, alors pensez sécurité dès les prémices de la mise en place de votre cluster.
| En savoir plus |
| Shipping in Pirate-Infested Waters: Practical Attack and Defense in Kubernetes <br><br> Greg Castle & CJ Cullen - Google |
« Vers l'infini, et au delà ! » (extension d’api)
L’architecture de Kubernetes utilise un certain nombre de ressources que nous manipulons tous les jours dans les interactions avec notre cluster: pods, services, ingress, deployment etc … Cependant Kubernetes permet l’ajout de nouvelles ressources et l’implémentation de nouveaux objets sans pour autant devoir faire une pull-request dans le dépôt git core de l’API Kubernetes. Heureusement car la ressource que je souhaite ajouter est pertinente pour mon contexte et mon utilisation mais ne l’est pas forcément pour le reste de la communauté.
Prenons l’exemple du service Prometheus dont l’intégration est faites au travers de ressources dédiées spécifique. Le fait que ces dernières ne soit pas embarquées dans le coeur de Kubernetes permet d’augmenter sa flexibilité en laissant le choix à l’utilisateur.
Pour étendre Kubernetes, 2 possibilités :
- Ajouter une extension au serveur d’API Kubernetes en créant notre propre serveur d’API
- Utiliser les CustomResourceDefinition qui sont des ressources à part entière et permettent de faire porter notre extension directement par le système lui même.
En étendant l’API vous serez alors capable de requêter, modifier ou supprimer vos ressources comme n’importe quelles autres ressources standards. Cette extension s’accompagne généralement de l’ajout d’un operator. Un operator est un pod implémentant la partie métier, il interagit avec le cluster pour le mettre dans l’état attendu en réalisant perpétuellement le cycle suivant :
- Observation de l’état actuel du cluster.
- Analyse de cet état et comparaison avec l’état désiré.
- Application des modifications au cluster pour atteindre l’état désiré.

L’extension d’API et le déploiement d’un operator s’accompagnent de la mise en place de toutes les règles d'autorisation (RBAC) nécessaire à leurs opérations sur le cluster. L’implémentation des operators peut se faire dans n’importe quel langage et il est fortement recommandé d’utiliser toutes les librairies de générations de code mises à disposition par la communauté.
| En savoir plus |
| Operator le plus courant : Prometheus<br><br> Extending Kubernetes: Our Journey & Roadmap<br><br> Daniel Smith & Eric Tune, Google |
Bonus: la keynote qui nous a marqué !
Brendan Burns a participé à la création de Kubernetes chez Google et travaille aujourd’hui pour Microsoft. Lors de sa keynote, il a présenté Metaparticle. Il part du constat suivant : pour déployer une application en mode microservice, dans Kubernetes par exemple, il faut écrire trois fichiers. L’application elle même dans le langage de votre choix, le Dockerfile pour packager l’application dans son container et enfin le fichier de déploiement pour déployer son application sur Kubernetes.
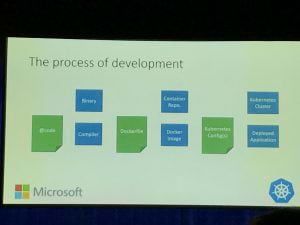
Certaines informations sont dupliquées à travers ces trois fichiers, par exemple la simple écoute de l’application sur le port 80 est définie à la fois dans le code, le Dockerfile et le fichier de déploiement. La chance de faire une erreur est grande et le coût de maintenance est élevé.
Metaparticle propose de définir des librairies standards permettant de définir des patterns et des fonctionnalités du monde des microservices (conteneurisation, déploiement sur k8s, sharding…) directement dans le code de votre application. Plus de YAML ou de DSL, plus de Dockerfile, plus de fichier de déploiement Kubernetes, tout est défini dans le code de votre application.
Outre la simplification du processus de développement cela permet aussi de profiter des fonctionnalités des langages de programmation déjà éprouvés que les DSL ne possèdent pas (abstraction, héritage…). Les développeurs jouent alors en terrain connu et n’ont plus besoin d’apprendre de nouveaux formats et outils dans l’unique but de packager leur application dans kubernetes.
Plusieurs exemples basiques ont été montrés durant le keynote, par exemple pour conteneuriser un simple serveur HTTP en javascript il suffit d’écrire le code suivant :
const mp = require(‘@metaparticle/package’); … mp.containerize( { port: [port], repository: ‘docker.io/image’ }, () => { server.listen(port, (err) => { console.log( hello world); }); });
Pour déployer sur Kubernetes en Java :
@Package(repository=”docker.io/image”, jarfile=”path/to/my-app.jar”) @Runtime(replicas=4)
public static void Main { Containerize(() -> { … } }
Au départ une expérimentation personnelle de Brendan Burns, Metaparticle est devenu un projet à part entière après la présentation à la Kubecon et l’intérêt qu’il a suscité parmi la communauté. Le projet supporte plusieurs langages dont Java, Golang et le Javascript avec des librairies encore très basiques. C’est un changement important dans l’approche de la conteneurisation et dans le processus de développement d’une application microservice. Son adoption et son développement, notamment la variété des librairies disponibles, décidera de son avenir et de son impact sur l’écosystème. A noter que pour l’instant, seul le déploiement sur Kubernetes est envisagé ce qui créer une forte adhérence. Dans tous les cas, Metaparticle est à surveiller de très près !
| En savoir plus |
| This Job is Too Hard: Building New Tools, Patterns and Paradigms to Democratize<br><br> Brendan Burns, Distinguished Engineer, Microsoft |
Conclusion
Peu d’annonces lors de cette Kubecon 2017 mais beaucoup de sujets et de retours d’expérience qui prouvent qu’aujourd’hui Kubernetes a fait ses preuves et a passé un cap : celui de la maturité.
Le message est clair, Kubernetes s’est imposé comme un standard et est maintenant stable, proposant des mises à jour régulières et moins importantes. C’est désormais à la communauté d’innover, d’étendre les capacités et les fonctionnalités en construisant par dessus les fondations posées par Kubernetes. C’est ce que font la plupart des produits de l’écosystème.
OCTO Technology a donc pu affiner sa vision de l’écosystème Kubernetes et est revenu avec de nombreux sujets à creuser dans ses bagages, pour une possible intégration chez ses clients !
Retrouvez notre talk concernant la mise en place d’une stack de monitoring prometheus sur un environnement de production ici : https://www.youtube.com/watch?v=MNc3046o-Og&t=4s
Et bien sur toutes les sessions sont disponibles sur youtube : https://www.youtube.com/playlist?list=PLj6h78yzYM2P-3-xqvmWaZbbI1sW-ulZb
Prochain rendez vous les 2, 3 et 4 mai à Copenhague pour la Kubecon + CloudNativeCon Europe 2018.